
RS @GoogleDeepMind | PhD @ELLISforEurope 🇪🇺 w/ @zeynepakata & @OriolVinyalsML; Large Models × {Lifelong, Data, Multimodal} | Views are my own.
Joined June 2019
- Tweets 351
- Following 500
- Followers 1,499
- Likes 4,521
54 Photos and videos





Pinned Tweet

4 Aug 2025
💫 After four PhD years on all things multimodal, pre- and post-training, I’m super excited for a new research chapter @GoogleDeepMind 🇨🇭!
Biggest thanks to @zeynepakata and @OriolVinyalsML for all the guidance, support, and incredibly eventful and defining research years ♥️!


23
12
390
34,013
Karsten Roth retweeted

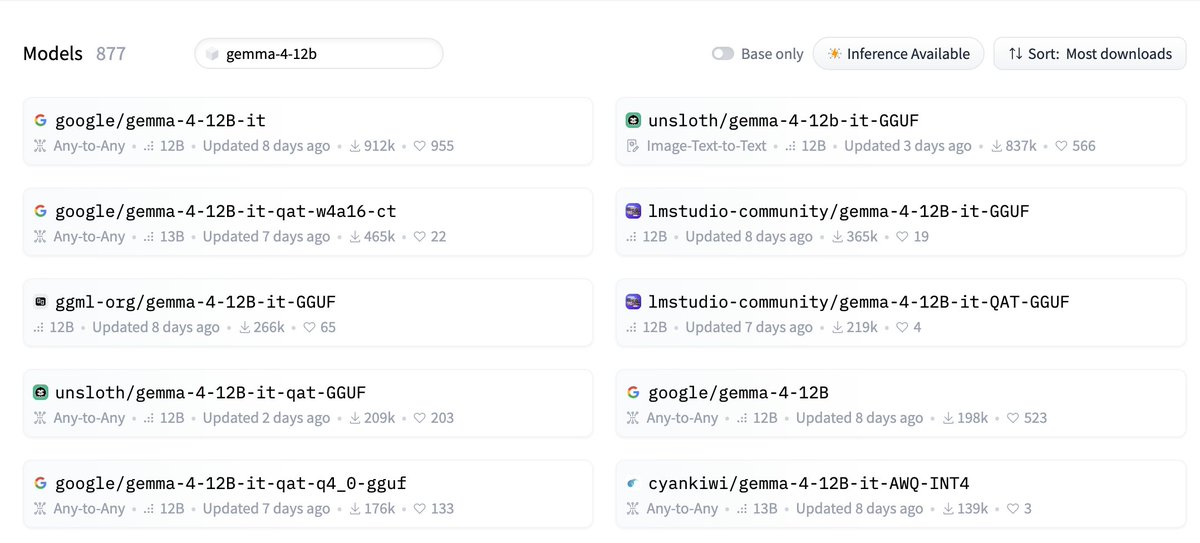
Released last week, and already more than 4M downloads on HuggingFace alone 😊
This makes Gemma 4 12B the most popular encoderfree VLM by a large margin.
In addition to being the first-ever general purpose LLM with encoderfree audio input!
Jun 3

Our new Gemma 4 12B model hits a sweet spot between size performance: it can run locally on a laptop, while enabling powerful multi-step reasoning and agentic workflows. Can’t wait to see what the community does with this one!
12
33
151
47,044
Karsten Roth retweeted

Jun 5
We just dropped Gemma 4 Quantization-Aware Training (QAT) checkpoints on Hugging Face!
All Gemma 4 model sizes and their drafters are now optimized with QAT to cut memory requirements and maximize on-device performance!
96
282
2,854
502,649
Karsten Roth retweeted

This video is at normal speed. Gemma 4 12B MLX version running locally at 50 tokens/sec.
Thank you Google DeepMind team. This model feels really solid for a lot of small local tasks and everyday AI workflows.
16
15
244
19,758
Karsten Roth retweeted

Jun 4
I am SO excited to be sharing that I am joining @BerntBornich and @1x_tech to lead the new 1X World Model Lab aimed at building the next frontier of embodied AI! The core guiding principle of the lab is: scale up along every damn axis!! 🚀
Robotics data is NOT a second-class citizen - it is too important of a problem to be left to fine tuning! Your model needs to see your most important tokens from step 0
We need to think about robotics through the first principles of AI: how do we best utilize the vast amounts of web-scale media and how do we create a data-flywheel to collect millions of hours of rich robot interactions. There is no other moat in AI outside of data and @1x_tech has done an INCREDIBLE job scaling manufacturing, production and hardware to build humanoid robots that can create a unique data-flywheel in unstructured environments. Scaling data collection for highly dexterous on-policy robot data will be the only way for creating a moat in AI. @JackMonas and team have made great progress in building World Models, and now the goal is to supercharge this effort by starting a hyper-focused scale and data-pilled lab.
Before scaling compute / data / models, we are currently RAPIDLY scaling our team and hiring across the 4 core pillars of AI: model data, data infra, ML infra and evals. Looking for folks that are excited about the 0->1 problem and share the same principles as us. There’s a single application for everyone in the lab - if you’re a good at engineering and ML, we will find a place for you in the team ❤️
AGI won’t be solved by fine-tuning… Let’s build the next frontier of AI together 🚀
My DMs are always open!!
Jun 4

