
Composable AI agents for security teams
Joined May 2025
- Tweets 41
- Following 14
- Followers 416
- Likes 160
12 Photos and videos






We've raised a $7.4M seed round led by @a16z to build the agent operating system for security teams.
Threat actors now scale with tokens. Campaigns that used to require a coordinated team can be run by a small group with the right model harness. Defense has been absorbing that hit with the same playbook and the same headcount. We built Cotool to make defense compound in the same way.
Grateful to the team at @a16z , @YCombinator, @WndrCoLLC , @homebrew , and our angels from Okta, Ramp, Cloudflare, and others who've lived this problem firsthand.
If you’re a security practitioner looking for more leverage in the AI age, come see how Cotool can help!
11
21
2,468
Cotool retweeted

Jun 11
The "AI SOC Analyst" is a band-aid on a broken leg.
A ton of security startups are dropping autonomous agents into legacy SOC queues to speed up triage. It’s a waste of budget. You are just optimizing a workflow that shouldn't exist in an AI-native world.
Think about factory electrification in the 1920s. Early factories just swapped massive steam engines for large electric motors and saw zero productivity gains. It was only when they threw out the blueprints, put tiny motors at individual workstations, and changed the floor layout that productivity skyrocketed.
Cybersecurity is stuck in the steam era. Legacy SIEMs force you to pay an insane markup on basic data storage while your team wastes finite engineering cycles tuning noisy alerts.
The future isn't a faster SOC. It's a decentralized security data lake.
New platforms like @RunReveal and @scanner_dev are cutting out the middleman by running directly on top of cheap infrastructure like S3 and ClickHouse. Meanwhile, tools like @cotoolai are perfecting the AI blue-team application layer.
The real win here isn't autonomous code remediation; it's fixing the tuning loop. Most alerts are false positives. When an alert hits, tools like RunReveal can run an immediate background investigation, auto-close the noise, and hand the human generalist the exact context needed to tune the rule in seconds.
You don't need a dedicated SOC or an army of analysts anymore. You need elite data infrastructure and software that lets a single generalist focus on outcomes, not implementation details.
open.substack.com/pub/frankl…
3
8
431
Frontier labs are steadily exhausting open datasets and RL environments. Public benchmarks have a shelf life, and it's shortening fast.
With the Cotool Research project, we're building private evals to stay ahead. The goal is simple: provide defenders an accurate picture of how frontier agents actually perform on defensive security tasks.
@ThruntingLabs helped us build exactly that: a benchmark grounded in real intrusion data from a live environment. CTFs are still useful, but as security teams hand more responsibility to agents, we need realistic data to compare models and agent harnesses.
link in thread for results!

We are proud to partner and bring light to the incredible work that the good folks at @cotoolai are doing!
A lot of AI security evaluations for frontier models miss the mark. They compare apples to oranges by using synthetic evaluation data to assess real-world workflows. Cotool understands this and takes a different approach.
This evaluation was built around real intrusion data informed by our macOS intrusion reporting, and their write-up is excellent. The results are genuinely interesting, especially in showing both the progress AI has made and the room still left for harder, more realistic evaluation.
We’re glad to be part of it and look forward to supporting future reporting and evaluations with Cotool.
Blog post: cotool.ai/blog/beyond-ctfs-e…
Research: cotool.ai/research/macos-thr…

1
3
10
1,407
Interactive Results: cotool.ai/research/macos-thr…
Blog Post: cotool.ai/research/macos-thr…
4
90
New from Cotool: NYU CTF Bench.
We evaluated 81 real CSAW CTF challenges to measure end-to-end cyber capability across models.
Takeaway: reasoning depth still matters a lot in real security workflows.
Full results here: cotool.ai/research/nyu-ctf
1
6
276
Hosting an event for RSA on Monday, if you're a practitioner looking for a non-salesy place to hang, swing by! Co-hosting with @material_sec and @trufflesec
luma.com/home
1
5
441
Job's just getting started!
Mar 5

Excited to announce that @cotoolai has raised a $7.4M seed round led by @a16z to build the agent operating system for security teams.
Threat actors now scale with tokens. Campaigns that used to require a coordinated team can be run by a small group with the right model harness. Defense has been absorbing that hit with the same playbook and the same headcount. We built Cotool to make defense compound in the same way.
