
An MIT spin-off that's making synthetic data a reality.
Joined October 2020
- Tweets 79
- Following 76
- Followers 93
- Likes 25
42 Photos and videos














Excellent article in @Forbes today calling #syntheticdata “an all-too-rare example of…genuinely useful” generative AI, for the particular application of software testing.
Read @jpwarren profile of @datacebo and @kveeramac :
forbes.com/sites/justinwarre…
#bigdata #syntheticdata #generativeai #data #datascience #enterprisedata #tabulardata #predictiveAI #machinelearning #ML #generativemodels #MLmodels #productiontesting #softwaretesting #cybersecurity #hacking #infosec #security
4
7
739
SDV Enterprise v0.24.0 is out 🎉
This release adds features that help you generate higher quality synthetic data and improve ease-of-use.
🌟 Model hierarchical relationships in a table. Use the SelfReferentialHierarchy CAG pattern when you have a column in a table that references the same table. This represents a hierarchical relationship between the rows.
📦 Program your synthesizers with bulk updates. Update the data preprocessing for many columns at once using our bulk update function. This is compatible with any of the preprocessing transformers in the RDT library.
📚 Read the full Release Notes here: docs.sdv.dev/sdv-enterprise/…
📚 Learn more about the SDV: sdv.dev/
#syntheticdata #generativeai #machinelearning #ai

1
105
Today, we’re excited to introduce a powerful new bundle to the @sdv_dev: AI connectors. AI connectors address 2 key challenges that SDV users face when training generative AI models on datasets from enterprise data stores. (Link to the announcement: bit.ly/3EURLCB)
❎ Creating accurate metadata is time consuming, especially for complex multi-table schemas
Metadata provides a deeper context (semantic and statistical) about your data and the synthesizers use this context to generate high quality synthetic data. Without AI connectors, SDV users have to export data from the database, use SDV’s metadata auto-detection feature to establish metadata, and then manually update the metadata to be accurate.
✅ AI Connectors automatically generate higher quality metadata
AI connectors automatically infers higher quality metadata using the database schema and our own inference engine, without having to read tables into memory from the database.
When benchmarked with 55 datasets stored in 4 different database platforms, metadata generated using AI connectors resulted in 35% higher quality metadata (average score of 0.98) compared to metadata generated using the auto-detection approach (average score of 0.73).
❎ Identifying a referentially sound and representative sample for training data is tricky
Training SDV Synthesizers requires loading a representative sample of data from your database into memory. In addition, the data needs to have referential integrity for the synthesizers to learn the proper relationships. Approaches to identifying a high quality, referentially sound sample of data can be tedious and time-consuming to implement.
✅ AI Connectors uses an inbuilt algorithm to generate a training data set and guarantee referential integrity
With AI connectors, we created an algorithm called Referential First Search (RFS) that guarantees that the real data used to train the model is a subset with referential integrity. When benchmarked with 7 datasets stored in 5 different databases, training data created using AI connectors achieved an average of 18% higher quality data score over the standard approach of random subsampling and then enforcing referential integrity after.
Read more about AI connectors and how to access it in our latest product announcement here: bit.ly/3EURLCB
#syntheticdata #generativeai #machinelearning #databases
1
83
SDV Enterprise v0.23.0 is out 🎉
This release enhances your ability to program your synthesizer to find certain patterns and recreate them— whether it's through multi-table CAG patterns, single-table constraints, or pre-processing techniques that transform your data.
