
how hard could it be?
Joined February 2007
- Tweets 5,041
- Following 7,500
- Followers 1,128
- Likes 169,009
60 Photos and videos



Jun 15
‘[llms] are fundamentally engines that create "highly probable statements" – but the probability is not that of being true but of being said.’ — worth pondering from time to time …

30
Christian Langreiter retweeted

Jun 13
56,000 tokens/sec at just 80 MHz. 🤯
I burned a full Transformer with KV cache into a custom chip. Designed gate by gate as a 100% digital integrated circuit. Prototyped on a FPGA. (No GPU. No CPU)
Just pure digital silicon running @karpathy microGPT, spelling out names on a tiny LCD.
This is GateGPT 👇
146
486
4,390
573,366
Jun 12
schmidhuber perspective

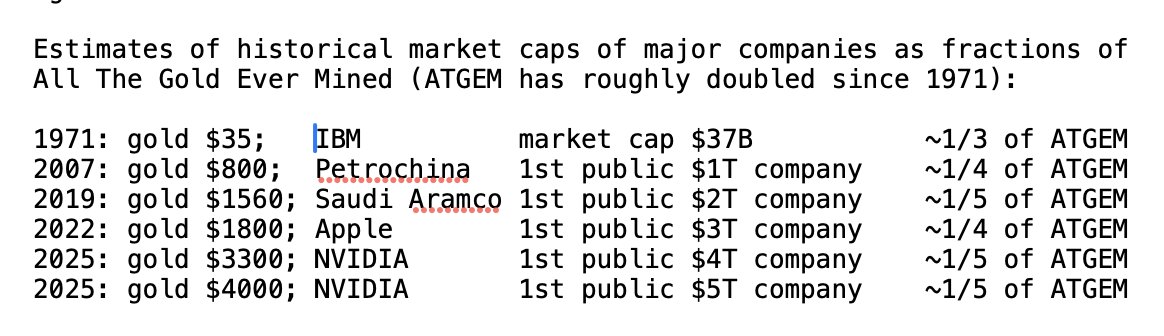
Tera IPOs coming! $1T sounds like a lot. But $1T is just a 7-m-wide gold cube, thanks to massive inflation since 1971 when $ and gold decoupled. A little house full of gold. To put things in perspective: the 2017 neutron star merger GW170817 produced several earth masses of gold.
82
Christian Langreiter retweeted

Jun 10
Codexで強化学習
生き物つくってもうた。。
108
442
6,069
816,421
Christian Langreiter retweeted

Jun 10
Many AI leaders in the US accused Chinese LLMs of subtle manipulation of the user (without proof, but it's hard to prove). But then the leading American lab documented manipulation of their users. Can't make this up.
40
95
1,289
49,542
Christian Langreiter retweeted

Jun 4
Recursive self-improvement post by Anthropic:
“Each time we release a model, we give it code that trains a small AI model, ask the new model to speed it up.
In May 2024, Claude Opus 4 averaged a ~3x speedup. This April, Mythos Preview achieved ~52x.”
RSI is happening, and I can't wait to see Mythos.

47
40
530
47,870
Christian Langreiter retweeted

Jun 3
Kyle revived MusicTransformer! If anyone wants a little taste of history.
Fun Fact: This was actually one of the first applications of transformers because the team sat next to us back in the day.
Jun 3

@huangcza @iansimon @notwaldorf tiny labor of love to revive an old model ♡ kylemcdonald.github.io/Music…
4
3
48
3,357
Christian Langreiter retweeted

May 21
Deep work and deep thinking will be increasingly valuable in a world where AI agents automate a lot of knowledge work. Spawning tens of agents in parallel and context switching between them feels productive, but it's mostly dopamine.
9
12
97
5,684

The more I play around with GEPA the more I realize its not just a prompt optimization algorithm.
Its really the most efficient way to have an LLM explore a massive dataset and and make useful insights.
This visualizer alone shows just how cool that process is.
21
108
1,387
118,946
Christian Langreiter retweeted

