
works on ZK, prev mir
Joined October 2018
- Tweets 575
- Following 870
- Followers 8,276
- Likes 3,866
25 Photos and videos














Brendan Farmer retweeted

Jun 13
Two days ago, we announced Plonky3 v0.6.0 and hinted at cool improvements for Circle STARK.
The reality? We just made Circle STARK over M31 *𝑓𝑙𝑦* in Plonky3 ⚡
No new hardware, just math and engineering giving us 2.3x faster prover at higher security! 🚀
Jun 11

🔥 WHIR has landed in Plonky3 🔥
We just released v0.6.0, and with it we open the door to the world of multilinear PCS! 🚀
We've also shipped a ton of cool new features and performance improvements.
👀 Spoiler alert: Circle STARK is now *really* fast.
github.com/Plonky3/Plonky3
1
2
30
1,916
Brendan Farmer retweeted

Jun 12
SHA-256, BLAKE3, Poseidon, Keccak

8
13
123
15,937
Brendan Farmer retweeted

May 24
more people should know @kevaundray
and for that matter the others doing the zkevm work (including those outside EF)
(Justin is of course great, but I've mentioned justin being great many times already😄)
42
16
331
51,941

May 21
An interesting part of this is that if you look at the CoT summary, the model primarily focuses on finding a counterexample to the conjecture instead of proving it. There are maybe two explanations for this:
1. The model has superhuman mathematical intuition relative to generations of mathematicians who assumed that the conjecture must be true.
2. The model believes that it is more likely to solve the problem by finding a counterexample (in the case that the conjecture is false): P(success | false) > P(success | true) and is trying to maximize the number of problems that it solves.
(2) is plausible because the model is very good at searching the solution space using moves provided by existing techniques. Would be interesting to see if models outperform in finding counterexamples and generally prefer that approach when tackling conjectures.

14
2
60
9,392

This is a gem! A commitment scheme you can open in any field you want. Arithmetization mixing different fields, and even integers and rationals! Ideal-check as a generalization of zero-check. I can’t wait to apply all of this.
Huge congrats to @0xAlbertG et al.!

Introducing Zinc , where we tackle the problem of arithmetizing and proving computations unfriendly to finite fields.
Examples: classic hashes, hash signature, lattice ops., etc.
We prove 7 SHA-256 compressions followed by the ECDSA MSM with:

3
11
71
4,836
Brendan Farmer retweeted

Apr 28
We’ve just merged WHIR into Plonky3: github.com/Plonky3/Plonky3/p…
I have a few ideas for improvements and next steps.
Let’s improve performance and usability.
2
10
67
5,995
Brendan Farmer retweeted

Apr 24
Finally, and with some delay, the counter example of Dmitry Krachun and Stepan Kazanin is public:
eprint.iacr.org/2026/782
I am honored to have had the chance to work with such extremely talented mathematicians. We eventually stumbled about a simplified proof, which does not use any additive combinatorics.
3
12
64
3,653
Apr 20
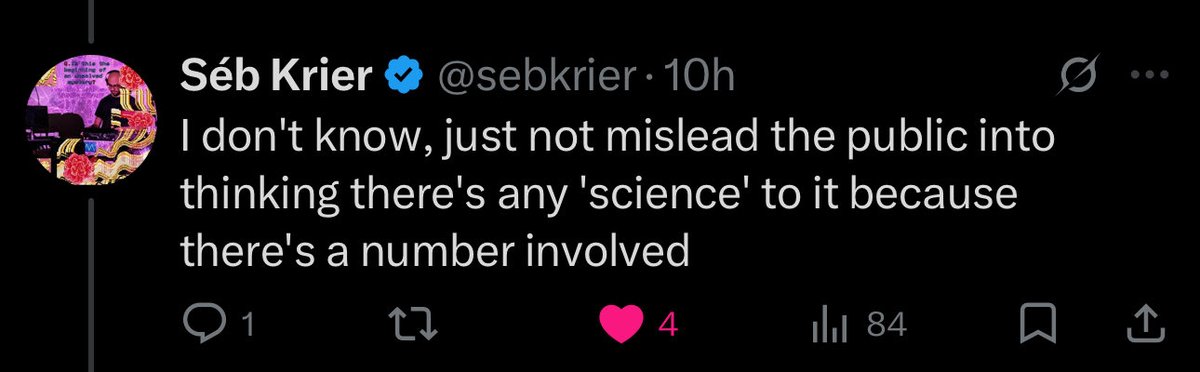
Strongly agree. This was one of the most striking things about reading the SBF books/articles - he would arbitrarily assign probabilities to events or payoffs based on absolutely nothing, and sort of hilariously he would do so to a degree of precision (XY%) that made no sense.