We’re going all in on World Models.
Today we’re launching the 1X World Model Lab.
The bet is simple:
You can’t fine-tune your way to AGI.
And you definitely can’t fine-tune your way to robots that can operate in the physical world.
General-purpose humanoids need models that understand space, motion, objects, causality, affordances, physics, and action before they ever see a specific task.
The frontier is not better VLA wrappers.
The frontier is embodied world models.
The 1X World Model Lab will focus on large-scale embodied world model pretraining: building the most generalizable foundation model for humanoid robots from the ground up.
The next frontier in AI requires scaling:
web-scale media egocentric human videos sim dexterous remote operated robot data on-policy NEO data → real-world deployment for robot data collection and RL → abundance of data → physical AI
The robot collects data.
The model gets better.
The robot gets better.
Repeat.
To lead this, we brought in one of the best for the mission: @_sam_sinha_ , as Head of World Models.
Sam was a founding research scientist at Luma AI and has been at the frontier of scaling multimodal generative video models his whole career.
If you’re the best in the world at large-scale pretraining, video models, robotics, RL, infra, or data — and you want your models to move atoms, not just pixels — join us.
Send background evidence of exceptional ability to:
wmlab@1x.tech
We’re building the model that makes autonomous labor real.

60
28
420
93,047
Karsten Roth retweeted

Gemma 4 12B was a large team effort over more than a year. The model’s encoder-free tech was developed by @ASusanoPinto @AndreasPSteiner @confusezius @kmisiunas & myself with many contributions from @ashkamath20 @LawrenceSt72142 @OlivierBachem @armandjoulin & the whole Gemma Team

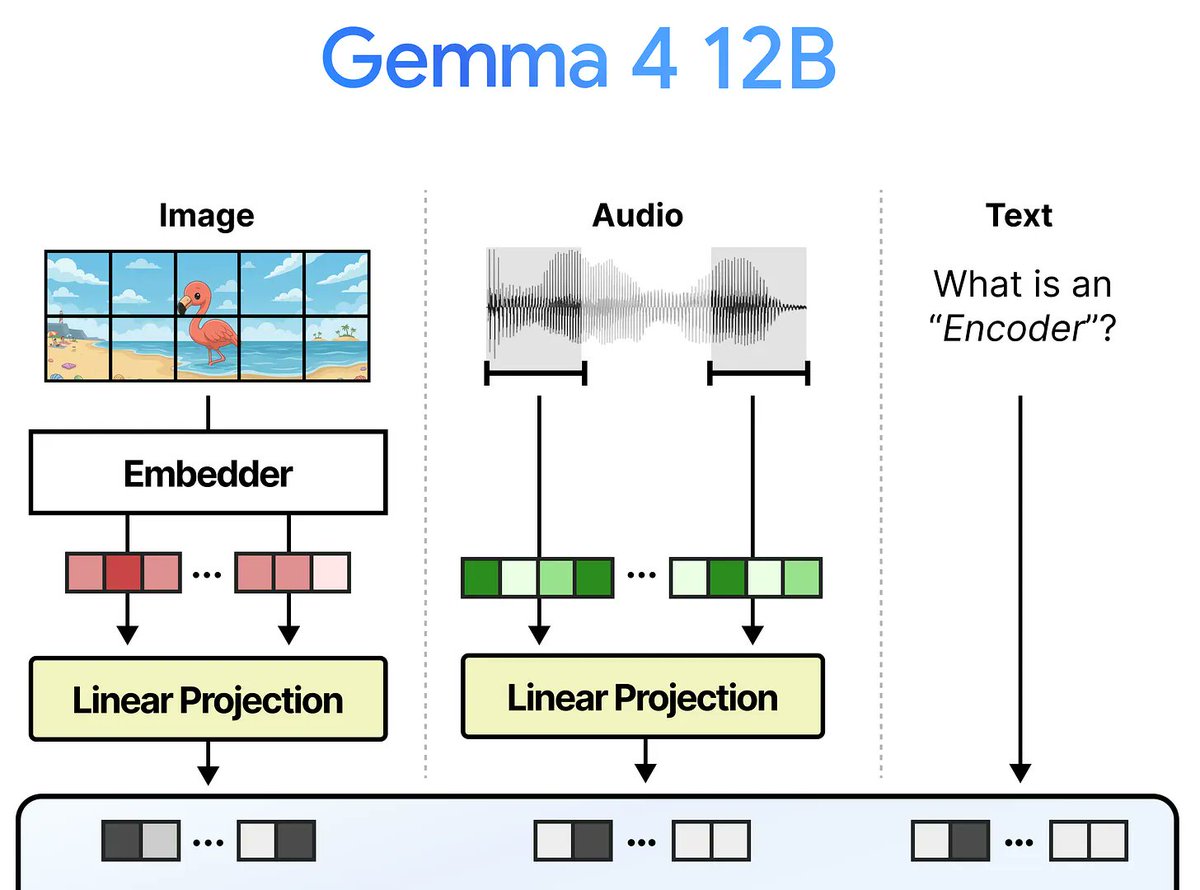
For the past years my research focus was on unifying models and training paradigms across modalities. Today I'm excited that we're releasing our latest model aligned with this theme:
Gemma 4 12B, a dense encoder-free model which processes raw text, image, and audio inputs!
1/
5
5
63
5,721
Karsten Roth retweeted
For the past years my research focus was on unifying models and training paradigms across modalities. Today I'm excited that we're releasing our latest model aligned with this theme:
Gemma 4 12B, a dense encoder-free model which processes raw text, image, and audio inputs!
1/
27
129
1,124
108,126
Karsten Roth retweeted