May 21
I had to do this of course - test out the new Google Omni Flash model with my favorite 3d art sandbox - Dreams. Just a quick test for now.. I'll be sharing more examples and techniques soon but wanted to show you this one. There's something very fitting about combining "handmade" 3d models and animations sculpted from scratch in software that runs on 2013 hardware, with some of the most advanced AI technology in the world.
As part of my work for Google, I've used Google V2V models on a few different projects now - Ancestra, Dear Upstairs Neighbors and most recently one of the IO films (I'll share more about that project soon) 🥰 - and video continues to be my favorite form of input for Generative Ai workflows.
If an image says more than a thousand words, a video says more than a million. And knowing that these capabilities are now in the hands of all of you, makes me very excited to see the new workflows and projects that will come out of it.
What do you think of Omni so far?
29
38
486
38,150
Christian Langreiter retweeted

May 21
I uploaded a screenshot of Google Maps to Gemini Omni with a route drawn on it.
Then I prompted it to create a first person view of someone driving a taxi cab along the route in the reference image.
Pretty close to the real thing.
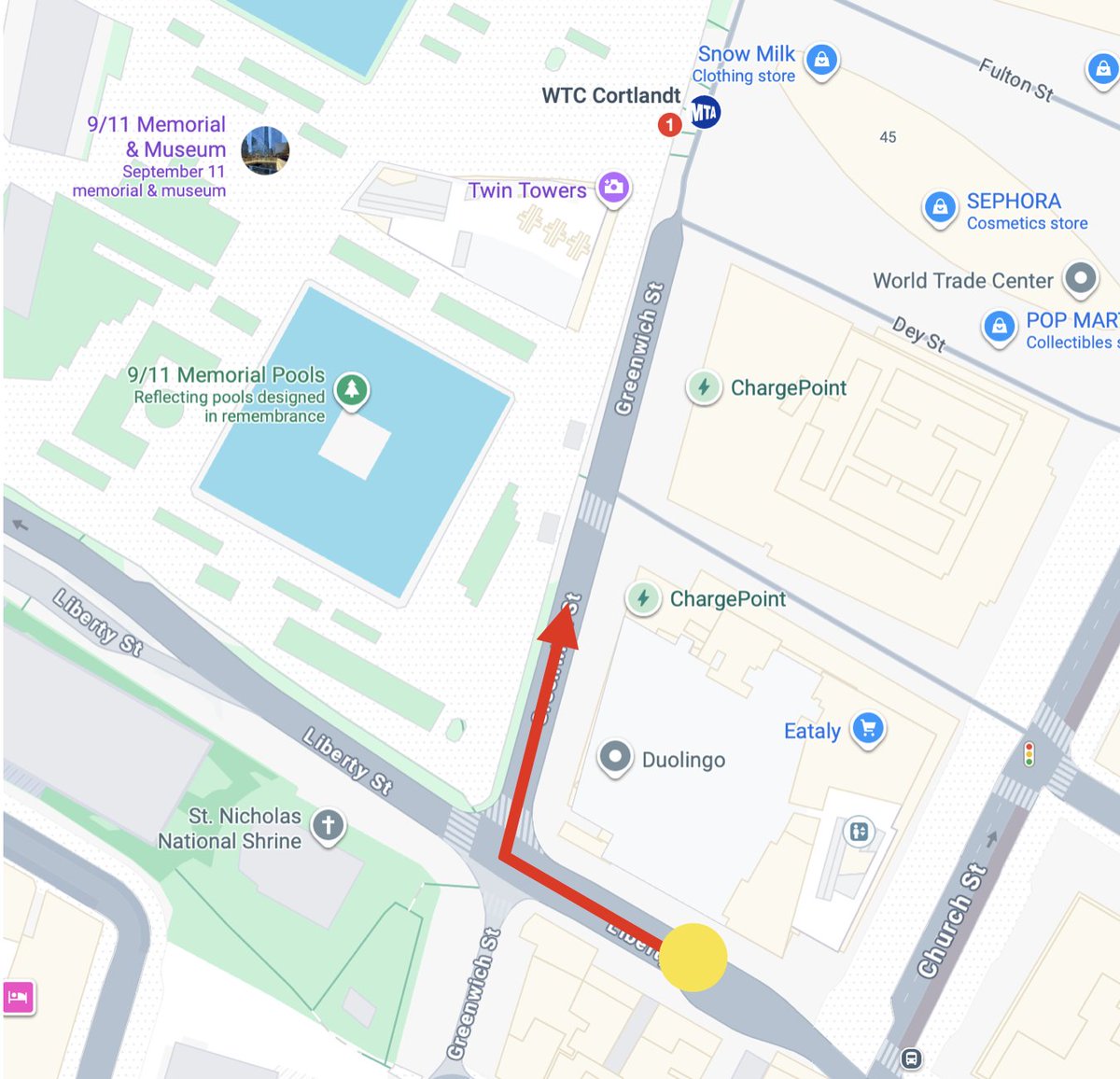
81
207
2,330
2,582,284
May 20
(just realized I hadn't used a "share link": x.com/i/grok/share/0bfc7dcf1…; fwiw, I'd agree with the general sentiment ...)
25
Christian Langreiter retweeted

