
RIT ‘22 B.S. Bioinformatics and Comp Biology. Developing next-generation drug discovery tools, co-founder/cso @try_litefold @theresidency @inventorsRes
Joined April 2014
- Tweets 1,419
- Following 560
- Followers 696
- Likes 19,302
16 Photos and videos

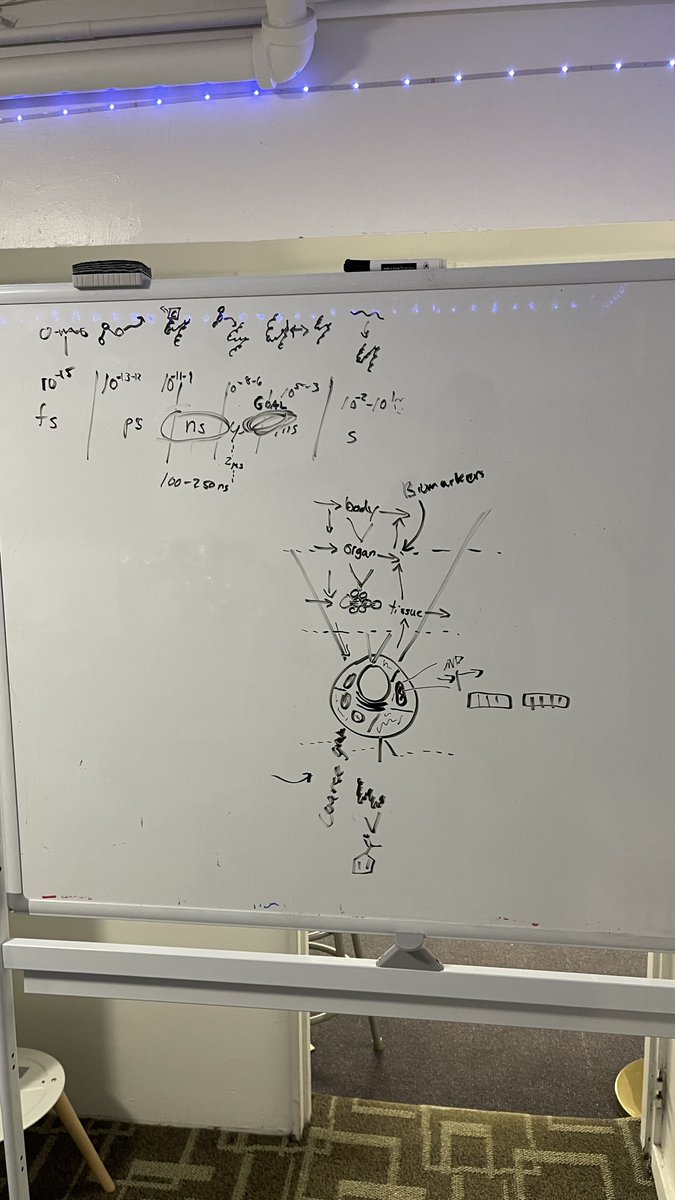

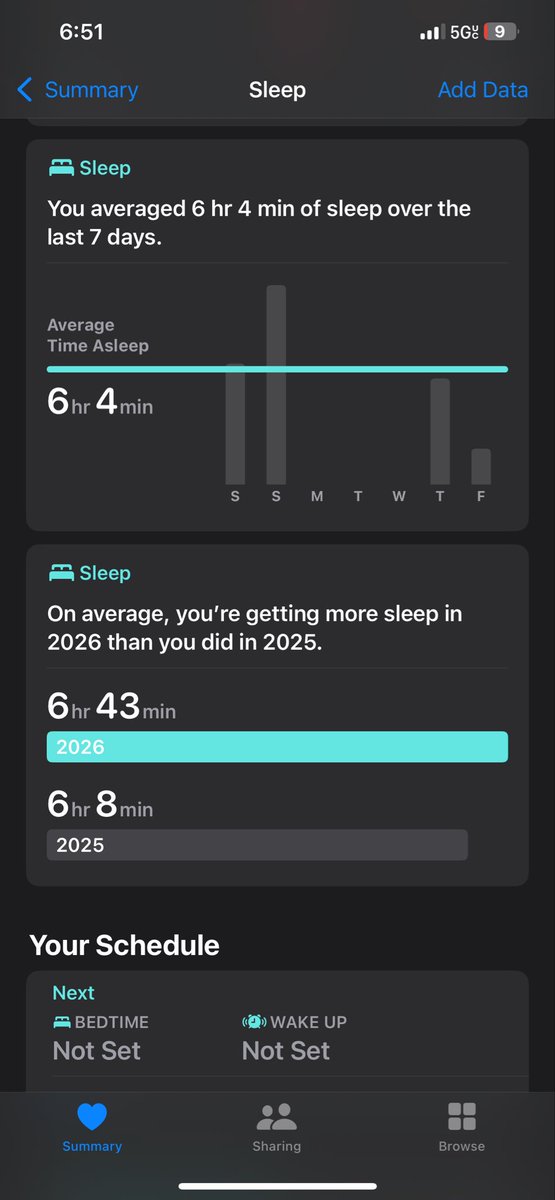
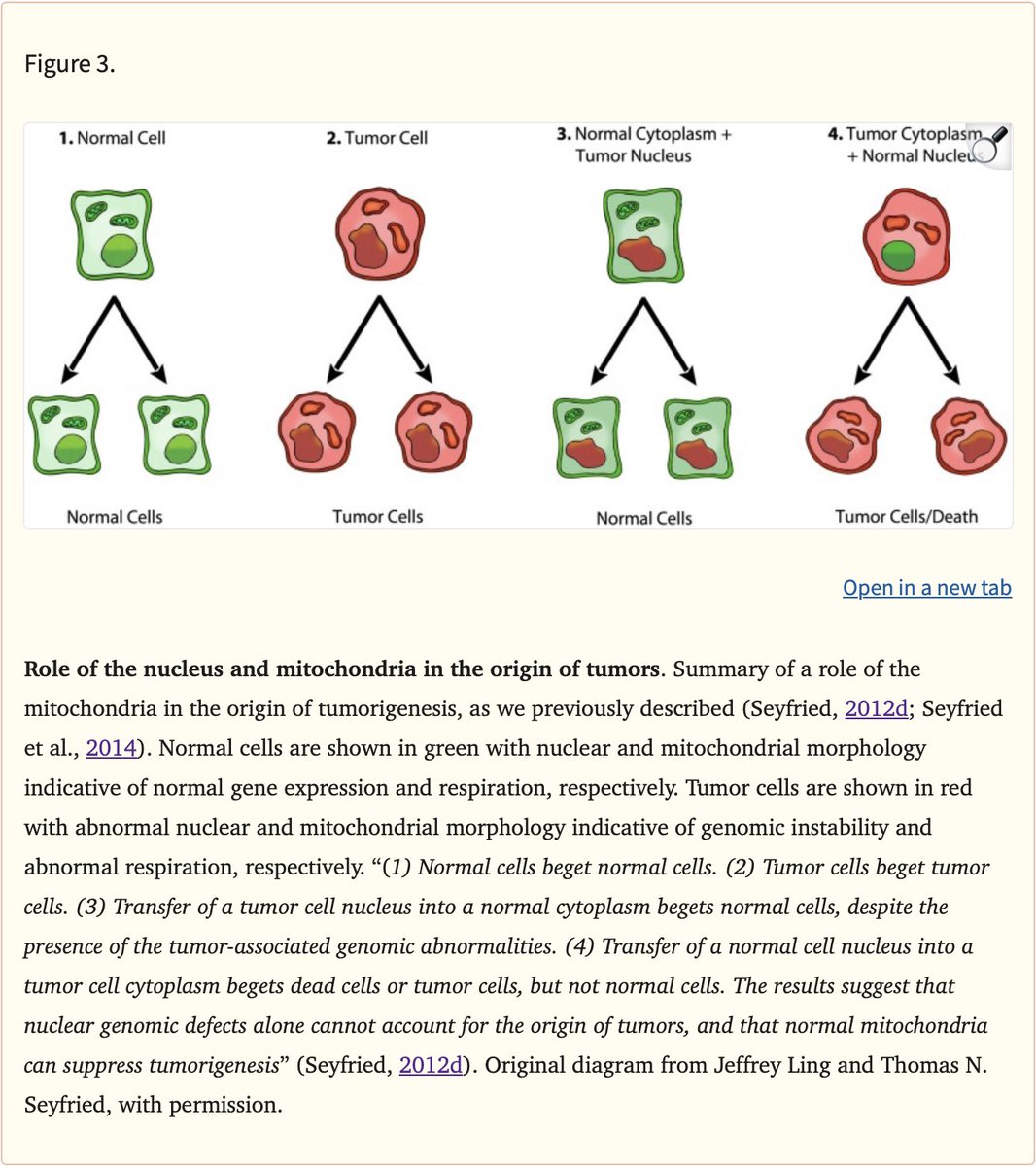