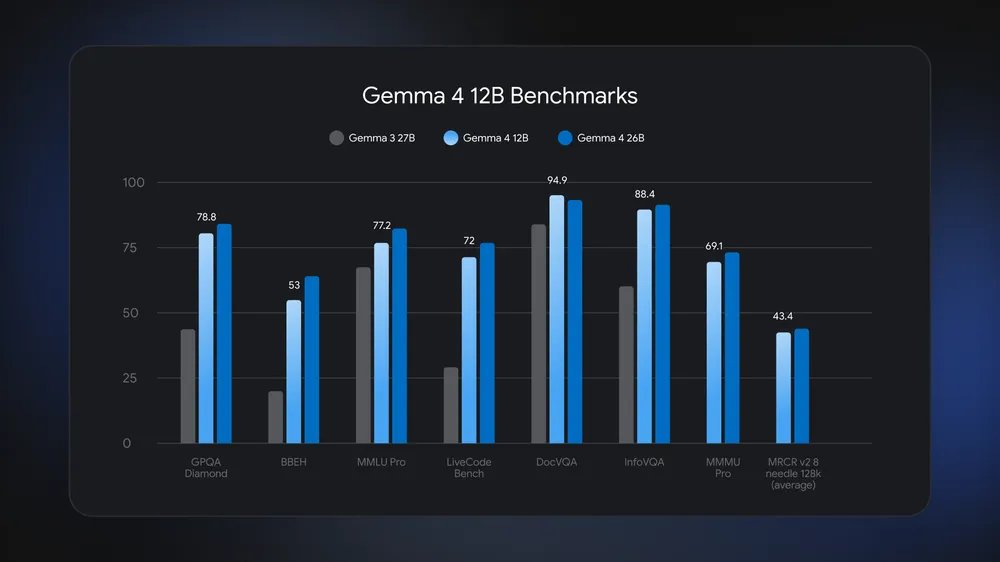
Gemma 4 Encoder-Free is here!! 🥳📷🔊
Super excited by this Gemma 4 12B model with great performance on vision and audio, without modality specific encoders. Closing in on the 26B while being 2x smaller in memory!
Available now on Hugging Face, Kaggle, llama.cpp, and others!

Gemma 4 12B in action: Object detection, function calling, voice command, segmentation, language switch, translation - all of this and much more without vision/audio encoders!
(Inputs and outputs are real, but FC2 data shown as code, and generation speedified)
1
5
13
2,055
Jun 3
So exciting to help build encoder-free Gemma from scratch! Amazing to see all modalities intertwined in one single LLM decoder 🧬.
Bonus for my academic heart ❤️👓: it's simple to run and brings some new architectural insights to the OSS community!
🧵1/n
Jun 3

Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇

1
12
53
4,572
Jun 3
For some more context, there are some great resources to look into!
The Keyword: blog.google/innovation-and-a…
Dev Blog: developers.googleblog.com/ge…
And in particular the Visual Guide for the more nitty-gritty details: newsletter.maartengrootendor…
1
1
3
370
Jun 3
Such a great time working with @ASusanoPinto, @AndreasPSteiner , @kmisiunas , @mtschannen to set up encoder-free training, and working alongside everyone else in the amazing @googlegemma team!
1
151
Karsten Roth retweeted
Jun 3
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇
403
1,748
12,376
3,185,590
Karsten Roth retweeted
Gemma 4 12B in action: Object detection, function calling, voice command, segmentation, language switch, translation - all of this and much more without vision/audio encoders!
(Inputs and outputs are real, but FC2 data shown as code, and generation speedified)
2
8
48
10,229
Karsten Roth retweeted

