
the average Cso, aka Mr Sweat 💦 I design, run, ship, lift, write. Building dailysweat.club & getflojo.com
Joined July 2013
- Tweets 846
- Following 931
- Followers 1,219
- Likes 25,884
44 Photos and videos

















cso retweeted

May 23
Liftoff of Starship V3, from the dunes right outside the pad.
This is the most insane shockwave action I have ever seen on video. Absolutely mad.
📽️ Me for @WeAreSpaceScout
269
2,165
15,274
2,994,035
one thing I love about AI is I sit thinking, with pen and paper, way more than before.
Rapid sketching 20 ideas, then handing off the best with some notes "to be made" might be the wet dream of all design minded people?
Also interesting merger of
- oldest tech: marks on surface, arguably the fastest way to visualize concept and think
- with super intelligence that executes.
Is this the way?
2
70
cso retweeted

May 6
“The secret to success is early to bed, early to rise. Work like hell, and advertise.”
— Ted Turner (RIP to a legend)
May 6

Arnold Schwarzenegger’s bio has great section on why he thought marketing a product was as important as making the product.
He ends it with a classic Ted Turner (RIP) he often cites: “Early to bed, early to rise. Work like hell, and advertise.”

32
1,152
9,786
591,020
cso retweeted

27 Oct 2025
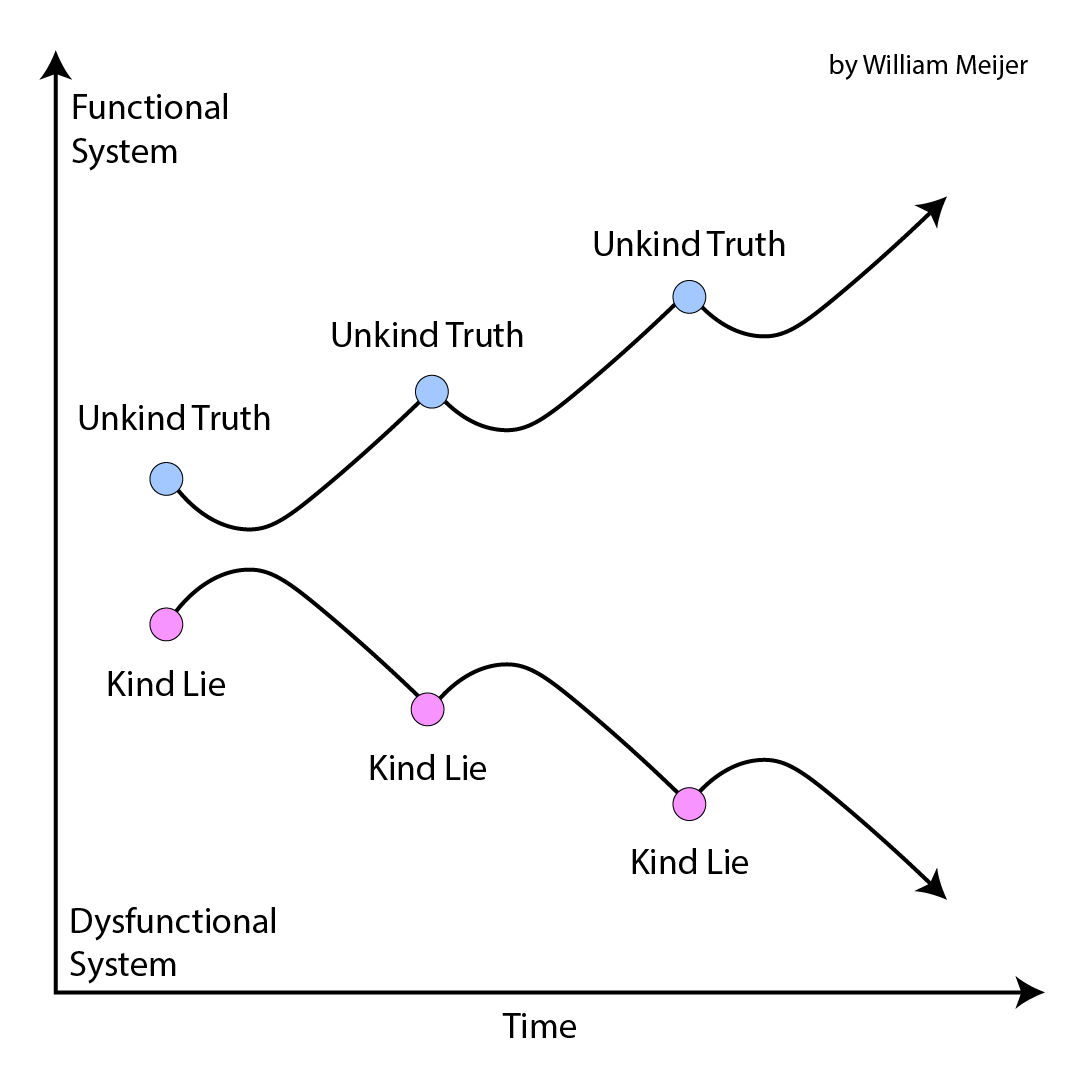
An extreme commitment to the truth makes relationships acutely dysfunctional but systems chronically functional (think Elon Musk).
An extreme commitment to kindness makes relationships acutely functional but systems chronically dysfunctional (think Sweden, UK)
359
1,881
12,265
1,718,757
cso retweeted

