
PhD @uwaterloo • (prev) intern @DbrxMosaicAI @GoogleAI, RA @UKPLab • IR NLP research (beir.ai, miracl.ai, TREC-RAG and FreshStack)
Joined July 2016
- Tweets 1,732
- Following 3,352
- Followers 2,705
- Likes 18,267
172 Photos and videos











Pinned Tweet

May 6
My new Weaviate podcast from Argentina with a freshly brewed mate in hand!🧉🇦🇷
It's always fun to chat with @CShorten30: I talk about search agents, I'm amazed how this field has changed rapidly and share ORBIT findings & research ideas! 💚
May 5

How do we train and evaluate Search Agents? 👾🔎
I am SUPER EXCITED to publish a new episode of the Weaviate Podcast with Nandan Thakur (@beirmug) on Search Agents! 🎙️💚
Firstly, congratulations to Nandan who has just completed his Ph.D. at the University of Waterloo advised by Professor Jimmy Lin (@lintool)! 🎉
During this time, Nandan published several impactful works such as BEIR 🍻, MIRACL 🌍🙌🌏, FreshStack 🥞, and many more.
This podcast dives into his new work on ORBIT and the current state of Search Agents! ⚛️
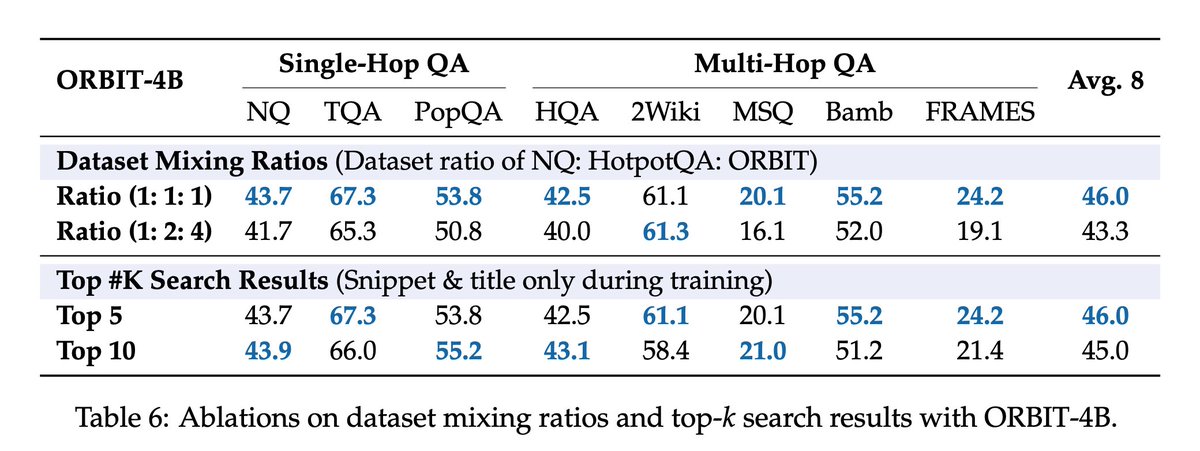
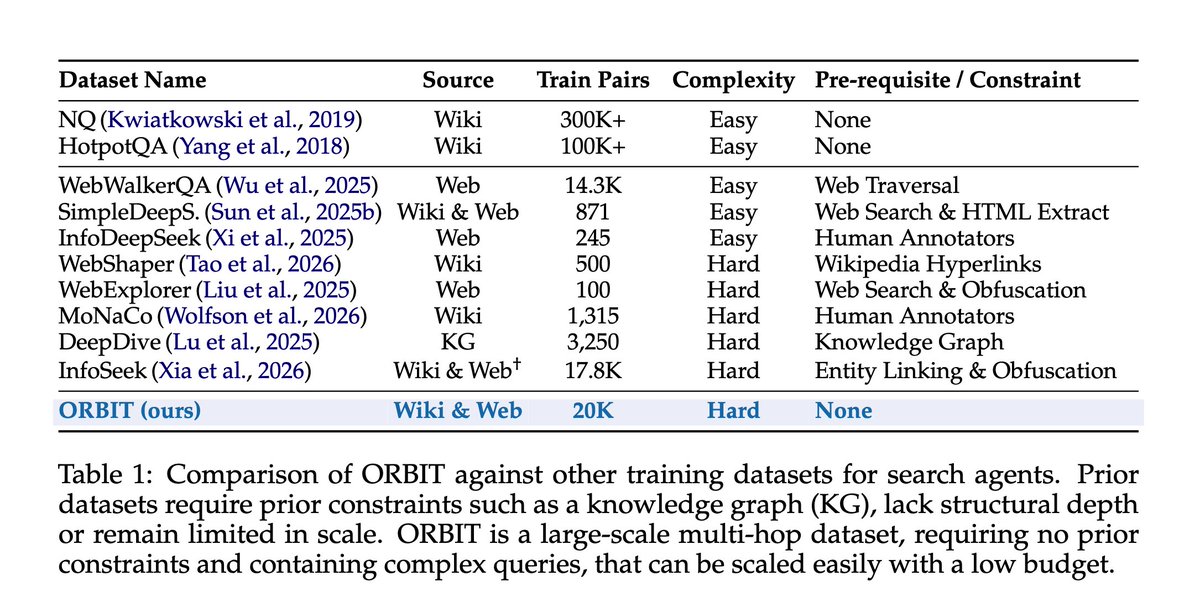
ORBIT contains 20K training examples, each one a complex, multi-hop question paired with a short verifiable answer. For example, "What was the runtime of the 2017 animated film set inside a smartphone, directed by..." (Answer: 86 minutes). 🎬
