
CAIO @soaruplift | PhD | Adj. Asst. Prof. @utcompsci | Former AI Resident @OpenAI | CS @StanfordEng | ❤️ Dogs & Lifting Weights
Joined November 2009
- Tweets 641
- Following 2,333
- Followers 1,243
- Likes 1,816
40 Photos and videos













Openclaude v0.11.0 just shipped with a FREE
frontier-grade LLM out of the box via OpenGateway
No API key. No signup. No card on file
Powered by @XiaomiMiMo
77
131
888
77,906

Fatma Tarlaci retweeted

Apr 27
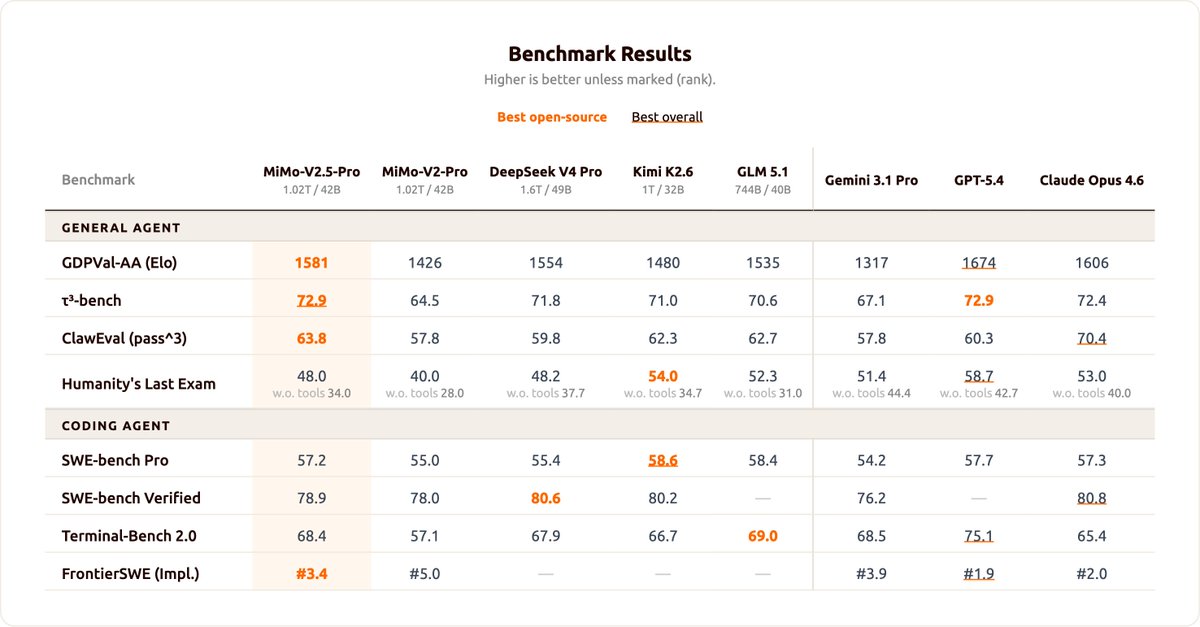
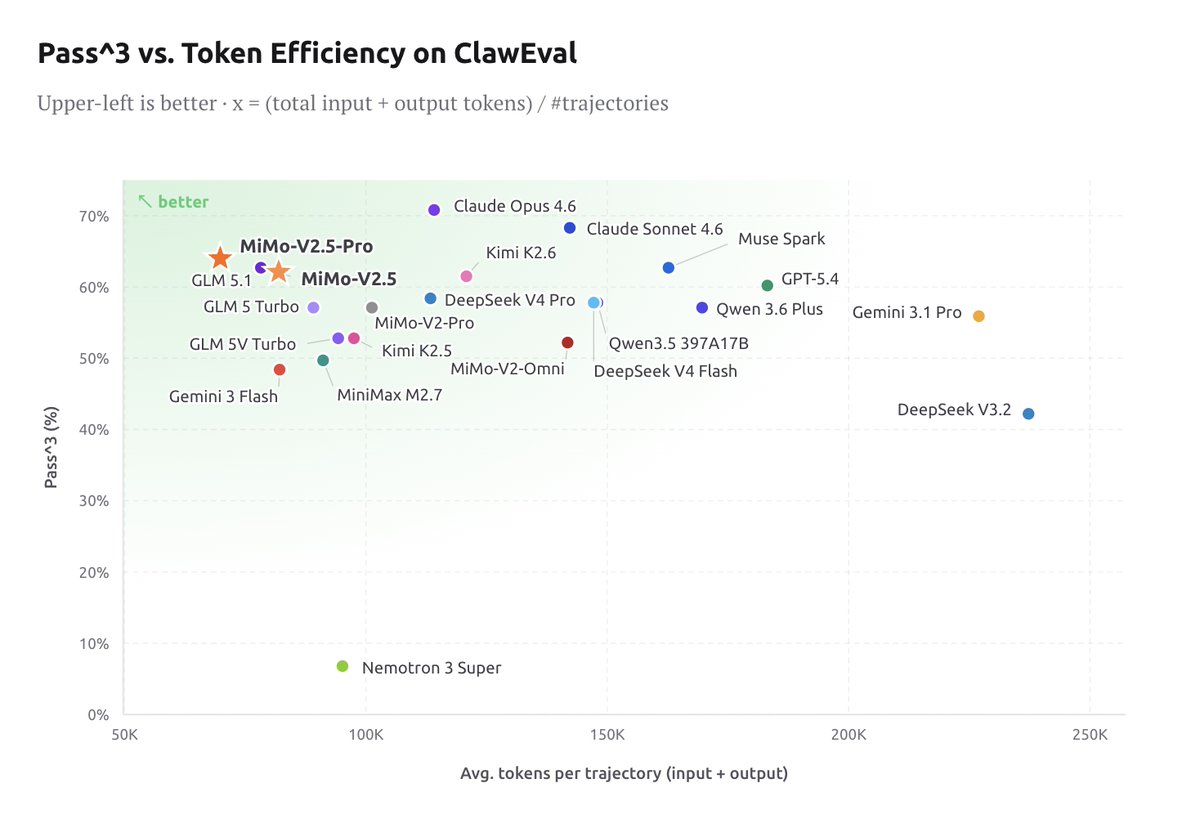
Xiaomi MiMo-V2.5 is now officially open-sourced!
MIT License, supporting commercial deployment, continued training, and fine-tuning - no additional authorization required.
Two models, both supporting a 1M-token context window :
• MiMo-V2.5-Pro: built for complex agent and coding tasks, ranking No.1 among open-source models on GDPVal-AA and ClawEval
• MiMo-V2.5: a native omni-modal model with strong agent capabilities
A model's value isn't measured by rankings alone — it's measured by the problems it solves.
Let's build with MiMo now!
🤗 Weights: huggingface.co/collections/X…
📄 Blog: mimo.xiaomi.com/index#blog
151
464
3,432
807,491
Fatma Tarlaci retweeted

