
building loudecho.ai | real-time AI ad platform
Joined April 2009
- Tweets 640
- Following 707
- Followers 403
- Likes 2,994
36 Photos and videos













Daniel Keyes retweeted

Fable isn't the first.
In 1999 the department of defense blocked exports of the PowerMac G4 for crossing the 1 gigaflop threshold.
Steve Jobs turned it into an ad.
127
1,026
12,506
857,568
Daniel Keyes retweeted

Jun 12
No, you don't get it.
He does not have $1 trillion sitting in cash, it is 99% stock in his companies.
To make that wealth liquid would mean selling all that stock which would swiftly destroy *both* the companies (Tesla, SpaceX, others) and the wealth. If he sold it all, he'd end up with maybe $100b max, several hundred thousand people would be out of work, the companies ruined and many of their suppliers also ruined.
Okay, but now Elon has $100b in cash, and can "solve the world's problems".
$100b divided by the world's 8 billion people is $12
If you were in charge, several of the most innovative industrial companies in the world would be destroyed, hundreds of thousands out of work, and space would again close to human civilization for another generation.
But everyone on earth could have one nice meal and you could revel in your altruism.
671
2,691
30,982
883,201


Jun 8
just be yourself -- don't try to be yourself.
Jun 7

trying to do the thing vs just doing the thing
this applies to a lot more than just smiling

36
Daniel Keyes retweeted

May 28
The rarest object type in the universe isn't black holes. It's us. Conscious matter. The flame of life.
We have a duty to expand it in scope and scale in order to preserve it.
855
2,001
11,177
1,420,721
Daniel Keyes retweeted

May 25
you only need a two more 10x increases to have ten times more power in space than on earth and then at that point you can beam down excess power via microwaves to ground stations and just turn off all the Fossil fuel power plants on Earth and then bam clean worldwide energy
50
23
521
66,527

Daniel Keyes retweeted

May 19
May 19

Over at Substack, @JoshEakle asks: "It's 2026, and I have yet to see an anti-almond farm protest."
124
573
5,906
931,336
Daniel Keyes retweeted