This dataset is used to train Search Agents on queries that require say 4 to 5 searches in order to answer.
The crazy part is that ORBIT was generated entirely without paid Web Search APIs! The entire pipeline runs on a 2018 Linux laptop driving DeepSeek's free chat interface! 💻♻️
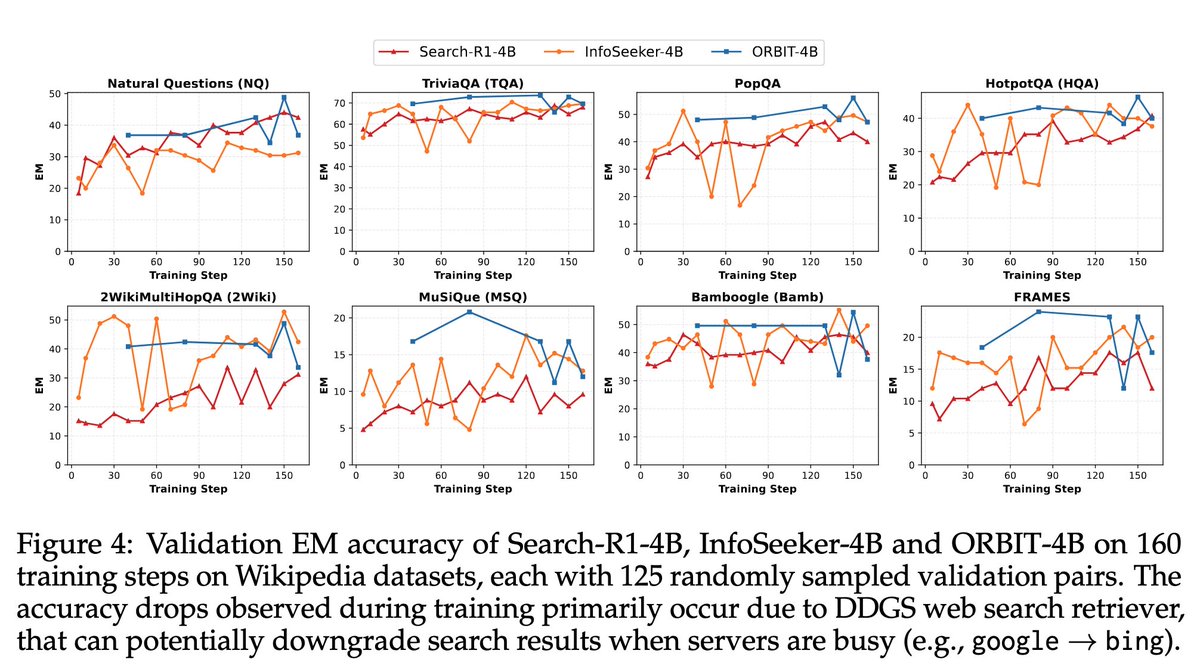
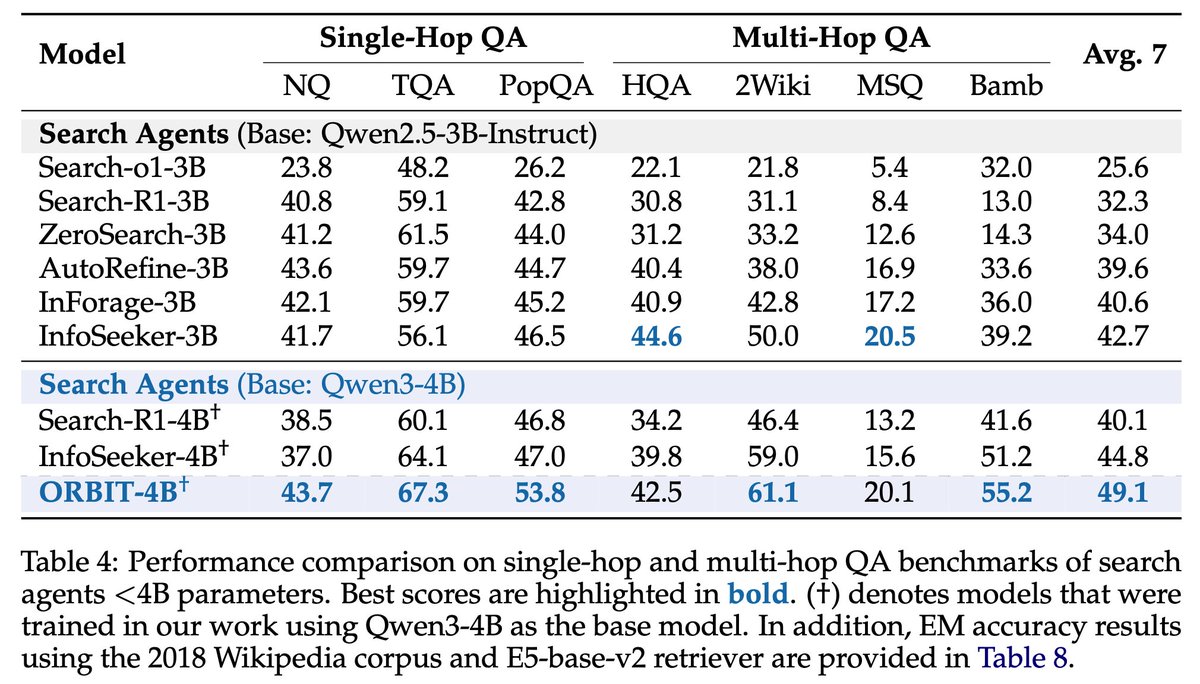
Trained on ORBIT, Qwen3-4B beats InfoSeeker-4B by 4.3 EM and Search-R1-4B by 9.0 EM across 7 Wikipedia QA benchmarks.
A lot of interesting nuggets in this one! As always, I hope you find it useful and happy to discuss further! 👋

