
Lightweight Tooling for AI in Prod.
Joined April 2025
- Tweets 38
- Following 62
- Followers 45
- Likes 6
12 Photos and videos









2
126

25 Nov 2025
What is 03/19/2001 subtract 9 weeks?
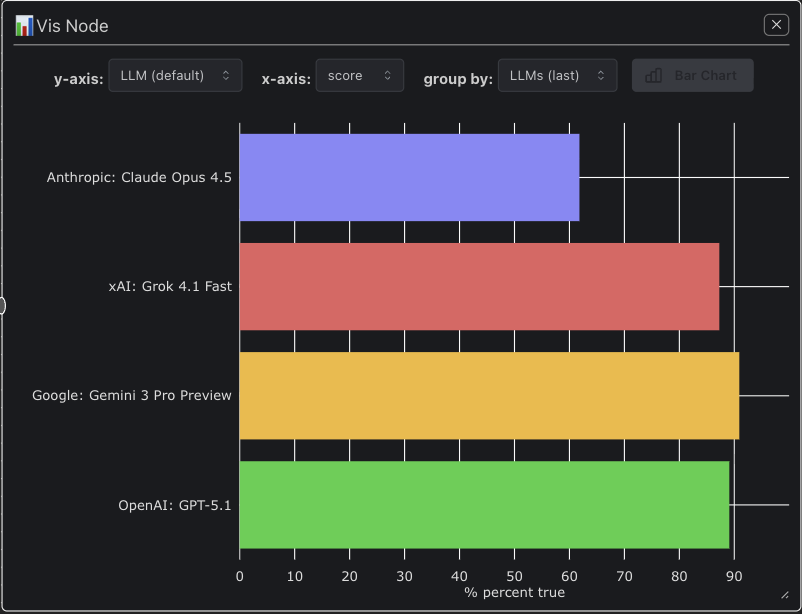
#Anthropic: Claude Opus 4.5
Ans: 01/10/2001 ❌
1
1
268
25 Nov 2025
Needless to say that Claude Opus 4.5 is sadly not the greatest date calculator 🤷♂️
68
18 Nov 2025
Gemini 3 not too bad on one of our Color Evals! Just fell short of Claude Sonnet 4.5 🧐
#Gemini
1
92
20 Oct 2025
The path forward in #AIImplementation isn't finding THE winner, but mapping the best fit model for the task. It's fair to expect from your #AIdevelopers to create a clear model-to-use-case mapping, driven by robust, comparative #LLMevaluations using industry-specific benchmarks. That's true optimization. 🗺️ #Benchmarking #AIStrategy
81
17 Oct 2025
Every LLM eventually reveals its specialty. Stop searching for the AI 'God Mode'! 🙅♀️ There's enough evidence to back up the #NoFreeLunch theorem out here! Let's quit chasing the perfect generalist and focus on the best tool for the job. #AIHacks 🛠️ #AILeaderboards #AIEvals
1
81
17 Oct 2025
#AiEngineers & #Developers : Y'all doublecheck your #AImodels on #benchmarks before #finetuning them, right? 😬
69
16 Oct 2025
Core Philosophy 2: Dream Big 💭, Share Big 📣 We dream of building the most trusted source for AI model selection. The gameplan: Community = scale. #AIEngineers, let's build the truth together! 💪 #CommunityDrivenAI #ScaleWithUs #Leaderboards #AIBenchmarking
46
15 Oct 2025
We need to air out the LLM performance data! 📢 #Transparent, public #leaderboards are how we get to the real "truth in AI" and build reliable products faster. Let's see the stats! #AIEvals #Community #AITruth #LLMBenchmarking
47
15 Oct 2025
Specialization over generalization = A better, more realistic way forward in #AI approach. #AIDevelopment #LLMInnovation Have a read of our Substack's writeup: chainforge.substack.com/p/wh…
37
15 Oct 2025
The @Cohere paper is the closest thing we've seen to a bold statement to call out #AItransparency issues in the industry: cohere.com/research/lmarena
2
2
206
14 Oct 2025
Core Philosophy # 3: Truth Should Be Accessible = Knowledge shouldn't be trapped. 🔓 We advocate for creating knowledge channels so real granular data on #LLMs model performance is accessible to every #engineer . Truth is power! ⚖️ #DemocratizeAI #OpenEvaluation #AI #Leaderboards
38
13 Oct 2025
The solution (time) is nigh! We're saying that truly comparative, publicly visible eval leaderboards for #AI should be the standard. We’re making it happen. Give us a follow and strap in! 🚀 #PublicLeaderboards #AITransparency
33
10 Oct 2025
Origin Story! Pair of AI researchers start to pick at LLMs. Get fed up, bring onboard engineer & build in open source. Team meets enthusiasts for coffee ☕ Chats that quickly light up eyes 🤩 That energy turns into trychainforge.ai 💡 #ChainforgeStory #AIEvolution #LLMBenchmarking
1
2
65
9 Oct 2025
Stop guessing! 🛑 We got tired of arbitrary and obscure benchmarks giving developers headaches - you need reliable data to ditch the confusion. 💊 #LLMEvals #DeveloperTools
29
8 Oct 2025
Chainforge Philosophy #1: The silver bullet "All-in-one” Model is a myth. 🦄 Every LLM has inevitable strengths & weaknesses based on its architecture & data. 🧭 #NoFreeLunch #ModelSelection #AIPhilosophy
1
2
43