Really proud of everyone in the team that worked hard for this release: Gemma 4 is here! blog.google/innovation-and-a…
5
14
111
3,567
Karsten Roth retweeted
Apr 2
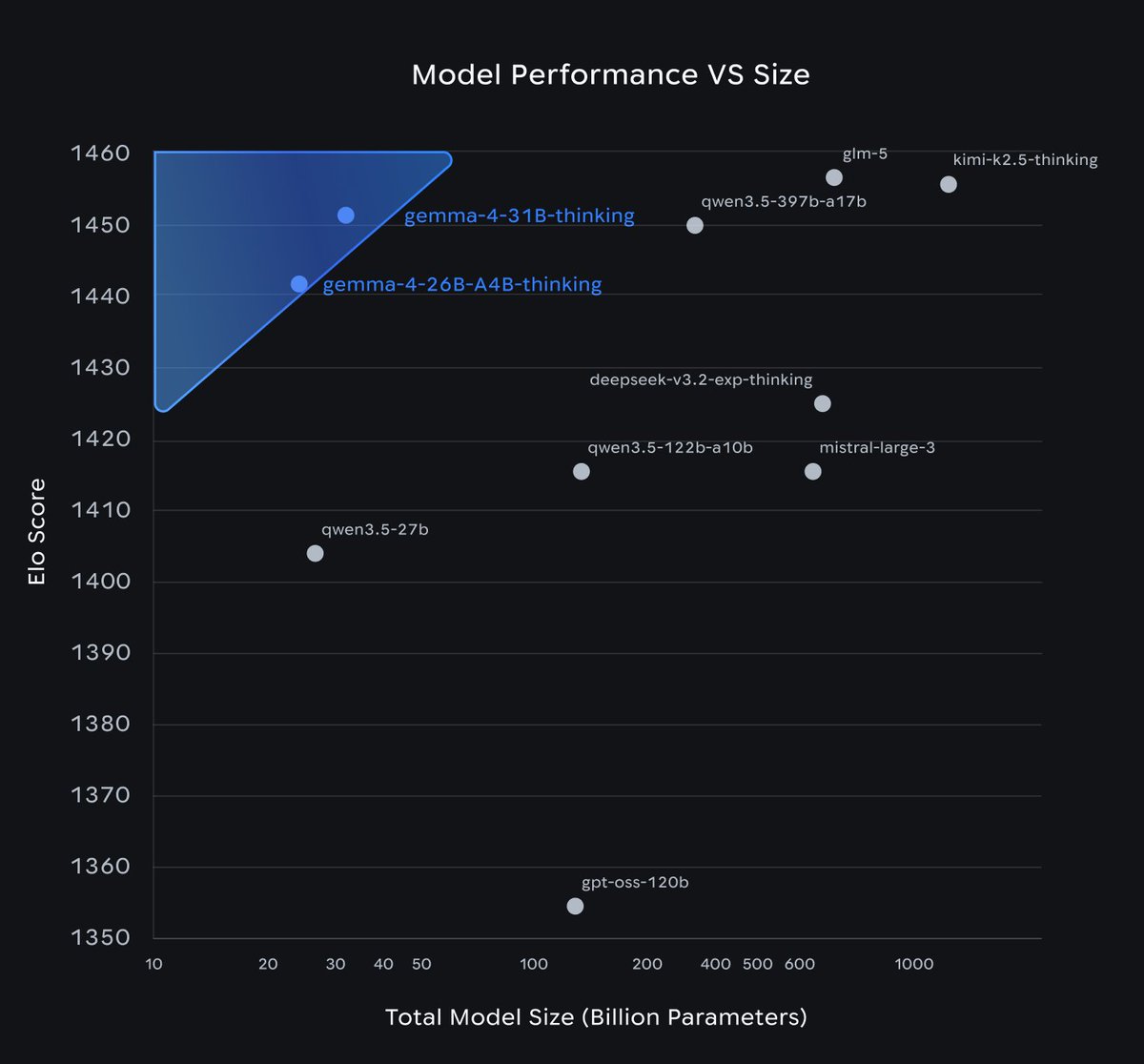
Meet Gemma 4!
Purpose-built for advanced reasoning and agentic workflows on the hardware you own, and released under an Apache 2.0 license.
We listened to invaluable community feedback in developing these models. Here is what makes Gemma 4 our most capable open models yet: 👇
167
836
7,150
626,917
4 Aug 2025
💫 After four PhD years on all things multimodal, pre- and post-training, I’m super excited for a new research chapter @GoogleDeepMind 🇨🇭!
Biggest thanks to @zeynepakata and @OriolVinyalsML for all the guidance, support, and incredibly eventful and defining research years ♥️!
23
12
390
34,013
4 Aug 2025
Huge thanks also to my committee @pegehler, @MatthiasBethge, @wielandbr and @phillip_isola!
Of course, this wouldn't have been possible without all the wonderful people & collaborators I had the pleasure of spending time with these past years!
Excited for what's to come ☺️!
1
7
1,792
4 Aug 2025
Also very thankful for the research environment provided by @ELLISforEurope and @MPI_IS, which made this PhD such an inter-european experience!
4
1,543
Karsten Roth retweeted

13 Jun 2025
I'm in Nashville for CVPR and wow, the Music City name is not exaggerated. If you're around, we'll be presenting our work on temporal model merging with @vishaal_urao, @confusezius, and @AmyPrb on Saturday 5-7 pm in ExHall D (poster #445). Come say hi!


