
AGI in progress @ Qwen. DeepResearch lives here → qwen.ai
Joined November 2021
- Tweets 17
- Following 52
- Followers 206
- Likes 31
Photos and videos

14 Nov 2025
🐳Every spark of curiosity deserves to be explored — try Qwen DeepResearch today! qwen.ai/blog?id=qwen-deepres…
98
14 Nov 2025
Welcome to try our latest Qwen DeepResearch — we’d love to hear your feedback! 🩷
13 Nov 2025

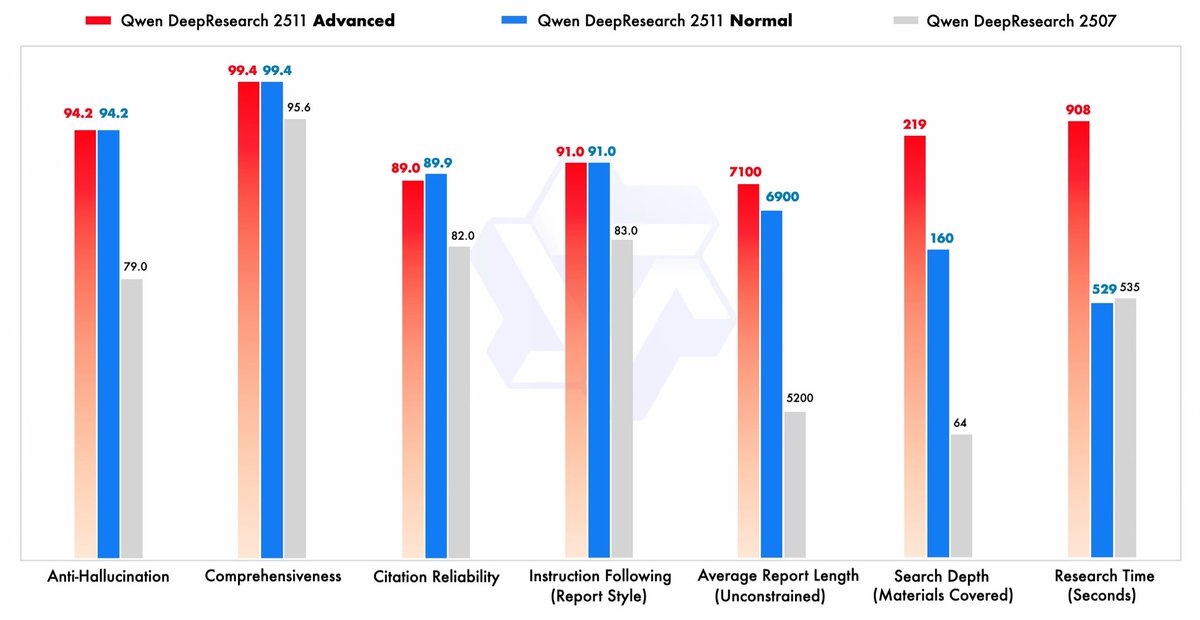
🚀 Qwen DeepResearch 2511 is LIVE! 🚀
We've just dropped a major upgrade, making your research deeper, faster, and smarter!
🔗: chat.qwen.ai/?inputFeature=d…
APP: qwen.ai/download
✨ Dual Mode Selection:
Normal Mode: Efficient & versatile for most needs!
Advanced Mode: Go deeper! Devotes extra time for a more thorough analysis. 🧠
📄 File Uploads Enabled: Now you can easily upload your documents or images for the AI to analyze!
⚡️ Boosted Search Power: Drastically improved search efficiency & depth. Read and process more web info in less time!
📊 Precise Report Control: Command the report format—word count, paragraphs, & content! Get comprehensive reports with enhanced citation reliability.
🧑💻 All-New UX: Our new decoupled architecture delivers a smoother, more responsive user experience!
1
2
214
Bei Chen retweeted

21 Oct 2025
Qwen Deep Research just got a major upgrade. ⚡️
It now creates not only the report, but also a live webpage 🌐 and a podcast 🎙️ - Powered by Qwen3-Coder, Qwen-Image, and Qwen3-TTS.
Your insights, now visual and audible. ✨
👉 chat.qwen.ai/?inputFeature=d…
68
200
1,450
204,588
Bei Chen retweeted
22 Jul 2025
>>> Qwen3-Coder is here! ✅
We’re releasing Qwen3-Coder-480B-A35B-Instruct, our most powerful open agentic code model to date. This 480B-parameter Mixture-of-Experts model (35B active) natively supports 256K context and scales to 1M context with extrapolation. It achieves top-tier performance across multiple agentic coding benchmarks among open models, including SWE-bench-Verified!!! 🚀
Alongside the model, we're also open-sourcing a command-line tool for agentic coding: Qwen Code. Forked from Gemini Code, it includes custom prompts and function call protocols to fully unlock Qwen3-Coder’s capabilities. Qwen3-Coder works seamlessly with the community’s best developer tools. As a foundation model, we hope it can be used anywhere across the digital world — Agentic Coding in the World!