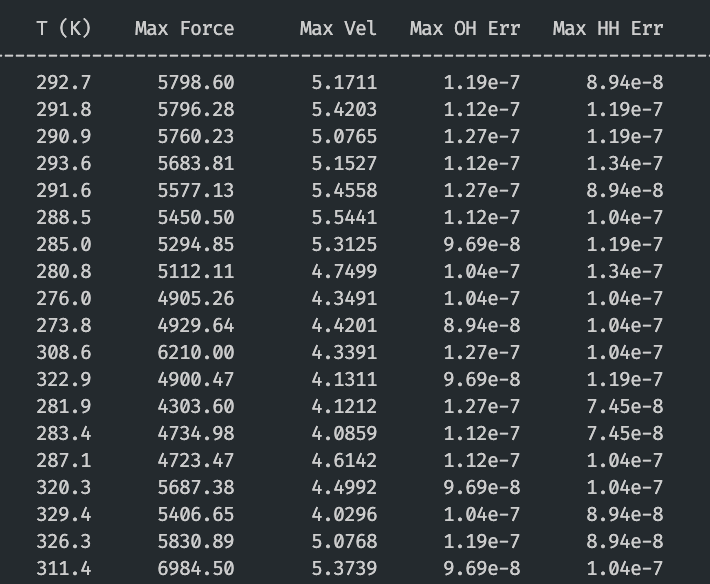




Pinned Tweet

5 Sep 2025
Just curious thinking here, but we can seriously model ligandability in-silico. You can build post translation modification models to have the protein more accurately modeled in its cellular environment, predict binding sites, use NN’s to compute forcefield parameters for molecular dynamics (soon skip the empirical parameters and use NN’s to run the MD’s themselves), you can build perturbative response models, essential site scanning analysis, drop that into anisotropic models and predict side chain fluctuations, predict if a drug is going to be agonist/antagonist, predict protein-protein interaction deviations, predict ligand tautomerizations, and design de-novo ligands to enact specific receptor conformational changes, and more that I don’t have the time to write down. The accuracy of that modeling is only getting better with time.
Admittedly, the place it stops being predictable is when you have to monitor systematic effects across the cell (soon there will a Google-like index of protein interactions that can model that on a cellular scale). So, forgive me for being naive, but why do we have to spend years of upfront protein science in-vivo just to determine if a single novel target is ligandable. Shouldn’t it be just rapidly modeling all of the aforementioned scenarios and if they pass, then move into in-vitro->in vivo->clinical? At worst you’ve spent ~2 weeks of time and 500$ on in-silico compute. At best, it’s taken 2 weeks of time and 500$ of compute to get to a place ready for wet-lab hypothesis testing.
At least that’s the mission we’re building towards @try_litefold. Ending Eroom’s Law and making all those modeling scenarios so cost effective, undergraduate students can do them at scale and so affordable you’ll be able to make in-silico hypotheses for the whole human proteome…simply because you can (even if drugging every protein isn’t needed).
5 Sep 2025

anybody in AI x bio who wants to know what industrial drug discovery is actually about should read this briefing by Treeline Bio (announced $200m additional capital yesterday, have raised $1.1bn total)
led by serious drug hunters Josh Bilenker and Jeff Engelman
link in comments
3
1
9
2,922
Cory Kornowicz retweeted
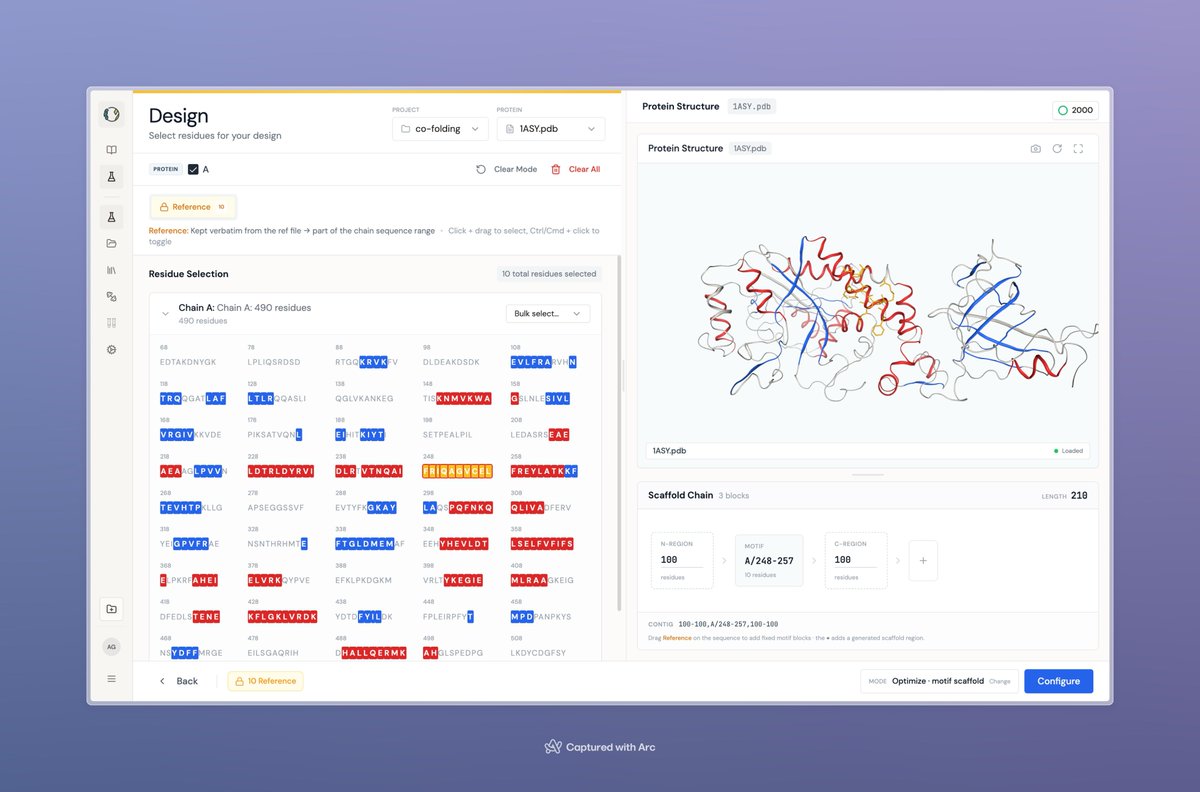
With the autonomy you want. I have been working on this now for nice time now. Will launch it very soon. The one and only one interface to design biomolecules.
Be it Sequence first, structure first, hybrid across all modalities.
Jun 14

