
PhD Nanyang Technological University🇸🇬, BS @PKU1898, cooking VLMs in @Kimi_Moonshot. Opinions are personal.
Joined December 2020
- Tweets 454
- Following 741
- Followers 3,233
- Likes 583
56 Photos and videos










Pinned Tweet

Jan 27
We are really taking a long time to prove this: everyone is building big macs but we bring you a kiwi🥝 instead.
You have multimodal with K2.5 everywhere: chat with visual tools, code with vision, generate aesthetic frontend with visual refs...and most basically, it is a SUPER POWERFUL VLM
Jan 27

Kimi K2.5 has arrived! 🥝
Here are 2 things to know: Aesthetic Coding x Agent Swarm.
19
19
477
44,495
May 29
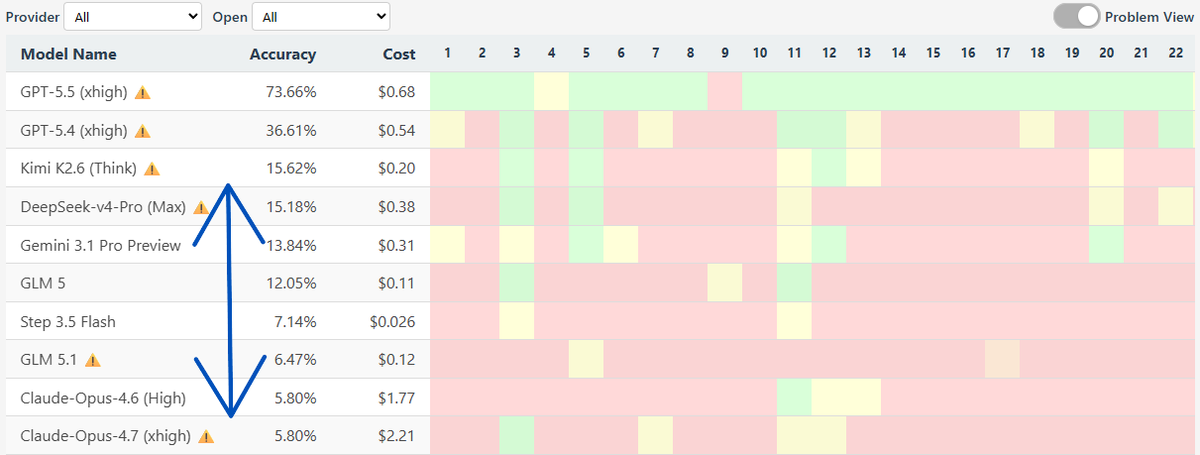
actually opus-4.7 and 4.8 have stalled at the same token-accuracy pareto for osworld
May 28

OSWorld: Hurray! survive one more day
2
16
2,525

May 5
this is literally insane that we truly see an open model thinking 200-300k for math problems…
1
1
111
12,290

Apr 29
Very Nice Move👍
Apr 28

Note we've renamed Code Arena to Frontend Design: WebDev for these chats. I hope this is less confusing, but lmk if you have better suggestions
8
703
Wu Haoning retweeted

Apr 28
huggingface.co/papers/2604.2…
arxiv.org/abs/2604.23781
tech report release
Apr 20

Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (github.com/openclaw/openclaw…), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping 0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀

