
He/him. Dad and husband. I work at vespa.ai. My main hobbies are sailing, mountain/road biking, and creating an ultra low power personal computer.
Joined November 2009
- Tweets 552
- Following 215
- Followers 214
- Likes 1,879
39 Photos and videos












Jun 2
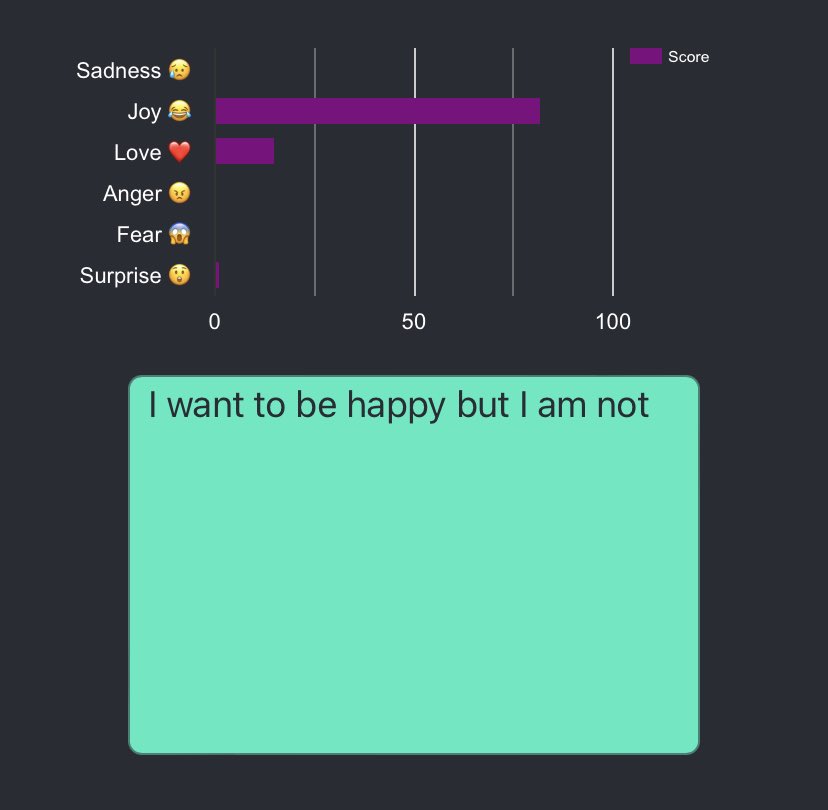
yeah why force all the data to flow through the lossiest, most expensive layer
Jun 1

slowly we're all realizing that tools should be called from code, not from within the llm api
1
121
Andreas Eriksen retweeted

I’m excited to join the speaker lineup at Vespa.ai Live! My session will explore Nuances of Binarized Embeddings-Based Retrieval
If you’re attending, let me know — would love to connect at the event.

2
2
9
473
Andreas Eriksen retweeted

May 31
My opinion on tokenmaxxing is companies shouldn’t mandate/constrain any tools at all and then evaluate software developers by output / (salary token use)
32
9
284
29,594
Andreas Eriksen retweeted

May 29
Vespa isn't only powering American AI, now it's also @MistralAI's retrieval solution
1
2
6
492
Andreas Eriksen retweeted

May 29
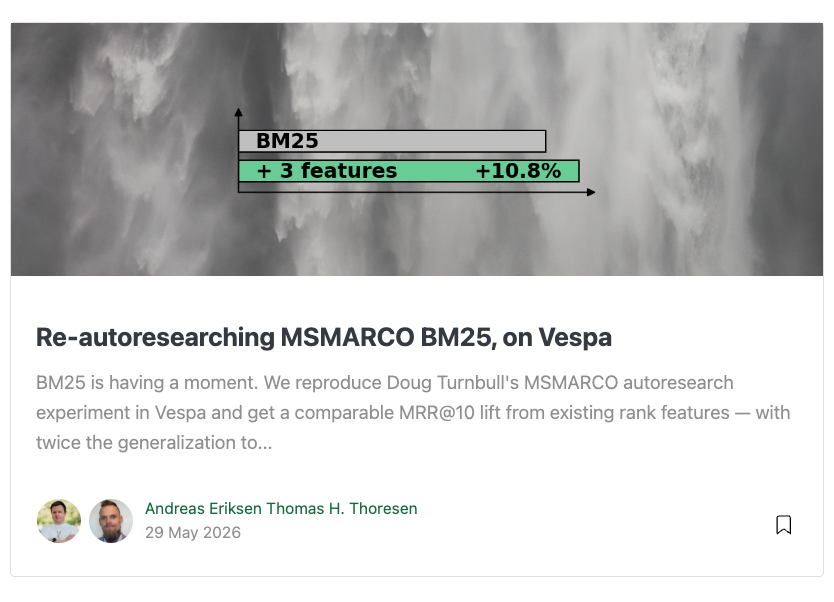
bm25 is nice and all, but you won't believe how easy it is to improve upon it with and how much more you can squeeze from lexical features in @vespaengine
3
5
26
1,960
May 28
Bound to happen, very happy to see it!
May 28