As mentioned, ab absolutely new experience for humans and agents to design bio molecules. Coming soon!
2
2
11
514
Cory Kornowicz retweeted

Jun 15
hacked into a very big consumer app used by everyone in india in <5 mins.
got full access to all user (yes, your) data, and revenue numbers per day.
if only people built software with security in mind 😐
63
30
1,681
157,060
Cory Kornowicz retweeted

Jun 13
Meet the members of Proxima:
Anindyadeep (@anindyadeeps) is building Litefold. LiteFold combines physics-based simulation and AI to accelerate the design and validation of drug candidates in silico.
Their leading product is Rosalind: An AI Co-Scientist for Life Sciences.


4
9
56
5,999
Cory Kornowicz retweeted
Jun 14
Some of the coolest problems are being solved by the folks in Proxima, if you're solving hard problems, come join us :)
Jun 13

Meet the members of Proxima:
Anindyadeep (@anindyadeeps) is building Litefold. LiteFold combines physics-based simulation and AI to accelerate the design and validation of drug candidates in silico.
Their leading product is Rosalind: An AI Co-Scientist for Life Sciences.
3
18
1,611
Jun 14
Couldn’t think of a better person than @anindyadeeps who fits this 💪🏼
Jun 14

If your deep tech CEO isn't
1) a grand visionary
2) a hardcore grinder operator
3) a technical genius
4) an amazing salesman
Then you're NGMI
1
35
Cory Kornowicz retweeted

Jun 14
Small molecule
peptide
antibody
enzymes
binders
you name it!! Coming Soon
Jun 14
As mentioned, ab absolutely new experience for humans and agents to design bio molecules. Coming soon!
1
3
8
546
Cory Kornowicz retweeted

Jun 1
> Three 30 ns MD runs of human β2AR, in parallel, from a browser
> Apo in water, carazolol-bound, and embedded in a POPC bilayer
> Finished in an afternoon on cloud GPUs.
> No CHARMM-GUI session, No terminal, no topology debugging, no queue.
> Life is good!
Focus on the Science, we take care of the rest. Links in the comments.
Jun 1

We ran β2AR three ways: bare, with carazolol bound, and in a lipid bilayer. Carazolol sits in the extracellular pocket, but the RMSF drop shows up at the cytoplasmic end of TM6.Inverse agonism as distal dampening, visible in 30 ns of MD. Read more in the blogpost. Links in comments.

