
Senior Research Scientist @GoogleDeepMind. Previously Gemini Diffusion, now making Gemini better at all things multimodal.
Joined March 2012
- Tweets 219
- Following 319
- Followers 2,217
- Likes 805
13 Photos and videos





Pinned Tweet

20 May 2025
🚀Meet Gemini Diffusion, our first diffusion-based and super fast language model, just announced at Google I/O!🚀
Very excited to be able to share what I've been working on for the past little while with our amazing small team @GoogleDeepMind.
20 May 2025

We’ve developed Gemini Diffusion: our state-of-the-art text diffusion model.
Instead of predicting text directly, it learns to generate outputs by refining noise, step-by-step. This helps it excel at coding and math, where it can iterate over solutions quickly. #GoogleIO
23
41
427
43,469
Ivana Balazevic retweeted

May 19
We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video.
It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
418
1,267
8,497
1,494,648

Ivana Balazevic retweeted

5 Dec 2025
If you’re starting a career in research, please consider researching mental illness. Felix fought immensely hard to recover and tried every treatment available to him. they werent enough. There are many people in similar positions now who need help that more research could bring
3
11
140
11,315
5 Dec 2025
💔
5 Dec 2025

Today marks 1 year since Felix died by suicide. He was my person. It’s also exactly ten yrs since we danced in a crappy nightclub and madeout the first time. These anniversaries shouldn’t go together, but they do.
@FelixHill84 was brilliant and not ashamed of his mental illness.
8
1,231
Ivana Balazevic retweeted

4 Dec 2025
i am looking for an intern to work on a project on unlearning undesired or unsafe behaviours from pretrained models. please reach out if you’re a good fit :) i’m at neurips till sunday and would love to chat.
20
19
225
18,204
Ivana Balazevic retweeted

7 Nov 2025
Are you interested to join @GoogleDeepMind as a student researcher (PhD students)?
I am hiring for a fun project on reward modeling for world models!
If you are interested on video understanding/generation and reward models/critiquing, get in touch and apply below! 👇
23
82
823
74,194
Ivana Balazevic retweeted

13 Jun 2025
In Nashville for my last PhD conference 🥲.
Come join today 10:30-12:30 in Hall D (#391) to talk insights, tips and tricks to modify pretraining for representation reuse - scalably.
🚀Joint work w/ @zeynepakata, @dimadamen, @ibalazevic & @olivierhenaff while at @GoogleDeepMind.
2
7
25
3,558
Ivana Balazevic retweeted

22 May 2025
Writing a STRONGLY WORDED LETTER with Gemini Diffusion and its Instant Edit tab
1
7
28
2,533
21 May 2025
To add to the buzz of this week, a bit more of a personal update: I’m moving to San Francisco in a few days!
Grateful for the 3.5 amazing years in London and all the wonderful friends and colleagues I’ve met here. ♥️
I’ll be staying at Google DeepMind and happy to chat about Gemini Diffusion and anything else related to AI or otherwise. Excited for this new chapter and more hikes and sunny days!!
20 May 2025

🚀Meet Gemini Diffusion, our first diffusion-based and super fast language model, just announced at Google I/O!🚀
Very excited to be able to share what I've been working on for the past little while with our amazing small team @GoogleDeepMind.
3
1
77
7,081
Ivana Balazevic retweeted

21 May 2025
In 2022, I worked on text diffusion for a bit and wrote a blog post. Since then, people have regularly asked me about scaling diffusion LLMs.
All the while, I was on the first row watching Brendan assemble a cracked team and make it a reality. Now I can stop being coy about it😁
20 May 2025

Excited to share what my team has been working on lately - Gemini diffusion! We bring diffusion to language modeling, yielding more power and blazing speeds!
🚀🚀🚀
Gemini diffusion is especially strong at coding. In this example the model generates at 2000 tokens/sec, including overheads like tokenization, prefill, safety filters etc.
8
23
226
17,858
Ivana Balazevic retweeted

20 May 2025
Got access to Google diffusion.
HOLY SH!T
909 tokens/s ??????
I made a calendar in 3s? 3 fcuking seconds?

120
222
5,688
751,098

Ivana Balazevic retweeted
20 May 2025
As I was saying: it's happening
20 May 2025
We’ve developed Gemini Diffusion: our state-of-the-art text diffusion model.
Instead of predicting text directly, it learns to generate outputs by refining noise, step-by-step. This helps it excel at coding and math, where it can iterate over solutions quickly. #GoogleIO
7
45
698
50,650
Ivana Balazevic retweeted