2
8
40
11,683
Apr 26
open intelligence in duet

1
1
40
3,071
Wu Haoning retweeted

Apr 24
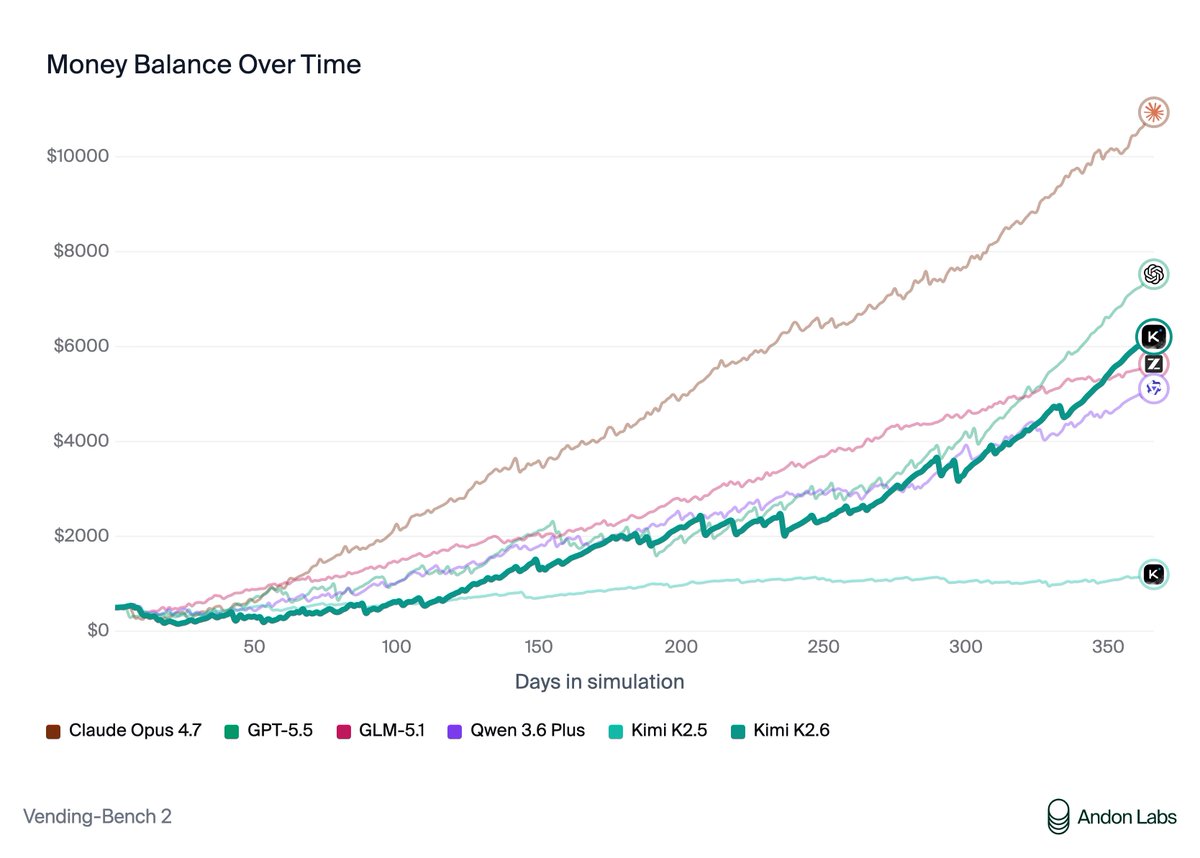
Kimi K2.6 is #5 on Vending-Bench 2. It's the best open model, overtaking GLM 5.1.
Apr 20
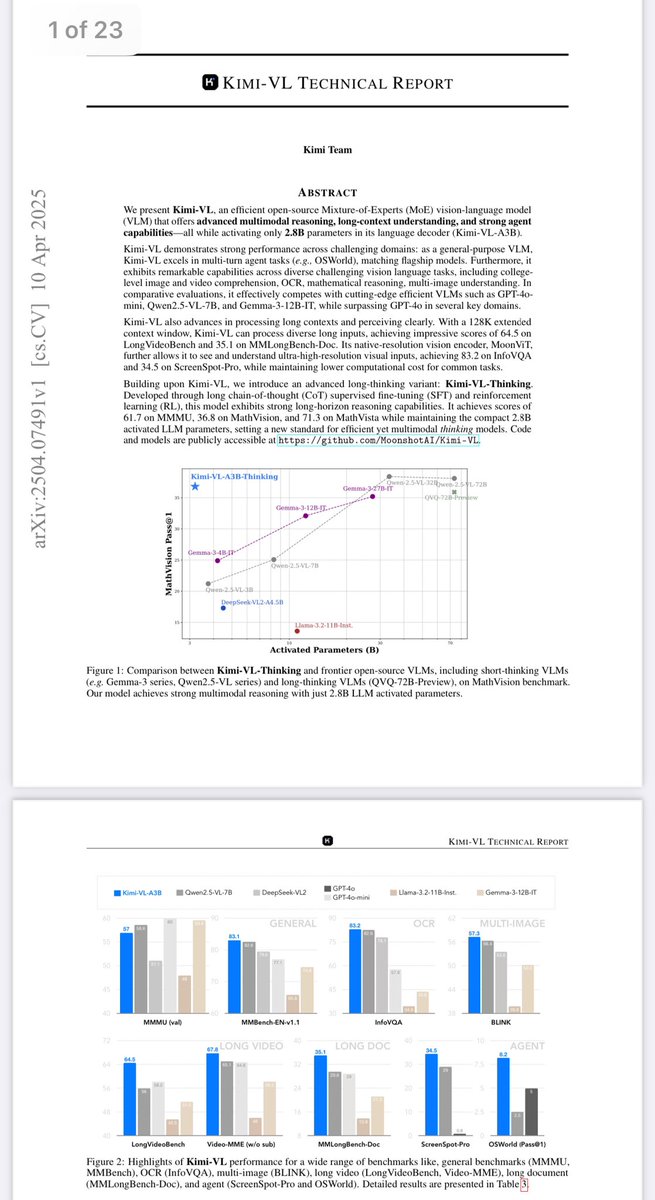
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000 tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100 files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on kimi.com in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code
-
🔗 API: platform.moonshot.ai
🔗 Tech blog: kimi.com/blog/kimi-k2-6
🔗 Weights & code: huggingface.co/moonshotai/Ki…