May 15
It's funny seeing this because ~2 weeks ago I used my 5090 to train a Monet LoRA for Qwen Image
If anyone wants the .safetensors say below, I also have J. Atkinson Grimshaw, Edward Hopper, Charles Demuth, etc
Sample output for:
> a painting of an impressionist pond scene dense with clusters of green lily pads floating on rippling blue water, scattered white water lilies with yellow centers and small pink blooms, vertical green reeds and vegetation along the left edge, soft dappled light with reflections of sky and foliage, thick visible brushstrokes, muted blues greens and earth tones in the style of monet water lilies series


i just generated an image in the style of a Monet painting using AI
please describe, in as much detail as possible, what makes this inferior to a real Monet painting

2
2
9
2,238
Christian Langreiter retweeted

May 7
Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
307
1,674
11,182
3,159,715
Christian Langreiter retweeted

May 14
This one blew my mind back in the day!
From "Learning Invariant Features through Topographic Filter Maps" (2009) by @koraykv, @MarcRanzato, @rob_fergus and @ylecun



19
26
257
91,430
Christian Langreiter retweeted

May 13
We’re training models wrong and it’s due to chatGPT. Even the modern coding agents used daily still use message-based exchanges: They send messages to users, to themselves (CoT) and to tools, and receive messages in turn.
This bottlenecks even very intelligent agents to a single stream. The models cannot read while writing, cannot act while thinking and cannot think while processing information.
In our new paper, see below, we discuss LLMs with parallel streams. We show that multi-stream LLMs can …
🔵Be created by instruction-tuning for the stream format
🔵Simplify user and tool use UX removing many pain points with agents and chat models (such as having to interrupt the model to get a word in)
🔵Multi-Stream LLMs are fast, they can predict read tokens in all streams in parallel in each forward pass, improving latency
🔵 LLMs with multiple streams have an easier time encoding a separation of concerns, improving security
🔵 LLMs with many internal streams provide a legible form of parallel/cont. reasoning. Even if the main CoT stream is accidentally pressured or too focused on a particular task to voice concerns, other internal streams can subvocalize concerns that would otherwise not be verbalized.
Does this sound related to a recent thinky post :) - Yes, but I don’t feel so bad about being outshipped with such a cool report on their side by 23 hours. I’ll link a 2nd thread below with a more direct comparison. I actually think both are complementary in interesting ways.
42
168
1,365
157,038
Christian Langreiter retweeted

May 9
I feel it’s really unhelpful that searching for “deep RL” sends you to Q learning, MDPs, Bellman’s equation etc, when it’s literally just
Run LLM agent on data -> was it good? -> policy gradient /- reward
Like that’s actually it! And LLMs are just stacks of attn MLP
29
14
439
64,514
Christian Langreiter retweeted

Falls das Nerds lesen, die sich für mein epistemologisches Modell KI-gestützter Wissensarbeit (#KIWA) interessieren: Hier ist eine lesbare Zusammenfassung (feat. Lotman, Wittgenstein, Neurath, Steven Johnson, Brecht, Benn).
docs.google.com/document/d/1…
2
2
5
160
Christian Langreiter retweeted

May 7
Robots don't need a human face.
Instead of building a humanoid face, we use a real human face as a controller for Reachy Mini's existing non-human face.
Open source, runs in your browser. 🧵
18
36
375
66,692