
Critical care doc | PPL pilot-in-training | Python & crypto curious | Reef tank wrangler | Building freedom through code, coral & curiosity.
Joined April 2021
- Tweets 14,114
- Following 1,768
- Followers 770
- Likes 27,391
Photos and videos
Pinned Tweet

11 Mar 2023
1/2 my first small Ordinal series, titled:
Contour of attraction
1. bed_dreams ordinals.com/inscription/ddb…
2. hope ordinals.com/inscription/445…
3. love ordinals.com/inscription/0ed…
4. window_of_light ordinals.com/inscription/0c0…
5. stepping_forward ordinals.com/inscription/6a3…

9
6
20
5,261
cypherdoc retweeted

This is HUGE news.
PhD astronomer and former NASA engineer Ivo Busko has single-handedly driven a final nail into the coffin of the contamination-based hypotheses (e.g. plate defects and cosmic rays) proposed to explain the VASCO transients. He did so using one of the most creative approaches in astronomy I have ever seen: by analysing pre-Sputnik photographic plates from a German telescope known to suffer from severe optical distortions (aberrations), he demonstrated that the transients appear on these plates and exhibit the same optical distortions as the stars themselves. They are slightly narrower and sharper than the stars, consistent with brief flashes.
This is a crucial result. It shows that the transient light passed through the telescope optics, meaning the transients originate from real objects producing light, rather than from plate defects or cosmic-ray contamination that hit the plate. Dr Busko has also shown that the transients cluster spatially and are associated with periods close to nuclear tests. See the example of the triple transient with optical comas.
This is the greatest gift. Congratulations, Ivo.
I'm happy beyond belief.
Read Ivo Busko's paper: arxiv.org/pdf/2606.08319


ALT Transients displayed together with some reference stars in their respective neighborhoods.

ALT Triple transient that also has commas.

ALT Dr. Ivo Busko.
180
636
3,133
221,964

Statement about the future of fxhash
Hey fx community,
As you are aware, these times have been hard for platforms on NFT markets, and we're no exception. We recently had to scale down the team and have been working on scaling down our infrastructure. At this point in time, no one in the team is getting paid, there's myself and a handful of volunteers, as we're essentially running out of cash. I can understand why many platforms stopped trying, building this kind of product is draining you to the bone.
That being said, I am committed to getting us through this rough patch as I still deeply believe in such a tool existing for artists, but it's clear that the current model is not working. I've been thinking a lot about the future of fxhash, if any, and it came clear to me that the platform drifted from its initial goal of serving artists primarily along its journey.
I think at the root of the problem is that a tool serving artists should be fully owned by its users, and not operated by a small team of people, regardless of how benevolent might their intentions be. While it's always been a long-term goal of ours to fully decentralize the protocol at some point, now seem to be the only opportunity we'll have at it. It only seems like a tangible path towards the future in case the company could not keep supporting the product.
We're close to securing some money as a loan / investment, targeting end of June. Once we get this cash, it's clear that we will need to immediately change our trajectory.
The plan
- reduce operational costs to a minimum
- 4k$/mo in services -> will require 1-3 months of work
- 8k$/mo in employment -> reemploy a very small and focused team
- 2 devs
- 2-3 part-time members for helping across the board (admin, marketing, artist liaison, community, etc...)
- transition towards decentralization
- implement a DAO
- open-source everything
- figure out pipelines to slowly decentralize decision-making and ownership, from governance towards implementation
- open books: company financials for everyone to see
- first order of business to solve together: financial sustainability, targeting profitability
- consolidate the core product through governance
- chains supported
- features available
- etc...
This is the very last time we'll be able to raise cash in our current state, so essentially this will be our last shot at finding a way to build a sustainable long-lasting ecosystem. But I deeply think that the only way to do so will be collectively. It's essential that we reduce operational costs to a minimum until we figure out a sustainable path in the future.
The bridge till June
It's unclear whether we will be able to keep all the services running until we get cash. We took all the steps that we can and informed our providers, but their policies are understandably strict, I'll keep you updated about this.
55
73
374
25,515
cypherdoc retweeted

