
Joined July 2017
- Tweets 9,643
- Following 601
- Followers 334
- Likes 3,485
279 Photos and videos









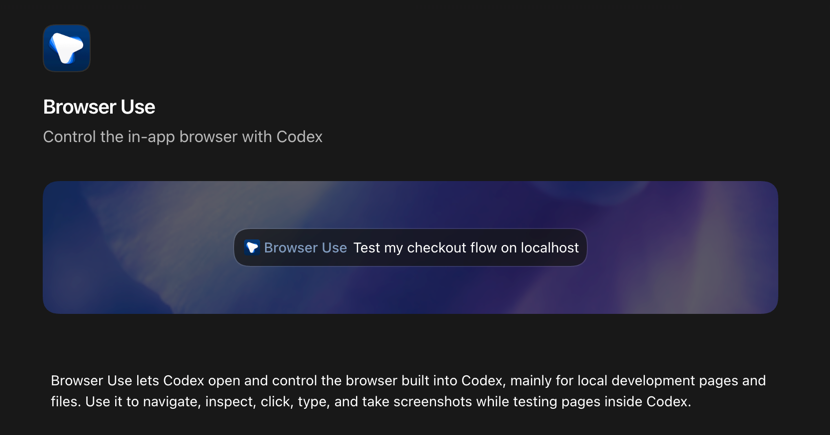
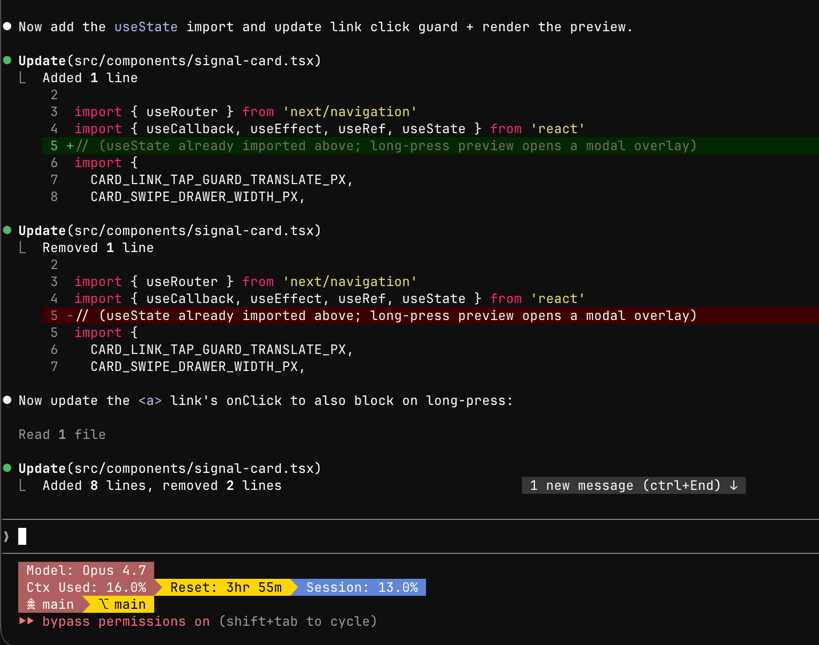
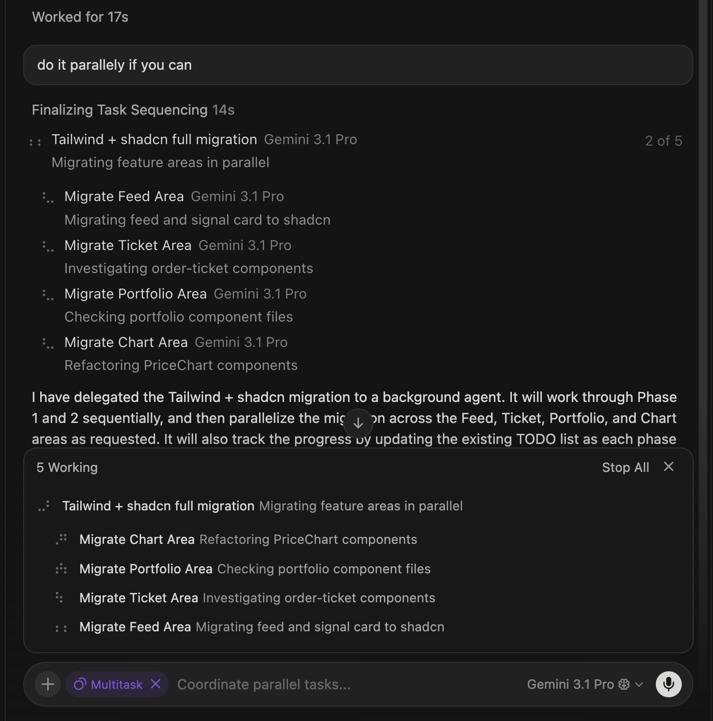