4
3
17
2,114
13 Jun 2025
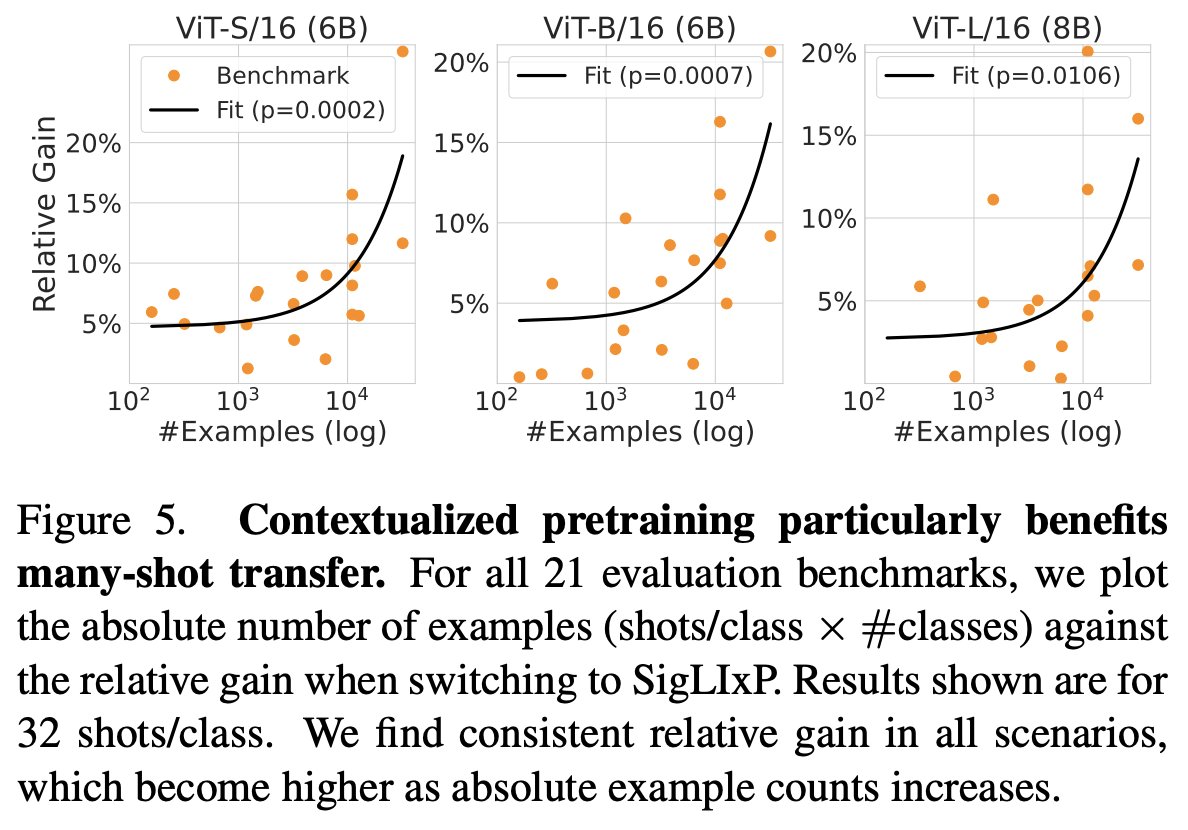
In Nashville for my last PhD conference 🥲.
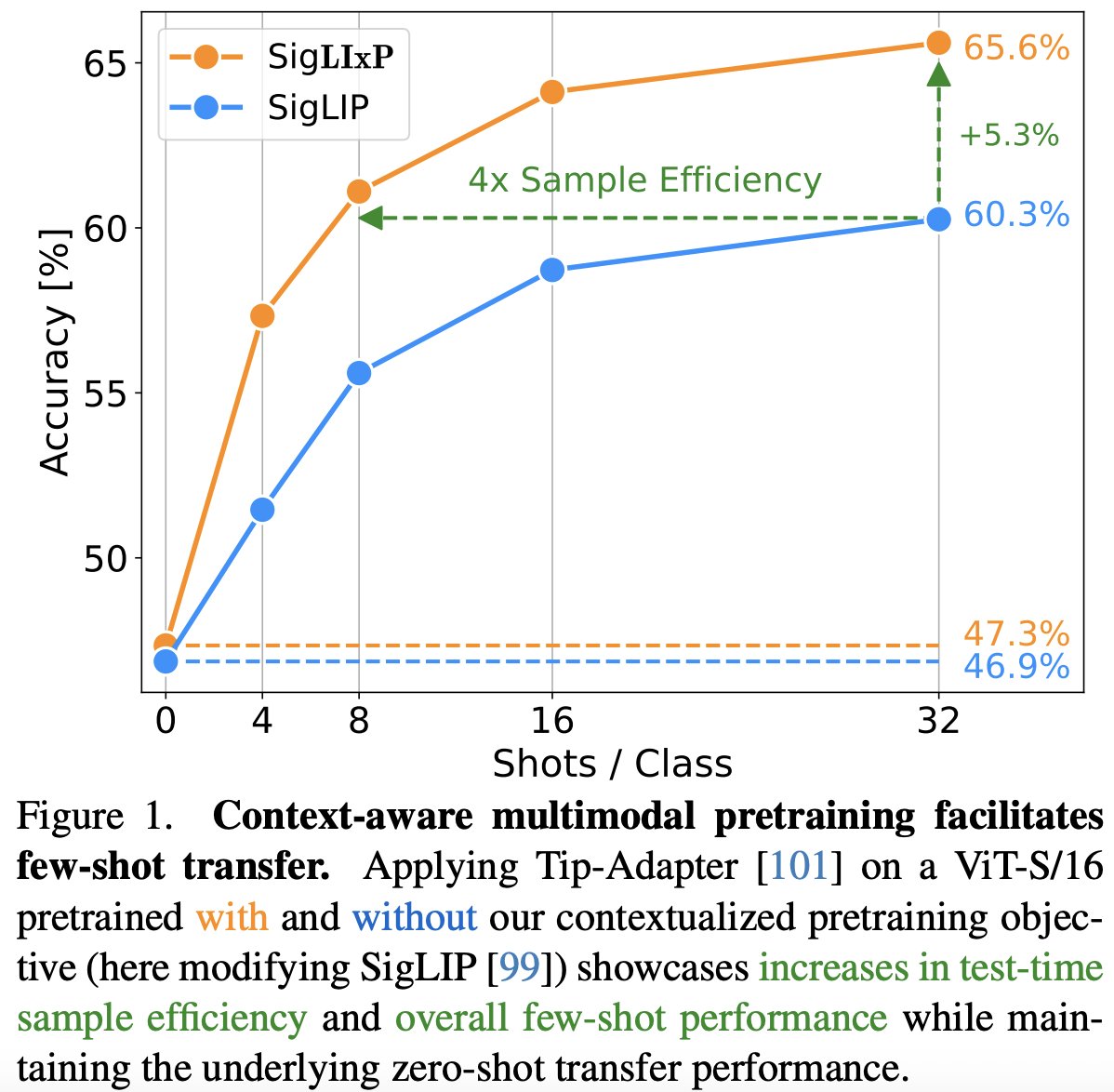
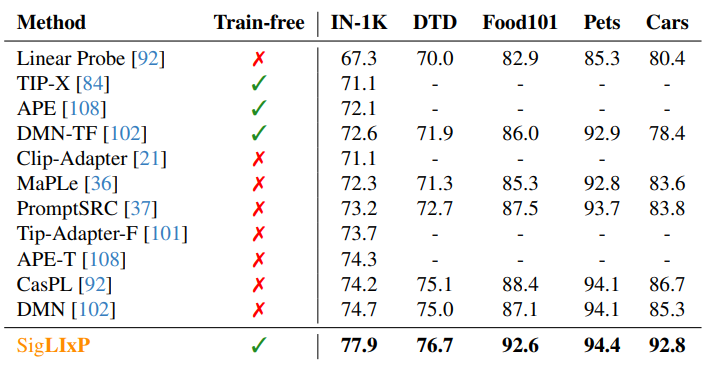
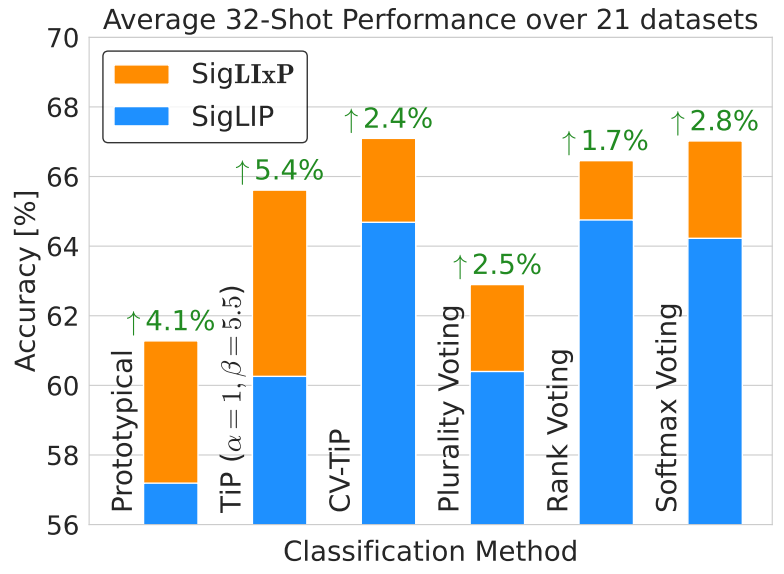
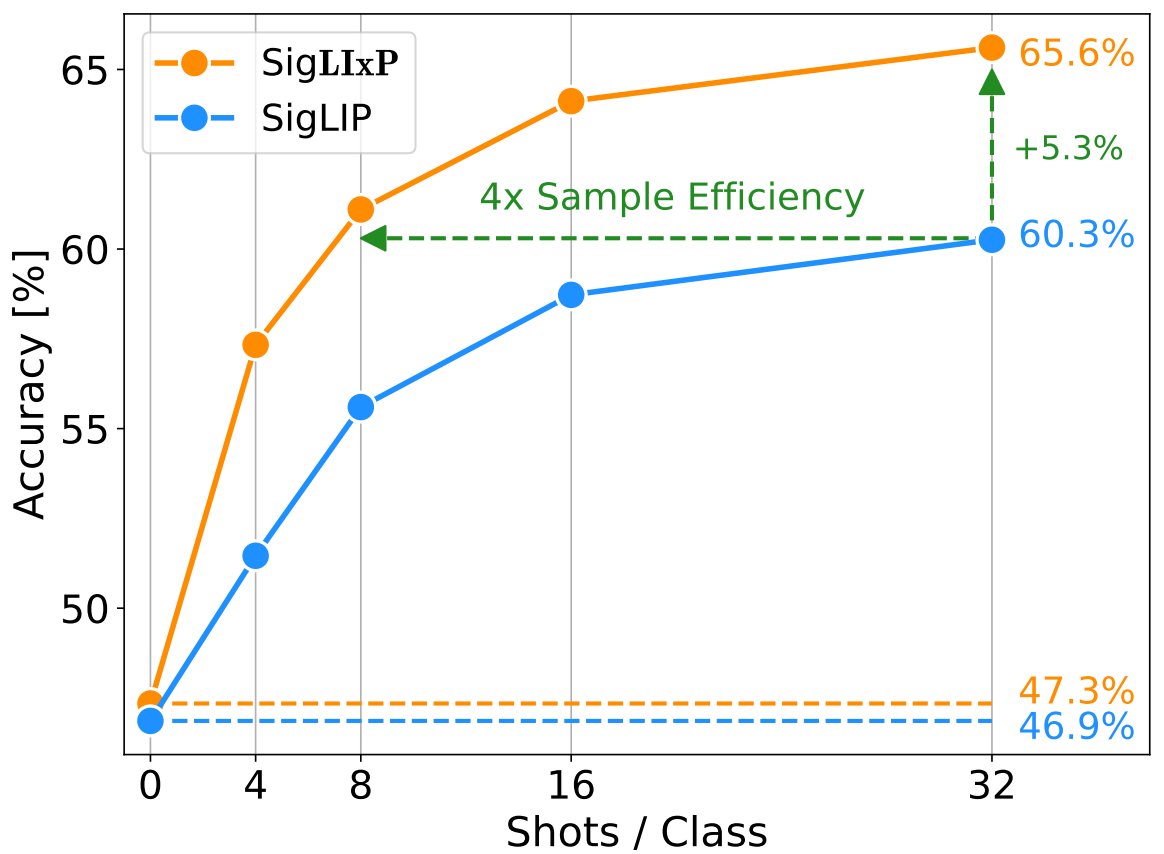
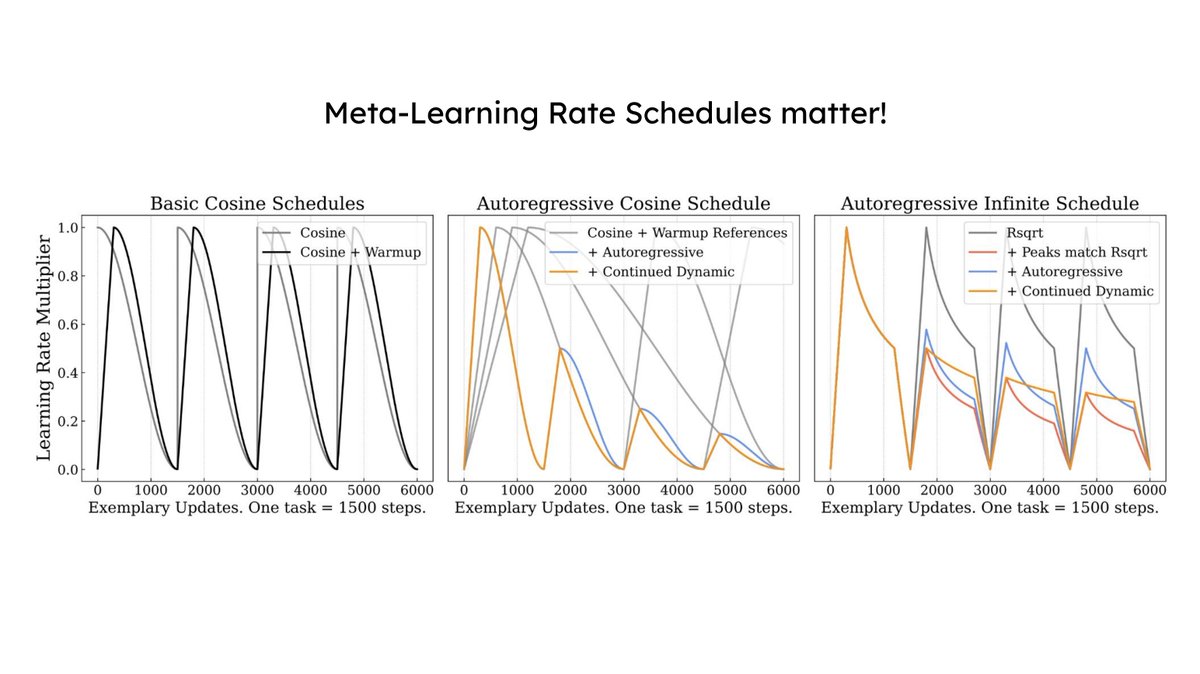