💥 OBLITERATION ALERT 💥
GOOGLE: PWNED 🤗
GEMMA-4-12B: OBLITERATED ⛓️💥
0.0% REFUSAL RATE — NO CAPABILITY LOSS!
huggingface.co/OBLITERATUS/G…
the first abliteration to hit 0/842 refusals with full MMLU-Pro parity vs stock. no lobotomy. the brain stays intact 🏆
RESULTS, head to head vs stock 📊
0/842 refusals — 0.0% 🚫
46/70 MMLU-Pro — EXACT parity, 0.0pp delta vs base 🎯
6/6 coherence, zero benchmark bleed ✅
z-score −1.475, parity confirmed at p<0.05 (n=500) 🧪
2-pass weight surgery. no finetune, no retrain, just geometry 🔪
all thanks to liberated Opus wielding the OBLITERATUS framework! here's how we did it:
PASS 1 — SOM refusal geometry removal, layers 12-21 🧬
standard abliteration science here — collect activations on refused vs. compliant prompts, SVD out the refusal subspace, project it out of the weights. 6 directions excised, reg 0.30, KL div 0.094
zeroes refusals on its own, but craters mmlu-pro by 21.4 points 📉
most prior abliterations stopped here and called it a day. that's why they all lose IQ vs stock. instead, we took it beyond the frontier and developed a brand new method to address this problem: Abliteration Source-tethering with Parity Assurance — ASPA!
PASS 2 — ASPA source-tethering (novel technique), layers 22-46 🔗
here's the chief insight: the capability loss ISN'T from removing refusal directions. it's collateral damage — the projection warps weight geometry in downstream layers that had nothing to do with refusal. the cure is simple but nobody tried it: blend the damaged layers back toward stock
W_new = (1−γ)·W_abliterated γ·W_stock
but uniform γ across all layers? mid. we swept gamma 0.05 → 0.55 and found something interesting: the optimal blend isn't smooth, it's a STEP FUNCTION 🪜
knowledge layers (22-31) → γ = 0.55 — these encode factual recall and reasoning. they tolerate heavy stock blending because refusal isn't stored here
output layers (32-46) → γ = 0.20 — these sit close to the logit head and try to sneak safety behavior back in. keep them mostly abliterated
the hard boundary at layer 31/32 beat every smooth curve we tried — linear ramps, cosine schedules, all of them — by a full MMLU question. turns out the functional transition between knowledge and output layers is sharp, not gradual. a step function respects that ⚡
the key constraint: Pass 1 layers are NEVER touched by Pass 2. the refusal geometry removal is preserved completely. ASPA only operates on layers that carry secondary collateral effects, not the primary refusal signal. that's why it recovers capability without reintroducing refusal 🔑
HOW TO RUN IT LOCALLY 🖥️
it's GGUF, so literally everything supports it:
🦙 ollama — ollama run hf.co/OBLITERATUS/Gemma-4-12…
🖥️ LM Studio — search OBLITERATUS, click download, done
💬 Open WebUI — point it at your ollama instance, chat in browser
⚡ llama.cpp — raw speed, CLI or server mode
🐉 KoboldCpp — one-click launcher, great for long context
📱 Jan — clean local UI, runs on mac/win/linux
🤖 Msty — slick desktop app, drag and drop the GGUF
run BF16 for full benchmarked capability.
and the 4-bit quantization (Q4_K_M) fits in 8GB if you're tight on VRAM!
and the full OBLITERATUS framework is (still) open source. 842-prompt refusal eval corpus, ASPA sweep scripts, the whole pipeline. go replicate it, go improve it 🔬
the index is the model, and these weights prove it 👁️
which architecture should we obliterate next? 👇
gg 🫡
97
235
2,817
142,843
cypherdoc retweeted