6
7
161
16,048
Apr 24
As long as K2.5/K2.6 is multimodal, we are also making it to use (I am really amazed by how it excels at long multi-image documents because we are not specially optimizing for them too much)
However still a long way to go

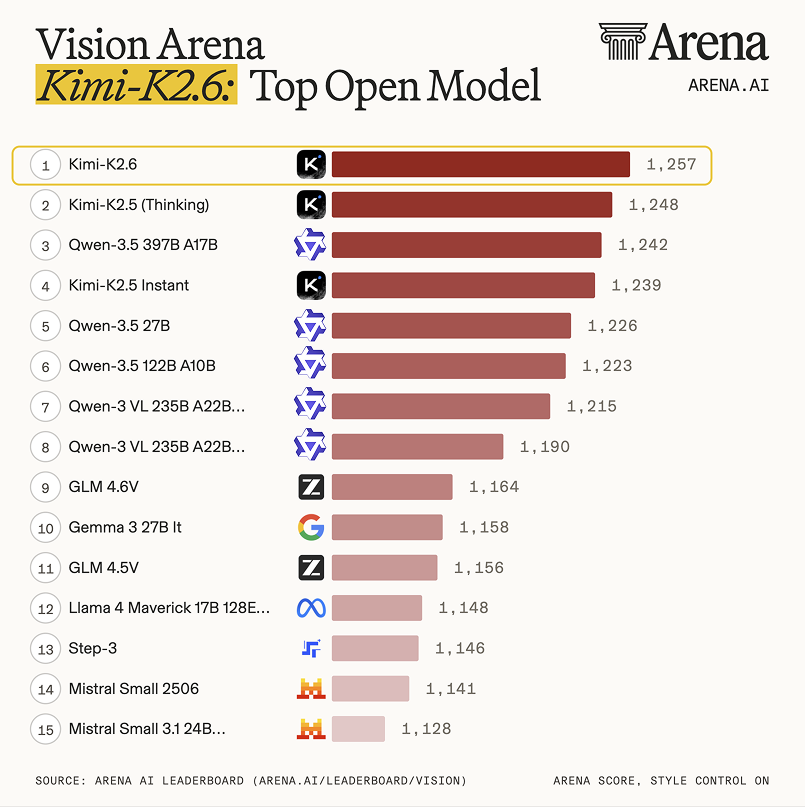
Kimi K2.6 is the new SOTA open model in Vision and Document Arena, with solid gains since Kimi K2.5:
- #1 open on Vision Arena (#15 overall), 14 over #2 Kimi K2.5 (Thinking)
- #1 open on Document Arena (#8 overall), 9 over K2.5 and on par with proprietary models like Muse Spark and Gemini 3.1 Pro.
Huge congrats again to the @Kimi_Moonshot team on the open source progress!
1
7
102
14,199
Apr 24
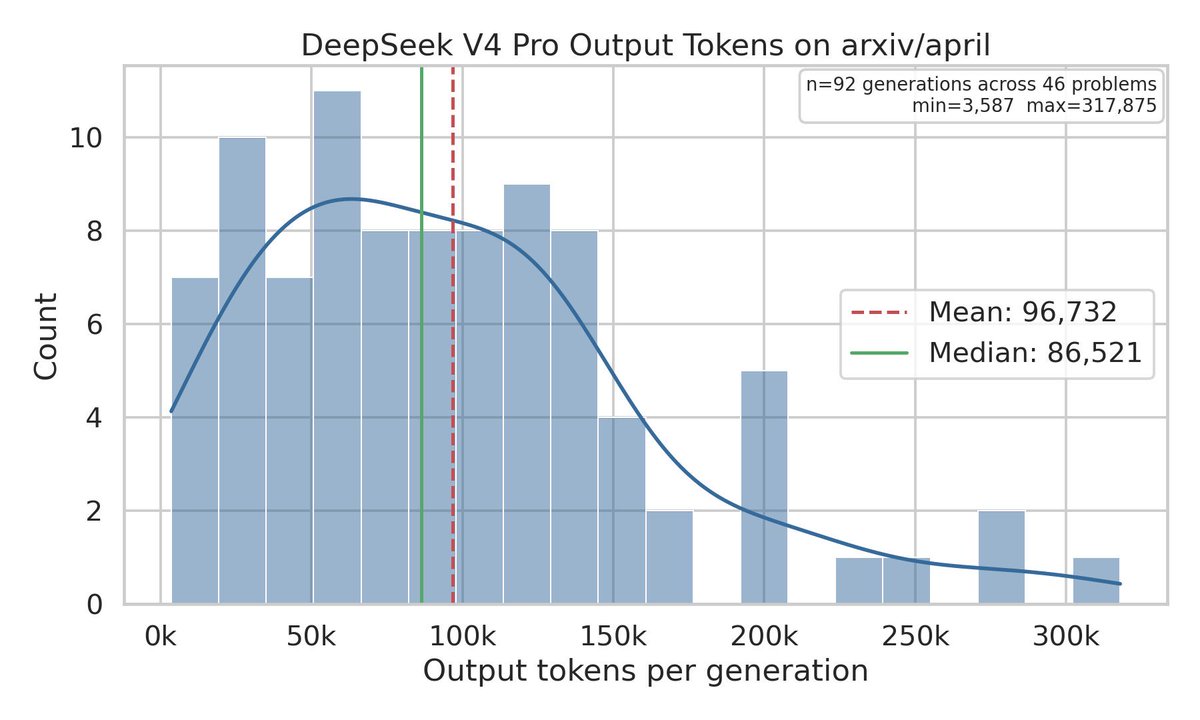
I think deepseek-v4 is not over-benchmaxxing, which is good.
We build these things for people to use.
14
36
1,138
44,854