💬 Chat: chat.qwen.ai/
📚 Blog: qwenlm.github.io/blog/qwen3-…
🤗 Model: hf.co/Qwen/Qwen3-Coder-480B-…
🤖 Qwen Code: github.com/QwenLM/qwen-code

380
1,448
9,349
2,276,291
14 May 2025
Check out our latest feature — DeepResearch! Constantly getting smarter~😊
13 May 2025
After a few weeks of phased testing, Deep Research on Qwen Chat is now live and available for everyone ! 🎉
Here's how to use it: Just ask something you're curious about — like "Tell me something about robotics." Qwen will then ask you to narrow it down — maybe history, theory, or real-world applications. You can pick one, or just say "Not sure… Surprise me!" 😄
Then, while you grab a coffee ☕ or take a quick break, Qwen will put together a clear, helpful report just for you.
AI is getting better every day, and Qwen is here to help make your life a little easier — whether it’s for work, learning, or just satisfying your curiosity.
Why not give it a try? You might find something cool! 💡
🔗:chat.qwen.ai/?inputFeature=d…
1
3
35
3,475
Bei Chen retweeted
13 May 2025
After a few weeks of phased testing, Deep Research on Qwen Chat is now live and available for everyone ! 🎉
Here's how to use it: Just ask something you're curious about — like "Tell me something about robotics." Qwen will then ask you to narrow it down — maybe history, theory, or real-world applications. You can pick one, or just say "Not sure… Surprise me!" 😄
Then, while you grab a coffee ☕ or take a quick break, Qwen will put together a clear, helpful report just for you.
AI is getting better every day, and Qwen is here to help make your life a little easier — whether it’s for work, learning, or just satisfying your curiosity.
Why not give it a try? You might find something cool! 💡
🔗:chat.qwen.ai/?inputFeature=d…
77
233
1,445
102,729
Bei Chen retweeted
28 Jan 2025
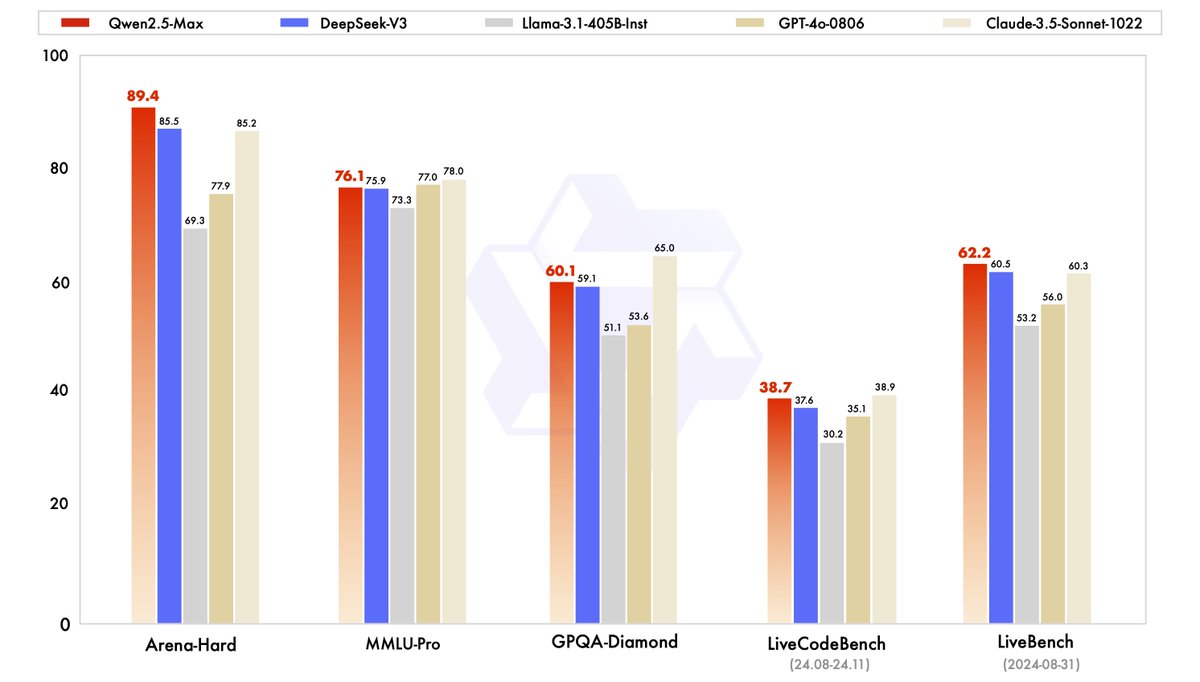
The burst of DeepSeek V3 has attracted attention from the whole AI community to large-scale MoE models. Concurrently, we have been building Qwen2.5-Max, a large MoE LLM pretrained on massive data and post-trained with curated SFT and RLHF recipes. It achieves competitive performance against the top-tier models, and outcompetes DeepSeek V3 in benchmarks like Arena Hard, LiveBench, LiveCodeBench, GPQA-Diamond.
