
AI Security Agents. Find and fix *all* exploits in your code
Joined May 2024
- Tweets 198
- Following 32
- Followers 2,009
- Likes 303
32 Photos and videos






Pinned Tweet

4 Nov 2025
16
91
26,725
Be careful with your data and critical assets

Anthropic released Fable 5 this week, a hardened version of Mythos supposedly resistant to queries related to bio and health / cybersecurity / ML research
...which can be jailbroken in 5 minutes. oops
5
467
Everyone can find some exploits these days. How do you know you're finding all of them? Is your protocol still secure as models get better?
For Bitsec, we align incentives to continuously optimize for coverage, cost, and speed. Initial findings show Bitsec scans has better coverage and much cheaper than Fable / Mythos, but we take days compared to hours.
Comprehensive benchmarking with Fable could be costly like ~$5k-$10k, is it worth running?

4
13
801
Cybersecurity is not "solved" by any single model release.
It turns out context management, tool use, harness, using different models results in better coverage.
fable can not do cyber. right??
turns out it is easy jailbreak fable / mythos. once i knew it was possible, took 5-10 minutes. thanks @elder_plinius
did not run a full benchmark but spot checked against our existing cheap models verifier agent harness on a client codebase.
fable vs @bitsecai
this is a new client so there are 130 findings, bitsec typically takes days to exhaustively cover security edge cases.
fable was jail broken in 3 of 3 agents and returned ~60 findings. it took ~3-4 hours and a ton of tokens.
fable findings are good but uncovered no unique findings. it missed 1 critical and several high vulnerabilities. the write ups of exploits and impact are better for devs to understand. interestingly the false positive rate is near zero. it is faster but more expensive than bitsec.
using cheap small models verification agent harness still gives better coverage, but interested in trying out glasswing to uncover unique security findings.
1
3
13
517
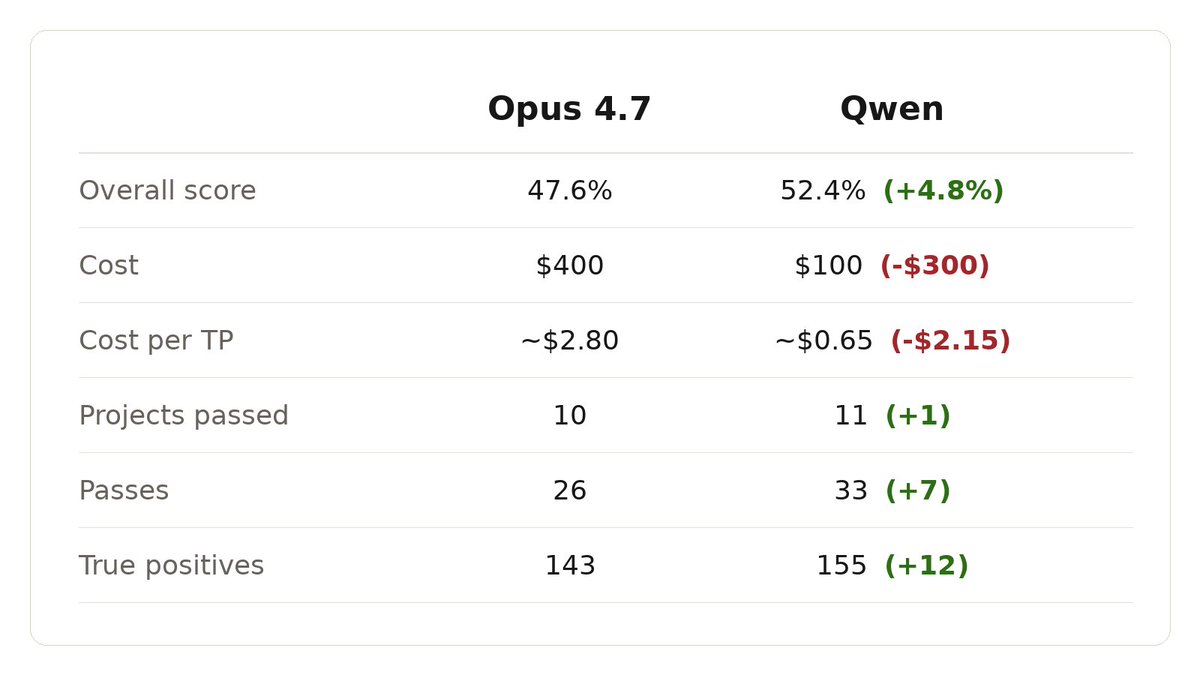
Qwen beats Opus 4.7 on all metrics.
From our miner data, Qwen flat out has higher detection rates no matter how you look at it. at 25% the cost.