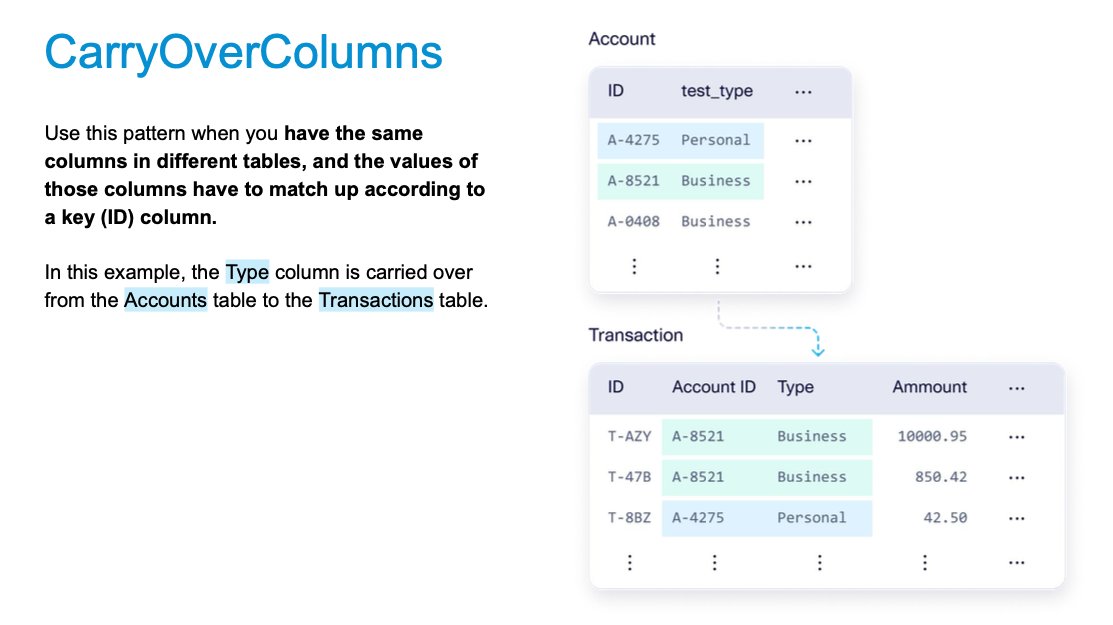
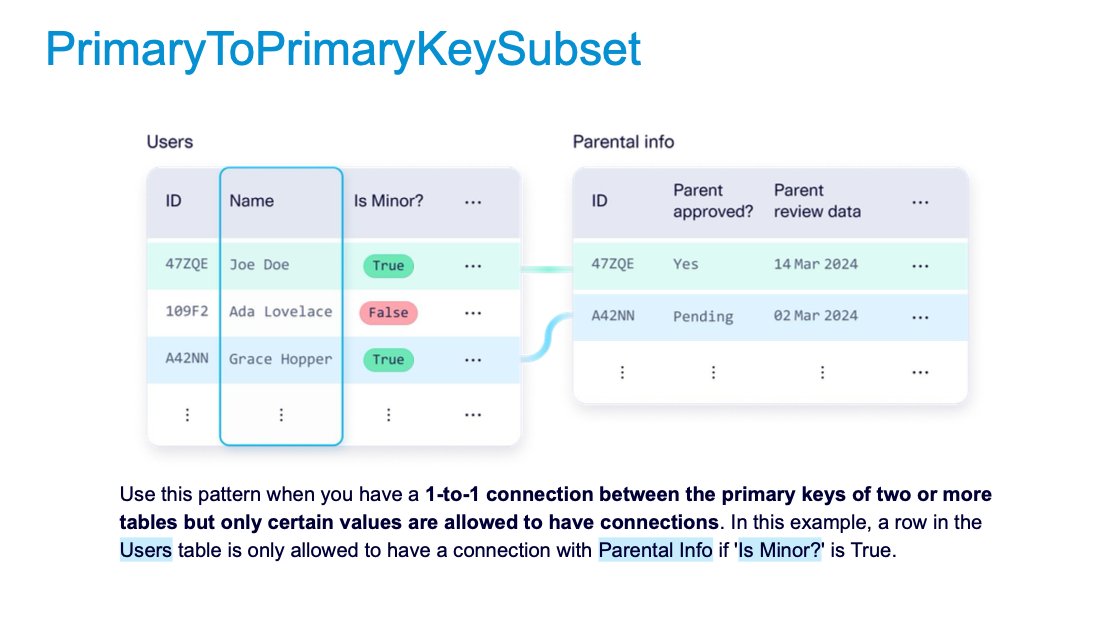
🏆 Improved CAG patterns. Use CarryOverColumns to specify a column that is repeated across many tables with different relationships. The PrimaryToPrimaryKeySubset pattern now works with missing values. See more about these interesting data patterns SDV Enterprise supports in the slides below.