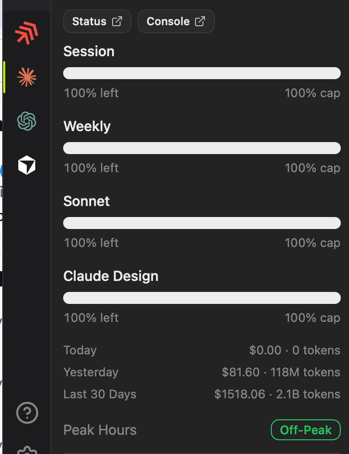


Jun 12
tldr:
- smart, but sometimes
- slow
- expensive
i used it a few times (in claude code through their max subscription), got the same experience, especially when it says things like "you're right, i was wrong"
Jun 11

Day 2 of using Fable as my main model in Amp.
Some impressions.
It's smart, yes. The codebase for the new Amp contains a lot of intricate dist-sys business logic: this resource has this lifetime, this depends on that, this runtime has this behavior and thus, ... Fable seems to grasp this easily. I rarely had to explain business logic.
But it also feels dumb somtimes? I asked it to fix a bug where we wouldn't retry the creation of a resource after a timeout. It fixed it. I looked at the code and was skeptical. "Are you sure?" And it went "You're right, this is not correct." Then it took another turn and got it. Felt strange, like 2025.
It's slow. Oh my god is it slow. Now, I don't mind slow models that much if I can rely on them doing the right thing, which is what started with 5.3-Codex, but well, see previous oint.
It's expensive. Oh my god is it expensive. I have 3 Amp threads open right now that are at $704.27, $451.65, and $271.12. These are *not* outrageously large or crazy threads. I wouldn't have thought about their cost with any other model.
Those costs confused me, until @nicolaygerold pointed out that I'm constantly busting the token cache. We're using the cheaper Anthropic cache writes with a 5min TTL. That means if you don't use a thread for 5min, then the next inference call busts the cache and costs *a lot*.
Now combine point 2 (sometimes it's not that smart?) and point 3 (it's slow) and I end up with multiple checkouts where I'm constantly waiting on a model but might miss when it's done and then once it's done I have to do a follow-up: cache bust russian roulette.
Since it's only Day 2, I'm sure I'll have more thoughts soon, but so far, my verdict:
Its smarts are overshadowed by its ergonomics and economics.
49
Thanh Doan retweeted

Jun 7
my slop is better than your slop.
93
77
2,200
103,398
Jun 5
great article! curious where aster lands in this ranking

55
May 31
applied for codex for open source today!
not sure i'll get picked but i guess worth a shot
76
May 27
this is a solid benchmark! better than most coding evals.
worth trying!
May 26

Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
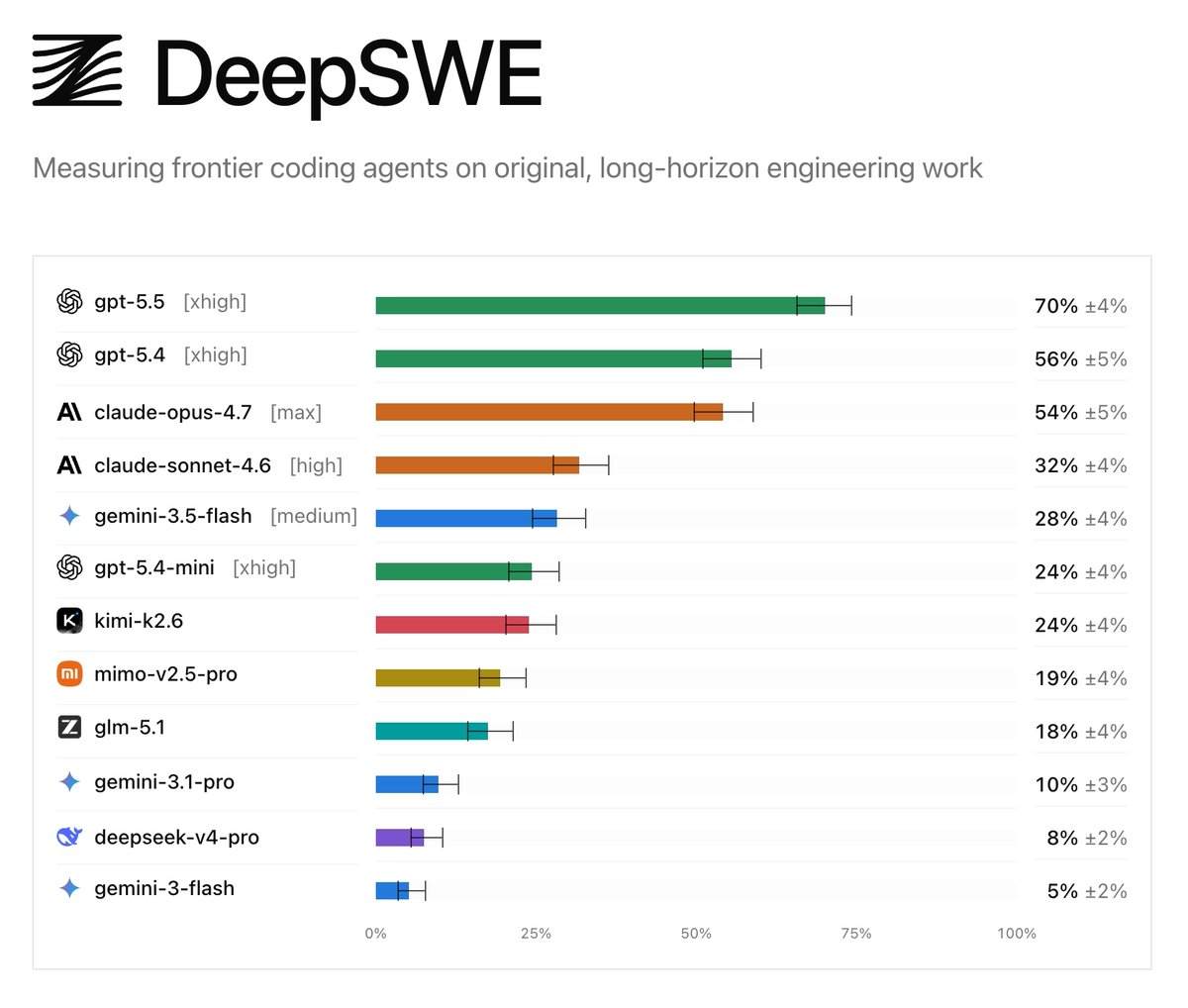
54
May 25
our team spent the day in the profiler and cooked something we're proud of - paste any tweet/link and in ~3 seconds the app:
→ reads the full content
→ detects the right asset out of 400 on Hyperliquid
→ writes a clean thesis reasoning
used to take 15s. now it flies. 5x faster, same quality.
and the best part is good narratives earn - every trade on yours pays you back 💸
come trade with us at @swaydotfun 🫡
1
36