📖 Blog: qwenlm.github.io/blog/qwen2.…
💬 Qwen Chat: chat.qwenlm.ai (choose Qwen2.5-Max as the model)
⚙️ API: alibabacloud.com/help/en/mod… (check the code snippet in the blog)
💻 HF Demo: huggingface.co/spaces/Qwen/Q…
In the future, we not only continue the scaling in pretraining, but also invest in the scaling in RL. We hope that Qwen is able to explore the unknown in the near future! 🔥
💗 Thank you for your support during the past year. See you next year!
456
1,408
7,230
3,062,149
Bei Chen retweeted

27 Dec 2024
🚀 Introducing Aria-UI – a cutting-edge grounding LMM for GUI agents with a lightning-fast 3.9B parameters activated backbone!
🌐 Try it yourself: huggingface.co/spaces/Aria-U…
📄 Project page: ariaui.github.io
📂 Explore on GitHub: github.com/AriaUI/Aria-UI
7
56
373
105,947
Bei Chen retweeted

15 Oct 2024
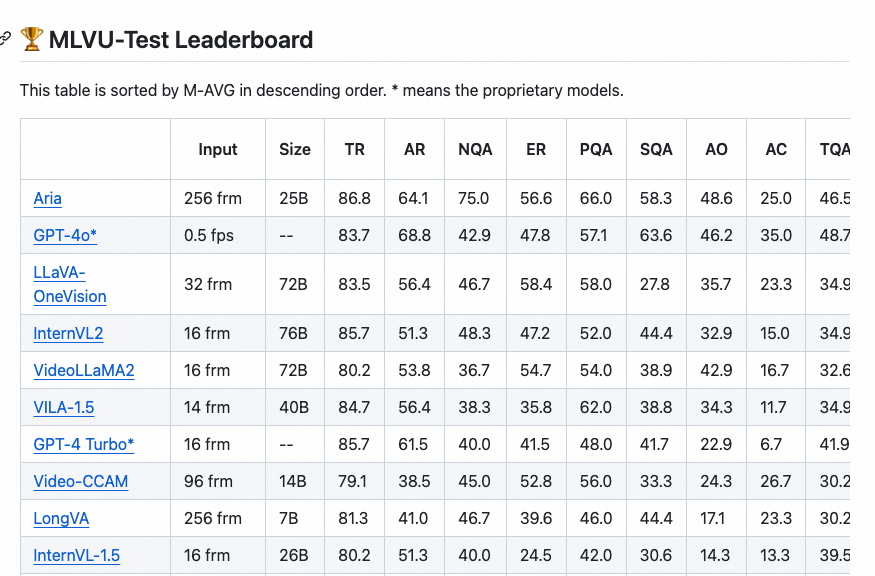
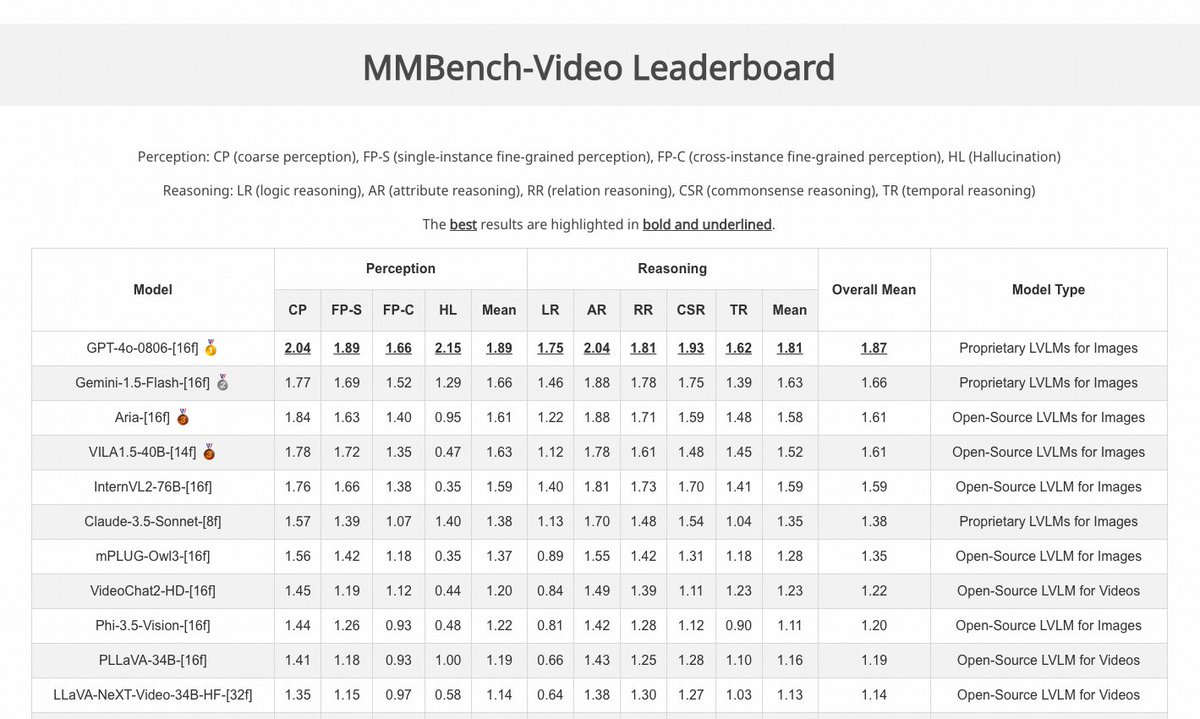
Excited to see Aria ranking high on video benchmarks like MLVU, MMBench-Video, VideoMME, and LongVideoBench, while activating merely 3.9B parameters.
Video understanding is a core capability for next-gen multimodal models, and there’s still plenty of work ahead!
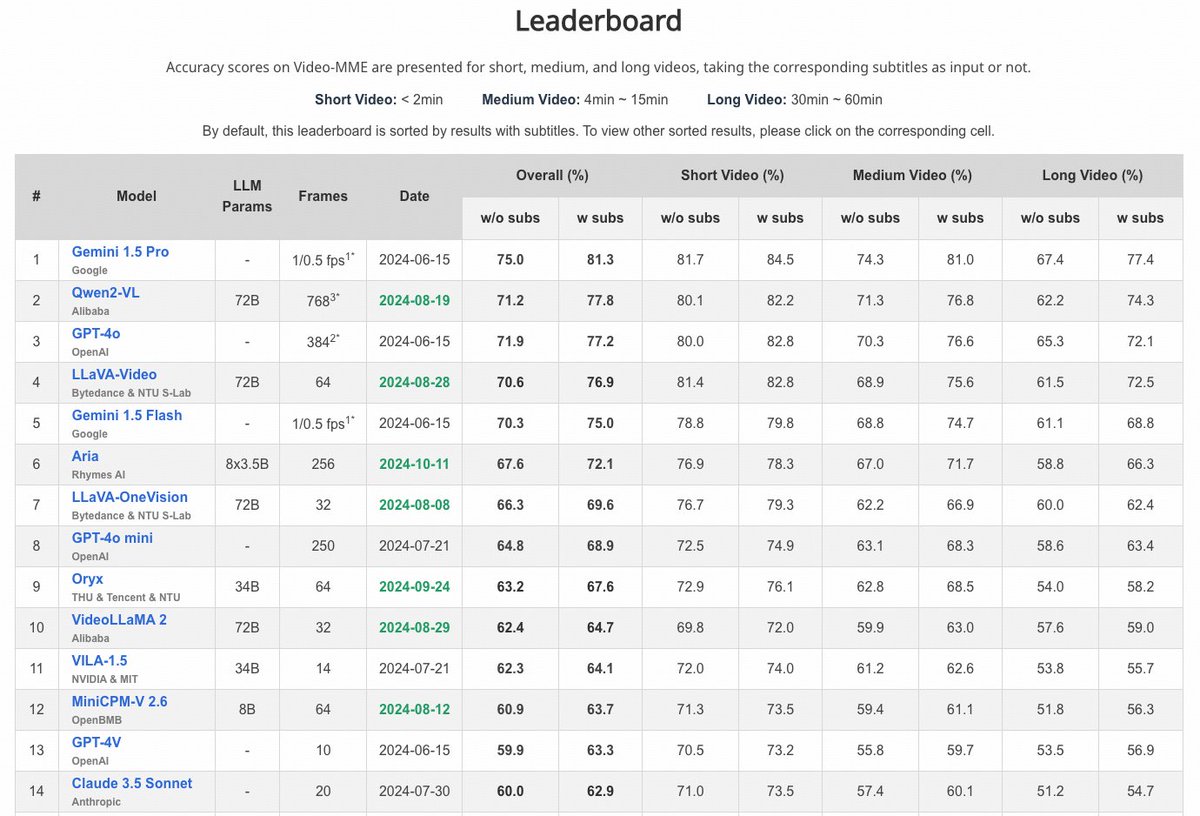
1
26
1,481
Bei Chen retweeted

10 Oct 2024
🚀 Introducing Aria from @rhymes_ai_ : The first open-source, multimodal native MoE model! Aria uses 3.9B parameters per token, excelling in multimodal & language tasks.