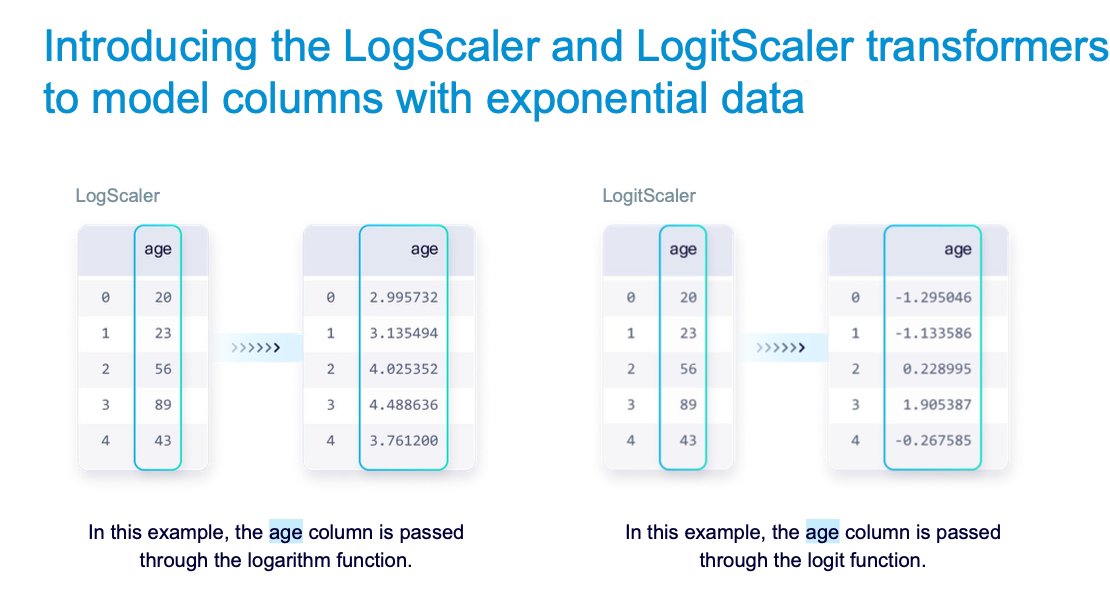
💡 Experiment with new transformers to improve your synthetic data quality. Try applying the new LogScaler and LogitScaler on data that exhibits exponential properties.
📚 Read the full Release Notes here: bit.ly/4152LVn
📚 Learn more about the SDV: bit.ly/4b858Lu
#syntheticdata #generativeai #machinelearning #ai

1
68
Today, we are excited to introduce a very powerful new framework to The Synthetic Data Vault : 𝗰𝗼𝗻𝘀𝘁𝗿𝗮𝗶𝗻𝘁 𝗮𝘂𝗴𝗺𝗲𝗻𝘁𝗲𝗱 𝗴𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 (#CAG for short). CAG addresses the shortcomings of generative models in capturing the context buried in enterprise data stores - with human input. (Link to the announcement: datacebo.com/announcements/i…)
❎ 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗔𝗜 𝗺𝗼𝗱𝗲𝗹𝘀 𝗳𝗮𝗶𝗹 𝘁𝗼 𝗰𝗮𝗽𝘁𝘂𝗿𝗲 𝗱𝗲𝘁𝗲𝗿𝗺𝗶𝗻𝗶𝘀𝘁𝗶𝗰 𝗿𝗲𝗹𝗮𝘁𝗶𝗼𝗻𝘀𝗵𝗶𝗽𝘀 𝗯𝗲𝘁𝘄𝗲𝗲𝗻 𝗰𝗼𝗹𝘂𝗺𝗻𝘀, 𝗿𝗼𝘄𝘀, 𝗮𝗻𝗱 𝘁𝗮𝗯𝗹𝗲𝘀. We call such relationships database context. Database context describes hard and fast rules under which data is created and stored.