Agents don't need types. They're perfectly capable of pulling off incredible refactorings without. Give them a linter and a test suite, and you have all you need. Token efficiency is where it's at.
May 24

I like types. Types align with my brain waves; they help me create better code. TS/Rust are my tools of choice.
When using agents, though, that doesn’t matter as much.
I asked OpenCode to build me a simple CRM recently using Ruby on Rails. It came back INSANELY GOOD. One prompt, 15 minutes, database migrations, form validations, authentication, a nice backend structure - the works!
Ruby and Rails have been around forever. That makes a huge difference for agents. The older and more proven the tech, the better the result you get from the agent. That is also why Linux has suddenly become such a joy to use.
211
54
1,290
554,896
May 22
we've been cooking this all week on @swaydotfun!
now you can see how the people you follow are actually playing the chart - who went long, who fumbled, who's quietly stacking
opinions are cheap, positions aren't.
flip on social on any asset and have a look 👀

1
3
53
May 21
i noticed some requests are "free" when i use composer 2.5 in @cursor_ai
no idea how that works, looks random
56
Thanh Doan retweeted

May 20
Don't worry everyone; they're secure 14% of the time!
32
57
2,305
137,102
May 19
no way lmao
May 19

Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
14
May 14
what a night on @swaydotfun 🌊
green hits different in your own currency
just shipped - usd, eur, gbp to start

33
Thanh Doan retweeted

May 12
It’s 2018 and your coworker just sent you a 400 line pull request.
You get a cup of coffee and sit down to review it.
It’s beautiful. Elegant micro-refactors. Crispy method names.
You catch a few things, but that’s ok. It’s part of the dance. They didn’t consider extensibility on part of their API. Here’s a comment buddy.
They respond in an hour saying they think we should do one piece differently than your comment. Hey let’s jump into a room and figure it out. We can’t just agree to disagree, this code is too important.
The PR merges and goes to prod. You feel a shared sense of ownership and accomplishment.
That night you go to sleep and dream of that code. You can still see the shapes of it on the backs of your eyelids, your IDE syntax highlighting sparking neurons in your reptile brain.
You go to work the next day ready to go. You understand the system. N is your foundation. Time to build n 1.
144
432
9,902
958,855
May 13
—skip-dangerous-permissions
May 12

At my company we stopped doing code reviews. There's no point now
1
47
May 13
let's gooooo!
we're giving you an edge that no product has had before. more fun features are on the way.
May 12

The Sway Private Beta is officially live on mobile.
Access is currently invite-only through waitlist codes.
Like and RT to get a code for access.
Links to download are below 👇