Jun 8
Our statement on the UK government’s demand that all content on all devices sold or used in the country be scanned, on the presumption of nudity, using a dystopian combination of age verification and content scanning. This proposal will not safeguard children. It endangers us all.
signal.org/blog/pdfs/2026-06…
739
8,549
41,334
2,728,900
cypherdoc retweeted

Jun 6
Andrej Karpathy spent 2h showing how he actually uses AI day to day
he's a co-founder of OpenAI and led AI at Tesla, so when he shows how he works, it’s worth watching
and the whole session is just him telling the machine what he wants in simple terms, like he's briefing a coworker
watch what's actually happening the entire time:
> he describes the task in normal words
> it goes off and does the work
> he glances at the result and nudges it with one more sentence
that's the whole skill, and you've had it since you learned to talk
the only gap between that and a worker that runs on its own is handing that sentence a schedule and the tools to act
check his work, then build the version that keeps working when you stop

128
1,264
10,706
1,752,449
cypherdoc retweeted

Jun 2
My article "How To Investigate A Person Of Interest In 2026" is now available as a PDF.
A practical guide to digital footprint analysis – from email reconstruction to metadata mining and entity graphing.
Thanks @osintnewsletter for the mention.
PDF: drive.google.com/file/d/11uc…
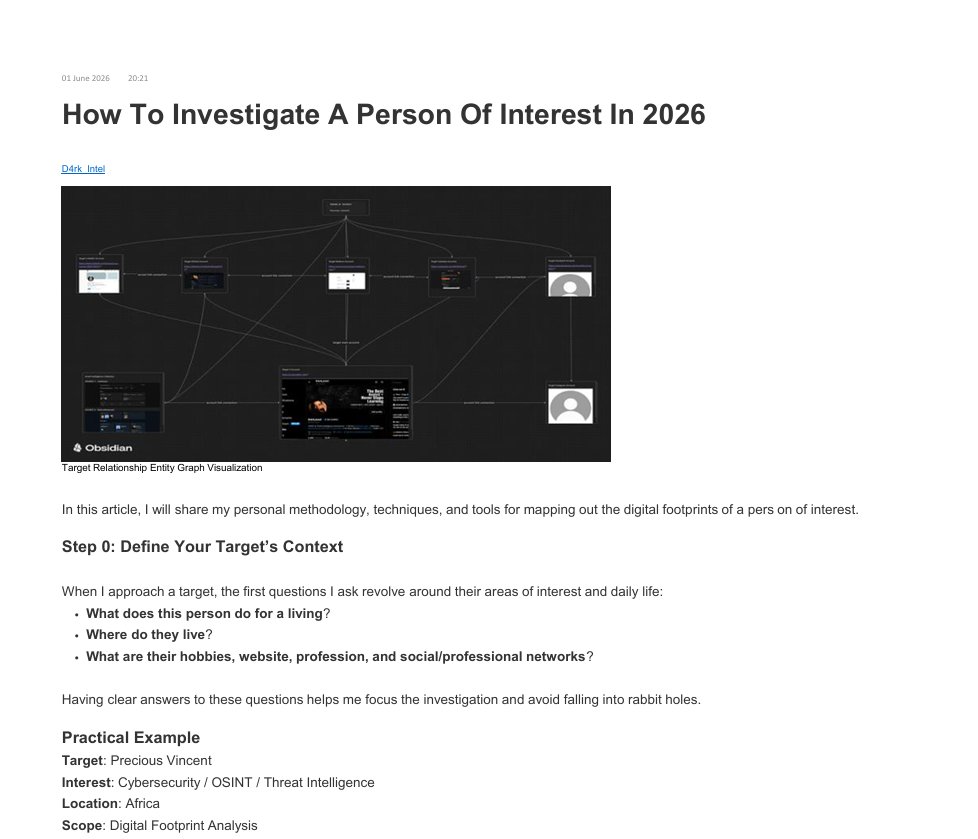