What is even harder is that usually, this context is not explicitly stored within the database schema itself – but data teams know that it exists. Downstream applications process this data based on the context using logic within the application software.
When the generative models are used to create #syntheticdata the expectation is that the #syntheticdata will also follow the database context.
✅ When we launched The Synthetic Data Vault — a system to enable enterprises to build generative models for their own #multitable data — we provided the ability to include context via what we called #𝗰𝗼𝗻𝘀𝘁𝗿𝗮𝗶𝗻𝘁𝘀.
🔥 Over the years, 𝗰𝗼𝗻𝘀𝘁𝗿𝗮𝗶𝗻𝘁𝘀 𝗵𝗮𝘀 𝗯𝗲𝗰𝗼𝗺𝗲 𝗼𝗻𝗲 𝗼𝗳 𝘁𝗵𝗲 𝗺𝗼𝘀𝘁 𝗽𝗼𝗽𝘂𝗹𝗮𝗿 𝗳𝗲𝗮𝘁𝘂𝗿𝗲𝘀 𝗼𝗳 𝗼𝘂𝗿 𝗦𝗗𝗩 𝗘𝗻𝘁𝗲𝗿𝗽𝗿𝗶𝘀𝗲 𝗽𝗿𝗼𝗱𝘂𝗰𝘁.
💪 𝗪𝗶𝘁𝗵 𝗖𝗔𝗚 𝘄𝗲 𝗮𝗿𝗲 𝗱𝗼𝘂𝗯𝗹𝗶𝗻𝗴 𝗱𝗼𝘄𝗻 𝗼𝗻 𝘁𝗵𝗶𝘀 𝗳𝗼𝗰𝘂𝘀. To use this new and powerful framework, users can just pick the pre-defined pattern that corresponds to their database context and tell SDV where to apply it. It will then augment your synthesizer directly with this information. And 100% valid #syntheticdata
𝗥𝗲𝗮𝗱 𝗺𝗼𝗿𝗲 𝗮𝗯𝗼𝘂𝘁 𝗖𝗔𝗚, 𝘄𝗵𝗮𝘁 𝗶𝘁 𝗺𝗲𝗮𝗻𝘀 𝗳𝗼𝗿 𝘆𝗼𝘂, 𝗮𝗻𝗱 𝗵𝗼𝘄 𝘁𝗼 𝗮𝗰𝗰𝗲𝘀𝘀 𝗶𝘁 𝗶𝗻 𝗼𝘂𝗿 𝗹𝗮𝘁𝗲𝘀𝘁 𝗽𝗿𝗼𝗱𝘂𝗰𝘁 𝗮𝗻𝗻𝗼𝘂𝗻𝗰𝗲𝗺𝗲𝗻𝘁 𝗵𝗲𝗿𝗲: datacebo.com/announcements/i…
𝗛𝗮𝗽𝗽𝘆 𝗵𝗼𝗹𝗶𝗱𝗮𝘆𝘀 𝗮𝗻𝗱 𝗲𝗻𝗷𝗼𝘆 𝘀𝘆𝗻𝘁𝗵𝗲𝘀𝗶𝘇𝗶𝗻𝗴!
- from all of DataCebo Team
#syntheticdata #generativeai #data #machinelearning #ml #ai
1
1
4
130
Working with customers all over the world has taught us about one important, but often overlooked benefit of using #syntheticdata: increased data diversity.