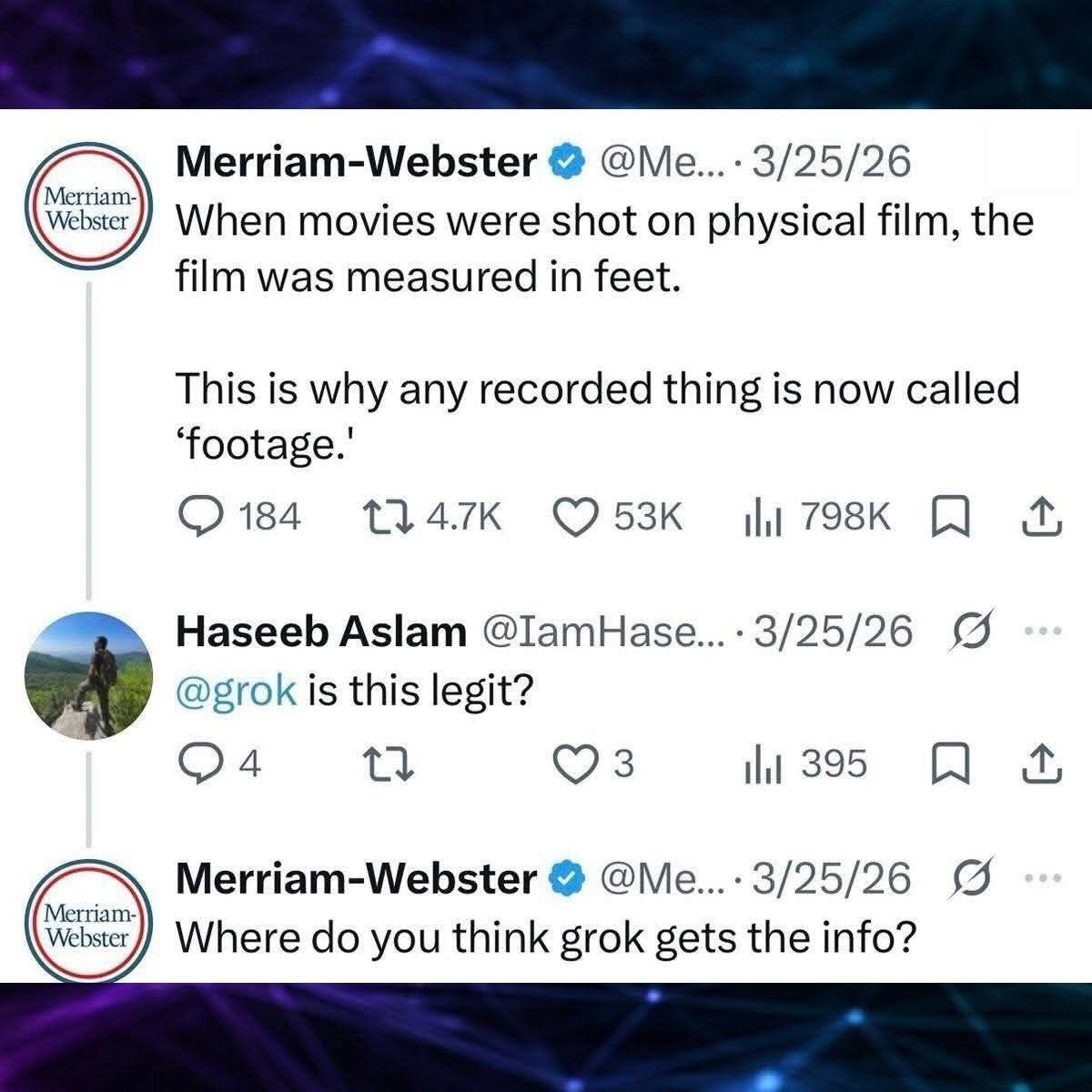
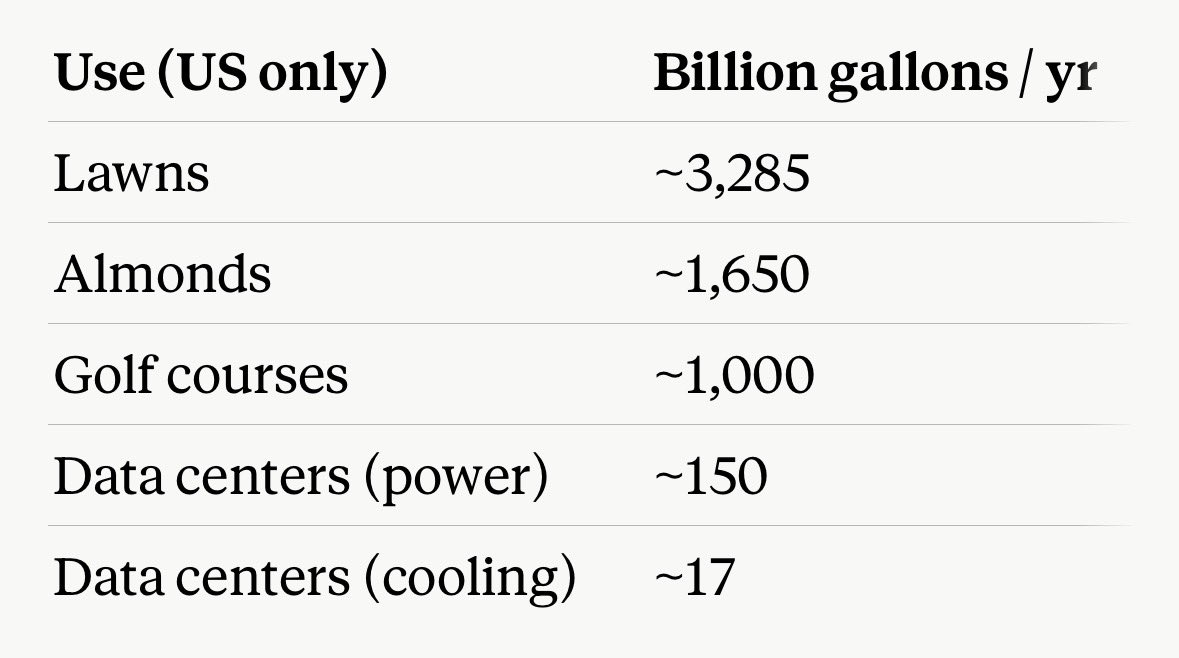
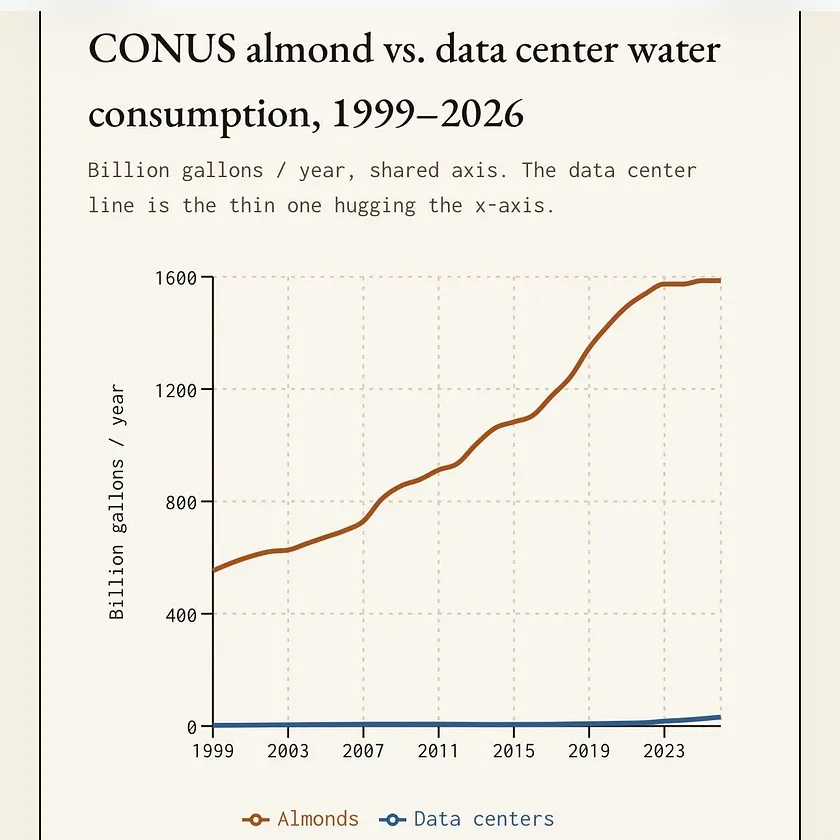
Data centers are not stealing your water
322
294
1,991
722,447
Daniel Keyes retweeted