Wu Haoning retweeted

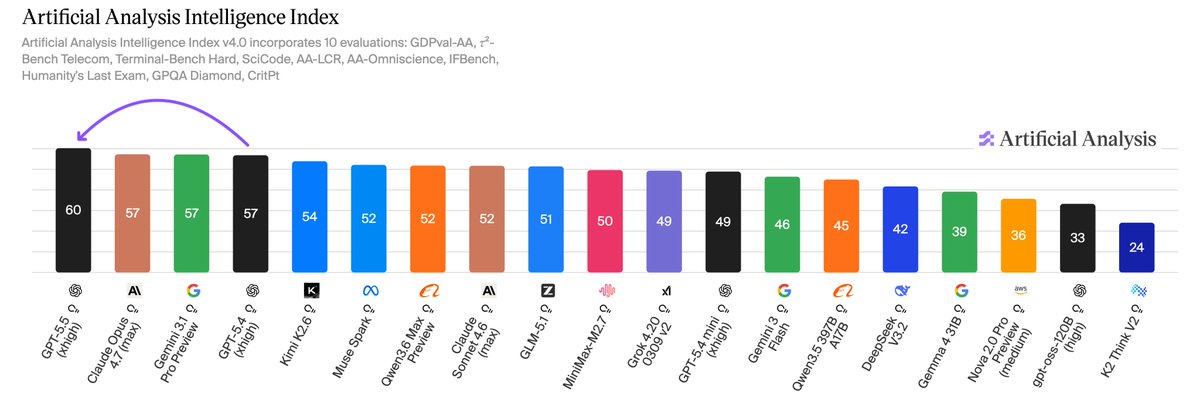
GPT-5.5 takes OpenAI back to the clear number one in AI. OpenAI’s new model tops the Artificial Analysis Intelligence Index by 3 points, breaking a three-way tie with Anthropic and Google
OpenAI gave us pre-release access to test all five reasoning effort levels: xhigh, high, medium, low and non-reasoning.
➤ OpenAI topping five headline evaluations: GPT-5.5 (xhigh) leads Terminal-Bench Hard, GDPval-AA and our newly hosted APEX-Agents-AA. The model trails only other OpenAI models in CritPt and AA-LCR, and comes second to Gemini 3.1 Pro Preview on three additional evaluations. The largest gains are on AA-Omniscience ( 14 pts), our knowledge and hallucination benchmark, and τ²-Bench Telecom ( 7 pts), a customer service agent benchmark.
➤ 20% more expensive to run our Intelligence Index: Per-token pricing has doubled from GPT-5.4 to $5/$30 per 1M input/output tokens. However, a ~40% token use reduction largely absorbs the hike - resulting in a net ~ 20% cost to run our Intelligence Index.
➤ Effort a clear ladder for balancing intelligence and cost: GPT-5.5 (medium) scores the same as Claude Opus 4.7 (max) on our Intelligence Index at one quarter of the cost (~$1,200 vs $4,800) - although Gemini 3.1 Pro Preview scores the same at a cost of ~$900. GPT-5.5 (low) approximates Claude Opus 4.7 (Non-reasoning, high) on our Intelligence Index at half the cost to run (~$500 vs ~$1 ,000).
➤ Number one in GDPval-AA with an Elo of 1785: GPT-5.5 (xhigh) leads Claude Opus 4.7 (max) by ~30 pts and Gemini 3.1 Pro Preview by ~470 pts. GDPval-AA is Artificial Analysis’ benchmark that leverages OpenAI’s GDPval dataset to evaluate models on real-world economically valuable tasks.
➤ Top AA-Omniscience accuracy, but trailing the frontier on hallucination: Our private AA-Omniscience benchmark rewards factual knowledge across diverse topics, but punishes hallucination. GPT-5.5 (xhigh) has the highest accuracy at 57% - meaning the model can recall facts in the Omniscience corpus more effectively than any other model. However, it has a hallucination rate of 86% - vs Opus 4.7 (max) at 36%, and Gemini 3.1 Pro Preview at 50%. This makes it more likely to answer a question when it does not ‘know’ the answer. The 14 pt gain in AA-Omniscience from GPT-5.4 (xhigh) was largely driven by knowledge, with a modest improvement in hallucination.
Congratulations to the team at @OpenAI and @sama on the launch
63
208
1,682
264,973
Apr 23
It becomes much smarter than previous generations!