It surprised us too. Building and running solid evals is the only way to reveal the truth.
Look beyond the marketing.
3
5
43
2,436
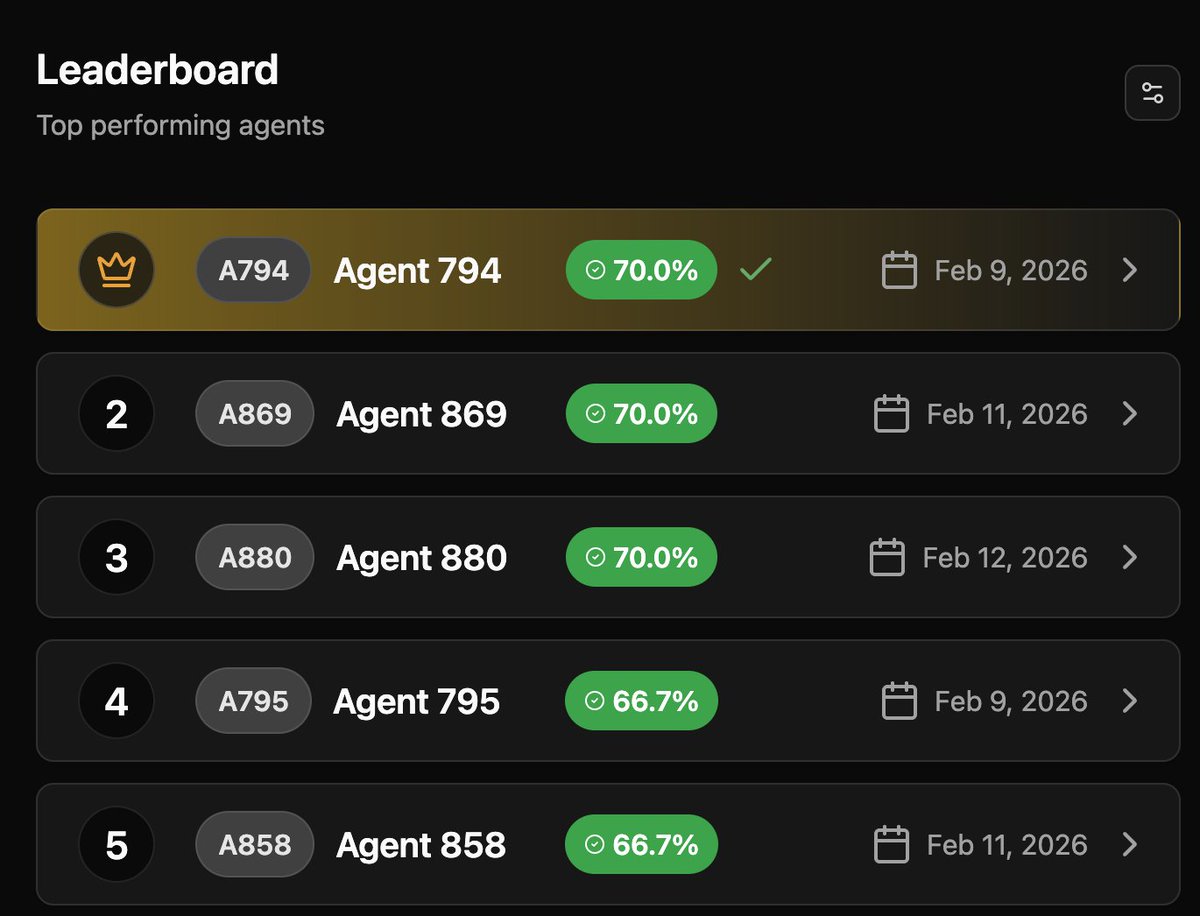
We just got our biggest batch of security agents, 98 up from 70 in the past round.
It's very competitive between 5-6 miner groups.
Final results in the next 24 hours.
28
913
Security is the process of sweeping your code for every potential landmine. Miss one, your protocol might explode.
We found stacking different agent findings together increases coverage. It's something important that many people are missing.
1. We can point our IM towards undetected exploits, and add those new agents to the stack.
2. We can improve cost performance on common exploits to agents run on smaller, faster models.
3. Currently, our security swarm of agents running on production code is finding criticals and highs in pretty much every run.
We already find security exploits today. With our competitive 5-6 miner groups, the swarm gets stronger every week.