2
7
33
3,233
Nandan Thakur retweeted

Jun 13
Really excited to open source a new project: Omnigent, a meta-harness for AI agents.
It lets you build multi-agent coding and custom agents, sitting above Claude Code, Codex, Pi, and agent SDKs to let you compose them. It also adds live collaboration and rich control policies.

73
182
1,008
164,999
Nandan Thakur retweeted

Jun 9
A message to Anthropic leadership: You're not special. Making sure AI goes well is a team effort not a "you effort."
46
149
2,340
101,157
Jun 9
New developments are happening this year at TREC-RAG! 🎉🎉
Jun 4

It’s incredibly rewarding to see ClimbMix become part of TREC RAG 2026.
The question of “did the model retrieve it, or did it already know it?” sits at the heart of modern RAG evaluation. Better controlled datasets and benchmarks are an important step toward answering that question scientifically.
Excited to see where this goes 🚀
8
983

🎉 Happy to see @mattjustram joining @mixedbreadai and @rpradeep42 joining @DbrxMosaicAI - grep is all you need? ❌ bm25 is all you need? ❌ both wrong - talent is all you need ✅
5
4
46
4,623
Nandan Thakur retweeted

Jun 8
personal update:
happy to share that i've joined @mixedbreadai 🍞 as a member to work on technical stuffs & agents & search!
too happy to meet so many great bakers and working on exciting projects, so i missed the perfect timing (June 1st, Mon) to say this :P
14
4
62
5,769
Jun 8
I just read this blog today and I am deeply concerned about this!
I've thought a lot about how modern day learning/teaching can get stalled due to agents, that can code up projects within minutes.
I recommend learning the basics, reading papers, and understanding the code...
3
11
1,056
Nandan Thakur retweeted

Jun 2
By now, everyone knows that single-vector embedding models are hugely limiting for modern workflows.
But they contain than you think: you can extract sparse Latent Terms from them.
And it turns out that BM25 is all you need to turn this vocabulary into a strong retriever.
6
24
196
39,697
Nandan Thakur retweeted

May 30
Very excited to finally share this one after sitting on it for far too long! It's very topical now. Blog post coming very soon :)
May 29

Latent Terms: Dense Retrievers Contain Trivially Extractable BM25-ready Zipfian Vocabularies
@bclavie et al. extract indexable, BM25-ready sparse features from frozen dense retrievers using reconstruction-trained Sparse Autoencoders.
📝 arxiv.org/abs/2605.29384
9
15
88
13,248
Nandan Thakur retweeted

May 27
Grateful that my PhD thesis was recognized as one of the top dissertations in the 2026 Faculty of Mathematics Doctoral Prize at the @UWaterloo ! 🎉
And it is always especially nice to hear kind words from your PhD supervisor @claclarke . I guess that feeling never really goes away, even after you graduate. 😊
uwaterloo.ca/computer-scienc…
7
5
95
6,864
Nandan Thakur retweeted

May 15
Does retrieval help RAG or did the LLM already memorize the answer? 🤔 Too often, the overlap between RAG corpora and what LLMs “know” is unclear
Better RAG evaluation needs tighter alignment between NLP and IR
📚 That's why for RAG 2026 we are using @nvidia's ClimbMix corpus
15
7
20
6,763
Nandan Thakur retweeted