3
6
27
5,276
Cory Kornowicz retweeted
May 27
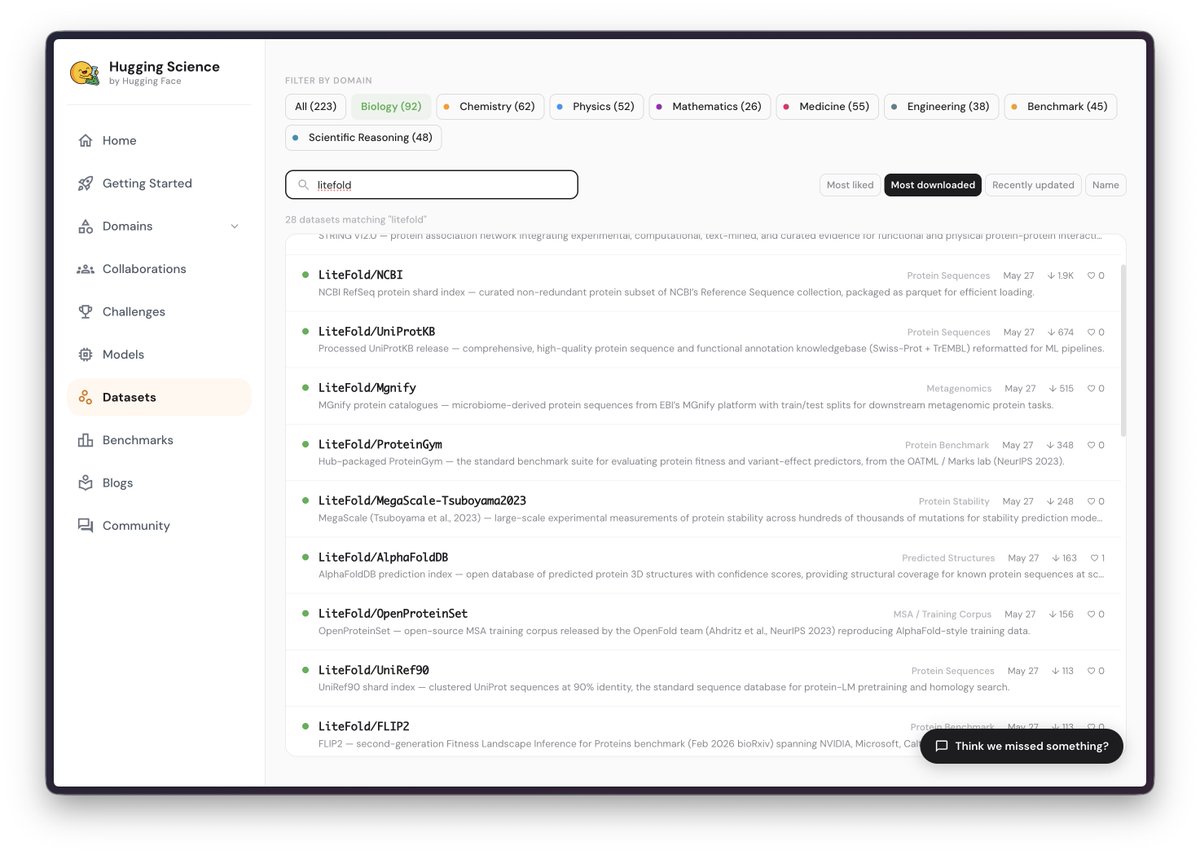
We are also now integrated inside Hugging Science guys less gooo!!! huggingscience.co/#/datasets
May 27
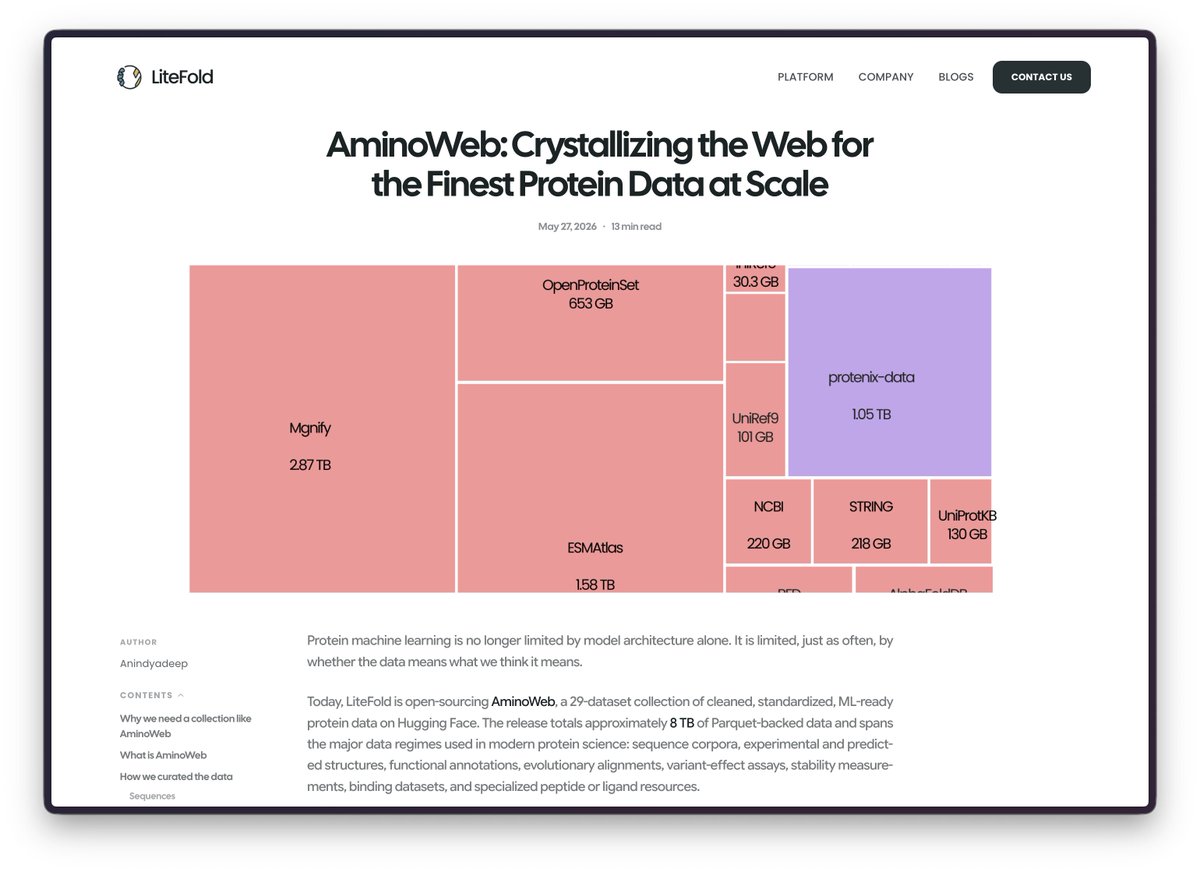
We have released the biggest protein data collection on Hugging Face, guys!
We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
4
36
2,433
Cory Kornowicz retweeted
May 27
We have released the biggest protein data collection on Hugging Face, guys!
We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
May 27
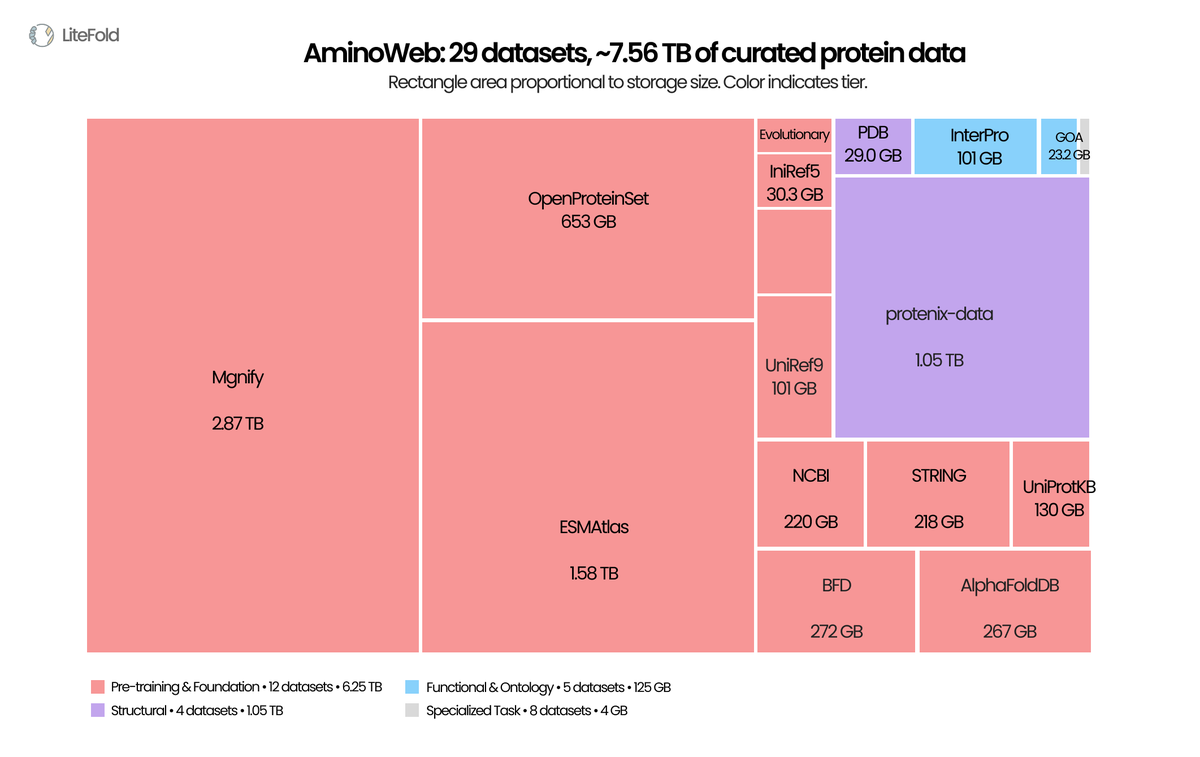
LLMs got FineWeb, The Pile, RedPajama, Dolma. Protein ML got per-paper supplementary tables and FTP mirrors scattered across a dozen institutions.
Today we're releasing AminoWeb on @huggingface : 29 cleaned, ML-ready protein datasets, ~7.5 TB total. Sequence, structure, function, MSA, variant-effect, stability, binding. UniProt, PDB, AlphaFoldDB, ESMAtlas, ProteinGym, MegaScale, Protenix, and more.
Typed Parquet. Homology-aware splits. Preserved score conventions. Full provenance per record.
Protein ML scaled architectures for years while the data layer stayed fragmented. We've also shared the full curation pipeline, case studies, and observations in the companion blog post.
