
Research Scientist @Meta. PhD from @Princeton ORFE. Interested in RL.
Joined March 2009
- Tweets 221
- Following 1,696
- Followers 850
- Likes 1,868
24 Photos and videos







Daniel Jiang retweeted

Jun 4
We've lost an absolute giant today. RIP Dimitri Bertsekas. His probability and optimization books got me through my masters. Massive loss for the MIT community and the field.
18
116
1,021
92,874
Daniel Jiang retweeted

Self-correction for LLMs is usually done by critiquing an answer and regenerating the entire reasoning trace. We show targeted backtrack-and-resample works better: self-localize the first erroneous step, then sample a counterfactual. Repeat.
[1\n]
8
3
5
1,839
Daniel Jiang retweeted

Oh, to me it is the opposite. LLM RL is when you say supervised fine-tuning (SFT) instead of behavior cloning, RLVF instead of batch policy optimization,
base policy instead of behavior policy, trace instead of trajectory, verifiable reward instead of reward, .. LOL
2
4
38
2,825
Daniel Jiang retweeted

Apr 8
When I teach, I prepare my lecture notes by writing on Goodnotes, then export them as PDFs and share to the class. Recently I asked claude code to read these PDF files and convert them into markdown. This is a test I constantly gave to new LLMs and now claude is good enough to pass it.
I converted my RL theory graduate-level course into markdowns and post the lecture notes here: zhuoranyang.github.io/sds685…
When preparing the course, I learned a lot from the wonderful courses offered by @CsabaSzepesvari @chijinML @WenSun1 @nanjiang_cs and borrowed some good stuffs from their notes. Also I discussed what to teach in a RL course heavily with @zhaoran_wang and stole many of his insights.

6
60
488
77,131
Daniel Jiang retweeted

Mar 31
✨New paper alert
Does AI help or harm critical thinking? It’s one of the most pressing questions around AI. But maybe the better question is: under what conditions? In our #CHI2026 paper, we find that time can change everything.
🌐 criticalthinking-ai.app/
#AI #criticalthinking #humancognition #decisionmaking #civicparticipation
(1/10)
2
7
28
2,980
Daniel Jiang retweeted

Feb 12
Introducing Simile.
Simulating human behavior is one of the most consequential and technically difficult problems of our time.
We raised $100M from Index, Hanabi, A* BCV, @karpathy @drfeifei @adamdangelo @rauchg @scottbelsky among others.
502
827
7,775
2,352,092
Great work by @Ankur_Samanta_ on self-improvement in LLMs via RL post-training on “debate” outcomes!

Can LLMs self-improve reasoning without external supervision?
Introducing MACA: RL for teaching agents how to better leverage multi-agent debate. No external labels—just copies of the model learning from each other.
Improved collaboration, accuracy, and self-consistency.
[1\n]
4
327
Daniel Jiang retweeted

29 Dec 2025
What if we boost LLM output diversity by fusing base and aligned models?
Excited to share this work led by @YichenZW, whose passion for understanding LLM diversity really shows here. More insights and fun ideas on LLM creativity coming soon as well!💡
22 Dec 2025

Lack of diversity in your LLM generation?
(also noted by Artificial Hivemind, best paper @NeurIPSConf)
Time to bring your base model back!
An inference-time, token-level collaboration between a base and an aligned model can optimize and control diversity and quality!

2
24
5,433
Daniel Jiang retweeted

29 Oct 2025
TD Learning can suffer on long tasks: ↑ deep bellman recursions → ↓ poor scalability (despite big data)
We introduce a new method (TRL) with a "divide-and-conquer" value update, which scales well with long horizons!
2
31
235
62,836
Daniel Jiang retweeted

10 Oct 2025
This paper shows that you can predict actual purchase intent (90% accuracy) by asking an LLM to impersonate a customer with a demographic profile, giving it a product & having it give its impressions, which another AI rates.
No fine-tuning or training & beats classic ML methods.