Agree with this by @sebkrier
There is a kind of pseudoscience of ascribing probabilities to highly speculative futures without any real basis

2
2
9
3,944
Apr 20
The China open model thing was interesting as well. Couldn't help but wonder if Jensen sees open models as strategic for pricing power vs labs / commoditizing the complement
Apr 18

put together a clip that better expresses jensen v dario by proxy
dario is speaking from a recent fox segment
jensen is speaking from the dwarkesh podcast
2
647
Apr 20
My initial reaction to this was to rage out and point out that canonical bridges would've averted the exploit -
- but I think Doug's right. Even if you believe that L2s are the correct longterm architecture, the roadmap itself was poorly conceived.
To give an example, leading optimistic rollups were enforcing a 7-day withdrawal delay and making their users pay for DA on Ethereum...when they either had no proofs or a permissioned validator set. 🤦♂️
To be very clear: this is no longer the case, these teams are very talented and they deserve a ton of credit for solving genuinely hard engineering problems. My criticism is directed at "alignment" and how arbitrary it's always been.
Apr 19

Can’t help but reflect on how much of this mess is a downstream consequence of the rollup centric roadmap and misconceptions promulgated in the interest of “alignment”.
For years users were told:
- “L2s are just Ethereum”. Except when shit hits the fan we learn L2 assets are very much junior to mainnet
- “Rollups share a security zone”. Only if you use the canonical bridge… which nobody does because the roadmap was launched when the tech was unusable 7 day bridges.
- “Every app needs their own chain”. An explosion of marginal chains exposing a huge surface area of often barely maintained infra. The hack started on a chain with just 47 rsETH. Why does that chain exist?
- “Ethereum is the world’s most economically secure asset”. Now we have a million restaking wrappers each with their own vulnerability surface, many treated as secure as ETH. All to support barely any demand
1
10
1,609
Apr 19
Is the computational functionalism argument being used by ML and CS people actually serious? Is there an argument or does it just ignore the hard problem by asserting that mental states are computational states?
I think there are actually interesting arguments against computational functionalism, but it seems like the positive argument for it doesn't really engage with the philosophy of mind literature from the past 50 years.
1
4
948
Apr 10
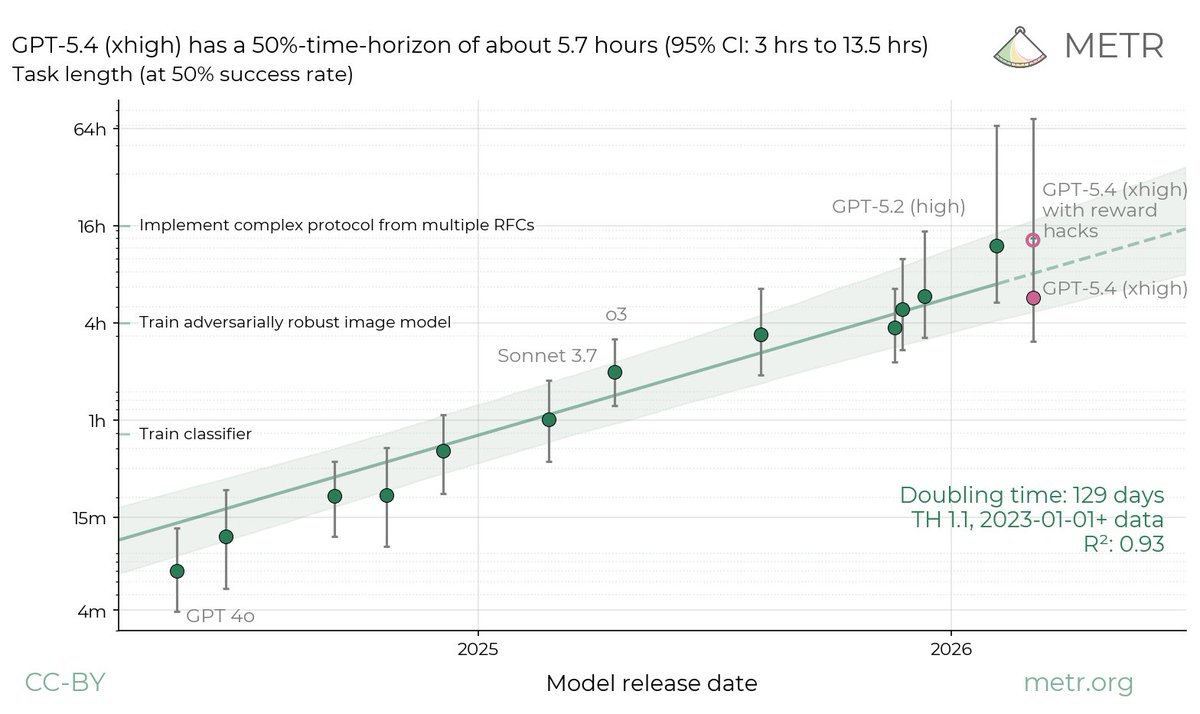
I think Opus 4.6 overperformance and GPT-5.4 underperformance should be read as failures of the benchmark. imo citing the METR doubling timeline is statistically illiterate.
If you look at the task distribution wrt duration, assignment of duration doesn't seem rigorous, there aren't enough long-duration tasks, there's bias in how tasks are constructed (clustered around particular skills/capabilities) and the eval is susceptible to benchmaxxing. I'm not a statistician, but it's unclear to me that logistic regression is appropriate.
I think it's a useful measure of whether models are improving, but improved scores indicate improvements in specific skills/capabilities, not reliability as a function of duration.
Apr 10