when you realize that touching a single grocery store receipt puts more BPA into your body than drinking from a plastic water bottle for an entire year

198
1,133
13,618
1,310,035
cso retweeted

May 5
The last 20% isn't most of the work, it's all of the work.
100
312
3,086
147,278
cso retweeted

May 6
the urge to quit everything and traverse the mountains of kazakhstan on horseback
51
402
4,296
123,947
cso retweeted

May 3
"Understand that ethical wealth creation is possible. If you secretly despise wealth, it will elude you." -@naval
13
9
485
38,495
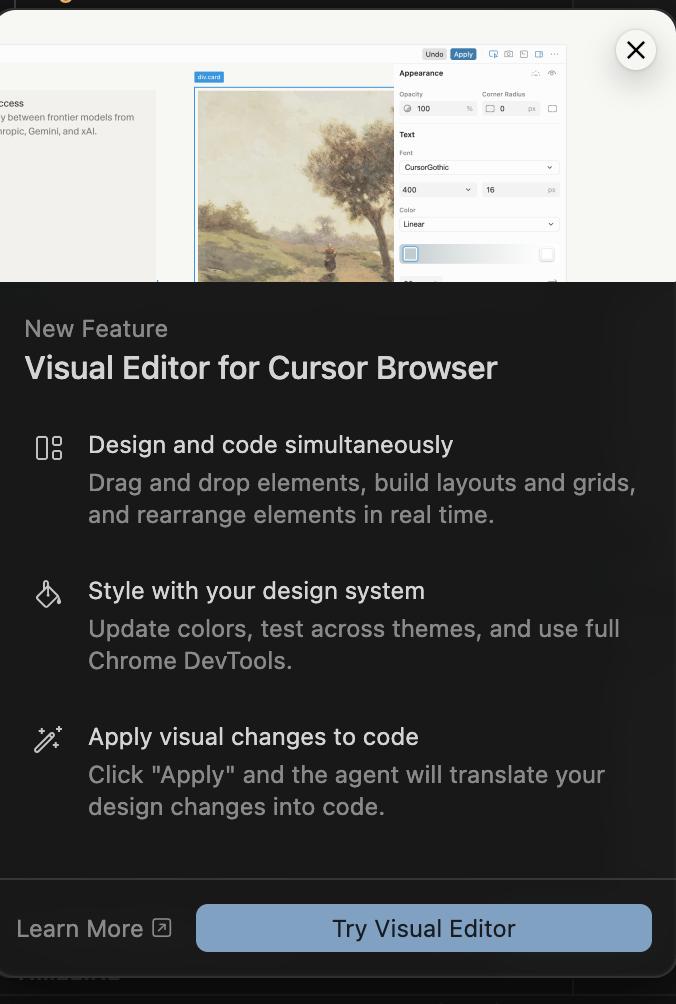
me with my clanker crew trying to center some divs

2
348
cso retweeted

Apr 10
動画生成じゃなくて画像生成
これwebカメラからのリアルタイム画像生成だけど動画生成のフレーム補完と違ってなんか温もりを感じて好き
112
522
5,170
270,676

cso retweeted

Apr 10
As I build my own 2nd brain 🧠 on Obsidian using @karpathy ‘s wiki idea, it suddenly dawned on me - one day when we r gone, our kids could inherit an interactive map to your mind, passion, obsessions, work, fascinations…
It’s kind of beautiful way to think abt your 2nd 🧠.
85
101
1,768
203,627
cso retweeted