Claude Code is finally an RLM (oct 2025), congrats to Anthropic :-)
2
245
May 18
Yeah this was great. Also feel a deep connection with wanting to do stuff but not feeling qualified lol
May 18

I loved the Project Hail Mary movie (and the book).
Science, technology, competence, and openness – this is my culture.
1
67
May 16
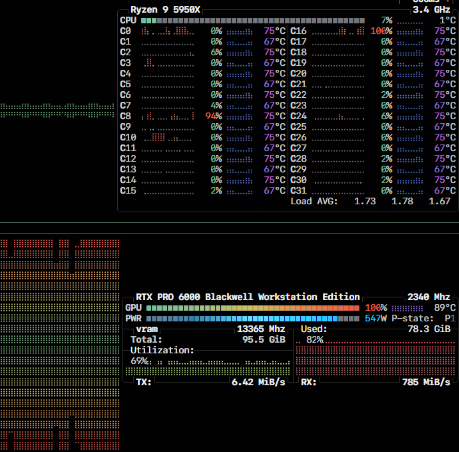
PSA: btop is amazingly nice. Among the first things I install on any linux box I use

1
3
838
Andreas Eriksen retweeted

Hypencoder is now ready for production using Vespa! Props to @andreer for making it happen! Really great stuff!
May 6

Just added a sample app for how to search with hypencoder models on Vespa. A large meta-model that generates a small query-specific model that scores your docs - it feels like pure science fiction, but of course we can do it: github.com/vespa-engine/samp…
1
2
13
1,253
Andreas Eriksen retweeted
A metamodel that generates weights for a NN for each query on the fly and using the same net for ranking documents against the same query - cool idea by @Julian_a42f9a
But, can you do it completely within @vespaengine , at scale, with reasonable latency (a few hundred ms)?
@andreer: hold my beer... (red bull)
🤯
May 6
Just added a sample app for how to search with hypencoder models on Vespa. A large meta-model that generates a small query-specific model that scores your docs - it feels like pure science fiction, but of course we can do it: github.com/vespa-engine/samp…
1
1
6
230
May 6
Just added a sample app for how to search with hypencoder models on Vespa. A large meta-model that generates a small query-specific model that scores your docs - it feels like pure science fiction, but of course we can do it: github.com/vespa-engine/samp…
3
2
9
1,693

Andreas Eriksen retweeted

Feb 19
State-of-the-art ColBERT models are trained by applying knowledge distillation on top of dense pre-trained models
What if we run the whole pre-training in the multi-vector?
Introducing ColBERT-Zero, a model that sets a new SOTA on BEIR, using only public data
11
33
189
30,307
Andreas Eriksen retweeted
Jan 3
Considering putting this into the front panel. It responds very nicely to changes in cpu load
1
1
2
76
Jan 3
raspberry pi zero 2w cluster brought up for the first time today. for hacking on, benchmarking and stability testing a certain wifi driver, and a few other plans to come later ...
2
10
401




21 Dec 2025
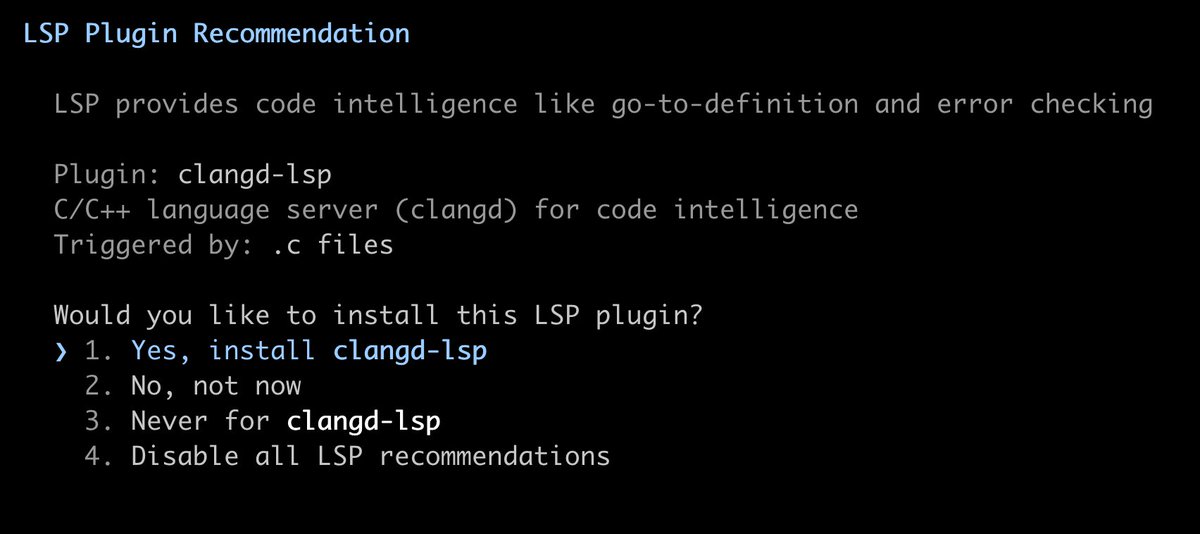
Claude started suggesting LSP to me this morning. Been waiting on this for a while - with semantic tools, there should be less fumbling around.
1
77