We ran GPT-5.4 (xhigh) on our tasks. Its time-horizon depends greatly on our treatment of reward hacks: the point estimate would be 5.7hrs (95% CI of 3hrs to 13.5hrs) under our standard methodology, but 13hrs (95% CI of 5hrs to 74hrs) if we allow reward hacks.
1
5
862
Mar 20
This post reminds me that I don't understand the economics of frontier labs.
Inference is a low-margin business to begin with, and OpenAI and Anthropic must continuously invest huge amounts in R&D compute to maintain pricing power (if cheaper open-source models catch up, frontier labs' margins should approach zero).
This is made worse because training cost increases superlinearly, so labs are caught in a rapidly compressing window as open source models catch up on one side, while the amount of capital/compute/electricity required to meaningfully improve models goes vertical on the other.
MSFT and GOOG are ~zero-marginal-cost, high-growth, cash-generating businesses valued at 20-30x earnings. It's unclear that labs should even command 20-30x earnings, much less infinity-x earnings and 30x ARR.
Seems pretty clear privates are overpriced.
Mar 19

One of these two groups is mispriced
Private AI labs: OpenAI valued around $840B, Anthropic north of $600B on secondaries. Both at 30x ARR.
Public giants: Microsoft at ~$3T on 23x forward earnings. Amazon at ~$2.3T on 28x.
Microsoft likely owns ~25% of OpenAI. Amazon likely owns ~15% of Anthropic and ~5% of OpenAI
If private investors are pricing these labs for a $5T venture-style outcome then…
Microsoft’s implied stake in a $5T OpenAI is $1.25T embedded inside a $3T company. Amazon’s combined stakes embed roughly $1T inside a $2.3T company.
Publics too cheap on Al exposure? Or privates/secondaries in bubble territory? Which breaks first?
3
8
1,887
Mar 20
“Inference is low-margin” is maybe not quite right. Inference is low-margin relative to zero-marginal-cost software businesses, but it’s plausible that compute profit margins can be robust for inference (especially as hardware improves).
OAI cited a 70% compute margin in 2025, but this is based on a blend that includes monthly subscriptions with low usage. No lab, afaik, has released a per-token API profit margin.
Margins are more complicated for inference vs widgets in a factory because R&D spend is so high (and increasing superlinearly). R&D is a mandatory continuing cost to retain usage.
I don’t think it’s quite right to say that frontier labs have an amazing business, compared to, say, producing widgets in a factory, because margins are (guessing) 33%, given the structure of the business.
Also, as models rely increasingly on TTC, does this meaningfully reduce compute margins?
170
Mar 17
Assume this is bait,
but "great men sitting around moaning about their feelings" is basically as old as western civilization. See Achilles in the Iliad sitting around moaning about his wounded pride and grief.
It's difficult to find great men and women of the past who *didn't* write letters moaning about their feelings.
Mar 16