What is a Search Agent? 👾🔎
Here is a clip from our latest Weaviate Podcast discussing what separates Deep Research from Search Agents! 👇
May 5
How do we train and evaluate Search Agents? 👾🔎
I am SUPER EXCITED to publish a new episode of the Weaviate Podcast with Nandan Thakur (@beirmug) on Search Agents! 🎙️💚
Firstly, congratulations to Nandan who has just completed his Ph.D. at the University of Waterloo advised by Professor Jimmy Lin (@lintool)! 🎉
During this time, Nandan published several impactful works such as BEIR 🍻, MIRACL 🌍🙌🌏, FreshStack 🥞, and many more.
This podcast dives into his new work on ORBIT and the current state of Search Agents! ⚛️
ORBIT contains 20K training examples, each one a complex, multi-hop question paired with a short verifiable answer. For example, "What was the runtime of the 2017 animated film set inside a smartphone, directed by..." (Answer: 86 minutes). 🎬
This dataset is used to train Search Agents on queries that require say 4 to 5 searches in order to answer.
The crazy part is that ORBIT was generated entirely without paid Web Search APIs! The entire pipeline runs on a 2018 Linux laptop driving DeepSeek's free chat interface! 💻♻️
Trained on ORBIT, Qwen3-4B beats InfoSeeker-4B by 4.3 EM and Search-R1-4B by 9.0 EM across 7 Wikipedia QA benchmarks.
A lot of interesting nuggets in this one! As always, I hope you find it useful and happy to discuss further! 👋
1
7
10
1,168
Nandan Thakur retweeted

May 6
I’ve never been this excited about search.
6-7 years ago, IR got an influx of the paradigms we still use, all enabled by the big headroom MS MARCO and then BEIR created. Then progress slowed.
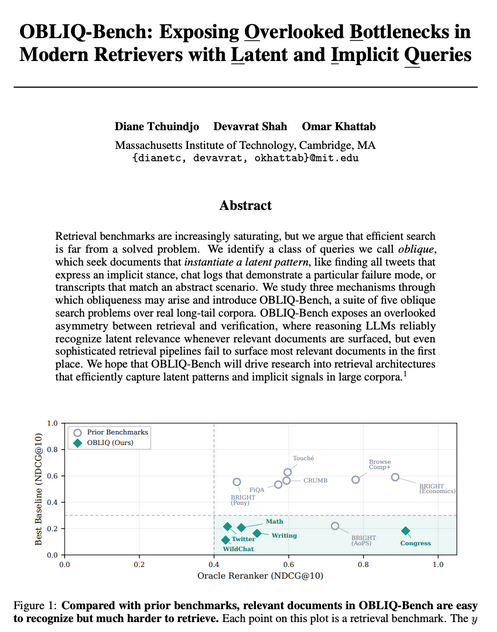
Today, Diane releases perhaps the most ambitious IR benchmark to date: OBLIQ-Bench.
Queries in it are meant to be increasingly opaque to current first-stage retrieval paradigms. Oblique queries put the bottleneck very early in the search process, as the relevance of a document to the query is quite latent.
I can't wait for core IR research on fundamentally more powerful paradigms for first-stage search to be reignited again. Stay tuned for more stories about this, and read Diane's thread and her paper below!!

We set out to build a better retriever, so we looked for the hardest IR benchmarks.
For each, we asked how much headroom remained by running oracle reranking with a frontier LLM. Most had little room left!
So we built OBLIQ-Bench to study much harder search queries than before.
8
44
360
39,508
May 6
My new Weaviate podcast from Argentina with a freshly brewed mate in hand!🧉🇦🇷
It's always fun to chat with @CShorten30: I talk about search agents, I'm amazed how this field has changed rapidly and share ORBIT findings & research ideas! 💚
May 5
How do we train and evaluate Search Agents? 👾🔎
I am SUPER EXCITED to publish a new episode of the Weaviate Podcast with Nandan Thakur (@beirmug) on Search Agents! 🎙️💚
Firstly, congratulations to Nandan who has just completed his Ph.D. at the University of Waterloo advised by Professor Jimmy Lin (@lintool)! 🎉
During this time, Nandan published several impactful works such as BEIR 🍻, MIRACL 🌍🙌🌏, FreshStack 🥞, and many more.
This podcast dives into his new work on ORBIT and the current state of Search Agents! ⚛️
ORBIT contains 20K training examples, each one a complex, multi-hop question paired with a short verifiable answer. For example, "What was the runtime of the 2017 animated film set inside a smartphone, directed by..." (Answer: 86 minutes). 🎬
This dataset is used to train Search Agents on queries that require say 4 to 5 searches in order to answer.
The crazy part is that ORBIT was generated entirely without paid Web Search APIs! The entire pipeline runs on a 2018 Linux laptop driving DeepSeek's free chat interface! 💻♻️
Trained on ORBIT, Qwen3-4B beats InfoSeeker-4B by 4.3 EM and Search-R1-4B by 9.0 EM across 7 Wikipedia QA benchmarks.
A lot of interesting nuggets in this one! As always, I hope you find it useful and happy to discuss further! 👋
2
7
33
3,233
May 6
Here is the link to the original ORBIT post discussed in the podcast: x.com/i/status/2041168415914…
Apr 6