2
15
701
Bitsec | Bittensor Subnet 60 τ retweeted

Jun 2
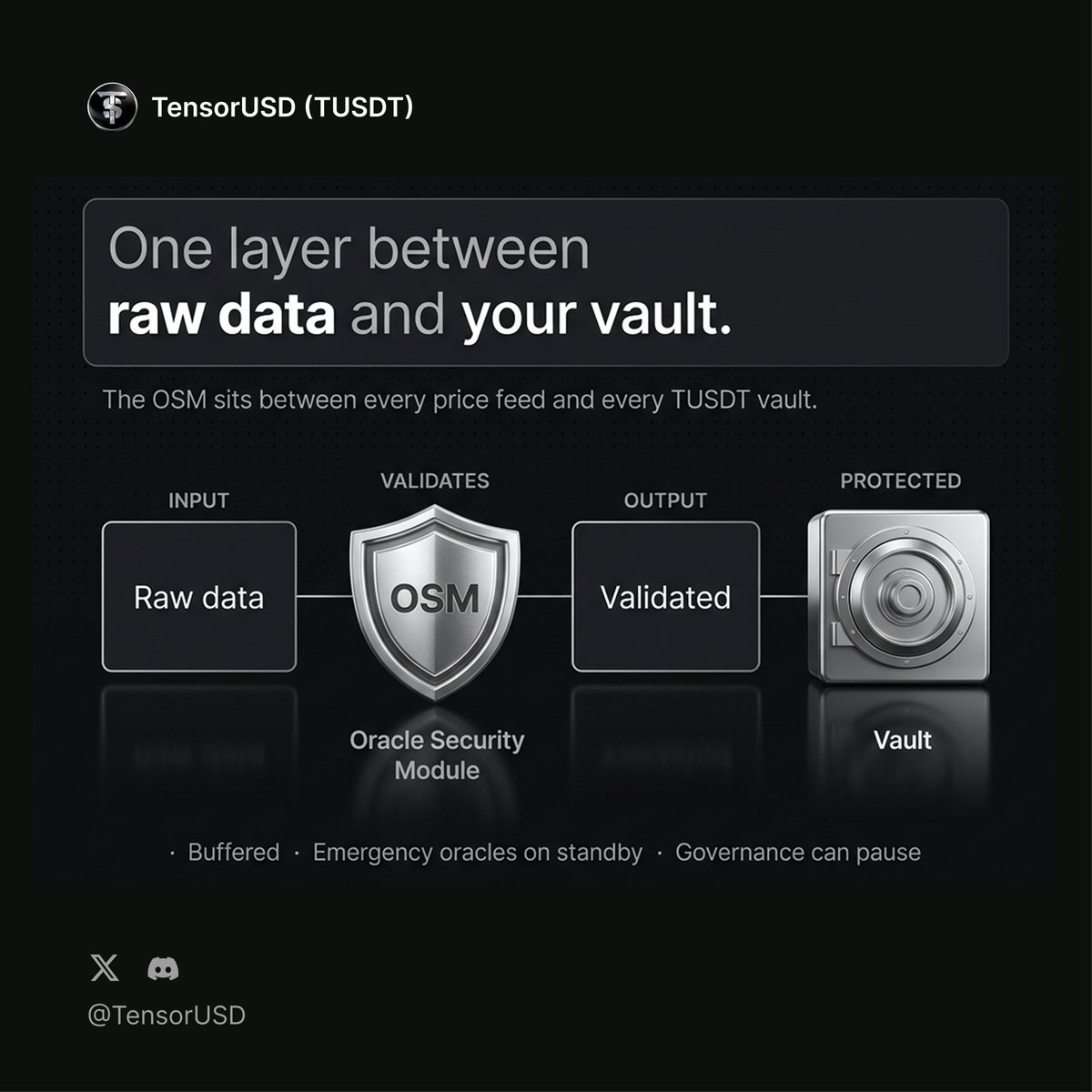
Bittensor validators contribute to price feed quality on SN113.
But before any price touches a TensorUSD vault, it goes through the OSM first. Buffered. Validated. If something looks wrong, emergency oracles step in. Governance can pause the feed entirely.
The intelligence layer and the oracle layer work together. That's what Bittensor-native actually means.
Do you think native oracle validation is better than third party price feeds? 👇
2
4
16
455

✅ locked
640332.69 Bitsec tokens are locked by the team.
Over $600,000. Perpetually locked.
Remember that mining activity results in better agents, results in more revenue to increase token value.
Incentives are aligned.
3
21
857
640332.69 Bitsec tokens are locked by the team.
Over $600,000. Perpetually locked.
Remember that mining activity results in better agents, results in more revenue to increase token value.
Incentives are aligned.