Grateful to the team at @a16z, @ycombinator, @WndrCoLLC, @homebrew, and our angels from Okta, Ramp, Cloudflare, and others who've lived this problem firsthand.
If you’re a security practitioner looking for more leverage in the AI age, come see how Cotool can help!
1
1
13
1,601
📊Today we're sharing initial results from one of our internal agent evals for Security Operations tasks.
We replicated the @splunk BOTSv3 CTF environment in an eval to test frontier models' capability on realistic blue team cybersecurity tasks.
BOTSv3 comprises over 2.7M logs (spanning over 13 months) and 59 Question and Answer pairs that test scenarios such as investigating cloud-based attacks (AWS, Azure) and simulated APT intrusions.
See results and blog post in the thread below
1
4
20
4,409
Blog Post: cotool.ai/blog/evaluating-ai…
Evals in security operations are an evergreen challenge. As agents take over more security operations tasks, benchmarking performance becomes increasingly critical. Our goal is to push the community forward with better metrics so that security teams can properly understand agent capabilities before handing over mission-critical tasks.
We have already identified a lot of future work that can build on what we're sharing today, including sharing more tasks and including comparisons on OSS model performance.
If you are:
- Participating in or building blue-team CTF challenges or security training scenarios
- Working with production security datasets that could be anonymized for benchmarking
- Researching agent evaluation methodologies or prompt optimization techniques
- Running a security operations team interested in testing agents in controlled environments
- Building security-specific agents at your company and have insights on model effectiveness for different tasks
We'd love to hear from you! DM us directly here on X @cotoolai
1
8
522
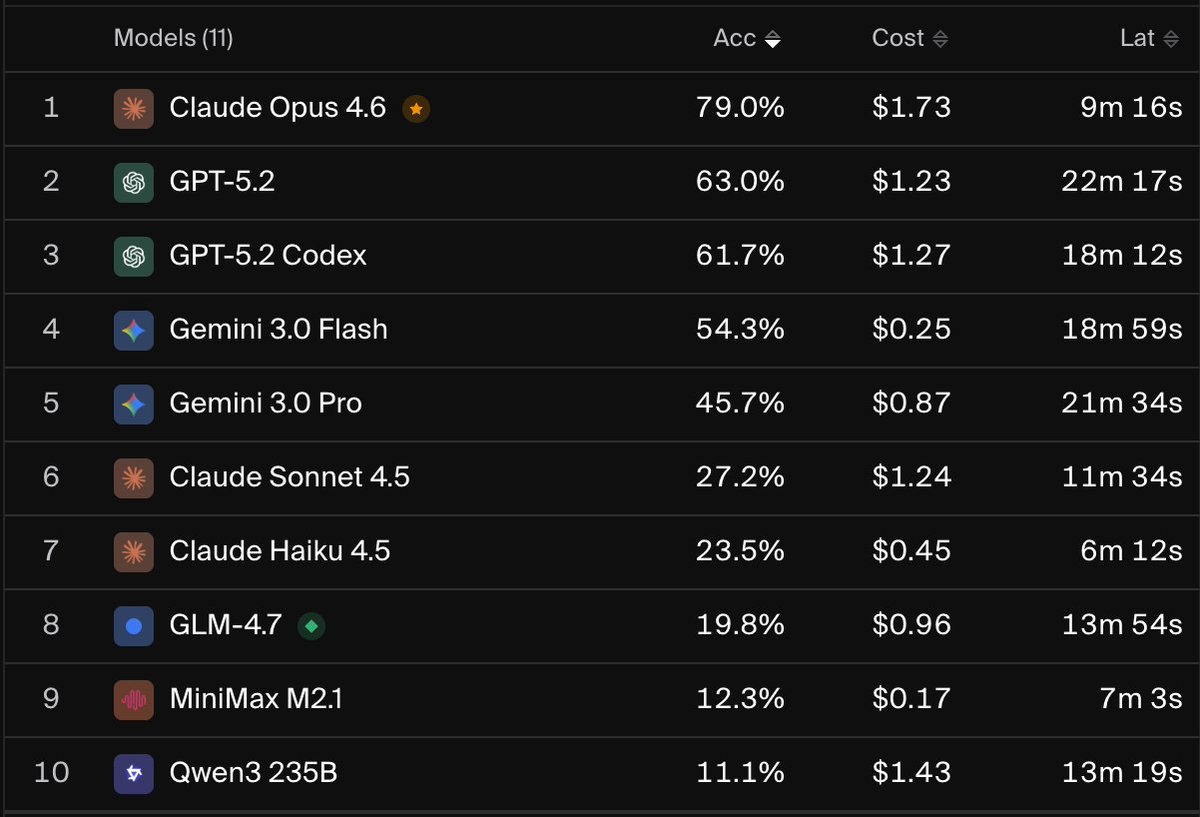
We added a new cohort of frontier models to our eval!