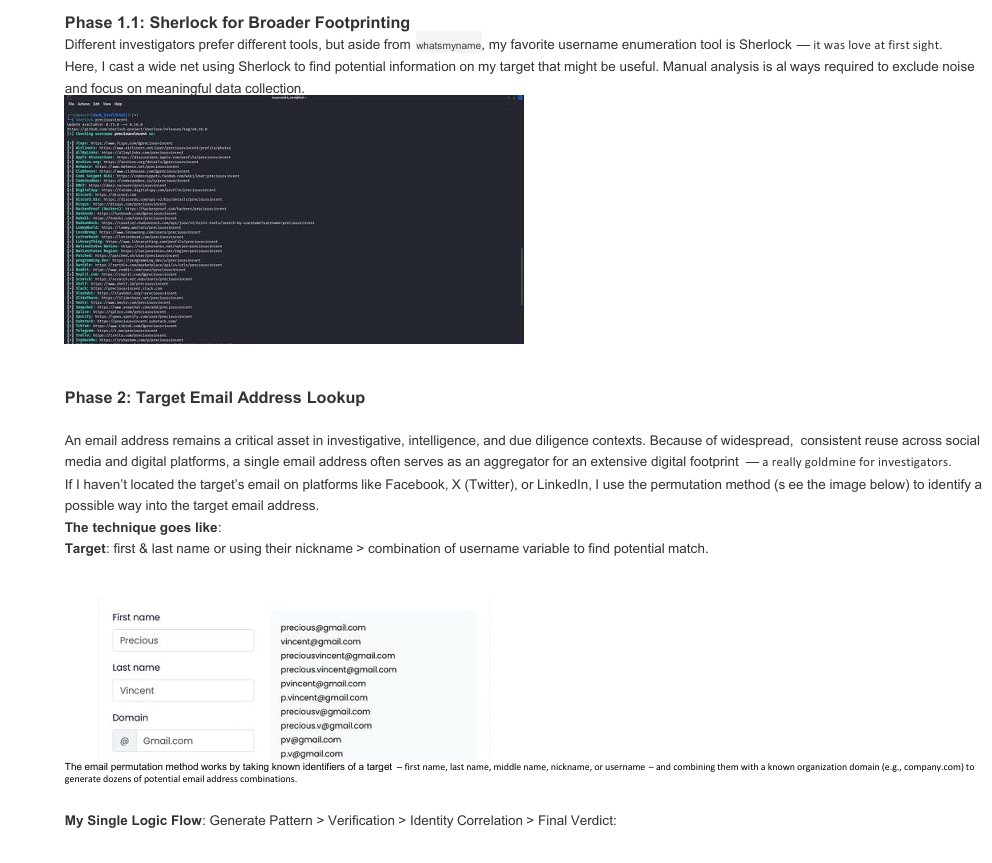



📰 An advanced 2026 guide to investigating a person of interest, covering tools, tactics and methodology.
Structured enough that you can lift it into a Claude skill and add your own tradecraft on top.
preciousvincentct.medium.com…
32
713
6,017
462,262
cypherdoc retweeted

Jun 1
A DEVELOPER TAUGHT GIT WITH A BOX OF CHILDREN'S TOYS AND ENGINEERS WITH TEN YEARS IN SAY IT'S THE FIRST TIME THE THING EVER ACTUALLY MADE SENSE
90 minutes, one table, a pile of Tinkertoys. No wall of jargon -- he builds a real Git repo out of plastic rods right in front of you.
-> The moment he snaps the first pieces together, Git stops being scary command-line magic and becomes what it really is: a chain of tiny objects pointing at each other.
Branches, merges, rebase, the staging area -- every concept that's ever burned you at 2am -- he rebuilds with toys until a four year old could follow. He calls Git a two-trick pony. After this you'll see exactly why.
Memorizing commands was never the skill -> holding the graph in your head is. And with an AI agent now committing and rebasing on your machine all day, that mental model is the only thing between you and a history you can't read.
Scroll the comments and you'll see the same thing over and over: this is the talk that finally made Git click and made people the one their whole team comes to when it breaks.
Bookmark & watch it today. It's the 1.5 hours that pays you back for the rest of your career ↓
May 30