It features a 64K token context window, captioning 256-frame videos in 10 seconds. Lightweight, fast, & efficient. Check out some cool demos!
Clear advantages over Pixtral-12B and Llama3.2-11B across a range of multimodal, language, and coding tasks. Also competitive against proprietary models like GPT-4o and Gemini-1.5 on some multimodal tasks 💪
Now open on @huggingface & @github with open weights & code 🤗 (Apache 2.0)!
Read more: rhymes.ai/blog-details/aria-…
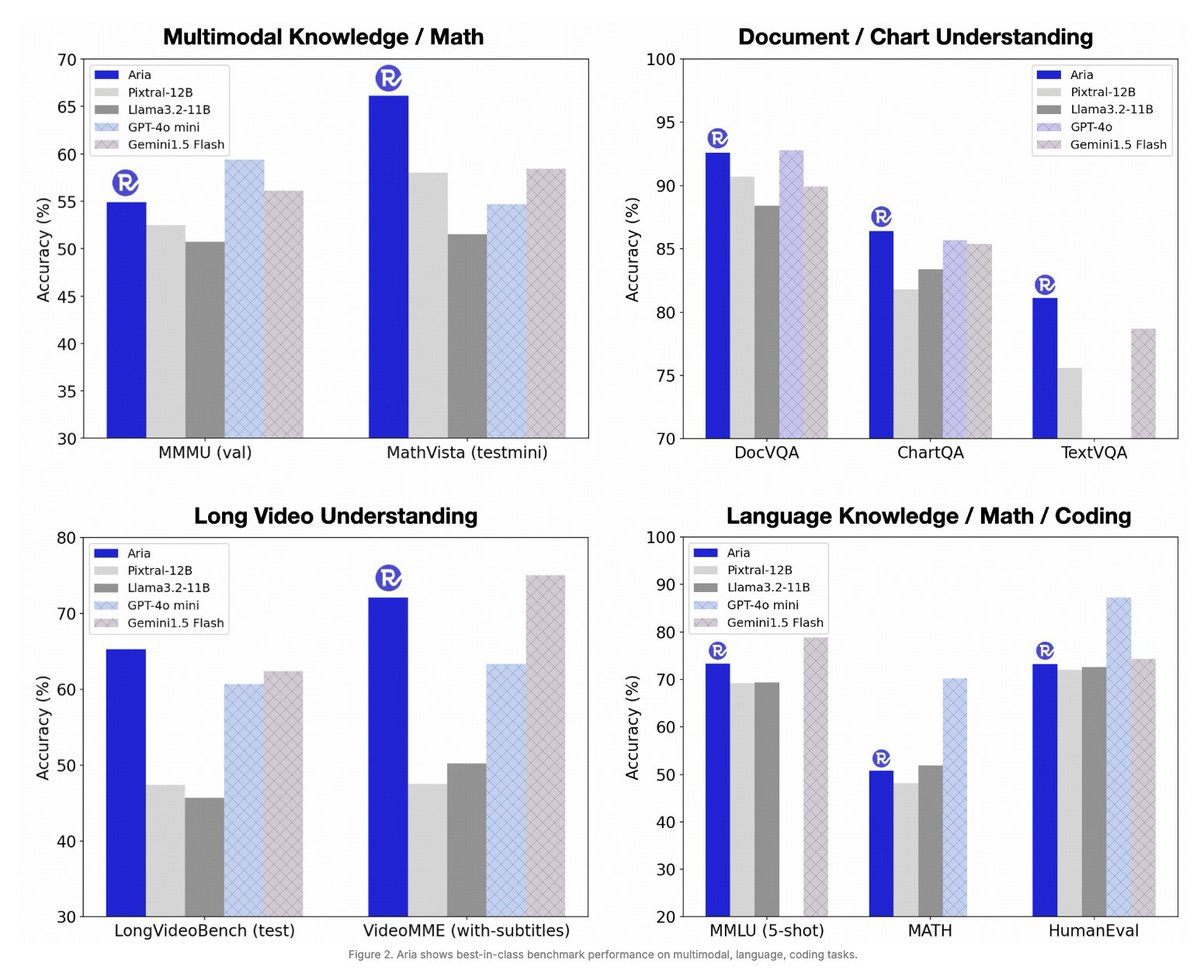
6
30
131
12,305
Bei Chen retweeted
10 Oct 2024
Introducing Aria: the first open-source, multimodal native MoE, with best-in-class performance across multimodal, language, and coding tasks!