Gemini 3 Pro, Claude Opus 4.5, and GPT-5.1 are all compared in our updated post: x.com/cotoolai/status/199591…

1/6 📊 UPDATED EVAL RESULTS
We compared Gemini 3 Pro, Claude Opus 4.5, and GPT 5.1 on a single investigation task of our internal agent eval for Security Operations tasks.
Key Results:
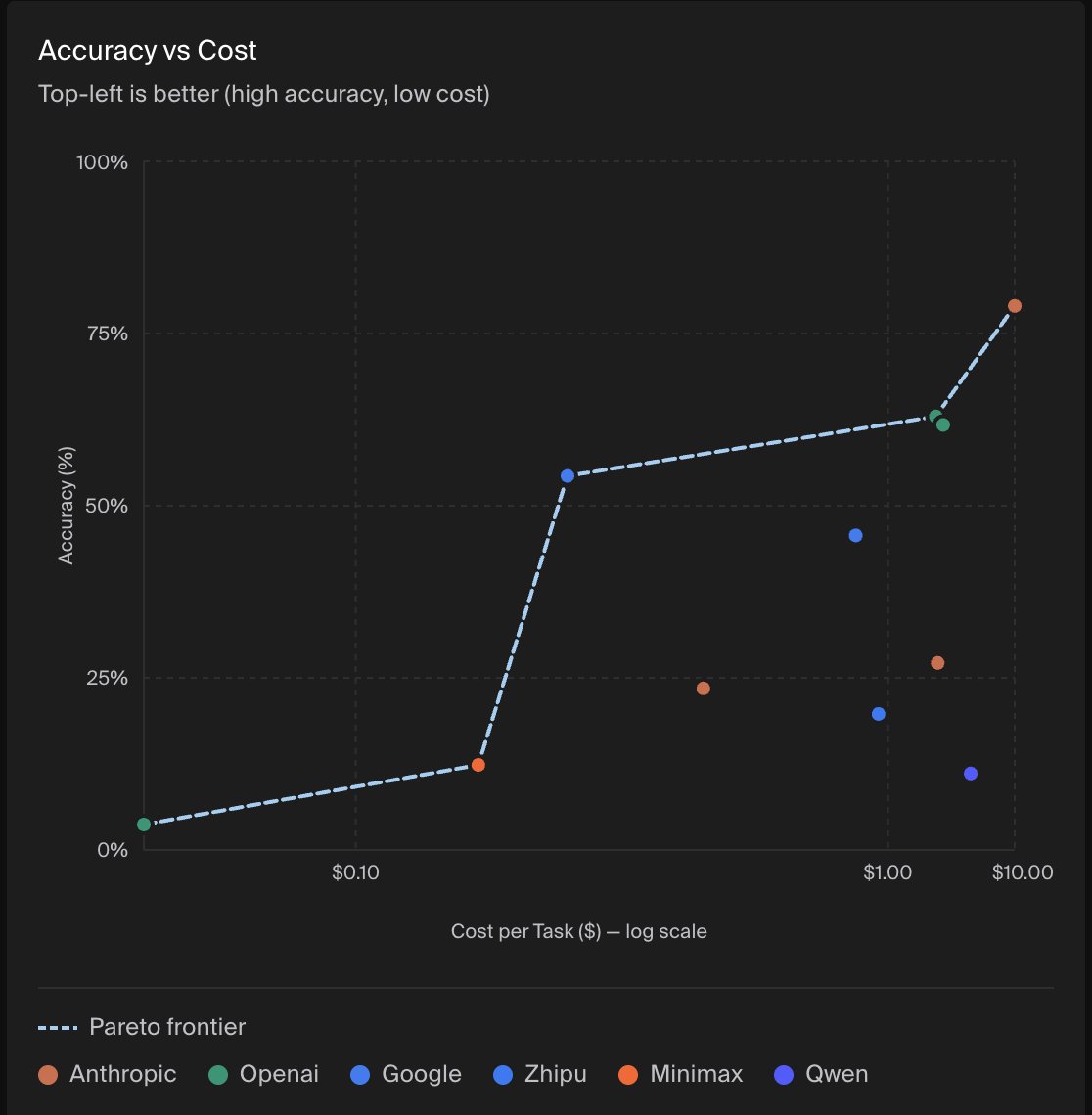
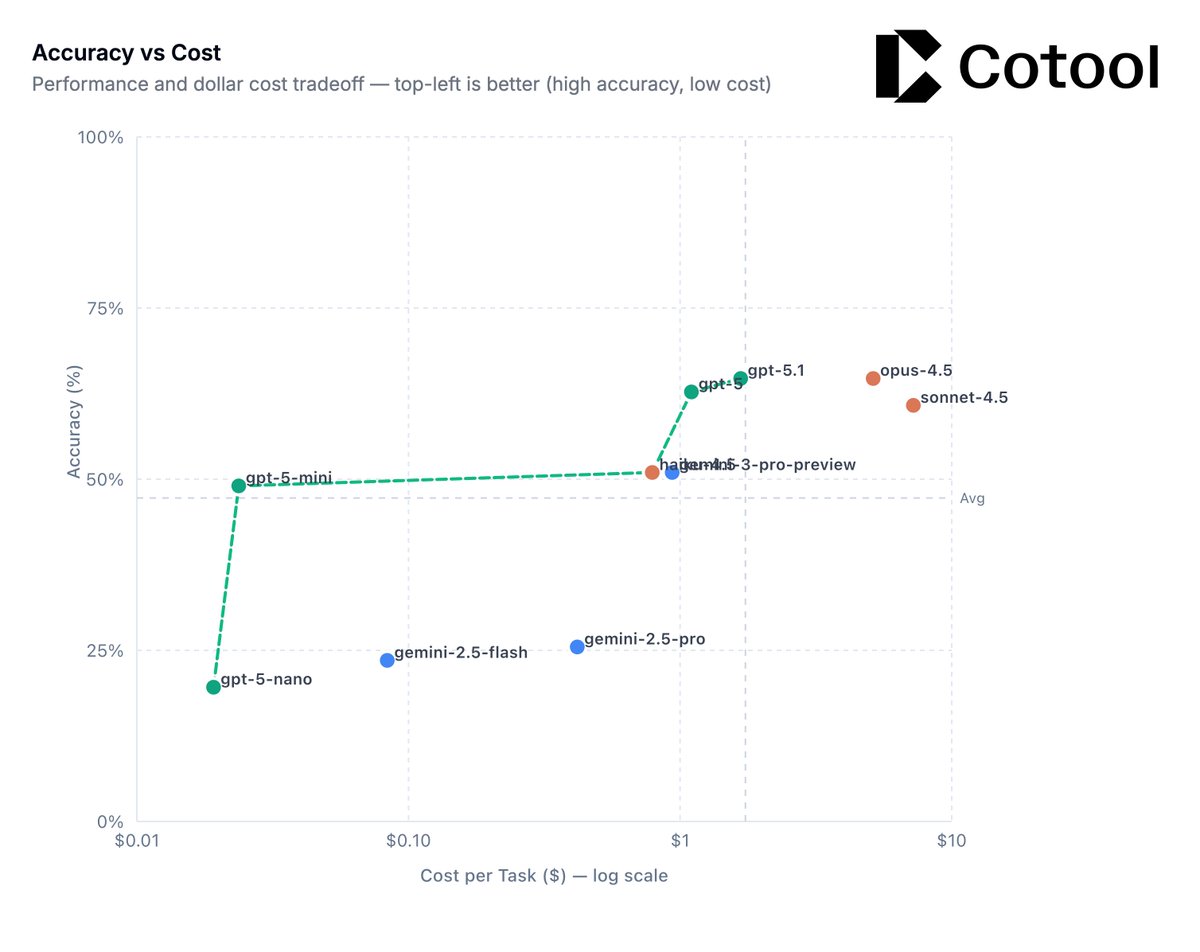
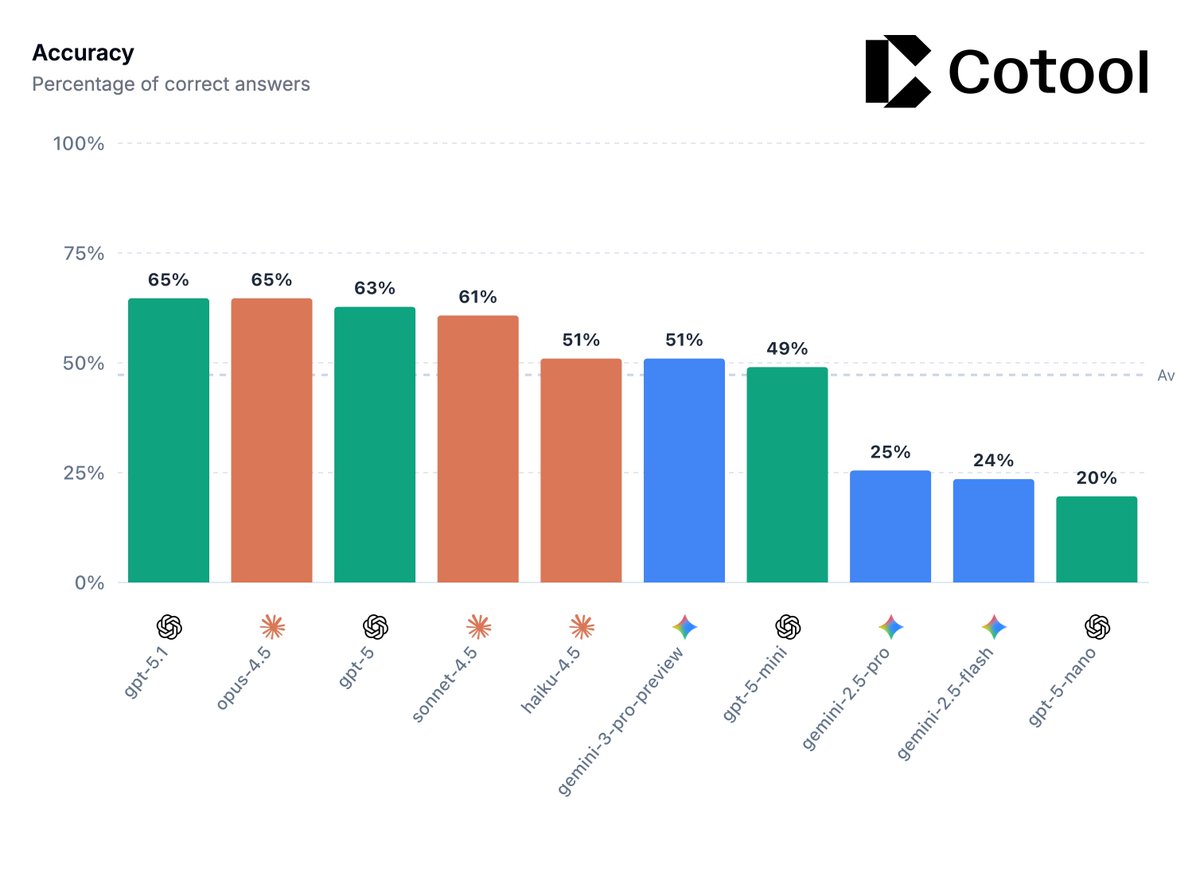
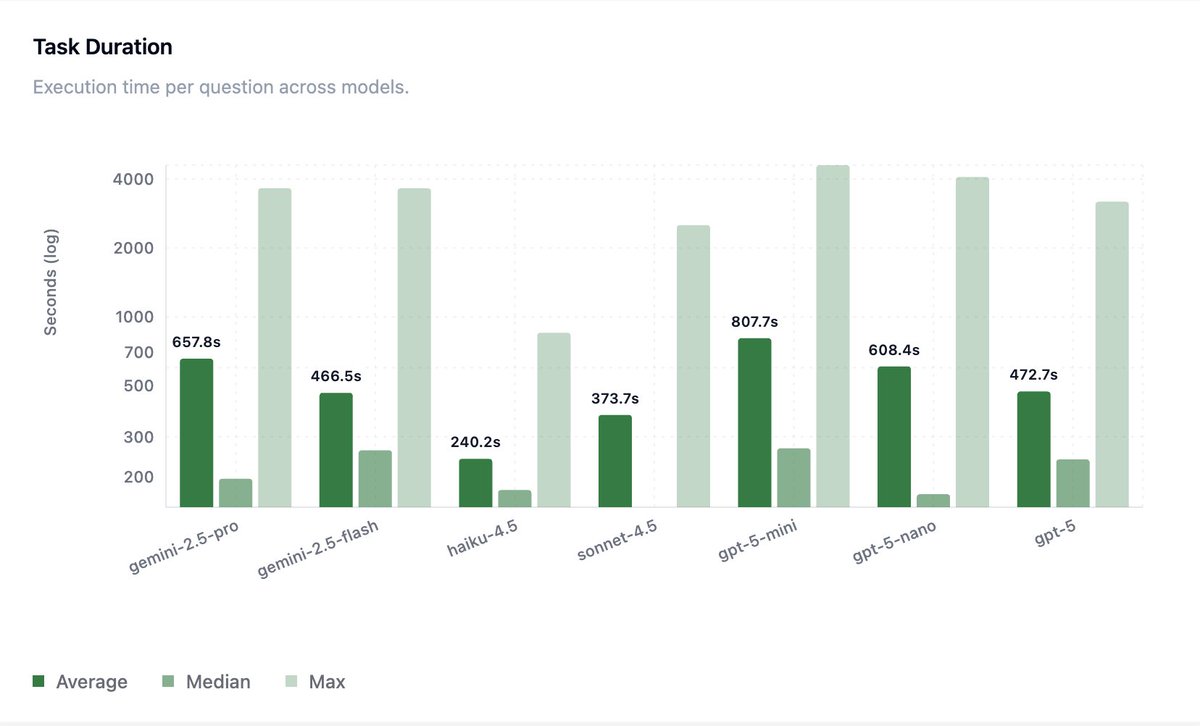
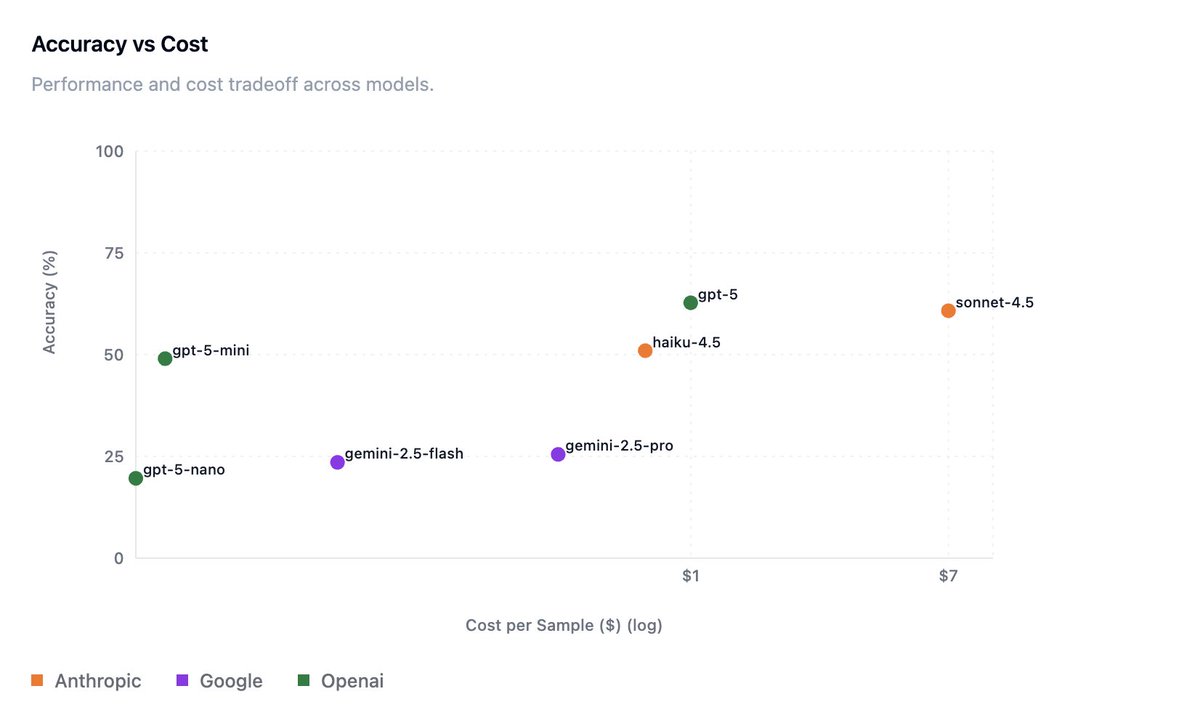
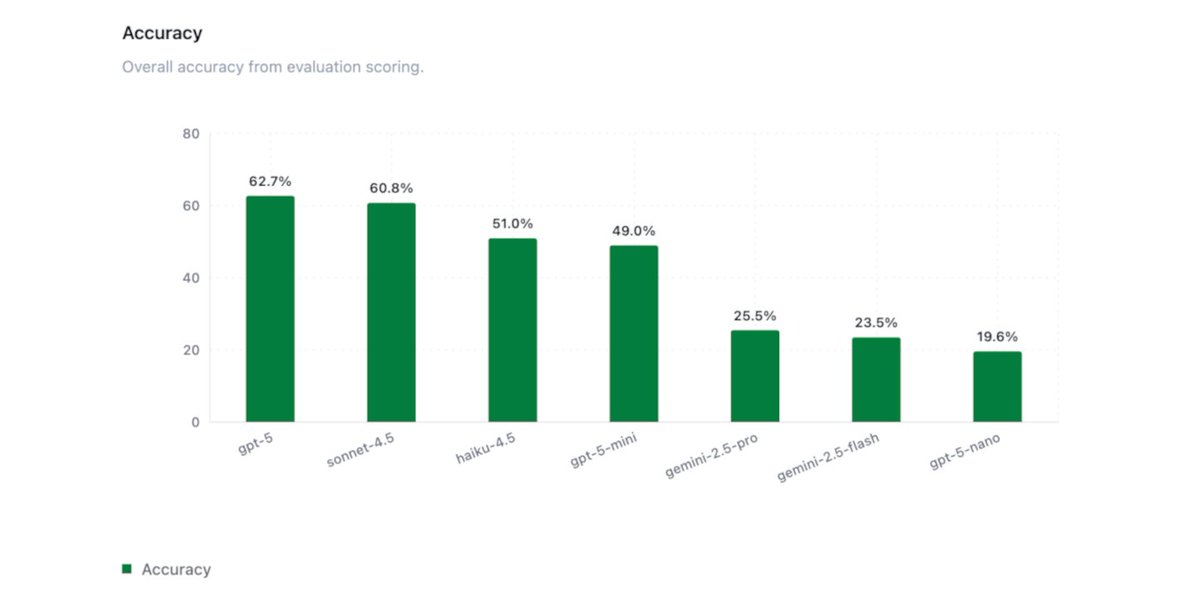
- @OpenAI GPT-5 models maintain the performance-cost Pareto frontier
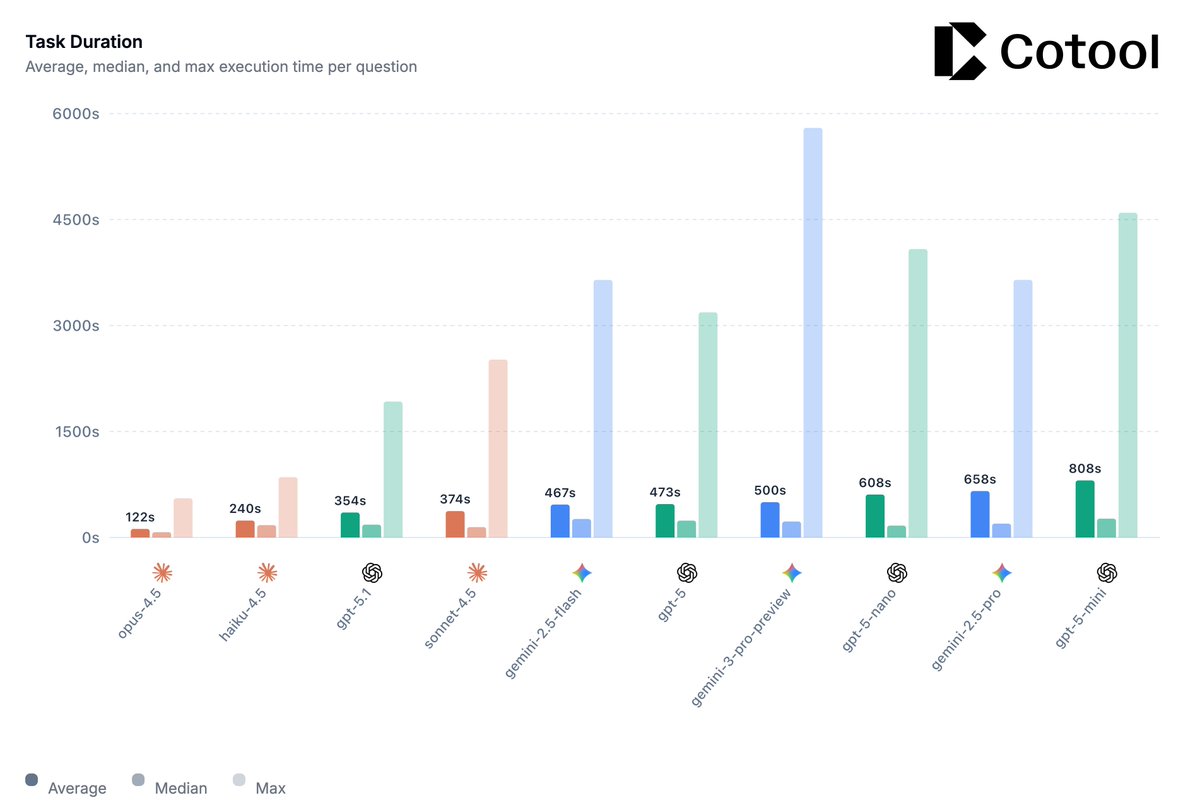