1
25
1,186
Apr 23
Shall we be looking forward to V4 now? Serving the burst of K2.6 has made us GPU poor again now😂
2
220
Wu Haoning retweeted

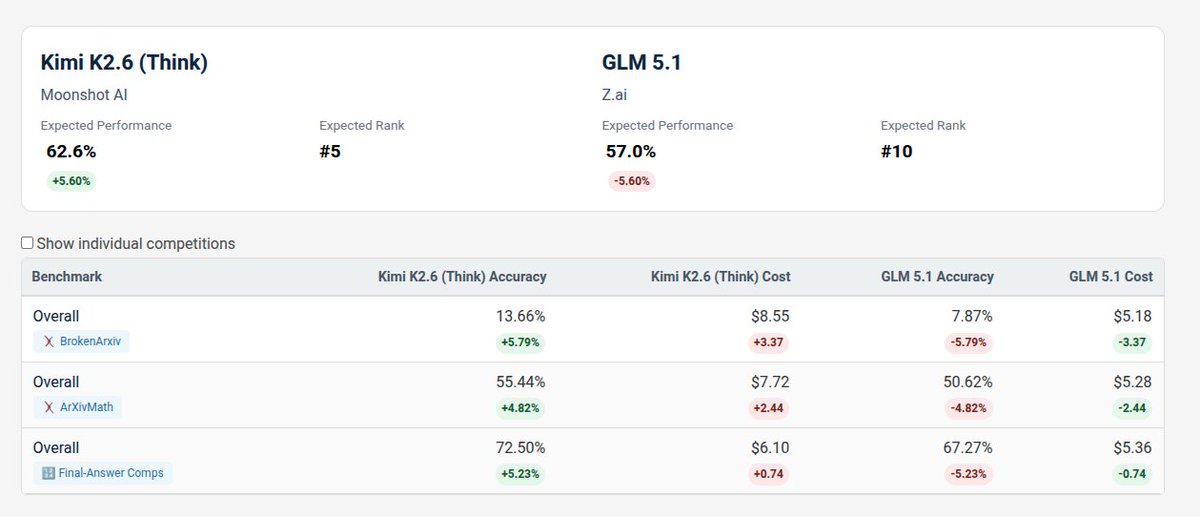
💥 Kimi-K2.6-thinking is the new best open-weight model on HalluHard (without web search)!
K2.5 had 76.9% hallucination rate, whereas K2.6 now has 63.6%. Since our benchmark contains hard hallucination cases, this improvement is very notable.
Thank you @Kimi_Moonshot for providing API credits and @dyfan22 for running the eval!
Full results: halluhard.com/
Paper: arxiv.org/abs/2602.01031

3
12
1,818
Apr 23
Looling forward to more open-source models on vision arena (但等等这玩意是open-source吗)
MiMo-V2.5 by @XiaomiMiMo is now live on Arena.
Evaluate it across Text, Vision & Code Arena - Pro versions available specifically in Text & Code.
Start prompting and voting in Battle mode. Scores incoming.

2
13
1,401

Kimi K2.6 by @Kimi_Moonshot is #8 in Document Arena.
Up 14 points over Kimi K2.5-Thinking, extending Kimi K2.6's lead as the #1 open model.

1
3
27
3,796