Apr 10
This is only the second chimpanzee civil war ever documented. The first was Gombe, 1974. Fifty years apart. Genetic data suggests chimp communities split roughly once every 500 years.
Gombe was 9 males breaking off from a group of about 60. The splinter faction was hunted down over four years. Every male killed. Goodall had nightmares about it for decades.
Ngogo is operating at a completely different scale. 200 chimps. The largest studied community on Earth. They functioned as one unit for 20 years, shared territory, ran border patrols together, fought neighboring groups side by side. Then in 2015 something snapped. Five key males died, possibly from disease. Those males were the social bridges between two clusters. Once the connective tissue disappeared, the cliques hardened.
By 2017 they occupied separate territories and patrolled borders against each other. By 2018 the killing started. 28 dead so far, 19 of them infants. The Western faction, despite being smaller, initiated every attack. They ripped infants from mothers. The lead researcher calls himself a war correspondent.
The part that rewrites the textbook: no ethnic divisions, no religion, no ideology, no resource scarcity. Just a social network that lost its bridge nodes. The researchers think the same mechanic explains human civil wars better than cultural theories do. Polarization isn't about beliefs. It's about who stopped talking to whom.
Apr 9

JUST IN: Massive chimpanzee group in Uganda has reportedly split into rival factions & descended into a deadly “civil war”
121
1,250
10,531
1,312,521
meditation reinvented from first principles
Apr 9

the Elon Musk and Jim Simons approach to meditation and relaxation is something everyone should give a try. by far one of the most efficient ways to refresh yourself. 30mins is all you need to feel a massive difference in your mood, energy, and thoughts
149
cso retweeted

AI companies with software engineers
161
1,262
19,335
2,061,567
cso retweeted

Apr 4
let me explain what Karpathy just shared
he’s spending way less time using AI to write code and more time using it to build personal knowledge bases
the full breakdown:
→ he dumps raw sources (articles, papers, repos, datasets, images) into a folder. then has an LLM organize them into a wiki… a collection of markdown files with summaries, links between related ideas, and concept articles that connect everything together
→ he uses Obsidian as his frontend. he views raw data, the organized wiki, and visualizations all in one place. the LLM writes and maintains the entire wiki. he rarely touches it directly
→ once the wiki gets big enough (~100 articles, ~400K words on one recent research topic)… he just asks the LLM questions against it. no RAG (complex retrieval system) needed. the LLM maintains its own index files and reads what it needs
→ outputs aren’t just text. he has the LLM render markdown files, slide decks, charts, and images… then files the outputs back into the wiki so every question he asks makes the knowledge base smarter
→ he runs “health checks” where the LLM finds inconsistent data, fills gaps using web search, and suggests new connections and articles. the wiki cleans and improves itself over time
→ he even vibe coded a search engine over his wiki that he uses directly in a browser or hands off to an LLM as a tool for bigger questions
→ his next step: training a custom model on his own research so it knows the material in its weights… not just in the context window
most people use AI to get answers.
Karpathy is using AI to build his own ‘Jarvis’ via compounding knowledge systems that get smarter the more he uses them
the difference between asking ChatGPT or Claude a question and having a personal research engine that grows with every session is the gap most people haven’t crossed yet
and this is where it gets really powerful
not replacing your thinking but organizing everything you’ve ever learned into something you can query or create with forever
if you’ve been using CLAUDE .md and context files in Claude Code… this is that same idea at a much bigger scale
if you’re doing any kind of AI work or deep learning on a new topic right now…
this workflow is worth studying closely
you’ll want to adopt it yourself
this is one of AI’s brightest minds after all. we’re all better off listening to him.

Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
92
431
3,722
490,329
truly wild how fast he is at plucking ideas out of thin air then executing at lightning speed.
He just did all this during a chill dinner telegram chat convo that started around EU potential conscriptions, modern warfare, how would nerds get involved, clearly drones are the future- we need more drones sims - he makes this game.
I had 2 burger patties in the meantime lol.
My mind is absolutely blown every time I see he him do this, selecting / detecting an idea, jumping on it this fast and creating so effortlessly.

Added heat vision to my drone, then my friend @csonotes and me thought:
What if we make it like Where's Waldo and it's drones vs people?
And then in multiplayer?
So you choose which side, drone or people, and as a person you have to run around and find a spot to hide and you can shoot drones out of the air too
Very scary probably esp with the drone sounds
Only thing is I don't know how to get people to walk up these buildings, I don't think they have stairs

1
7
2,200
cso retweeted

93 years & 231 days old Ann Esselstyn dead hangs for 2 min 52 seconds! To set new WR. (Maybe we call it live hangs instead now?) Distal strength reflects many things.
439
937
17,365
1,764,991