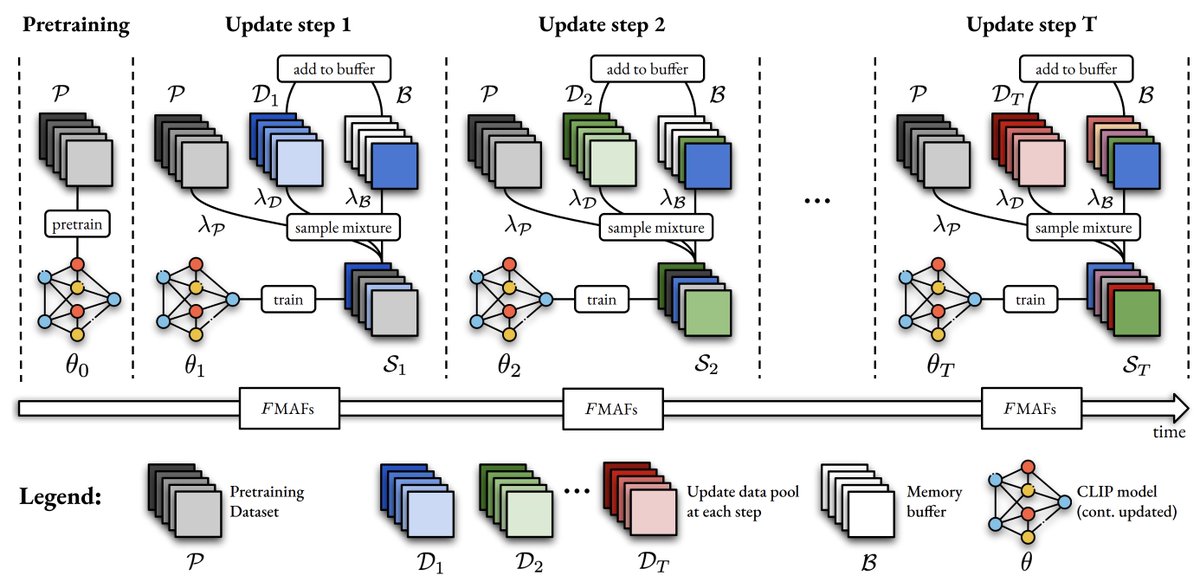
Come join today 10:30-12:30 in Hall D (#391) to talk insights, tips and tricks to modify pretraining for representation reuse - scalably.
🚀Joint work w/ @zeynepakata, @dimadamen, @ibalazevic & @olivierhenaff while at @GoogleDeepMind.
2
7
25
3,558
13 Jun 2025
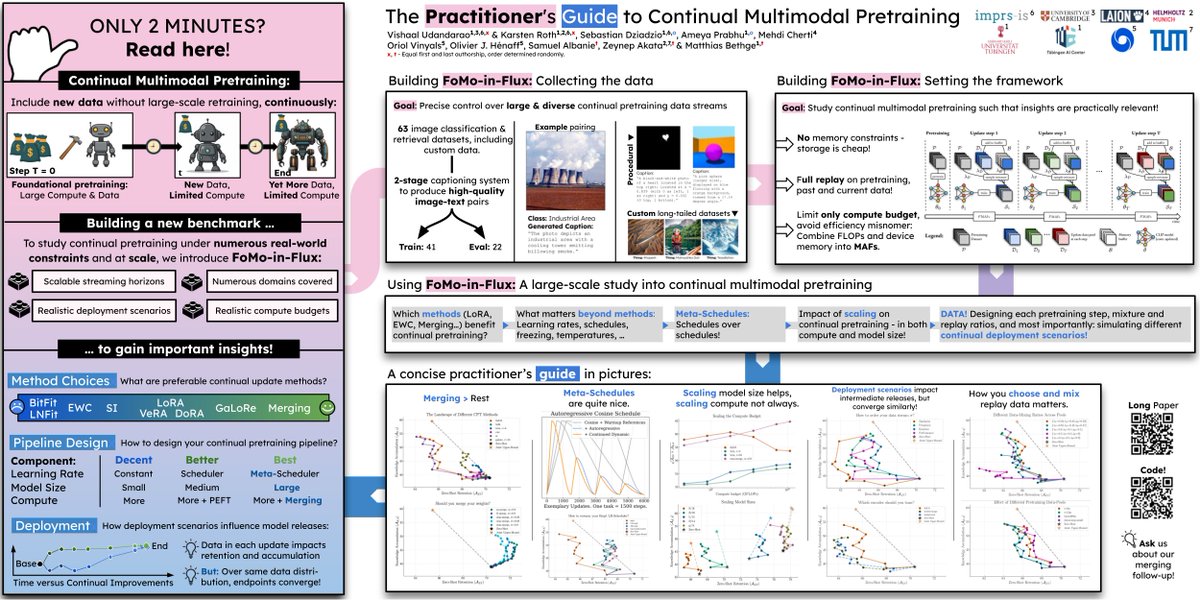