Access the data: huggingface.co/LiteFold
Read the release blogpost: litefold.ai/blog/aminoweb
38
71
360
88,435
Cory Kornowicz retweeted
May 23
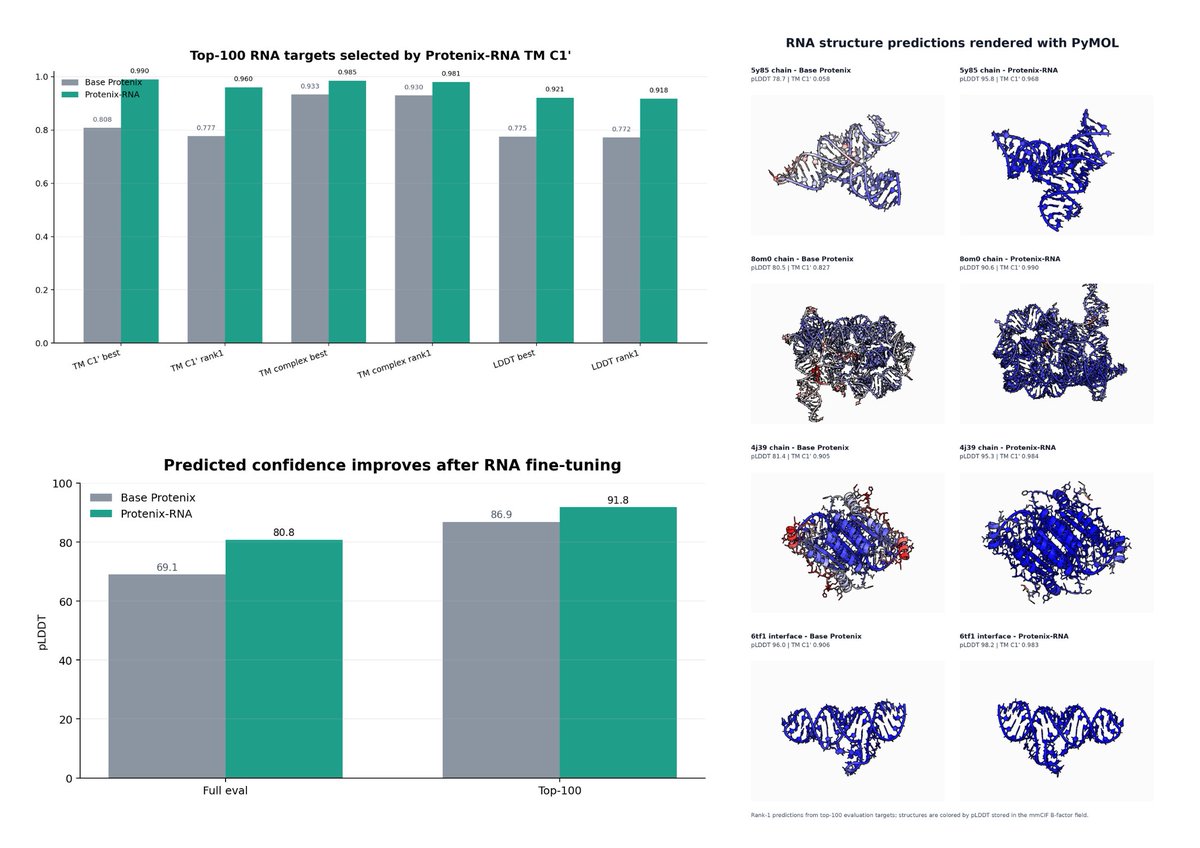
We fine-tuned Protenix on RNA data using @try_litefold Tune (our multi modal fine-tuning engine) and got 20% jump in pLDDT and 10% jump in the avg TM Score. Currently sota so far on rna structure prediction.
More announcements on this. Stay tuned.
May 22
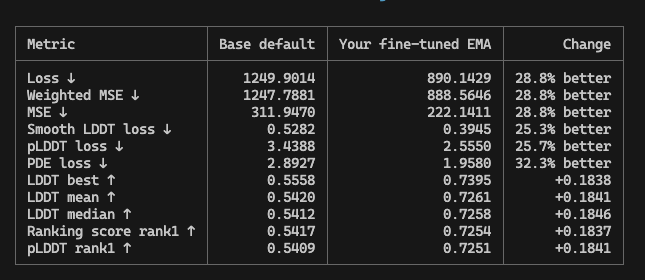
So our fine-tuning engine is giving us ~ 20% increase (full evaluation) in RNA folding task. Now starting second round of continual tuning.
5
21
81
18,047
May 21
I really need to advertise @try_litefold more, and that's my fault for having way too much fun.
But Rosalind is the best AI co-scientist that exists. Absolutely #1 on BixBench-Verified, but more importantly than benchmark chasing or the 0 to 1 molecule biology stuff:
She can construct nearly every FDA document, Form 3938, Form 351(K), IND's, eCTD’s - we're already working through trials with pharma partners spanning not just molecular biology and therapeutic development, but also process dev (upstream & downstream), eLab notebooks, and she can pull in any package in R/Python or even directly from Github. She has no limit on her sandbox storage, and there's no limit on what kinds of models she can run or fine-tune.
@try_litefold is the execution engine powering the largest de-sci peptide development across the globe. Which is why we added tons of support for membranes and non-canonical amino acids because that's where the real structural biology dabbles.
Now we're setting our eyes on training new SOTA models, custom metadynamics pipelines for our design partners, new virtual screening / FEP workflows, re-visioning molecular toolkit from the ground up in the AI era, and causal virtual cells.
Some fun things I have Rosalind work on in my free time: peptide molecular jackhammers for superior cancer selectivity and efficacy, VO2 max increasing peptides, solid state enzymes for flow-cell organic chemistry, anti-virals against Ebola/Covid/Hantavirus, cure for Alpha-Gal syndrome, and I got a tip recently for some OR8 receptors in mosquitoes that actives their immune system to fight malaria/dengue. And yes, from time to time, I make entire catalogs of de-novo molecules against every target that I see a pharma company publish in their pipelines.
It is damn near magic.
1
8
33
4,319
Cory Kornowicz retweeted