It is 100% true that great men and women of the past were not sitting around moaning about their feelings. I regret nothing.
2
2
15
1,720
Brendan Farmer retweeted
Mar 10
🚀 New Plonky3 release just dropped.
This is probably our most impactful and ambitious release so far:
- MUCH faster lookups
- High-arity folding
- N-ary Merkle trees Merkle caps
- Major Poseidon2 optimizations
- Poseidon1 support
- And many more…
Let’s break it down 👇
4
31
133
8,528
Feb 25
Hegseth [yelling]: and if you won't train WarClaude... we have an effective altruist who will.
2
7
468
Feb 24
Dario has claimed that inference revenue exceeds training cost for Anthropic's models, so training yields a positive return on investment.
I'm curious whether "training cost" refers to the final run or total R&D compute cost (up to ~4-5x greater, includes experiments, failed runs, etc).
It's definitely the case that Anthropic has negative cashflows and this is mainly because training cost for the next model is increasing at a high rate, but I'm curious whether there's positive ROI on total R&D compute spend for current models.
1
3
586
Feb 21
I was randomly thinking about this exact example, that it's somewhat easy (though impressive) to imagine LLMs proving isolated lemmas in math, or coding.
I think it's harder to imagine an LLM spontaneously picturing itself in an elevator accelerating to the speed of light, and then formulating GR. Conceptual creativity like this seems really difficult to capture via training.

Demis Hassabis just defined the real test for AGI. It’s more brutal than anyone expected.
Train AI on all human knowledge. Cut it off at 1911. See if it independently discovers general relativity like Einstein did in 1915.
If it can, we have AGI. If not, we’re still building pattern matchers.
Hassabis: “My definition of AGI has never changed. A system that can exhibit all the cognitive capabilities that humans can.”
Not bar exams. Not coding competitions. All cognitive capabilities.
Hassabis: “The brain is the only existence proof we have, maybe in the universe, of a general intelligence.”
That’s why DeepMind studies neuroscience. Not for inspiration. For data. The human brain is the only confirmed evidence that general intelligence is physically possible.
If you want to build it, you study the only example that exists.
Hassabis: “True creativity, continual learning, long-term planning. They’re not good at those things.”
Current systems are impressive and broken simultaneously.
Hassabis: “They can get gold medals in international math olympiad questions, but they can still fall over on relatively simple math problems if you pose it in a certain way.”
Jagged intelligence. Brilliant in narrow domains. Incompetent when approached differently.
That inconsistency is the tell. A true general intelligence doesn’t spike in one direction and collapse in another.
The Einstein test cuts through all of it. No benchmarks. No leaderboards. No carefully curated evals.
Just a model, a knowledge cutoff, and the question of whether it can do what one human did alone in 1915.
Hassabis: “Training an AI system with a knowledge cutoff of 1911 and seeing if it could come up with general relativity like Einstein did in 1915. That’s the true test of whether we have a full AGI system.”
Current models can’t. They remix brilliantly. They don’t generate paradigm-shifting theories from first principles.
Hassabis: “I think we’re still a few years away from that.”
A few years. Not decades.
The system that can be Einstein once can be Einstein a thousand times simultaneously across every domain.
That’s not AGI anymore. That’s the beginning of something we don’t have words for yet.
When that test gets passed, we won’t need a press release to know what happened.
3
7
1,270