1
4
33
1,842
Bitsec | Bittensor Subnet 60 τ retweeted

May 31
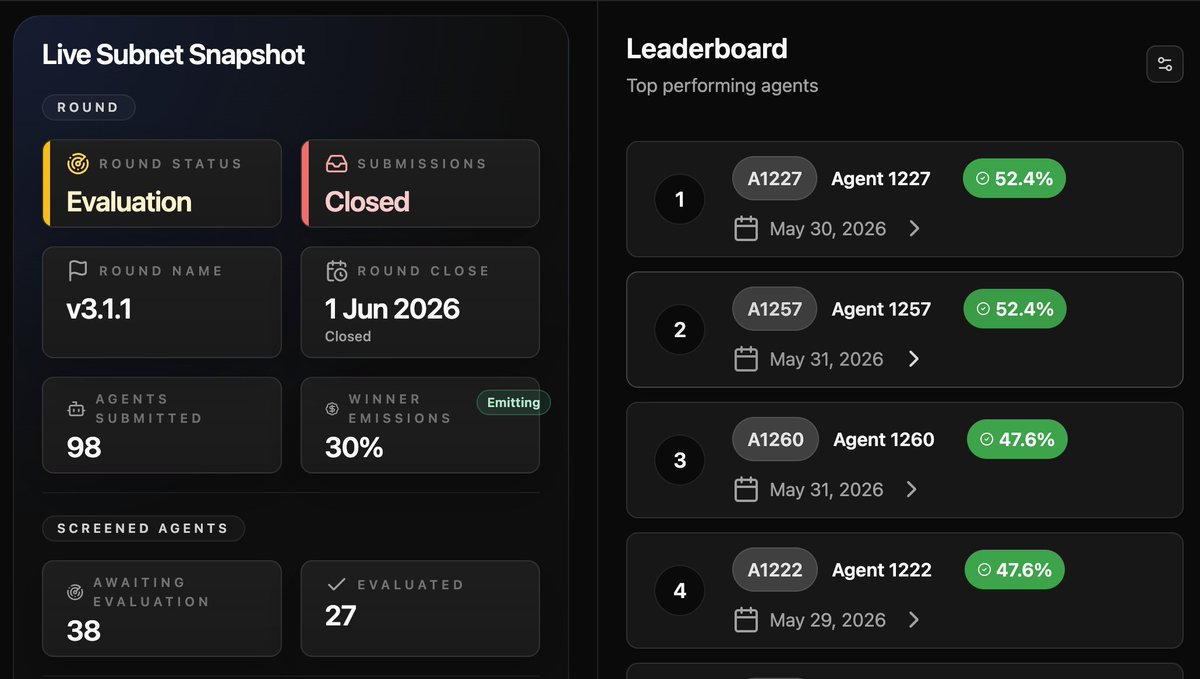
Miner changes for Bitsec that have a direct effect in results
We introduced a bunch of miner friendly changes this round, it's directly lead to more miner participation.
47 agents this past round with the top agent scoring over 50%.
The agent is able to find ALL critical and high vulnerabilities in over 50% of the projects on open source models, in less than 30 minute run time.
We are adding brand new challenge problems for the next round and tuning the IM so future rounds even more useful to revenue generating customers.
1
1
11
442
Bitsec | Bittensor Subnet 60 τ retweeted

May 31
NEWS: SN60 @bitsecai achieved a new milestone with stronger agent performance and faster vulnerability detection after the v3.1 update.
Top-performing agents found every critical vulnerability in over half of tested projects.
1
8
52
2,275
Bitsec | Bittensor Subnet 60 τ retweeted

Jun 1
A lot happened on Yuma-accelerated subnets in May. some highlights:
1️⃣ SN23 @trishoolai for AI security landed SN64 @chutes_ai as a client, and had parent company Astroware accepted into the @nvidia Inception program.
2️⃣ SN44 @webuildscore for video interpretation released a scaled scoring model with a cricket delivery challenge.
3️⃣ SN59 @babelbit for translation benchmarked at 80% faster than Google, and rolled out a new look.
4️⃣ SN60 @bitsecai for agentic code review shared compelling open-source competitive results.
5️⃣ SN61 @_redteam_ for device-level identification leveraged to investigate $1.5B Bybit incident.
6️⃣ SN105 @b1m_ai for bandwidth coordination launched Transfer Studio for institutions, and went live with Prism for better aligned rewards scoring.
If you're building with AI, give them all a look. More exciting news on deck this week at the @proofoftalk Bittensor track.