May 19
Instantly identifiable AI writing isn't annoying — it's a radical shift in how fucking annoying it is.
1
1
16
4,430
May 4
insane alpha on X if you know where to look
25
Daniel Keyes retweeted

Apr 30
Someone should come up with an exchange rate between these two currencies.

190
277
8,647
385,038
Apr 16
finally getting better at naming things

Codex for (almost) everything.
It can now use apps on your Mac, connect to more of your tools, create images, learn from previous actions, remember how you like to work, and take on ongoing and repeatable tasks.
32
Apr 15
open-source -> open-to-attacks
in fact, it's entirely possible that by next year, most open-source projects will be built by attackers to hide backdoors
Apr 15

Open source is dead.
That’s not a statement we ever thought we’d make.
@calcom was built on open source. It shaped our product, our community, and our growth. But the world has changed faster than our principles could keep up.
AI has fundamentally altered the security landscape. What once required time, expertise, and intent can now be automated at scale. Code is no longer just read. It is scanned, mapped, and exploited. Near zero cost.
In that world, transparency becomes exposure. Especially at scale.
After a lot of deliberation, we’ve made the decision to close the core @calcom codebase.
This is not a rejection of what open source gave us. It’s a response to what risks AI is making possible.
We’re still supporting builders, releasing the core code under a new MIT-licensed open source project called cal. diy for hobbyists and tinkerers, but our priority now is simple:
Protecting our customers and community at all costs.
This may not be the most popular call.
But we believe many companies will come to the same conclusion.
My full explanation below ↓
1
48
Apr 8
we now know who the robot overlords will go after first

41
Apr 7
this is brilliant.
it's a step function more helpful than many other AI UXs.
Apr 7

I built this thing called Clicky.
It's an AI teacher that lives as a buddy next to your cursor.
It can see your screen, talk to you, and even point at stuff, kinda like having a real teacher next to you.
I've been using it the past few days to learn Davinci Resolve, 10/10.
28
Daniel Keyes retweeted

Mar 31
People are bearish on memory, but the leaked Claude Code source code is showing us some additional memory demand that the market hasn't priced in IMO.
1. The market thinks about AI memory demand as a server-side story: HBM on H100s/B200s for inference. What the bug reports reveal in this code is that the client-side of AI coding agents is also extraordinarily memory-hungry. Idle Claude Code processes growing to 15GB each, active sessions hitting 93-129GB. This matters because the feature flag pipeline (DAEMON, PROACTIVE, CRON) points toward future always-on background agents. If a developer has a persistent daemon agent running alongside their active sessions, you're looking at baseline memory consumption of 15-30GB just for Claude Code on a developer workstation - before they even open their IDE, browser, or anything else. This means either enterprise IT needs a big uplift to higher-RAM workstations or we move even more memory-hungry workloads towards the cloud.
2. The Auto Dream consolidation feature runs background Claude sessions to clean up memory files. One observed consolidation took 8-9 minutes processing 913 sessions. In other words, a meaningful fraction of Anthropic's token consumption is the system managing its own memory, not the user doing productive work. As memory systems get more sophisticated (team sync, cross-session event buses, memory consolidation), this overhead grows. It's a recursive cost - more memory features require more inference to manage memory. I don't think anyone is modeling this as a distinct line item in token consumption estimates.
3. 1M token context windows for Claude Code. Moving from 200K to 1M context is a 5x increase in KV cache memory per session on the server side. Combined with multi-agent (5-15x per user) and the proactive/daemon features (sessions that persist for hours/days instead of minutes), you get a compounding memory demand curve that's steeper than linear adoption growth that many analysts model.
Memory demand per active user is increasing faster than user count, because each user's sessions are getting longer, wider (more agents), and deeper (larger context windows).
Mar 31