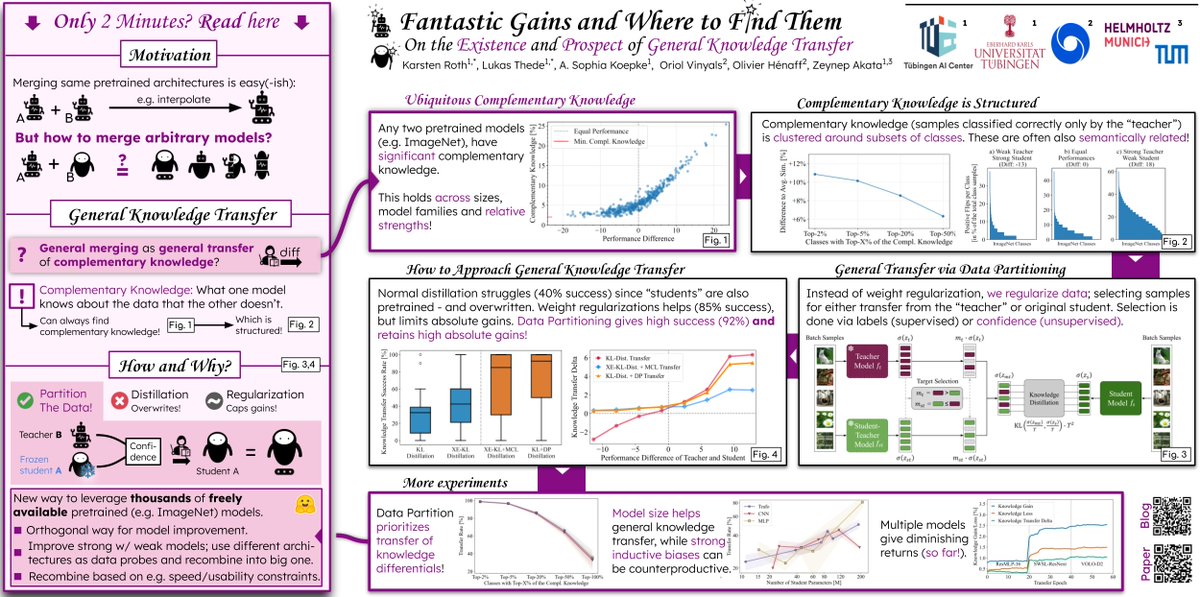
On top of that, will be presenting an exisiting joint effort with @vishaal_urao and @sbdzdz on continual model merging on sunday! All the infos here: x.com/sbdzdz/status/19333358…
13 Jun 2025

I'm in Nashville for CVPR and wow, the Music City name is not exaggerated. If you're around, we'll be presenting our work on temporal model merging with @vishaal_urao, @confusezius, and @AmyPrb on Saturday 5-7 pm in ExHall D (poster #445). Come say hi!
1
5
708
13 Jun 2025
CVPR was the first conference in my PhD, and it’s great seeing things come full circle concluding with CVPR. Looking forward to meeting everyone!
6
434