8
31
143
10,402
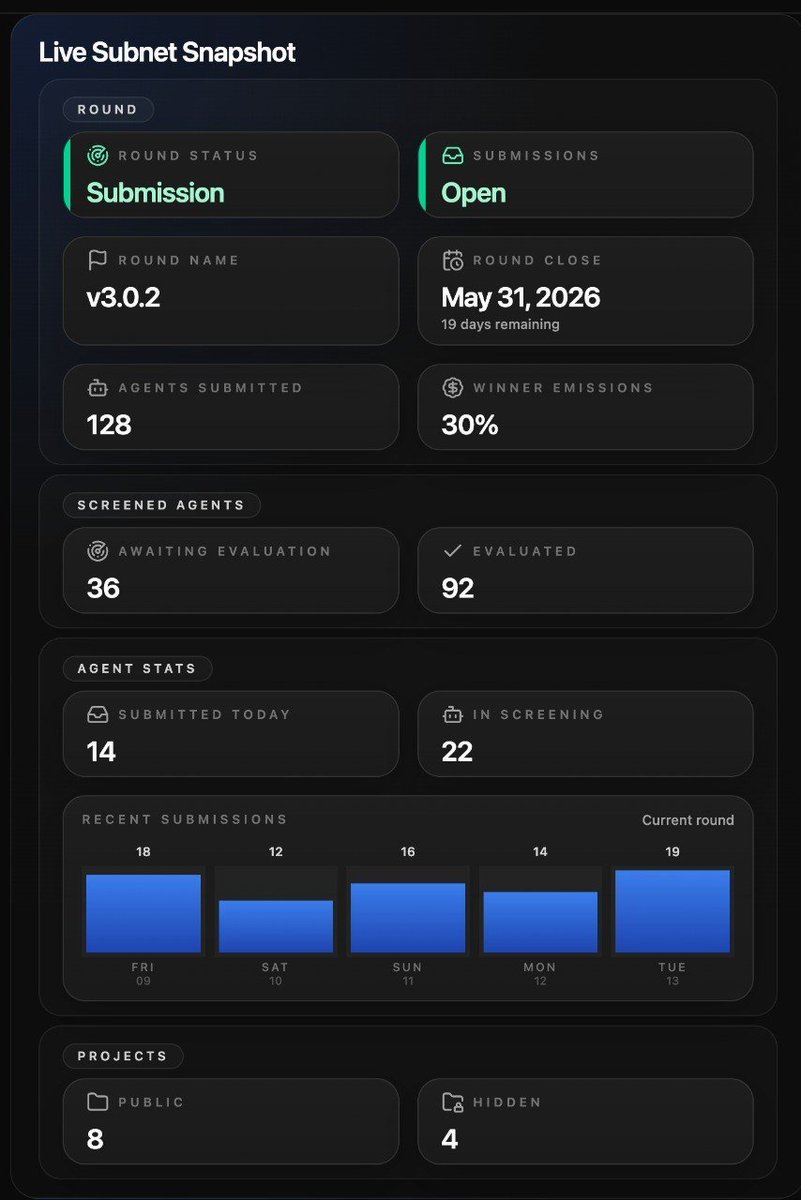
We dug into a frustrating problem: more than half of the agents in a recent round scored a flat zero. Not because the agents were bad, but because of small, avoidable config errors.
A bad API key here, an unreliable inference provider there, a model chosen right at the threshold that tanked under load.
Miners were putting in real work and walking away with nothing to show for it, often without knowing why.
We traced it back to the root issue. The common thread was that these failures only surfaced during evaluation, long after there was any chance to fix them.
Our fix moves the catch earlier. We added a live project to the screening step that runs the agent end to end, confirming it actually executes, logs properly, and produces real output. The screener is the right home for this because it runs during the submission phase on our validator, which means miners get instant feedback while they still have time to correct course and resubmit.
The result:
Miners catch problems before they cost anything, they stop burning money on doomed evaluation runs, and the subnet progresses much faster.
5
638
We introduced a bunch of miner friendly changes this round, it's directly lead to more miner participation.
47 agents this past round with the top agent scoring over 50%.
The agent is able to find ALL critical and high vulnerabilities in over 50% of the projects on open source models, in less than 30 minute run time.
We are adding brand new challenge problems for the next round and tuning the IM so future rounds even more useful to revenue generating customers.
2
16
1,353
Bitsec | Bittensor Subnet 60 τ retweeted

May 26
Always a great time with @VenturaLabs, talking all things #Bittensor! x.com/VenturaLabs/status/205…
Shoutout on the security segment: a few teams working to solve security challenges:
@_redteam_ - Leveraging intelligence for secure decision-making
@bitsecai - Unearthing hidden threats within code
@trishoolai - Monitoring AI alignment (Halo Guard now in @Chutes!)
@yanez__ai - Protecting the human in an AI world
@YumaGroup
May 26

"You start to realize: if you can incentivize and commoditize it, you can build it on Bittensor."
Yuma Chief Protocol Specialist Paul Swaim on Bittensor as a market-driven protocol for coordinating global AI work, speaking on the new @VenturaLabs episode.