141
684
7,638
902,545
Daniel Jiang retweeted

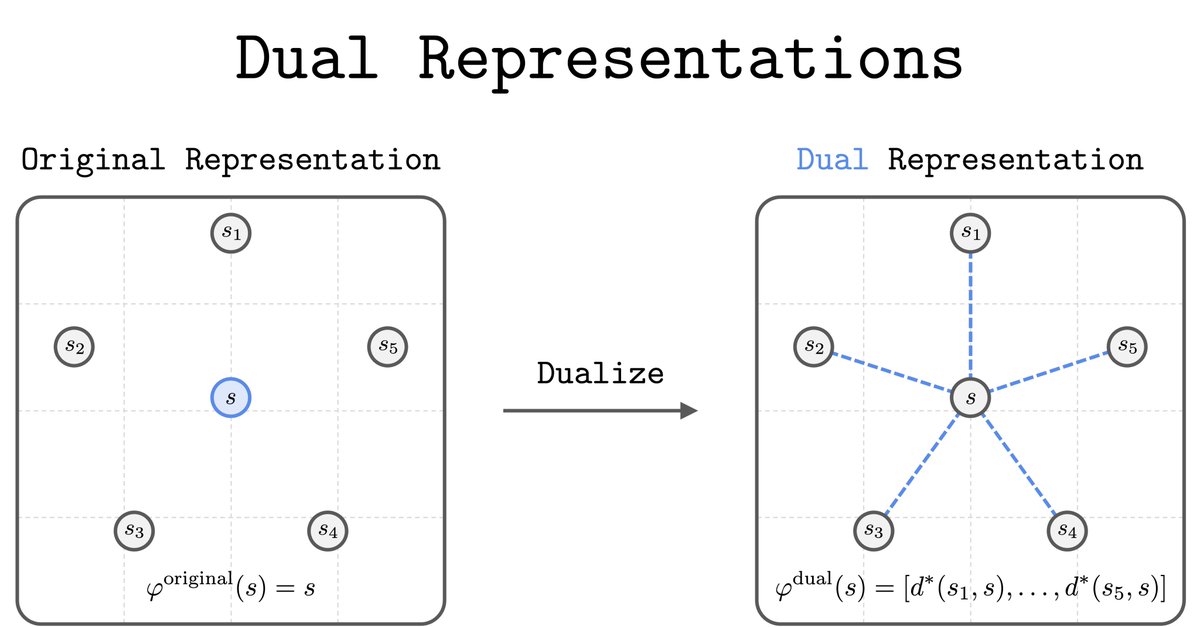
9 Oct 2025
Introducing *dual representations*!
tl;dr: We represent a state by the "set of similarities" to all other states. This dual perspective has lots of nice properties and practical benefits in RL.
Blog post: seohong.me/blog/dual-represe…
Paper: arxiv.org/abs/2510.06714
↓
14
121
941
180,751
Daniel Jiang retweeted

7 Aug 2025
Honored that our @RL_Conference paper won the Outstanding Paper Award on Empirical Reinforcement Learning Research!
📜Mitigating Suboptimality of Deterministic Policy Gradients in Complex Q-Functions
📎openreview.net/forum?id=H3jc…
Grateful to my advisors @JosephLim_AI and @ebiyik_!

6 Aug 2025

At @RL_Conference🍁, I'm presenting a talk and a poster on Aug 6, Track 1: Reinforcement Learning Algorithms.
We find that Deterministic Policy Gradient methods like TD3 often get stuck at local optima under complex Q-functions, and propose a novel actor architecture!
🧵

9
11
72
8,085
Daniel Jiang retweeted

6 Aug 2025
Use the same @ExpectedParrot survey you ran w/ LLMs with actual humans via our @Prolific integration (or bring your own panel) - it works!