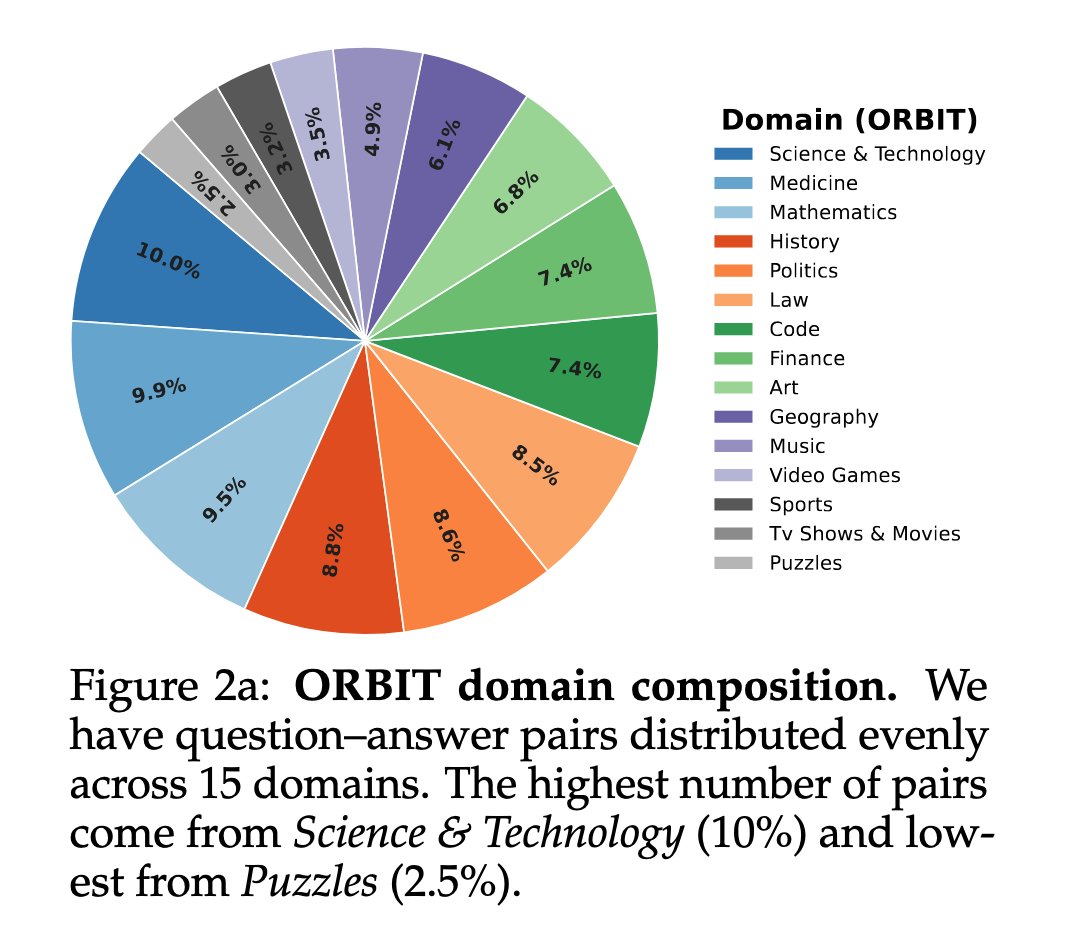
Introducing ⚛️ORBIT, a 20K reasoning-intensive web training dataset for search agents frugally generated without relying on paid APIs. Small (<4B) search agents trained with ORBIT outperform others by up to 9.0 EM accuracy on single & multi-hop Wikipedia QA. 🧵
1
5
410
Nandan Thakur retweeted