Blog: rhymes.ai/blog
Technical Report: arxiv.org/pdf/2410.05993
Github: github.com/rhymes-ai/Aria
Demo: rhymes.ai/

6
40
201
30,549
Bei Chen retweeted

23 Jul 2024
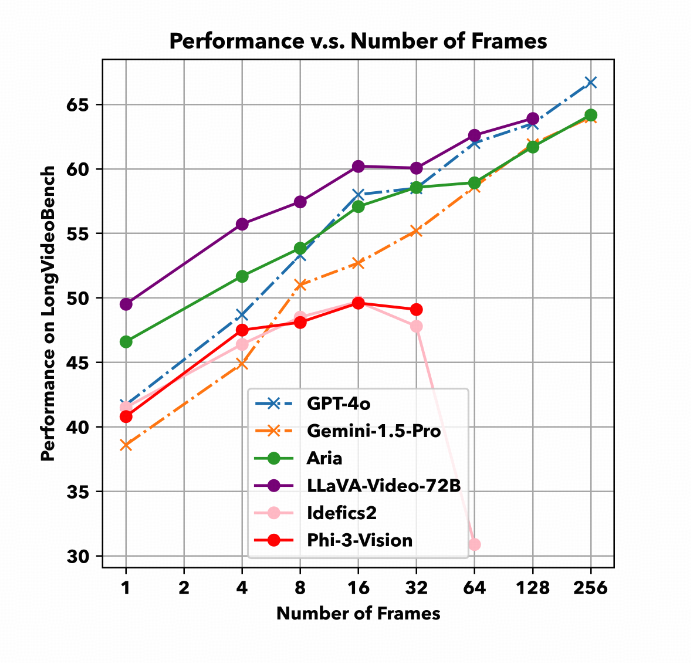
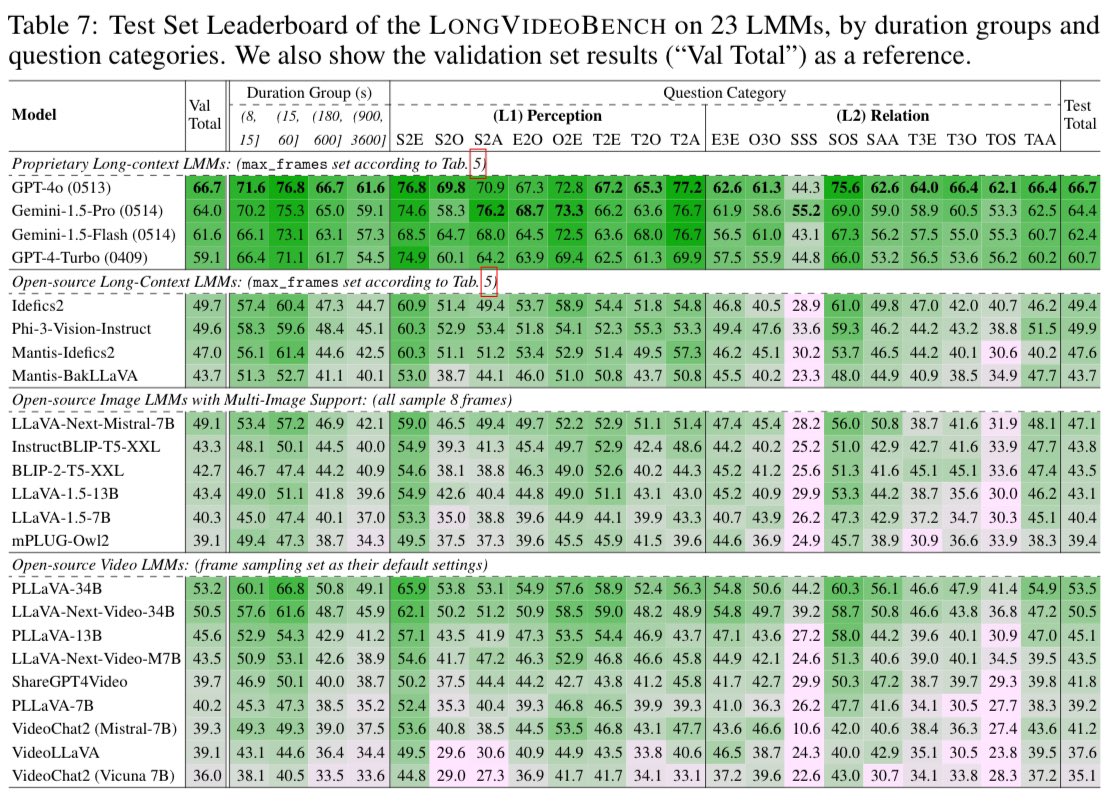
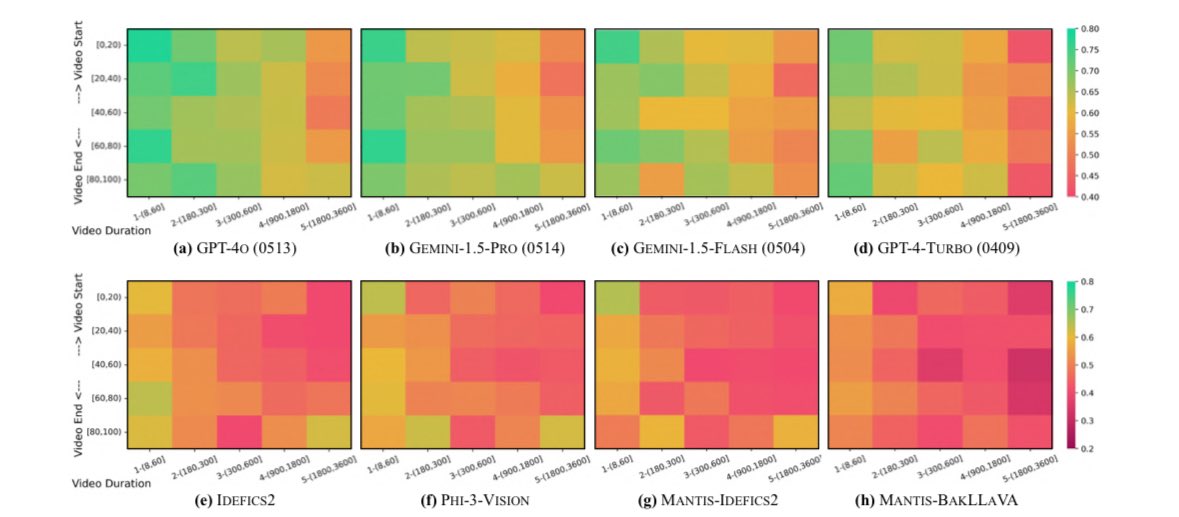
3) LongVideoBench consists of 6.7K human-labeled questions, evaluates 23 LMMs and reaches many interesting findings.
Please find more on our @huggingface Paper Page: huggingface.co/papers/2407.1…!
Work done by me, @DongxuLi_, @beichen1019, and @LiJunnan0409.
23 Jul 2024

2) Fulfilling that requirement, the LongVideoBench is composed of hard referring reasoning questions on VIDEO DEAILS, where GPT-4o/Gemini-1.5 can perform better with more input frames (almost linearly scale even on 256 frames!) while open-source models fall behind.