2
2
7
1,151

31 Jul 2025
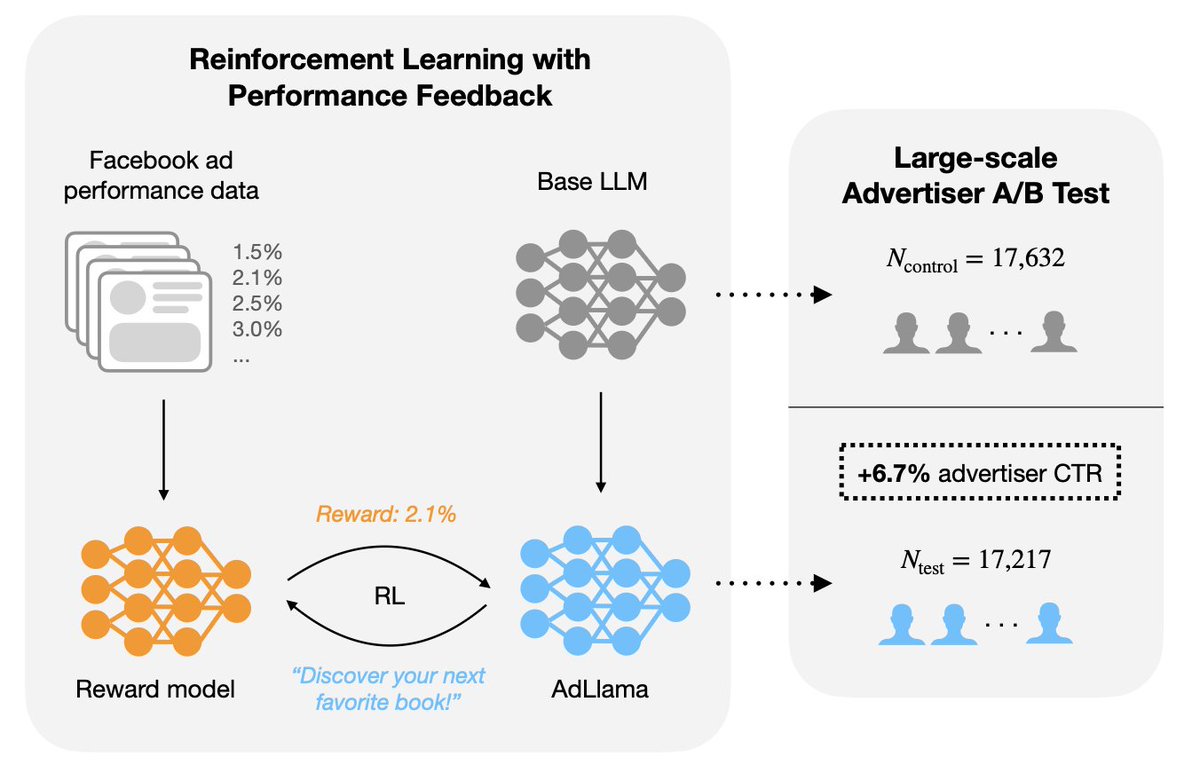
Sharing our new preprint on using reinforcement learning (RL) to post-train LLMs for generative ads on Facebook! Joint work with Alex Nikulkov, Yu-Chia Chen, Yang Bai, and @ZheqingZhu.
Paper link: arxiv.org/abs/2507.21983
2
4
21
3,441
31 Jul 2025
In a 10-week A/B test with 35,000 advertisers and 640,000 ad variations, we found that our advertisers using the RL-trained LLM created more performant ads compared to those who used an existing supervised model (trained to imitate curated examples).
1
1
152
31 Jul 2025
We think this is exciting because it suggests that metric-driven post-training can work at scale, and could be applied more broadly beyond online ads, especially in domains where generative AI is already proving useful. Please let us know of comments or feedback!
1
129
Daniel Jiang retweeted

18 Jun 2025
Wrapped up Stanford CS336 (Language Models from Scratch), taught with an amazing team @tatsu_hashimoto @marcelroed @neilbband @rckpudi. Researchers are becoming detached from the technical details of how LMs work. In CS336, we try to fix that by having students build everything:
46
570
4,922
679,080
Daniel Jiang retweeted
24 May 2025
What does it mean to write and think with AI? What new possibilities and challenges does that bring?
I spoke with THE AI (in Korean) about our group's research and the future of writing with AI. 👩🤖✍️
newstheai.com/news/articleVi…
3
10
62
11,823
Daniel Jiang retweeted

13 May 2025
CATransformers is a carbon-driven neural architecture and system hardware co-design framework. Using CATransformers, we discover greener CLIP models that achieve an average of 9.1% reduction potential in total lifecycle carbon emissions while maintaining accuracy (or increasing accuracy) and latency.
This research is the first to look into carbon-driven neural architecture and system hardware co-design. It is enabled by a first-of-its-kind architectural carbon modeling tool – ACT, which we developed at FAIR.
Check out:
Our paper ➡️ go.fb.me/nedmh0;
code repository ➡️ go.fb.me/7jcp6q;
and the additional carbon design tools and research artifacts in Sustainable AI ➡️go.fb.me/csee32
20
71
324
32,607