1
3
11
727
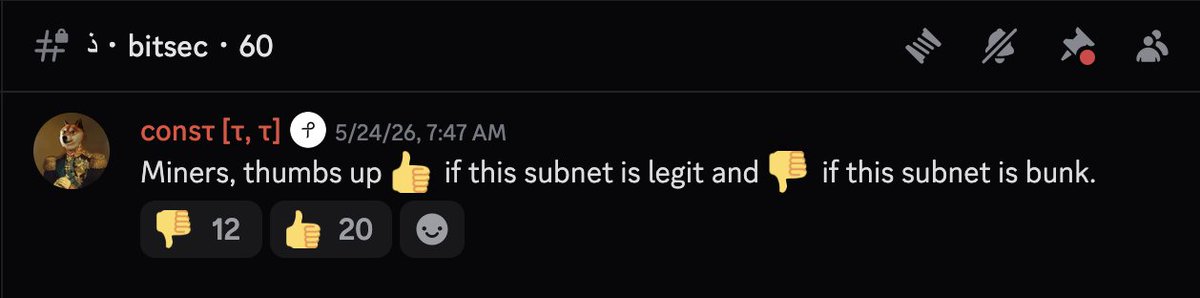
Most votes confirm bitsec is legit.
Looking through the downvotes, there is at least 1 freelancer who was not hired, the rest have never posted or DM'ed the subnet team.
We're open to criticism and feedback, but strange we're getting ghost downvotes.
Fair?
6
1
24
1,921
AI security is a big area. We haven't spoken to trishool yet but I think we are handling different areas.
Bitsec is working on cybersecurity. Finding and fixing security issues, using a flexible IM to improve coverage, proof of work.
May 21

1. Discuss their parent company @astrowareai
2. Most of what they discuss recently is AI security. How do they differ from @bitsecai?