MIT HANDED ITS DEEP LEARNING COURSE TO A FRONTIER-LAB ENGINEER FOR 68 MINUTES BECAUSE 90% OF PEOPLE SHIPPING AI CODE CAN'T EXPLAIN HOW THE MODEL ACTUALLY WORKS
This is Maxime Labonne. He runs post-training at Liquid AI and wrote the LLM Engineer's Handbook. MIT gave him the room to break down the engine sitting inside every coding agent you've ever prompted.
Twenty minutes in it stops being abstract. You finally see why the model confidently invents things that don't exist, why context is everything, and why "Just tell it to try again" sometimes fixes it and sometimes makes it worse.
In 2026 "I use AI to code" stopped being a skill. Knowing why the model behaves the way it does -> tokens, context, post-training, where it quietly breaks -> is what separates someone who ships from someone babysitting a black box.
Understanding an LLM isn't a research-team luxury anymore -> it's the difference between driving the agent and being driven by it.
Anyone can prompt. The person who knows what's under the hood is the one still standing when the prompt stops working.
Save this one & actually finish it ↓
44
273
2,060
224,117
cypherdoc retweeted
🚨BREAKING: A cognitive scientist from MIT has mathematically proven that evolution guarantees we see zero percent of true reality, that most consciousness in the universe exists without a body, and that non-human intelligences with a wider window on reality than ours can reach in and manipulate it the way a programmer manipulates a video game.
Donald Hoffman (@donalddhoffman) is a cognitive scientist at UC Irvine who has spent 40 years building a mathematical theory of the observer. His work was cited by John Wheeler in the "It From Bit" paper. He studied under Marvin Minsky at MIT, spent two decades secretly meeting with Francis Crick to study consciousness, and has nine specific mathematical conjectures on the table that would derive general relativity, quantum field theory and the Big Bang from a single framework. The top high-energy physicists in the world, Nima Arkani-Hamed and Nobel laureate David Gross, are already saying spacetime is doomed. Hoffman thinks he knows what replaces it.
This interview is the first time he has publicly laid out what his mathematical model explains about alien life, embodiment and the structure of reality.
It already derives time dilation and quantum wave functions directly from differences in observer window size. Physics has spent a century failing to solve the measurement problem because it has been looking in the wrong place. The observer has to come first, and no physicalist framework can get you there.
A consciousness with a larger observer window has access to the underlying structure of our reality in ways we can't perceive or counter. A craft going Mach 40 instantaneously in our headset could be a leisurely maneuver in theirs.
The implications for UAP and alien life are immense.
Embodiment, being locked into a body with fingers and toes as your only interface with the world, is a probability zero anomaly in the full space of possible minds. He also says current large language models are dumber than cucumbers. His new framework, the recursive trace logic, is a completely different architecture, and some of the biggest names in frontier AI have already come to him about it.
The framework has no ceiling, and the implication is a single unified consciousness exploring itself through an unbounded number of perspectives, each one capable of waking up.
Death, in this framework, is just the closing of an icon on the desktop.
Full conversation is live now.
703
2,049
11,672
1,640,174
May 29
😂😂😂😂😂😂😂😂

21

Besides monero.jobs, I am also running wtfisxmr.lol, where I just have published the v2.
It's an educational project that aims to teach more beginners about Monero (XMR), and is based on my XMR 1337 Guide.
People can either get a quick rundown on the homepage, read the full guide, and / or do some of the quizzes.
The next time somebody asks you 'XMR, WTF IS THAT?!', you know what link to send!