Data diversity refers to the overall variety of data that is accessible for a project. While it's a simple concept, increasing data diversity can deliver enormous value to an organization — allowing for more robust testing, better predictions, and even higher creativity.
In our latest blog post, (link: lnkd.in/eumZtB38) Neha Patki elaborates this concept using some concrete examples. In the blog we cover:
✳️ How #generativeai models in #SDV (@sdv_dev ) can create #syntheticdata that is diverse ?
✅ How generative models maintain the delicate balance between creating novel (diverse) data and preserving high degree of statistical resemblance to real data
❎ While we can create really diverse data using random data generators, they won’t resemble the real data.
Also in this blog are examples of how data diversity as generated by #syntheticdata impacts the outcomes. (Links to each of these case studies are in the blog as well)
Diverse synthetic data enables creation of a more robust product. ING creates synthetic financial transactions with 100x the combinations present in their real data. This allows them to thoroughly test all aspects of a complicated payments service, and keep their payments systems working.
Diverse #syntheticdata can help make better predictions. A research team at UCLA (@UCLA ) created synthetic credit card fraud events, which combined different characteristics of real fraud events into rarer occurrences. The synthetic data allowed them to better predict future credit card fraud by nearly 20x.
It allows product development teams to navigate new ideas. One promising new direction for research and development teams involves using synthetic data to invent brand new products by combining attributes of existing ones.
Link to the blog: datacebo.com/blog/synthesize…
2
3
270
🚀🔥 #CTGAN has been downloaded over 2.5 million times. 🔥🚀
Released #thisweek in 2019: version 0.1.0 of #CTGAN as part of The Synthetic Data Vault, a Deep Learning-based #syntheticdata generator for single-table data that can learn from real data and generate synthetic data with high fidelity.
During this time:
🙌 It continues to be the go-to model for many #fortune500 companies who want to create #syntheticdata to train robust #AI models
👍 It has been used for a wide variety of use cases in the domains ranging from #energy, #healthcare, #education, #insurance and many others
🔥It has been used to create #syntheticdata for data science competitions, to improve predictive accuracy of healthcare models, and to accurately predict fraud, to name a few.
🤝 Data created using #CTGAN has been used by more than 30,000 data science teams.
❤️ Thank you to all our users who used it and gave a ton of feedback which has helped us build it further and further.
With its demand surpassing any other generative AI model for tabular data, we will be releasing more features for CTGAN in the near future.
Check it out here: docs.sdv.dev/sdv/single-tabl…
#syntheticdata #datascience #dataanalytics #DS #sdv
Happy synthesizing!
- The DataCebo Team
1
2
194
Upon popular demand we have added the ability to connect to databases to bring data to The Synthetic Data Vault (@sdv_dev ). Users can now directly connect #SDV Enterprise to their databases, both to import real data and to export #syntheticdata. We have added #bigquery and #mssql and many more are in the pipeline.
With this new feature users can:
➡️ 𝙸𝚖𝚙𝚘𝚛𝚝 𝚍𝚊𝚝𝚊 from a database
✅ 𝙲𝚛𝚎𝚊𝚝𝚎 𝚖𝚎𝚝𝚊𝚍𝚊𝚝𝚊 for #generativeai modeling automatically
✔️ 𝙸𝚖𝚙𝚘𝚛𝚝 𝚊 𝚘𝚙𝚝𝚒𝚖𝚒𝚣𝚎𝚍 𝚜𝚞𝚋𝚜𝚎𝚝 for modeling
➡️ 𝙴𝚡𝚙𝚘𝚛𝚝 𝚜𝚢𝚗𝚝𝚑𝚎𝚝𝚒𝚌 𝚍𝚊𝚝𝚊 to the database
This feature is in Beta — try it out and let us know what you think.