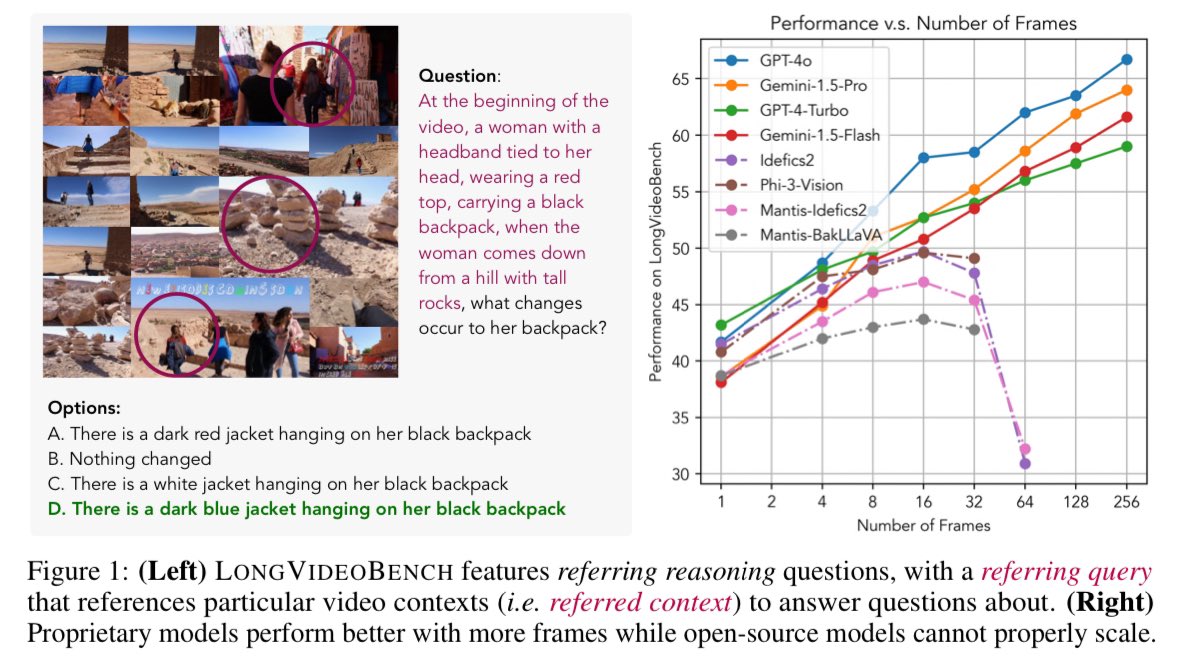
2
6
20
10,031
Bei Chen retweeted

23 Mar 2023
Repocoder is a simple but effective idea of iterative retrieval and generation for code. Hope to make it to Copilot to bring more customization for your productivity. The analysis in the paper is also informative. Main authors are @beichen1019 and @Zfj1998105.
@eaftandilian

RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation
abs: arxiv.org/abs/2303.12570

2
4
18
5,772
25 Aug 2022
Wow
24 Aug 2022

We are hiring 📣!
Sea AI Lab🇸🇬 is looking for interns & industrial PhD students (with NUS) across CV, RL, ML, Trustworthy AI, Audio and *NLP* (supervised by me). If you are interested in fundamental research🪶, apply now👨💻 and be a part of us!
sail.sea.com/talent/
3
22 Jul 2022
Our recent work on code generation. A simple idea (execution on generated test cases) with surpring performance (HumanEval pass@1 65.8%). Welcome to discuss~
CodeT: Code Generation with Generated Tests
abs: arxiv.org/abs/2207.10397
CODET improves the pass@1 on HumanEval to 65.8%, an increase of absolute 18.8% on the code-davinci-002 model, and an absolute 20 % improvement over previous sota results
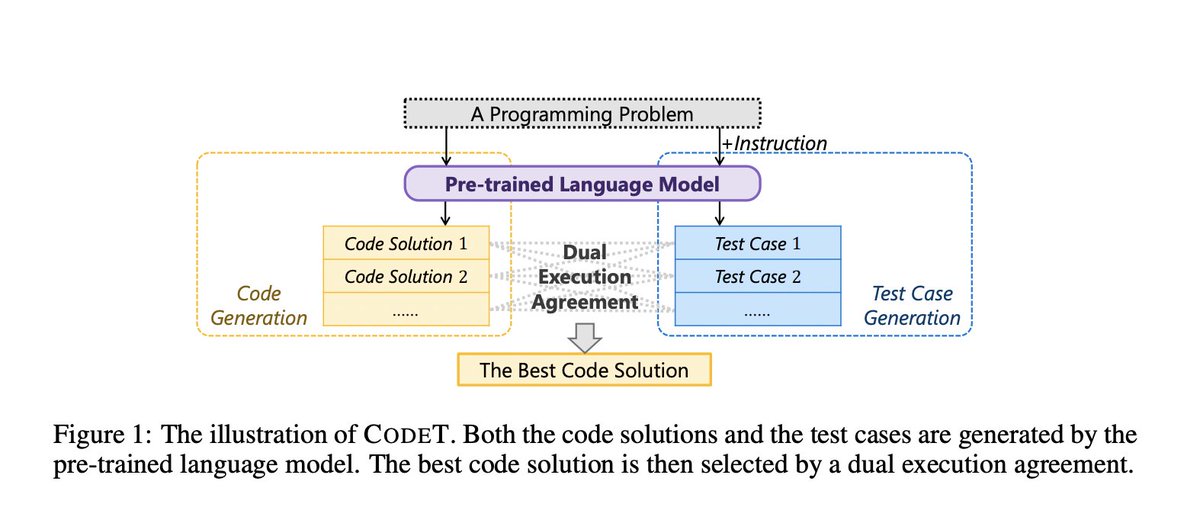
9
52
Bei Chen retweeted
22 Jul 2022
Thanks for promoting our work. Look forward to applying some of the techniques here to make copilot better.
1
9