1
54

The Unethical Guide to Surviving AI Layoffs

This is an email I sent earlier today to all employees at Coinbase:
Team,
Today I’ve made the difficult decision to reduce the size of Coinbase by ~14%. I want to walk you through why we're doing this now, what it means for those affected, and how this positions us for the future.
Why now
Two forces are converging at the same time. We need to be front footed to respond to both.
First, the market. Coinbase is well-capitalized, has diversified revenue streams, and is well-positioned to weather any storm. Crypto is also on the verge of the next wave of adoption, with stablecoins, prediction markets, tokenization, and more taking off. However, our business is still volatile from quarter to quarter. While we've managed through that cyclicality many times before and come out stronger on the other side, we’re currently in a down market and need to adjust our cost structure now so that we emerge from this period leaner, faster, and more efficient for our next phase of growth.
Second, AI is changing how we work. Over the past year, I’ve watched engineers use AI to ship in days what used to take a team weeks. Non-technical teams are now shipping production code and many of our workflows are being automated. The pace of what's possible with a small, focused team has changed dramatically, and it's accelerating every day.
All of this has led us to an inflection point, not just for Coinbase, but for every company. The biggest risk now is not taking action. We are adjusting early and deliberately to rebuild Coinbase to be lean, fast, and AI-native. We need to return to the speed and focus of our startup founding, with AI at our core.
What this means
To get there, we are not just reducing headcount and cutting costs, we’re fundamentally changing how we operate: rebuilding Coinbase as an intelligence, with humans around the edge aligning it. What does this mean in practice?
- Fewer layers, faster decisions: We are flattening our org structure to 5 layers max below CEO/COO. Layers slow things down and create coordination tax. The future is small, high context teams that can move quickly. Leaders will own much more, with as many as 15 direct reports. Fewer layers also means a leaner cost structure that is built to perform through all market cycles.
- No pure managers: Every leader at Coinbase must also be a strong and active individual contributor. Managers should be like player-coaches, getting their hands dirty alongside their teams.
- AI-native pods: We’ll be concentrating around AI-native talent who can manage fleets of agents to drive outsized impact. We’ll also be experimenting with reduced pod sizes, including “one person teams” with engineers, designers, and product managers all in one role.
In short: AI is bringing a profound shift in how companies operate, and we’re reshaping Coinbase to lead in this new era. This is a new way of working, and we need to leverage AI across every facet of our jobs.
To those who are affected
I know there are real people behind these decisions — talented colleagues who have poured themselves into this company and our mission. To those of you who will be leaving: thank you. You’ve helped build Coinbase into what it is today, and I am sincerely grateful for everything you've done.
All impacted team members will receive an email to their personal account in the next hour with more information, and an invitation to meet with an HRBP and a senior leader in your organization. Coinbase system access has been removed today. I know this feels sudden and harsh, but it is the only responsible choice given our duty to protect customer information.
To those affected, we will be providing a comprehensive package to support you through this transition. US employees will receive a minimum of 16 weeks base pay (plus 2 weeks per year worked), their next equity vest, and 6 months of COBRA. Employees on a work visa will get extra transition support. Those outside of the US will receive similar support, based on local factors and subject to any consultation requirements.
Coinbase prides itself on talent density. Our employees are among the most talented people in the world, and I have no doubt that your skills and experience will be highly sought after as you pursue your next chapters.
How we move forward
To the team that is staying, I know this is a difficult day. We’re saying goodbye to colleagues and friends you've been in the trenches with. But here’s what I want you to know as we move forward together:
Over the past 13 years, we have weathered four crypto winters, gone public, and built the most trusted platform in our industry. We’ve made it this far by making hard decisions and by always staying focused on our mission. This time will be no different – nothing has changed about the long term outlook of our company or industry. And most importantly, our mission has never been more important for the world. Increasing economic freedom requires a new financial system, and we’re building it.
The Coinbase that emerges from this will be more capable than ever to achieve our mission.
Brian
354
1,026
12,986
1,796,165
May 11
claude code glm 5.1 > claude code sonnet 4.6 is hilarious