May 20
Everyone's trying to fix sleep.
But insomnia isn't the problem. It's the bill.
Burnout, anxiety, panic - they all start the same way: you stop hearing yourself.
Today we're launching Aora. The first device that hears it for you.
@AoraBCI
25
13
102
11,394
Cory Kornowicz retweeted
May 21
Btw, @try_litefold has a hf page. Time to give the OpenScience community some gifts from our side. Coming soon!
1
6
39
2,774
May 21
we’re not ready for AI as a species because we still onboard planes front to back
2
2
75
May 19
This is great, but we also need immense data for structural biology as well. Try using AlphaFold for real life structural biology modeling. You simply can’t.
May 18

AI in bio needs more data to train new models. But what data?
At Vitalist Bay, our founder @MartinBJensen argued for moving beyond the existing kinds of bio datasets and mobilizing researchers to plan definite data strategies for their fields (@impetusgrants's next focus.)


1
2
8
1,037
Cory Kornowicz retweeted
May 17
This is amazing to see how far the research has come for @try_litefold in collaboration with @peptai_ ! LiteFold is building a new end to end computational stack for non canonical amino acid from scratch and this is just the start. Onwards and Upwards 🚀
2
10
40
2,742
Cory Kornowicz retweeted

Apr 30
How it feels to do biotech in 2026
99
692
11,566
446,961

Do more capable AI models produce better drug candidates?
Most teams in AI drug discovery assume they do & most effort goes into better architectures, more training data, and higher benchmark scores.
But in practice, the same pipeline can produce completely different outcomes depending on the biological target.
When one of the strongest peptide design pipelines available was benchmarked across multiple targets, hit rates ranged from 0% to 67% using the same underlying system.
The key finding was that the computational score used to rank designs was not a reliable predictor of experimental binding affinity. Separate analysis across more than 1,400 peptide inputs confirmed the same result, structure prediction confidence metrics showed negligible correlation with experimental outcomes.
The implication is important, a pipeline’s usefulness depends less on raw model capability and more on whether it was ever validated against biology where the answer is already known.
Confidence scores can be a decent binary signal (binds vs. does not bind), but they are often poor predictors of actual affinity.
Yet many autonomous discovery pipelines evaluate novel candidates without first confirming they can reliably separate known binders from known non-binders on that target class.
At @peptai_, every novel candidate first passes through a calibration stage.
Known binders and known non-binders from public datasets are run through the full computational pipeline, and the resulting score distributions become the baseline for interpreting new designs.
If a platform cannot recover signal on biology we already understand, there is no basis for trusting what it says about novel sequences.
24
11
71
12,722
May 13
we need to stop building black box virtual cells and start building causal virtual cells to have any real guarantees, oops maybe that gives away the virtual cell we are building
1
2
159
Cory Kornowicz retweeted
May 13
LiteFold just got featured in @YourStoryCo
It’s been 8 months since Cory and I officially started @try_litefold.
We began by building better interfaces and workflows for computational biology, followed by Rosalind, our AI Co-Scientist for therapeutic design.
Now we’re gradually moving toward developing our own in-house scientific and AI research focused on next-generation therapeutic models and research environments and partnerships.
Still very early. Really cant wait to share whats coming.
Story link in the comments

10
24
99
7,533