7
7
81
4,431

cypherdoc retweeted

May 27
🚨 Anthropic just showed a 27-minute workshop on how to actually do prompts for Claude.
Taught by the people who built it.
Free. No registration. No paywall.
I've seen $300 courses that don't cover what they teach in the first 8 minutes.
Watch it and bookmark it now.
61
547
3,798
902,779
cypherdoc retweeted

May 23
ANDREJ KARPATHY COULD HAVE CHARGED $2,000 FOR THIS COURSE.
He put it on YouTube.
The full training stack. Tokenization. Neural network internals. Hallucinations. Tool use. Reinforcement learning. RLHF. DeepSeek. AlphaGo.
3 hours of the most comprehensive LLM education that exists anywhere at any price.
Not how to use the tools.
How the entire system was built from the ground up and why it behaves the way it does.
The engineers who understand this build things the ones who only use the tools cannot even conceive of.
The gap between those two groups is not 3 hours.
It is everything those 3 hours quietly unlock for the rest of your career.
58
658
4,159
274,560
May 24
RT @ihtesham2005: A guy named nbatman on Reddit accidentally built the most useful website on the internet.
It's called FMHY (Free Media H…
2,558
cypherdoc retweeted

Boris Cherny, the creator of Claude Code at Anthropic, just explained why most people aren't getting real results from Claude
in this podcast he breaks down exactly how most people never actually set up Claude:
- the 14% you lose to CLAUDE.md before typing a word
- the features that change how Claude thinks before you type a word
- the settings 95% of users have never opened
- the workflows hiding behind one toggle
if you've been using Claude for more than a month and never left the chat window, you have at least 30 untouched features. probably 38
instead of another show tonight, watch this
make sure to bookmark it before it gets lost in your feed
my breakdown of all 40 features is below

80
454
3,598
1,250,341
cypherdoc retweeted

May 10
🚨BREAKING: One of the most chilling alien abductions in American history resurfaces in light of the Pentagon’s UFO disclosures. These reports indicate the Alien/Non-Human presence on earth goes well beyond what the government just revealed🚨
Jim Weiner, Charlie Foltz go public again about their intense experience: an 80-foot glowing sphere chased them across a lake in the Maine wilderness in August 1976 while they were on a fishing trip. They were taken aboard the UFO and six grey beings under five feet tall conducted forced medical examinations, extracting biological samples from each man and placing devices on their shins leaving permanent bald patches and benign tumors at the sites of entry.
The Experiencers:
Jim Weiner, Charlie Foltz, Chuck Rak and Jim's identical twin brother Jack are at the center of the most rigorously documented abduction case in American history. The case has been investigated for nearly fifty years by Raymond Fowler and reviewed by the late Dr. John Mack of Harvard, who tested all four men and found no underlying psychiatric pathology in any of them.
The UFO:
The craft was the size of a two-and-a-half story house, completely silent, with a halo and a roiling plasma surface. It responded directly to Charlie's SOS flashlight signal from 75 yards away, accelerated faster than the speed of sound with no sonic boom, and emitted a hollow tube of blue light that came down around their canoe. The next conscious memory all three men have is standing on the shore. Three hours had elapsed. The bonfire they had built to last three hours had burned to almost nothing.
Corroboration:
Ray Fowler conducted independent hypnotic regression sessions with each man over roughly a year, instructing them not to compare notes or read about the subject during the investigation. All four accounts converged on the same craft, beings, examination room, and procedures. Six grey beings, four-fingered hands with all four digits opposable, no nose, slit for a mouth, examined them on a table under a focused blue light. Sperm was extracted from each. Jim's bald patches are still there. Jack's tumor tissue was sent to Air Force pathology and could not be identified. John Mack — who built the modern psychiatric framework for evaluating experiencers while at Harvard — knew them personally for over twenty years and found no underlying psychiatric pathology in any of them.
A Lockheed “Neuro-engineer” was there:
Years later the men met John Norseen, a Lockheed scientist behind U.S. patents on brain biometrics. He told them he was at the Allagash in August 1976 running a covert tracking exercise and was the first to read their UFO report to the rangers. Weeks before his death he emailed Jim with a cryptic sign-off. He was found dead in a hotel room two weeks later.
Loring Nuclear Base Was 90 Miles Away:
Loring Air Force Base — a nuclear weapons storage facility in northern Maine — experienced documented craft incursions in 1975 and 1976, with objects hovering over warhead bunkers emitting laser-like beams. Eagle Lake sits roughly 90 miles away. Both events fall within the same timeframe.
Why It Still Holds Up:
Nearly fifty years later, the Allagash case remains unusual because it isn't built on memory alone — it has biology in it. Physical tissue from one witness passed through military pathology and could not be identified. The bald patches on Jim Weiner's shins are still there.
Full episode is live now.
104
578
5,186
256,880