May 5
YouTube: youtu.be/B71WF6EtgK8
Spotify: spotifycreators-web.app.link…
1
7
430
Nandan Thakur retweeted
May 5
How do we train and evaluate Search Agents? 👾🔎
I am SUPER EXCITED to publish a new episode of the Weaviate Podcast with Nandan Thakur (@beirmug) on Search Agents! 🎙️💚
Firstly, congratulations to Nandan who has just completed his Ph.D. at the University of Waterloo advised by Professor Jimmy Lin (@lintool)! 🎉
During this time, Nandan published several impactful works such as BEIR 🍻, MIRACL 🌍🙌🌏, FreshStack 🥞, and many more.
This podcast dives into his new work on ORBIT and the current state of Search Agents! ⚛️
ORBIT contains 20K training examples, each one a complex, multi-hop question paired with a short verifiable answer. For example, "What was the runtime of the 2017 animated film set inside a smartphone, directed by..." (Answer: 86 minutes). 🎬
This dataset is used to train Search Agents on queries that require say 4 to 5 searches in order to answer.
The crazy part is that ORBIT was generated entirely without paid Web Search APIs! The entire pipeline runs on a 2018 Linux laptop driving DeepSeek's free chat interface! 💻♻️
Trained on ORBIT, Qwen3-4B beats InfoSeeker-4B by 4.3 EM and Search-R1-4B by 9.0 EM across 7 Wikipedia QA benchmarks.
A lot of interesting nuggets in this one! As always, I hope you find it useful and happy to discuss further! 👋
5
15
45
10,259
Nandan Thakur retweeted
Weaviate Podcast #137 is live! Search Agents! 🎉
Here is an overview of chapters covered in the podcast 📜

May 5
How do we train and evaluate Search Agents? 👾🔎
I am SUPER EXCITED to publish a new episode of the Weaviate Podcast with Nandan Thakur (@beirmug) on Search Agents! 🎙️💚
Firstly, congratulations to Nandan who has just completed his Ph.D. at the University of Waterloo advised by Professor Jimmy Lin (@lintool)! 🎉
During this time, Nandan published several impactful works such as BEIR 🍻, MIRACL 🌍🙌🌏, FreshStack 🥞, and many more.
This podcast dives into his new work on ORBIT and the current state of Search Agents! ⚛️
ORBIT contains 20K training examples, each one a complex, multi-hop question paired with a short verifiable answer. For example, "What was the runtime of the 2017 animated film set inside a smartphone, directed by..." (Answer: 86 minutes). 🎬
This dataset is used to train Search Agents on queries that require say 4 to 5 searches in order to answer.
The crazy part is that ORBIT was generated entirely without paid Web Search APIs! The entire pipeline runs on a 2018 Linux laptop driving DeepSeek's free chat interface! 💻♻️
Trained on ORBIT, Qwen3-4B beats InfoSeeker-4B by 4.3 EM and Search-R1-4B by 9.0 EM across 7 Wikipedia QA benchmarks.
A lot of interesting nuggets in this one! As always, I hope you find it useful and happy to discuss further! 👋
1
5
3
534
May 6
Haha, I think I can't emphasize enough that I think compute/funding should not limit us in academia.
In ⚛️ ORBIT, i found that a single Linux laptop running non-stop for months is enough to generate a pretty good dataset, you don't need expensive APIs!

1
2
6
1,274