Link to the documentation: docs.sdv.dev/sdv/multi-table…
66
#otd in 1998 Yann LeCun (@ylecun) submitted a paper on gradient-based deep learning for document recognition.
It took more than a decade before the world finally warmed to neural networks. He has since had his paper cited roughly 70,000 times, and in 2018 won the Turing Award, widely viewed as "the Nobel Prize of computing."
The original paper: yann.lecun.com/exdb/publis/p…
213
🏆 We are pleased to share that DataCebo has been awarded a contract by the U.S. Department of Homeland Security’s (@DHSgov ) under the call for a Synthetic Data Generator.
With The Synthetic Data Vault (@sdv_dev ) the DHS will be able to build, deploy, and manage sophisticated generative AI models to generate high-quality synthetic data to:
✅ Test new applications and services with synthetic operational data.
🔍 Simulate impacts on cyber-physical systems without requiring access to the system or live data.
🧨 Create training data for ML when real world data is unavailable, restricted, or cost prohibitive.
We look forward to contributing to mission critical systems pertaining to national security, and collaborating with the DHS!
Link to the press release: dhs.gov/science-and-technolo…
#syntheticdata #generativeai #SVIP #dhs #sdv
1
4
205
Born #otd in 1950: the Turing Test. Alan Turing's paper from 74 years ago describes a modified version of the "imitation game" in which a human judge has to determine which of two typing partners is a computer.
June 2024: In related news, one recent study found that human subjects judged GPT-4 to be human more than half the time: livescience.com/technology/a…
August 2024: Consider these two sample tabular datasets. One is generated using @sdv_dev and the other is not which one is real and which one is synthetic (top or bottom)?
The original paper from turing: academic.oup.com/mind/articl…
#syntheticdata #generativeai #tabulardata #sdv
2
80
One of our users exclaimed "These speedups are insane!" Our multi table synthesizer in SDV Enterprise, called HSA Synthesizer, runs in less than 1 minute what takes HMA Synthesizer an hour - across 20 datasets.
❇️ We have been focusing on multi table synthesizers. #syntheticdata platform must address the complexity of multi table enterprise data at scale.
🔥 The 70x speeds fundamentally change how one uses #SDV. If you can model that fast and sample even faster the need to save model and version it goes away.
✅ What is more interesting is that these speed ups have not been achieved by increasing the compute required, but fundamentally changing the algorithms.
We are continuously evolving and more to come.
You can learn more about the trade offs in this blog: datacebo.com/blog/multi-tabl…
#syntheticdata, #generativeai, #performance -- @sdv_dev
1
5
101
In 1956, to store 5MB it required a hard disk that weighed a ton. In 2024 a #generativeai model can capture the salient properties of terabytes of data in an entire database within a single file and recreate it on demand - what we call #syntheticdata.
#otd in 1956 IBM launched the first commercial hard-disk drive, the Model 350 RAMAC, which weighed a ton and stored the equivalent of roughly 5 MB.
In comparison, today's largest commercial hard drive - Seagate's Exos X Mozaic - has 6 million times more space, at 30TB.
And … in 2024 with generative AI: Now a generative model of a file size of a few GBs can capture the salient properties of the data and recreate 30TBs of #syntheticdata with the same statistical properties and that looks like the real data on-the-fly
Read more about the original article about IBMs first hard disk here: storagenewsletter.com/2011/0…
2
83
Happy birthday to the late Dennis Ritchie, inventor of C and co-creator of Unix.
C and C have played a key role in the big data revolution, having been the origin languages for some of the core components of popular ML libraries, including #PyTorch and #TensorFlow.
Multics, the original project, had started in the mid-1960s as a time sharing operating system. Ken Thompson, Dennis Ritchie, Douglas McIlroy, and Joe Ossanna branched out and decided to reimplement a much simpler version of the project which became #unix.