19 May 2025
cooking up something tasty for tomorrow...
391
284
5,181
839,495
Ivana Balazevic retweeted

28 Apr 2025
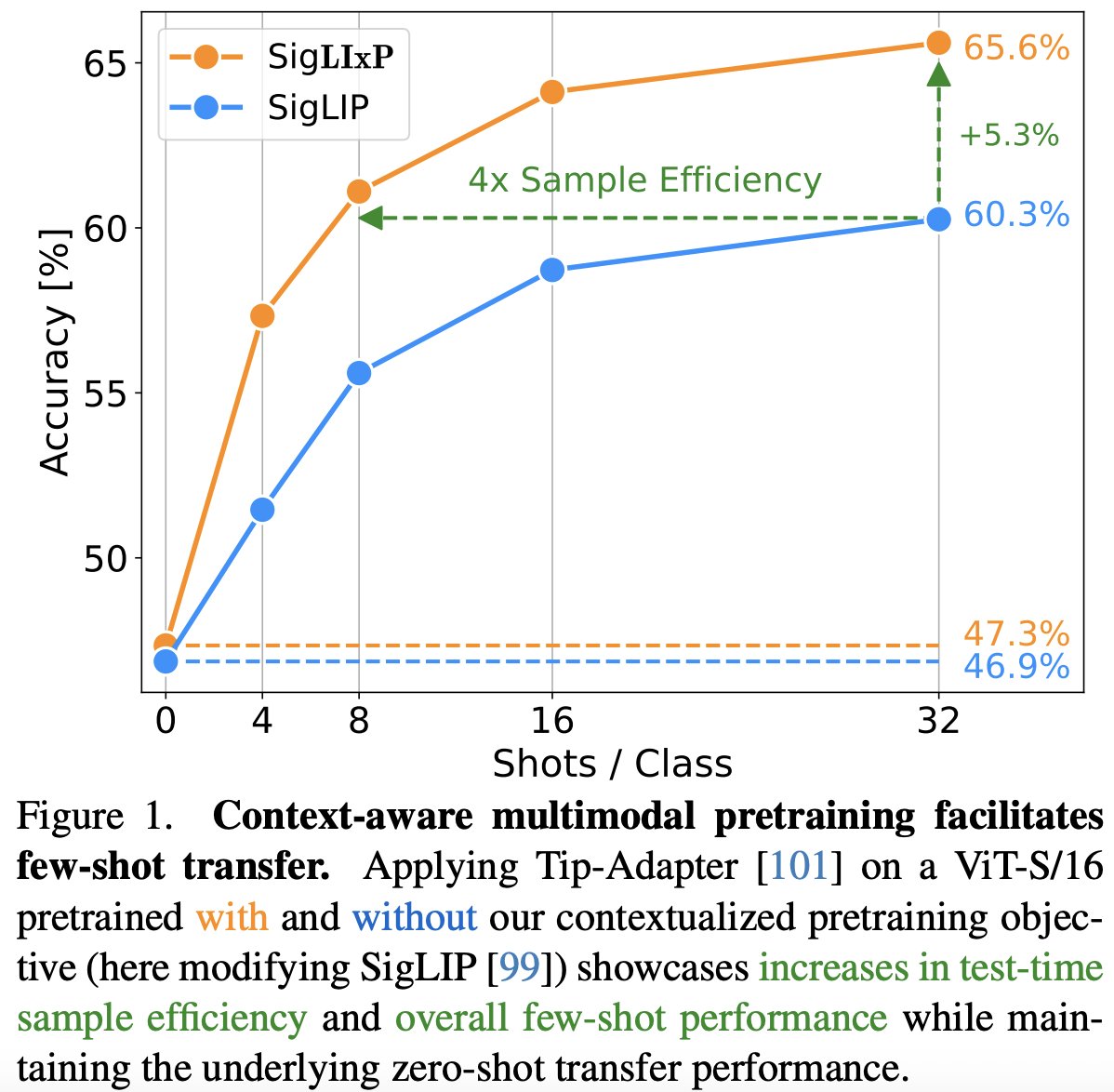
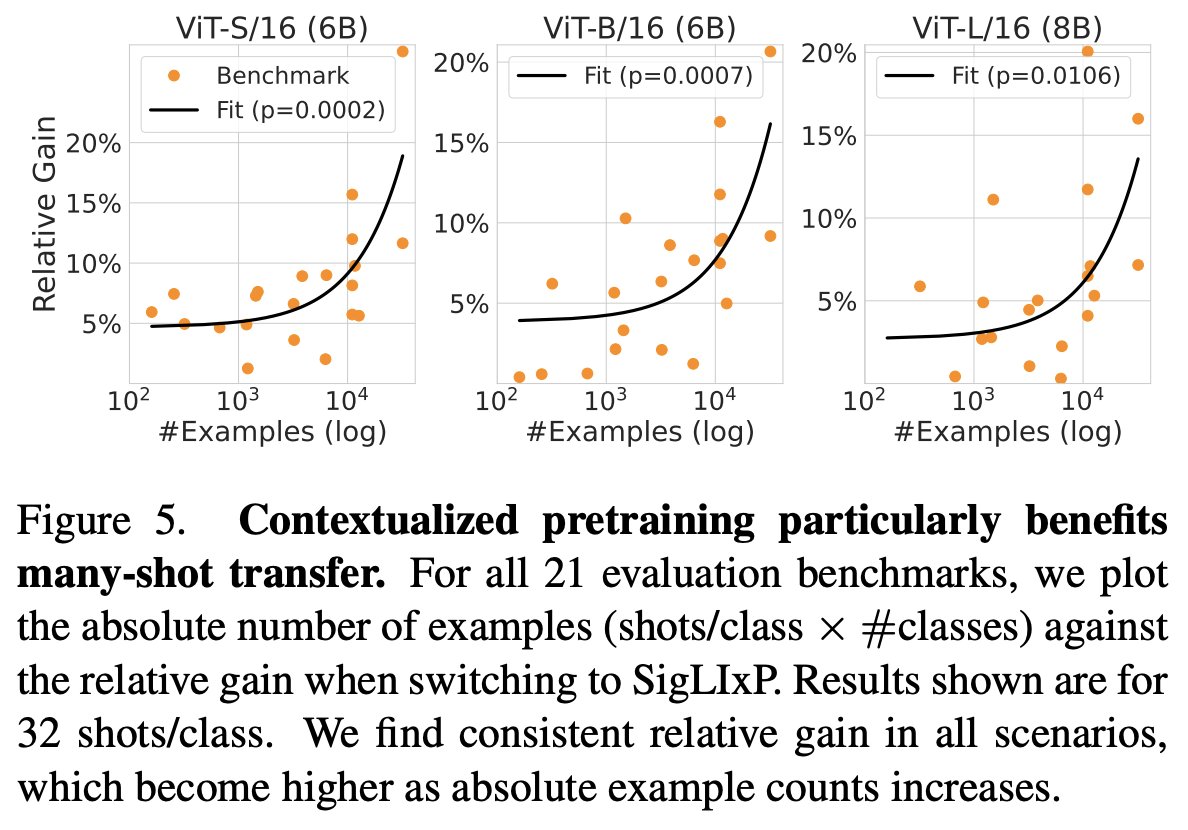
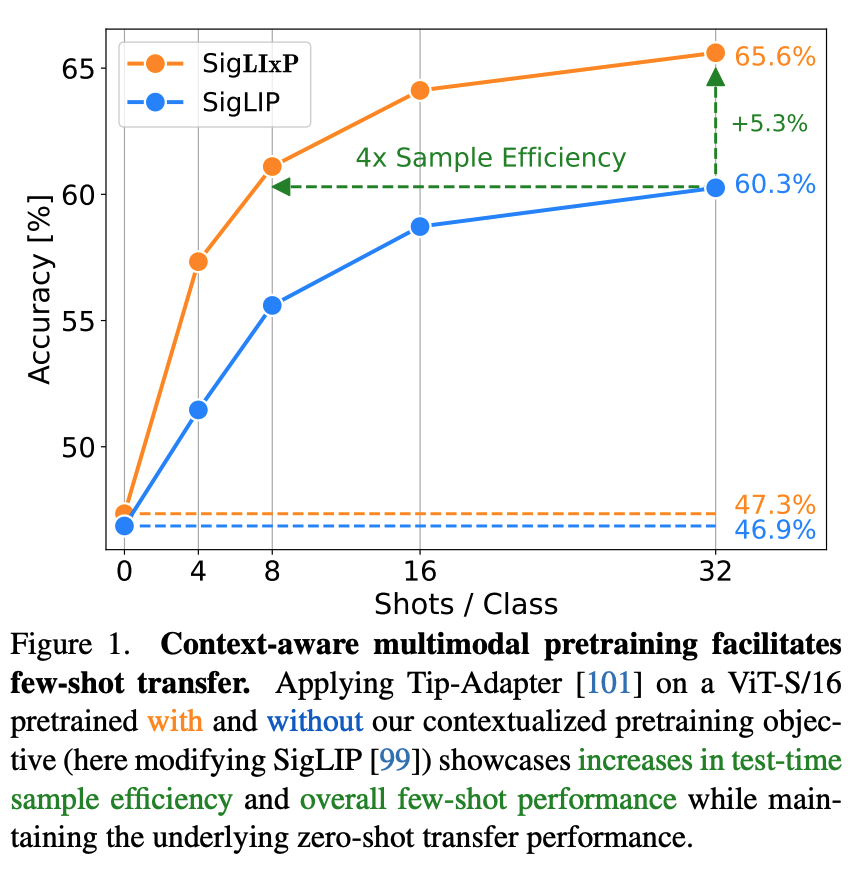
(3/4) Context-Aware Multimodal Pretraining
By the amazing @confusezius with @zeynepakata, @dimadamen, @ibalazevic, @olivierhenaff
📖 [Paper]: arxiv.org/abs/2411.15099
1
5
12
1,062
Ivana Balazevic retweeted