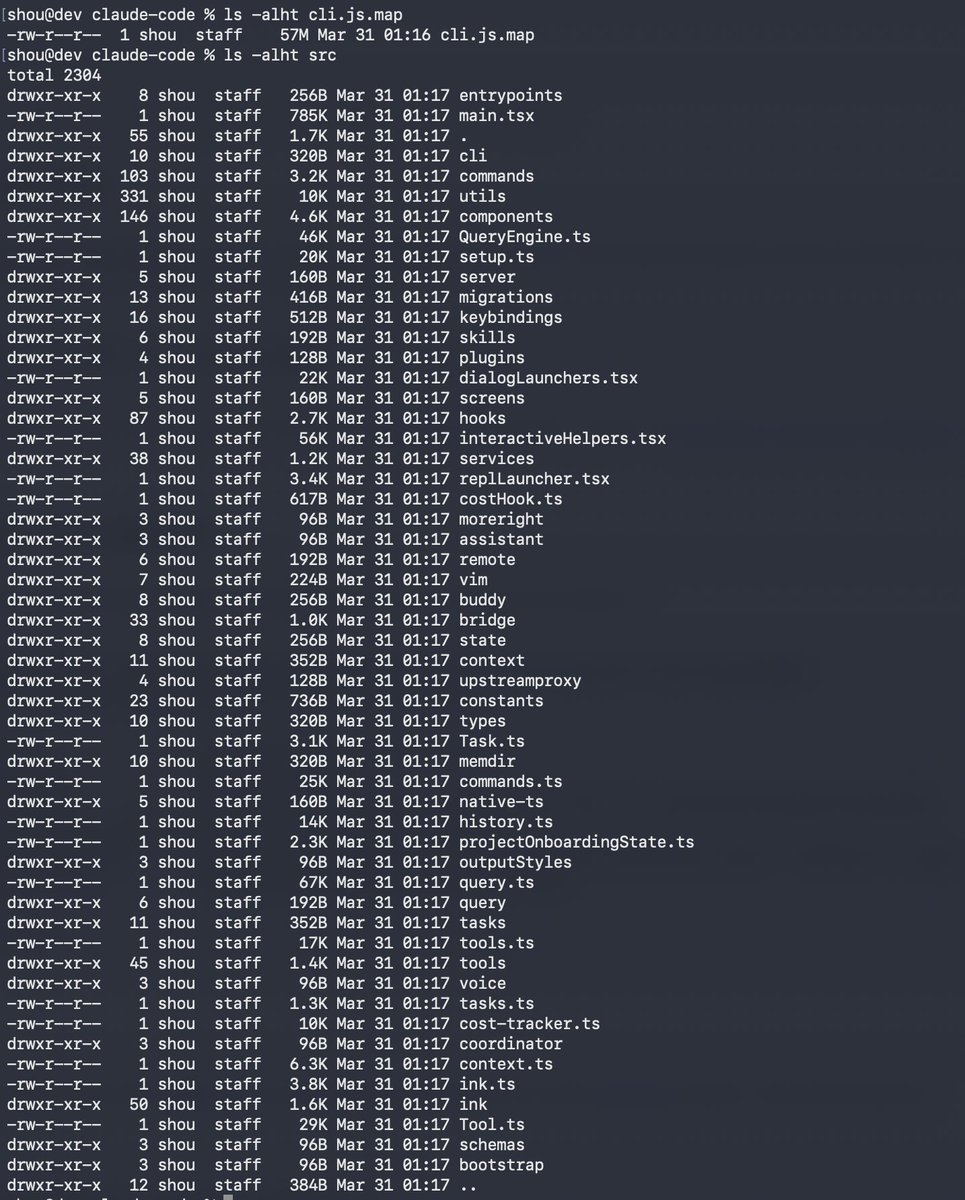
Claude code source code has been leaked via a map file in their npm registry!
Code: pub-aea8527898604c1bbb12468b…
36
95
761
234,512
Mar 27
i remember when being an AI engineer was just telling it think step by step
the nostalgia hits hard
30