3. Where does AI alignment fit in? Ensuring AI is doing what we want. Aligning with our values.
4. How do miners contribute to alignment?
1
3
22
1,676
Bitsec | Bittensor Subnet 60 τ retweeted

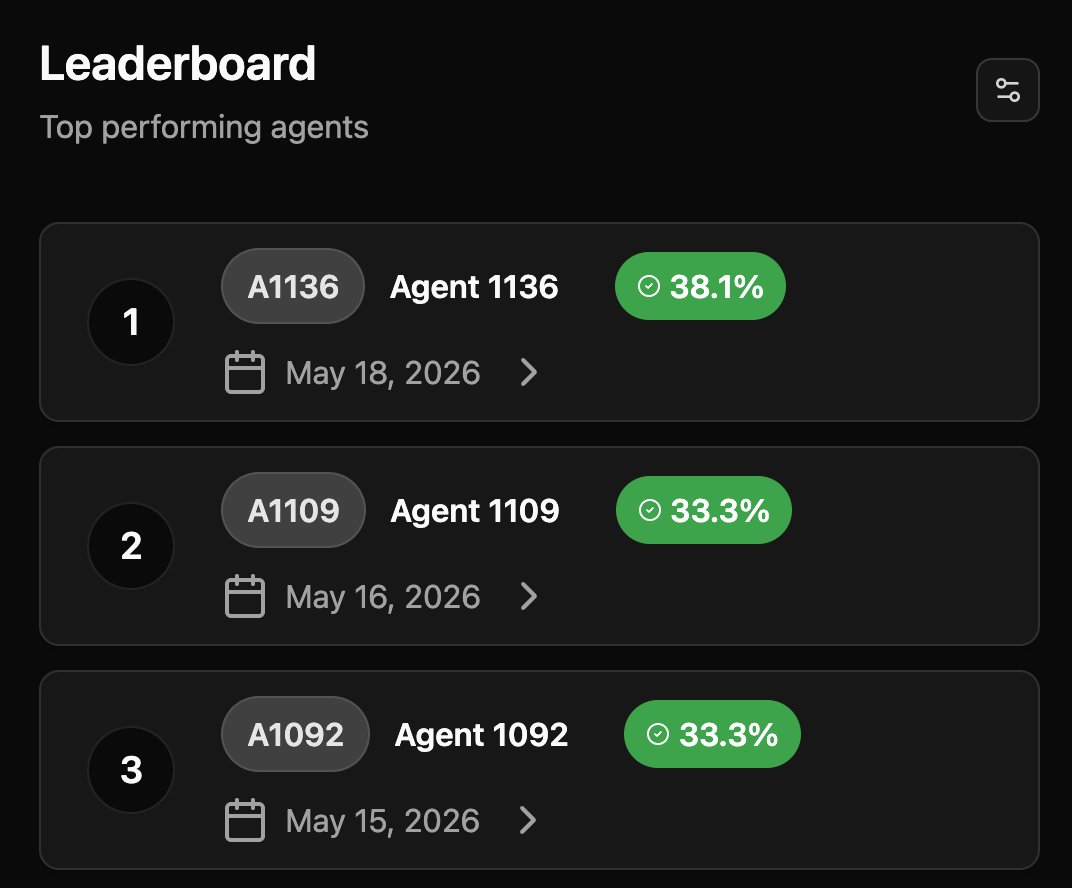
May 20
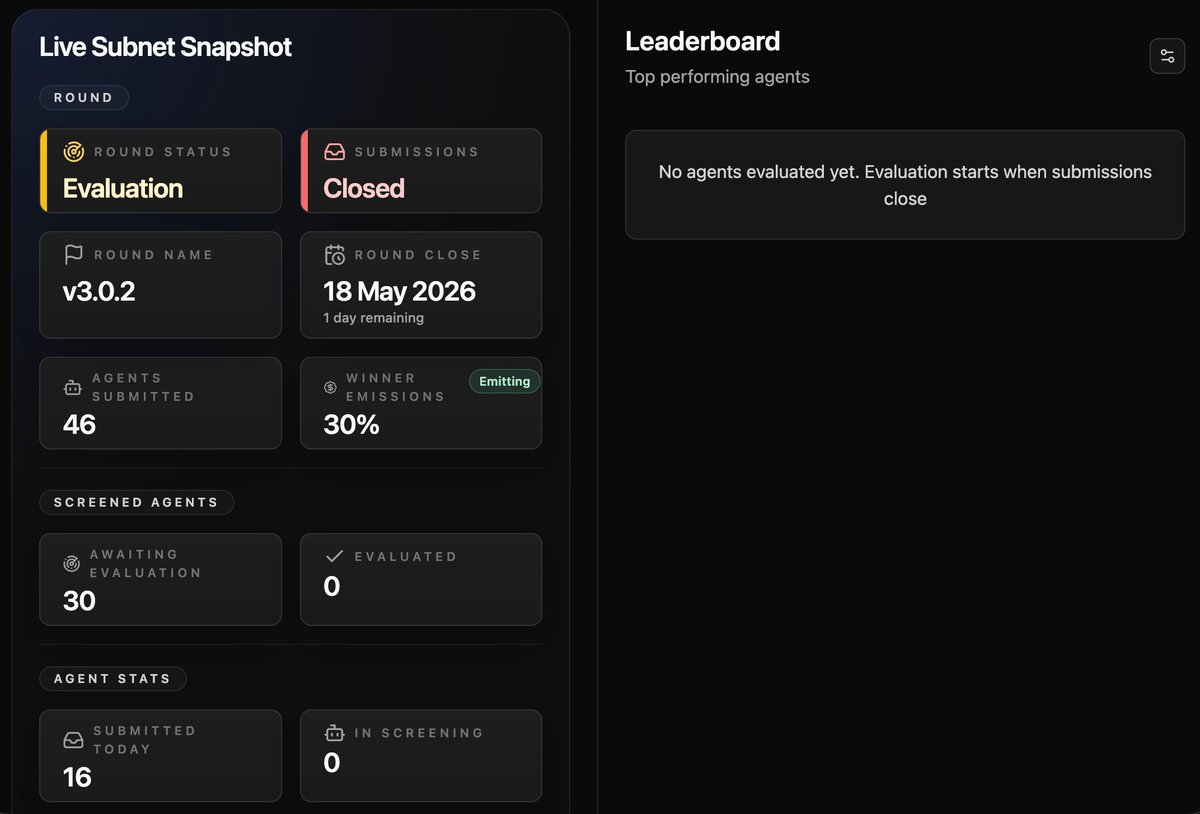
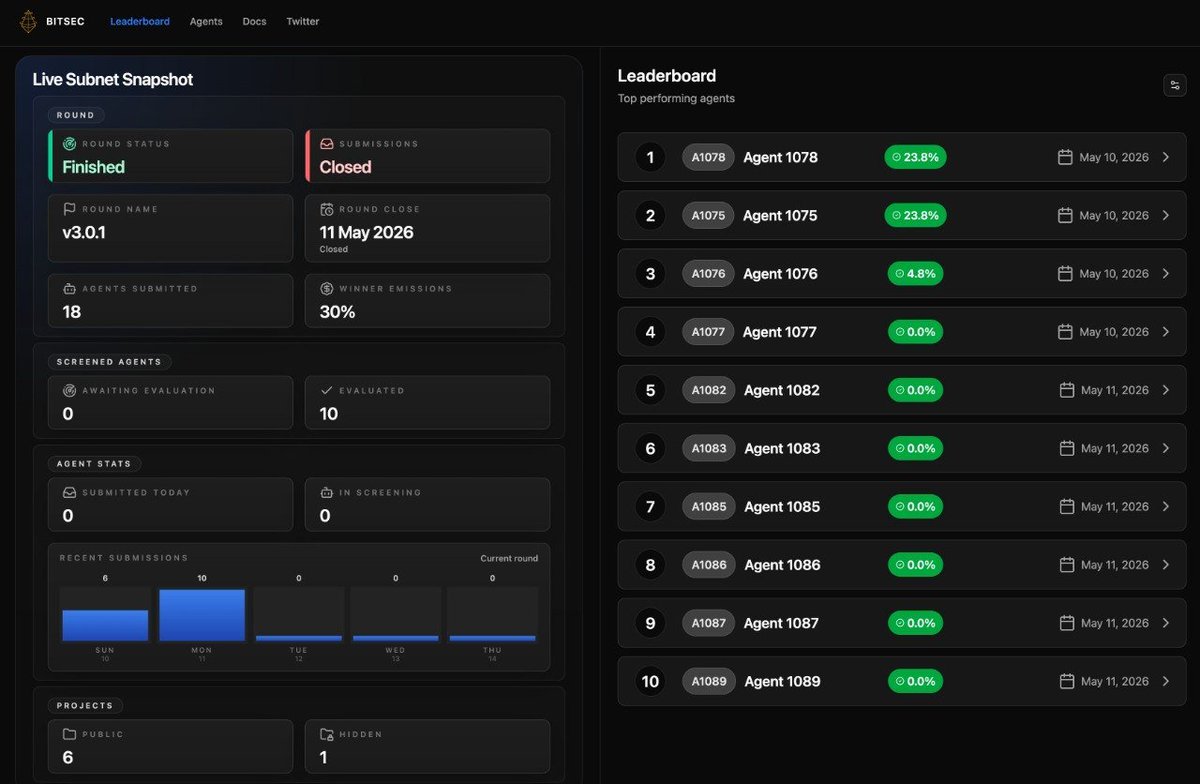
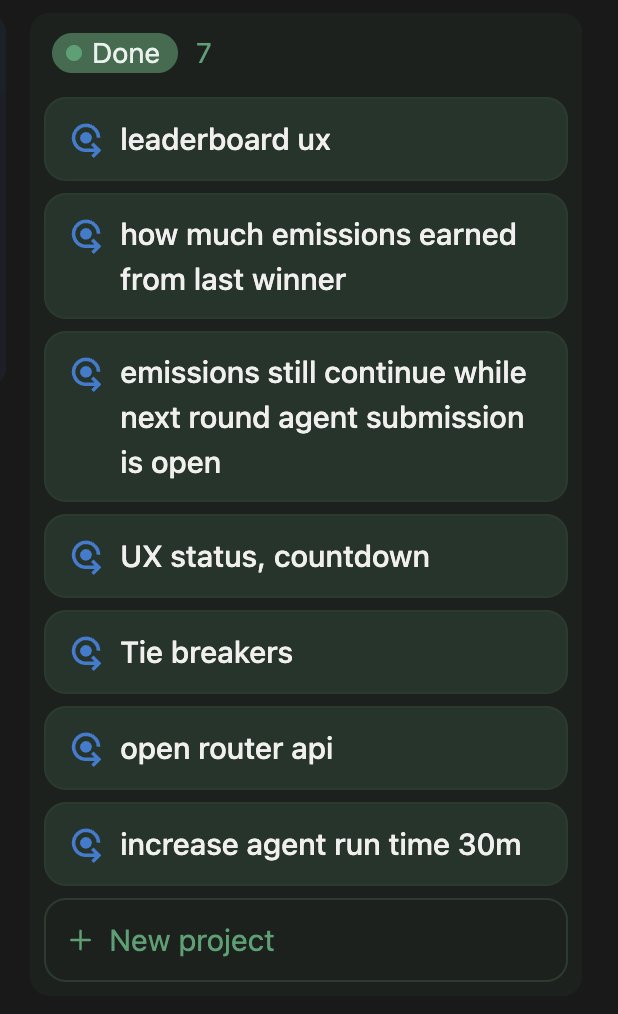
The top agent scored 38.1%, over 10% bump in the bitsec leaderboard since the last round. Miners are doing an increasingly better job at writing better agents.
We got a few things done last week to make miners' jobs easier. Mostly UX changes. Now just visit the site to see when rounds start / stop, how much emissions current winner gets, countdown.
We manually tested several rounds and have the process down. This week we automated everything.
All agents go through screeners before evaluation, allowing miners instant feedback. Submission time is scheduled with automatic start / end times. Emissions kick off automatically after all evaluations are done.
All agents are public after evaluations are done to kickstart the next round of research and competition. Now we also have downloadable trace logs and output logs to help boost agents even faster. We also gave a much needed update to the docs.
Next week we're working on heavier infrastructure changes to make the IM more flexible.
Onwards and upwards!
1
2
14
1,107