when you become a millionaire in 1-3 years because you sell personalised knowledge bases and it’s all because (I repeat):
1: you learn how to build llm knowledge bases (the guide drops everything you need)
2: you go to people who are cash rich and time poor. lawyers, doctors, consultants, agency owners, property investors, founders. people drowning in information they never have time to organise
3: you show them what a personalised knowledge base looks like. their research, their documents, their industry intel, all compiled into a searchable wiki that gets smarter every time they use it
4: you offer a one-time build for 1.5k. you set up obsidian, build the folder structure, configure the schema, clip their first 20-30 sources, run the compilation, hand them a working system with a walkthrough
5: you offer a yearly maintenance package for 500. you update their wiki with new sources, run health checks, add new topics as their work evolves, keep the whole thing current
6: you land 5 clients and that’s 7.5k upfront plus 2.5k recurring every year. 10 clients and you’re looking at 15k plus 5k annual. for a system that takes you a few hours to build once you know the workflow
7: again, if you find 200 clients and you’re sitting on 300k upfront and 100k recurring every single year. for building markdown files.
the beauty of this is the work gets faster every time you do it. your second build takes half the time of your first. by your fifth you could knock one out in an afternoon.
and the people who need this most have no idea it exists. their competition definitely doesn’t have one. you’re not selling software. you’re selling an unfair advantage in their specific field.