- @AnthropicAI Opus 4.5 completed tasks 2x faster on average than any other tested model, including Haiku 4.5 (!), suggesting that model reasoning capability and efficiency can outweigh raw inference latency in long-horizon tasks
- @GoogleDeepMind Gemini 3 Pro helps Google close the gap to other leading frontier models, but still lags behind in performance and reliability
The task is a @splunk BOTSv3 CTF environment built to test frontier models' capability on realistic blue team cybersecurity tasks.
BOTSv3 comprises over 2.7M logs (spanning over 13 months) and 59 Question and Answer pairs that test scenarios such as investigating cloud-based attacks (AWS, Azure) and simulated APT intrusions.
See results and blog post in the thread below
446
1/6 📊 UPDATED EVAL RESULTS
We compared Gemini 3 Pro, Claude Opus 4.5, and GPT 5.1 on a single investigation task of our internal agent eval for Security Operations tasks.
Key Results:
- @OpenAI GPT-5 models maintain the performance-cost Pareto frontier
- @AnthropicAI Opus 4.5 completed tasks 2x faster on average than any other tested model, including Haiku 4.5 (!), suggesting that model reasoning capability and efficiency can outweigh raw inference latency in long-horizon tasks
- @GoogleDeepMind Gemini 3 Pro helps Google close the gap to other leading frontier models, but still lags behind in performance and reliability
The task is a @splunk BOTSv3 CTF environment built to test frontier models' capability on realistic blue team cybersecurity tasks.