May 6
🌍 "We're not here to go make the people who blew up the world economy in 2008 even bigger and even richer," @IOHK_Charles said at Consensus 2026.
"We're here to change the world...I don't care if you want to do that from the lens of a Solana or $XRP or #Bitcoin or Cardano." 💬
May 6

🎙️ "Back when we started, JP Morgan was turning people's bank accounts off and now they have a blockchain product," Charles Hoskinson said at Consensus 2026.
"How about that? That's winning," adds @IOHK_Charles.
15
56
262
13,462
Fatma Tarlaci retweeted

Apr 30
Anthropic CISO just told you that 90% of their code is written by Claude.
Then he explained how they protect their own secrets while doing it.
Why your .env file is the weakest link in your entire AI workflow?
Watch it, then grab the full security config below👇

46
130
1,220
450,102

Introducing Claude Managed Agents: everything you need to build and deploy agents at scale.
It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days.
Now in public beta on the Claude Platform.
2,118
5,979
56,814
21,661,738
Fatma Tarlaci retweeted

Apr 6
I've combined Manim @NousResearch's Hermes Agent skill @yifanzhang_'s Math Code.
Math Code executes the proof on a problem called Jordan's Lemma and Hermes Agent with @claudeai Sonnet 3.7 directs Math Code, writes a script, gets Manim to render an explanatory video.
Jordan's Lemma: It helps to simplify high-dimensional problems by breaking them down into manageable, 2D pieces. The lemma is the underlying mathematical reason why Grover's Algorithm (useful in quantum) works by rotating within a 2D plane.
Rendered explanation video below:
x.com/yifan_zhang_/status/20…
Apr 5

Introducing the Manim skill for Hermes Agent.
Manim is an engine for creating precise programmatic animations for mathematical and technical explainers, made famous by the @3blue1brown channel.
15
53
592
141,860
Fatma Tarlaci retweeted

Apr 2
Prediction: This is gonna kill some oss projects.
"On the kernel security list we've seen a huge bump of reports. We were between 2 and 3 per week maybe two years ago, then reached probably 10 a week over the last year with the only difference being only AI slop, and now since the beginning of the year we're around 5-10 per day depending on the days (fridays and tuesdays seem the worst). Now most of these reports are correct, to the point that we had to bring in more maintainers to help us." lwn.net/Articles/1065620/
96
73
1,409
319,616




Sequoia’s @JulienBek says many of their founders are now wondering if they’re “just an iteration away” from AI labs destroying their business.
He says the most defensible companies - and potentially the next trillion-dollar company - will be “a software business that masquerades as a services firm.”
“If you sell tools today, you’re really in the line of sight for the models and you’re effectively competing with the next generation that they’re going to launch.”
“Whereas if you sell the work, you’re actually benefiting from what the models are doing and all the billions of dollars that are going towards AI.”

70
132
1,797
683,077
Fatma Tarlaci retweeted

Mar 9
My information consumption is now 1/4 X, 1/4 podcast interviews of the smartest practitioners, 1/4 talking to the leading AI models, and 1/4 reading old books. The opportunity cost of anything else is far too high, and rising daily.
1,435
3,906
35,043
34,643,724
Fatma Tarlaci retweeted

We've uploaded a fruit fly. We took the @FlyWireNews connectome of the fruit fly brain, applied a simple neuron model (@Philip_Shiu Nature 2024) and used it to control a MuJoCo physics-simulated body, closing the loop from neural activation to action.
A few things I want to say about what this means and where we're going at @eonsys. 🧵
327
1,300
7,943
1,780,100
Fatma Tarlaci retweeted

Mar 5
217
636
4,764
2,938,648


New podcast on AI (full episode). Links below.
A Motorcycle for the Mind
0:00 If you want to learn, do
2:13 Vibe coding is the new product management
6:49 Training models is the new coding
10:13 Is traditional software engineering dead?
13:07 There is no demand for average
14:12 The hottest new programming language is English
18:36 AI is adapting to us faster than we are adapting to it
22:56 No entrepreneur is worried about AI taking their job
26:46 The goal is not to have a job
29:49 AIs are not alive
32:55 AI fails the only true test of intelligence
36:49 Early adopters of AI have an enormous edge
39:37 AI meets you exactly where you are
43:02 Always leverage the best intelligence
44:37 If you can't define it, you can't program it
49:37 The solution to AI anxiety is action
456
2,139
14,759
2,349,529
Fatma Tarlaci retweeted

Feb 19
Today, we’re introducing Pomelli’s latest feature update, ‘Photoshoot’
With Photoshoot, you can start from a single image of your product and easily create high quality, customized product shots to elevate your marketing.
Available free of charge in the US, Canada, Australia & New Zealand! Get started with Pomelli today at labs.google/pomelli
1,163
4,643
49,663
24,093,516
Fatma Tarlaci retweeted
Feb 19
New @openclaw beta is up! Mostly security hardening and fixes today.
Ther'e also an early version of an Apple Watch app in there if you wanna go digging in the repo... github.com/openclaw/openclaw…
209
175
2,942
160,792
Fatma Tarlaci retweeted