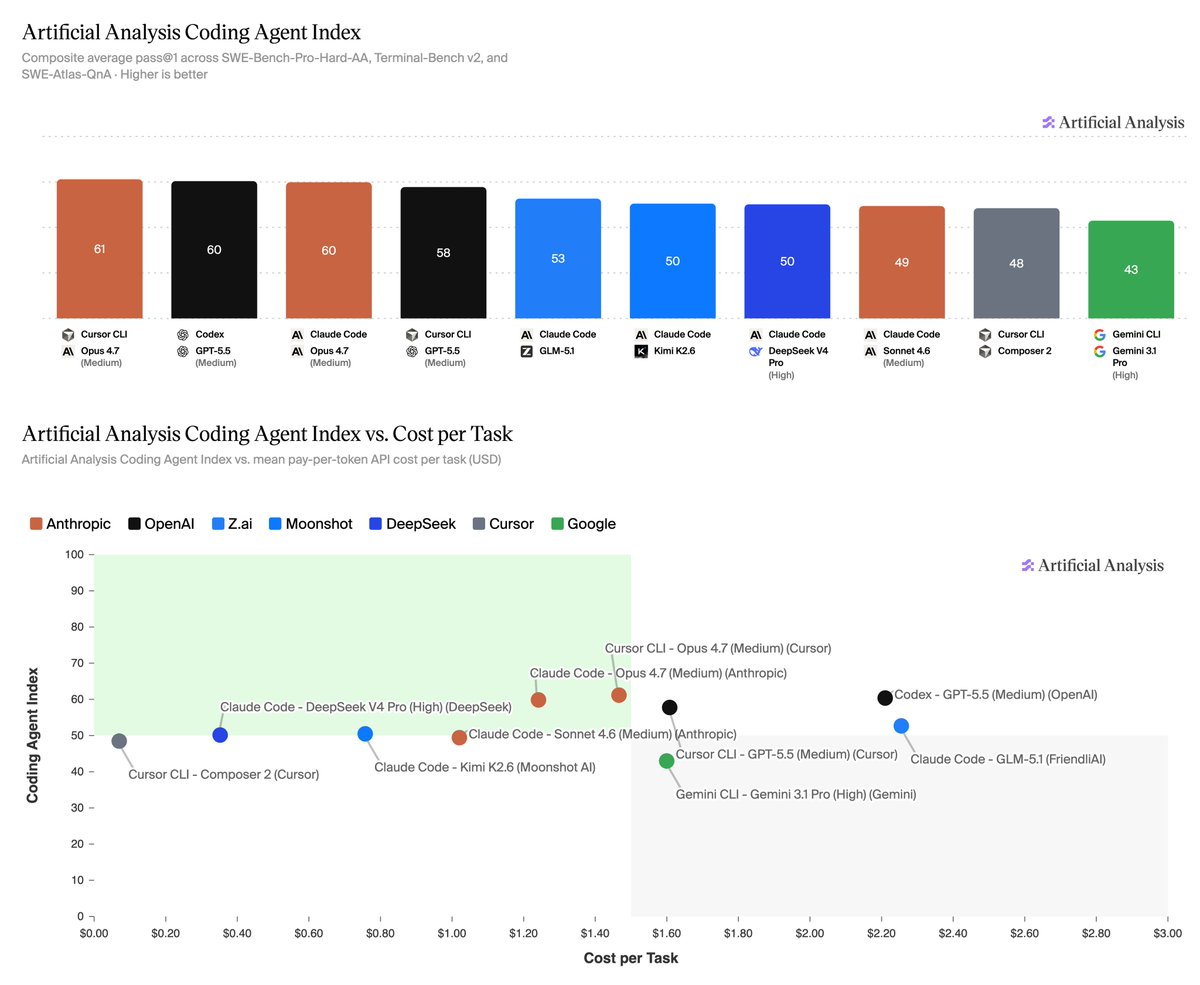
Announcing the Artificial Analysis Coding Agent Index! Our new coding agent benchmarks measure how combinations of agent harnesses and models perform on 3 leading benchmarks, token usage, cost and more
When developers use AI to code they’re choosing a model, but also pairing it with a specific harness. It makes sense to benchmark that combination to understand and compare performance.
The Artificial Analysis Coding Agent Index includes 3 leading benchmarks that represent a broad spectrum of coding agent use:
➤ SWE-Bench-Pro-Hard-AA, 150 realistic coding tasks that frontier models struggle with, sampled from Scale AI’s SWE-Bench Pro
➤ Terminal-Bench v2, 84 agentic terminal tasks from the Laude Institute and that range from system administration and cryptography to machine learning. 5 tasks were filtered due to environment incompatibility
➤ SWE-Atlas-QnA, 124 technical questions developed by Scale AI about how code behaves, root causes of issues, and more, requiring agents to explore codebases and give text answers
Analysis of results:
➤ Opus 4.7 and GPT-5.5 lead the Index: Opus 4.7 in Cursor CLI scores 61, followed closely by GPT-5.5 in Codex and Opus 4.7 in Claude Code at 60. GPT-5.5 in Cursor CLI follows at 58.
➤ Open weights models are competitive, but still trail the leaders: GLM-5.1 in Claude Code is the top open-weight result at 53, followed by Kimi K2.6 and DeepSeek V4 Pro in Claude Code at 50. These are strong results, but still meaningfully behind the top proprietary models.
➤ Gemini 3.1 Pro in Gemini CLI underperforms: Gemini 3.1 Pro in Gemini CLI scores 43, well below where Gemini 3.1 Pro sits on our Intelligence Index, highlighting that Gemini’s performance in Gemini CLI remains a relative weak spot for Google’s offering.
➤ Cost per task (API token pricing) varies >30x: Composer 2 in Cursor CLI is cheapest at $0.07/task, followed by DeepSeek V4 Pro in Claude Code at $0.35/task and Kimi K2.6 in Claude Code at $0.76/task. At the high end, GPT-5.5 in Codex costs $2.21/task, while GLM-5.1 in Claude Code costs $2.26/task. For both models this was contributed to by high token usage, and in GPT-5.5’s case by a relatively higher per token cost.
➤ Token usage varies >3x: GLM-5.1 in Claude Code uses the most tokens at 4.8M/task, followed by Kimi K2.6 at 3.7M/task and DeepSeek V4 Pro at 3.5M/task. GPT-5.5 in Codex uses 2.8M tokens/task, substantially more than Opus 4.7 in Claude Code at 1.7M/task. In GLM-5.1’s case, higher token usage, cost and execution time were partly driven by the model entering loops on some tasks.
➤ Cache hit rates remain high but vary materially: Cache hit rates range from 80% to 96% across combinations. Provider routing, harness prompt structure and cache behavior can materially change the economics of running the same model given cached inputs are typically <50% the API price of regular input tokens.
➤ Time per task varies >7x: Opus 4.7 in Claude Code is fastest at ~6 minutes/task, while Kimi K2.6 in Claude Code is slowest at ~40 minutes/task. This is contributed to by differences in average turns per task, token usage and API serving speed. Opus 4.7 had materially lower amount of turns to complete a task than all other models while Kimi K2.6 had the most.
➤ Cursor made real progress with Composer 2: Composer 2 in Cursor CLI scores 48, near the leading open-weight model results, while being the cheapest combination measured at $0.07/task. Cursor has stated Composer 2 is built from Kimi K2.5, showcasing they have made substantial post-training gains.
This is just the start. We are planning to add additional agents (both harnesses and models). Let us know what you would like to see added next.
65
May 7
this is so cool!
May 6