BOTSv3 comprises over 2.7M logs (spanning over 13 months) and 59 Question and Answer pairs that test scenarios such as investigating cloud-based attacks (AWS, Azure) and simulated APT intrusions.
See results and blog post in the thread below
2
1
5
1,279
5/6 Full Blog Post: cotool.ai/blog/evaluating-gp…
Evals in security operations are an evergreen challenge. As agents take over more security operations tasks, benchmarking performance becomes increasingly critical. Our goal is to push the community forward with better metrics so that security teams can properly understand agent capabilities before handing over mission-critical tasks.
We have already identified a lot of future work that can build on what we're sharing today, including sharing more tasks and including comparisons on OSS model performance.
If you are:
- Participating in or building blue-team CTF challenges or security training scenarios
- Working with production security datasets that could be anonymized for benchmarking
- Researching agent evaluation methodologies or prompt optimization techniques
- Running a security operations team interested in testing agents in controlled environments
- Building security-specific agents at your company and have insights on model effectiveness for different tasks
We'd love to hear from you! DM us directly here on X
@cotoolai
1
1
211
6/6 Finally, this work is a follow up to a previous blog post we put out. For more info around motivation, methodology, and much more around the eval itself, check out our initial post here:
x.com/cotoolai/status/199079…
📊Today we're sharing initial results from one of our internal agent evals for Security Operations tasks.
We replicated the @splunk BOTSv3 CTF environment in an eval to test frontier models' capability on realistic blue team cybersecurity tasks.
BOTSv3 comprises over 2.7M logs (spanning over 13 months) and 59 Question and Answer pairs that test scenarios such as investigating cloud-based attacks (AWS, Azure) and simulated APT intrusions.
See results and blog post in the thread below
1
145