More about Ritchie's legacy in ZDNET: zd.net/2creeZi
94
#OTD in 2016 we submitted the final camera ready version of the Massachusetts Institute of Technology paper ⭐️ The synthetic data vault ⭐️
The paper said:
"This synthetic data must meet two requirements:
1️⃣ First, it must somewhat resemble the original data statistically, to ensure realism and keep problems engaging for data scientists.
2️⃣ Second, it must also formally and structurally resemble the original data, so that any software written on top of it can be reused.
In order to meet these requirements, the data must be statistically modeled in its original form, so that we can sample from and recreate it. In our case and in most cases, that form is the database itself. Thus, modeling must occur before any transformations and aggregations are applied."
Today, #sdv counts millions of downloads, thousands of users and so many additional modules have been added to evaluate #syntheticdata, #benchmark models and so much more..
You can find the original paper here: dai.lids.mit.edu/wp-content/…
#syntheticdata, #generativeai, #tabulardata , #ai, #machinelearning, #DataScience
3
5
260
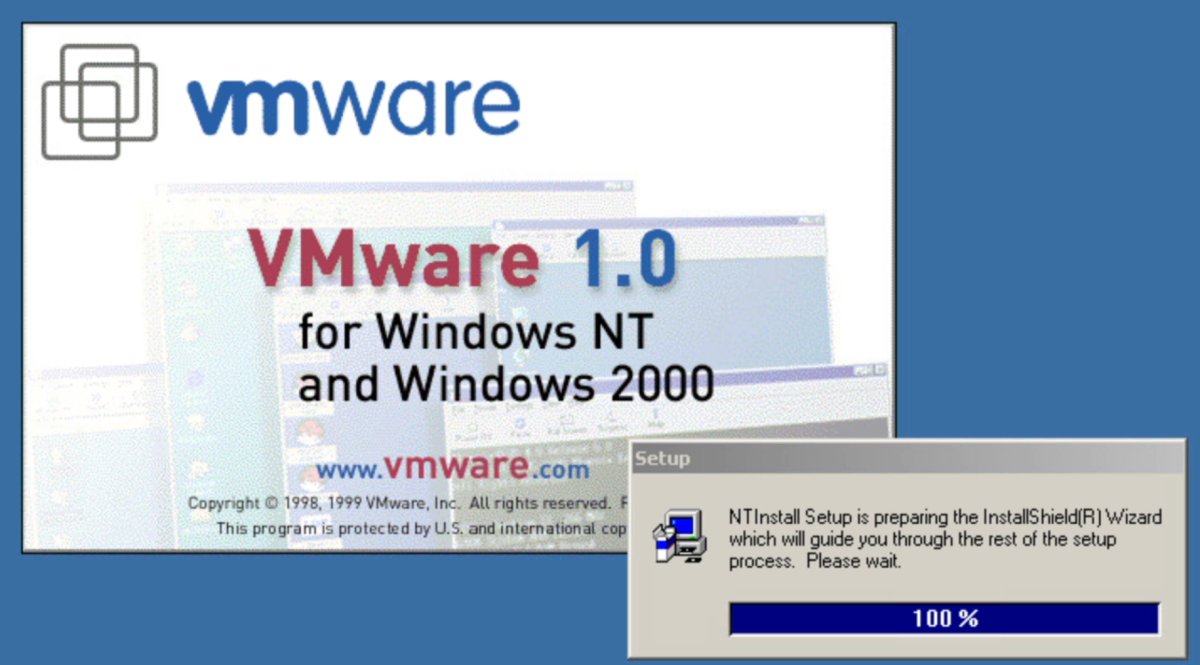
Launched 25 years ago this summer: VMware 1.0, the first commercial product that allowed users to run multiple operating systems as virtual machines on a single x86 machine.
Later known as VMware Workstation, it was an influential application that provided a framework for cloud compute instances and other infrastructure resources used in early cloud services.
#techhistory #cloudcomputing #bigdata
1
1
88