19 Apr 2025
One thing I notice in SF is the blurred lines between work and play time e.g. people performative coding at bars / parties signaling “hustle”. This is extremely peasant-coded and not conducive to great work imo.
History’s elites and greats kept strict borders and took leisure very seriously. It was viewed as a strict requirement to enable great work. Leonardo painted by day and staged court masquerades by night. Churchill drafted war speeches after champagne lunches and silk‑robed baths. Greek philosophers held week‑long wine‑soaked symposia that forged politics. Steve Jobs took long, device‑free walks in the hills that seeded the iPhone.
Work ferociously, build something magical, then close the lid; feast, dance, and wander. Live at the extremes. If you can’t stay off your laptop, skip the party.
87
175
3,938
221,402
Ivana Balazevic retweeted

6 Mar 2025
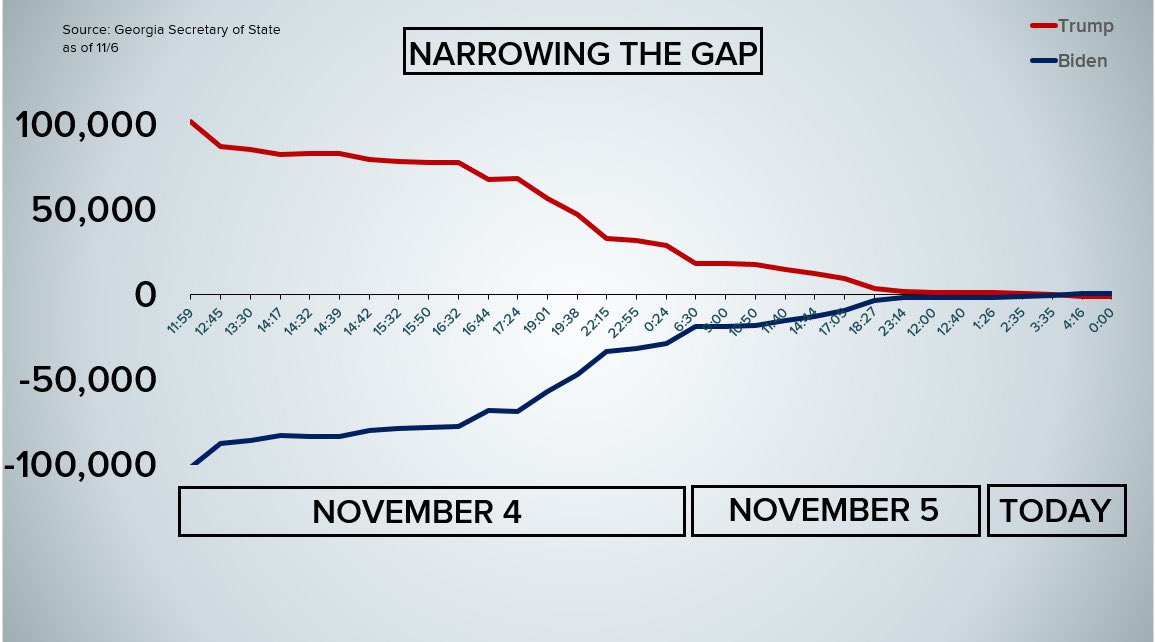
Yeah they gotta do it themselves now since trump fired like 90% of the national park service

674
47,849
538,576
12,162,263
Ivana Balazevic retweeted

14 Feb 2025
After an amazing 6 years at Google DeepMind, I'm thrilled to announce that I'll be starting a new project at the intersection of multimodal foundation modeling, data curation, and human behavior.
If this is of interest to you please reach out!
25
28
1,041
84,397
Ivana Balazevic retweeted

17 Jan 2025
Lots of vague AI hype on social media these days. There are good reasons to be optimistic about further progress, but plenty of unsolved research problems remain.
93
99
1,312
130,387