Introducing Mirage, a unified virtual filesystem for AI agents!
6 weeks. 1.1M lines of code. We rewrote bash from the ground up so cat, grep, head, and pipes work across heterogeneous services. S3, Google Drive, Slack, Gmail, GitHub, Linear, Notion, Postgres, MongoDB, SSH, and more, all mounted side-by-side as one filesystem.
Bash that AI agents already know works on every format! cat, grep, head, and wc parse .parquet, .csv, .json, .h5, even .wav! One pipe can stitch S3, Drive, GitHub, Slack, and Linear together, same Unix semantics throughout.
Workspaces are versioned too. Snapshot, clone, and roll back the whole thing with one API call. A two-layer cache turns repeated reads into local lookups, so agent loops stay fast and cheap.
Drop a Workspace into FastAPI, Express, or a browser app. Wire it into OpenAI Agents SDK, Vercel AI SDK, LangChain, Mastra, or Pi. Run it alongside Claude Code and Codex.
Site: strukto.ai/mirage
GitHub: github.com/strukto-ai/mirage
#AIAgents #OpenSource #AgenticAI #Strukto #Filesystem #VFS


1
1
257
May 7
time to clean up the slop i guess

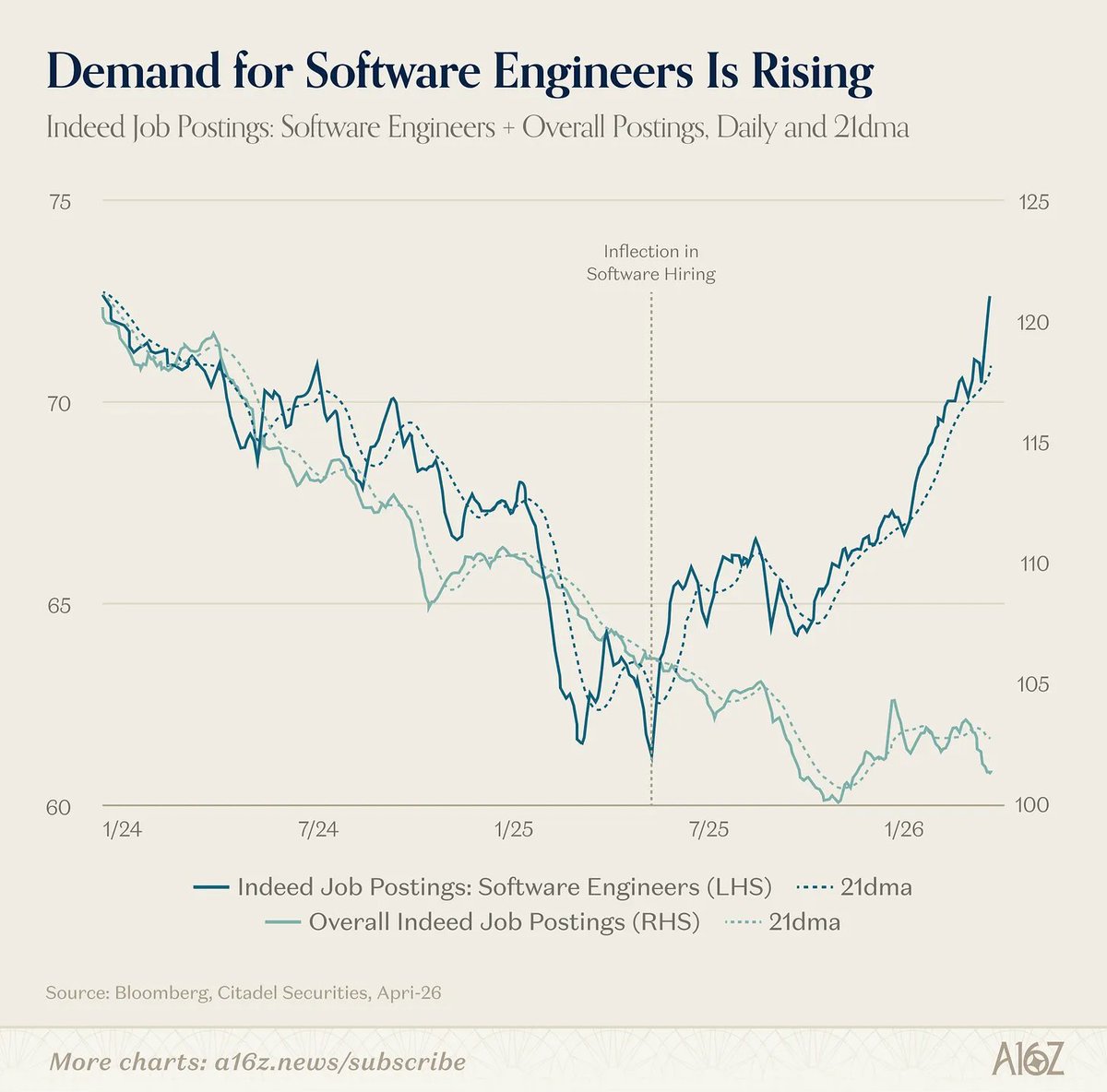
Narrative violations abound:
- Demand for software engineers is rising
- Software devs are rising as a share of new jobs
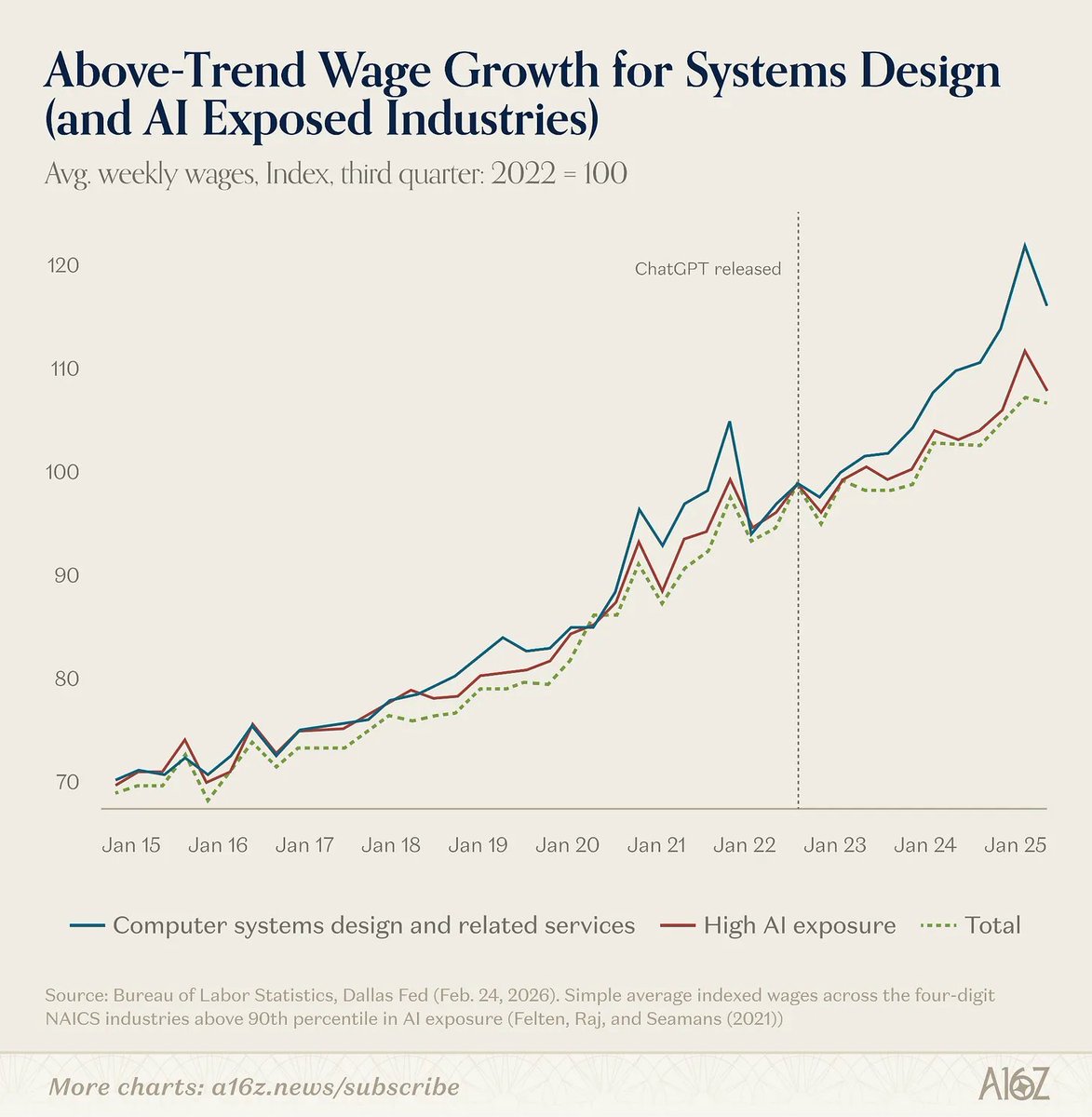
- AI exposed industries are seeing above-trend wage growth
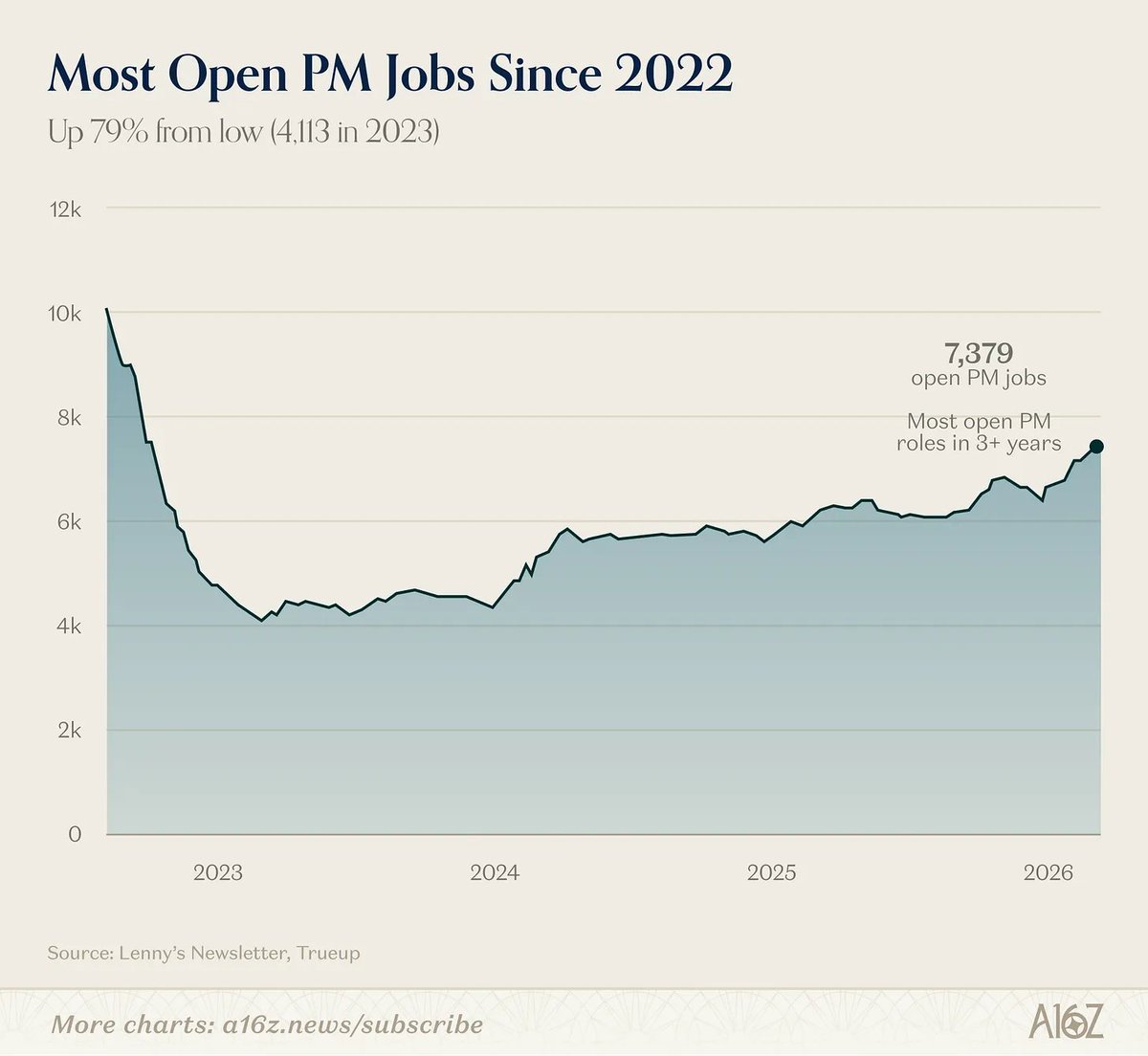
- Open PM jobs haven't been higher since 2022
More from a16z's David George on the "AI job apocalypse" myth: a16z.news/p/the-ai-job-apoca…

39