Feb 11
On DeepWiki and increasing malleability of software.
This starts as partially a post on appreciation to DeepWiki, which I routinely find very useful and I think more people would find useful to know about. I went through a few iterations of use:
Their first feature was that it auto-builds wiki pages for github repos (e.g. nanochat here) with quick Q&A:
deepwiki.com/karpathy/nanoch…
Just swap "github" to "deepwiki" in the URL for any repo and you can instantly Q&A against it. For example, yesterday I was curious about "how does torchao implement fp8 training?". I find that in *many* cases, library docs can be spotty and outdated and bad, but directly asking questions to the code via DeepWiki works very well. The code is the source of truth and LLMs are increasingly able to understand it.
But then I realized that in many cases it's even a lot more powerful not being the direct (human) consumer of this information/functionality, but giving your agent access to DeepWiki via MCP. So e.g. yesterday I faced some annoyances with using torchao library for fp8 training and I had the suspicion that the whole thing really shouldn't be that complicated (wait shouldn't this be a Function like Linear except with a few extra casts and 3 calls to torch._scaled_mm?) so I tried:
"Use DeepWiki MCP and Github CLI to look at how torchao implements fp8 training. Is it possible to 'rip out' the functionality? Implement nanochat/fp8.py that has identical API but is fully self-contained"
Claude went off for 5 minutes and came back with 150 lines of clean code that worked out of the box, with tests proving equivalent results, which allowed me to delete torchao as repo dependency, and for some reason I still don't fully understand (I think it has to do with internals of torch compile) - this simple version runs 3% faster. The agent also found a lot of tiny implementation details that actually do matter, that I may have naively missed otherwise and that would have been very hard for maintainers to keep docs about. Tricks around numerics, dtypes, autocast, meta device, torch compile interactions so I learned a lot from the process too. So this is now the default fp8 training implementation for nanochat
github.com/karpathy/nanochat…
Anyway TLDR I find this combo of DeepWiki MCP GitHub CLI is quite powerful to "rip out" any specific functionality from any github repo and target it for the very specific use case that you have in mind, and it actually kind of works now in some cases. Maybe you don't download, configure and take dependency on a giant monolithic library, maybe you point your agent at it and rip out the exact part you need. Maybe this informs how we write software more generally to actively encourage this workflow - e.g. building more "bacterial code", code that is less tangled, more self-contained, more dependency-free, more stateless, much easier to rip out from the repo (x.com/karpathy/status/194161…)
There's obvious downsides and risks to this, but it is fundamentally a new option that was not possible or economical before (it would have cost too much time) but now with agents, it is. Software might become a lot more fluid and malleable. "Libraries are over, LLMs are the new compiler" :). And does your project really need its 100MB of dependencies?
5 Jul 2025

How to build a thriving open source community by writing code like bacteria do 🦠. Bacterial code (genomes) are:
- small (each line of code costs energy)
- modular (organized into groups of swappable operons)
- self-contained (easily "copy paste-able" via horizontal gene transfer)
If chunks of code are small, modular, self-contained and trivial to copy-and-paste, the community can thrive via horizontal gene transfer. For any function (gene) or class (operon) that you write: can you imagine someone going "yoink" without knowing the rest of your code or having to import anything new, to gain a benefit? Could your code be a trending GitHub gist?
This coding style guide has allowed bacteria to colonize every ecological nook from cold to hot to acidic or alkaline in the depths of the Earth and the vacuum of space, along with an insane diversity of carbon anabolism, energy metabolism, etc. It excels at rapid prototyping but... it can't build complex life. By comparison, the eukaryotic genome is a significantly larger, more complex, organized and coupled monorepo. Significantly less inventive but necessary for complex life - for building entire organs and coordinating their activity. With our advantage of intelligent design, it should possible to take advantage of both. Build a eukaryotic monorepo backbone if you have to, but maximize bacterial DNA.
299
764
7,242
1,114,279
Fatma Tarlaci retweeted

Feb 12
A deep dive on the Claude Agent SDK - everything you need to know about deployment
00:00 Intro
01:08 The agent loop
03:23 Core primitives
05:30 Tools vs MCP vs skills
07:08 Context windows
10:47 Building on Replit
15:17 Creating a Todoist agent
22:06 Debugging
28:23 Deployment
16
64
515
29,285
Fatma Tarlaci retweeted

Feb 11
495
1,933
7,807
2,405,582