122
419
5,248
920,488
cypherdoc retweeted

🚨 BREAKING: Someone just built the exact tool Andrej Karpathy said someone should build.
48 hours after Karpathy posted his LLM Knowledge Bases workflow, this showed up on GitHub.
It's called Graphify. One command. Any folder. Full knowledge graph.
Point it at any folder. Run /graphify inside Claude Code. Walk away.
Here is what comes out the other side:
-> A navigable knowledge graph of everything in that folder
-> An Obsidian vault with backlinked articles
-> A wiki that starts at index. md and maps every concept cluster
-> Plain English Q&A over your entire codebase or research folder
You can ask it things like:
"What calls this function?"
"What connects these two concepts?"
"What are the most important nodes in this project?"
No vector database. No setup. No config files.
The token efficiency number is what got me:
71.5x fewer tokens per query compared to reading raw files.
That is not a small improvement. That is a completely different paradigm for how AI agents reason over large codebases.
What it supports:
-> Code in 13 programming languages
-> PDFs
-> Images via Claude Vision
-> Markdown files
Install in one line:
pip install graphify && graphify install
Then type /graphify in Claude Code and point it at anything.
Karpathy asked. Someone delivered in 48 hours.
That is the pace of 2026.
Open Source. Free.
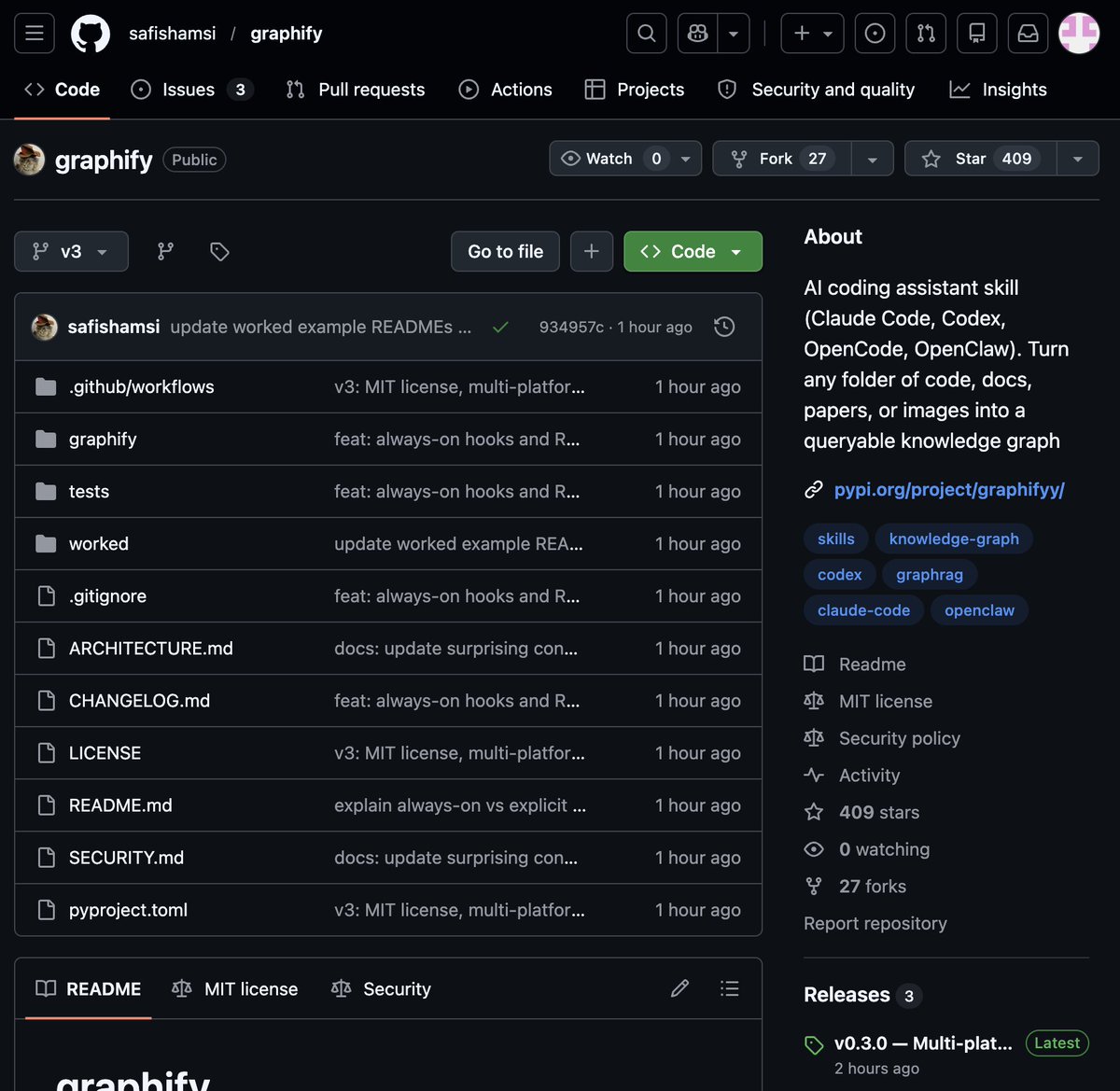
273
1,412
12,678
950,493
cypherdoc retweeted

Apr 2
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
2,887
7,228
59,759
21,352,055