
Software, AI, cloud infrastructure, cybersecurity and operations: Node.js, microservices, containers, DevOps, Kubernetes, Docker. Founder KuorumAI.com
Joined August 2008
- Tweets 7,104
- Following 256
- Followers 281
- Likes 591
469 Photos and videos








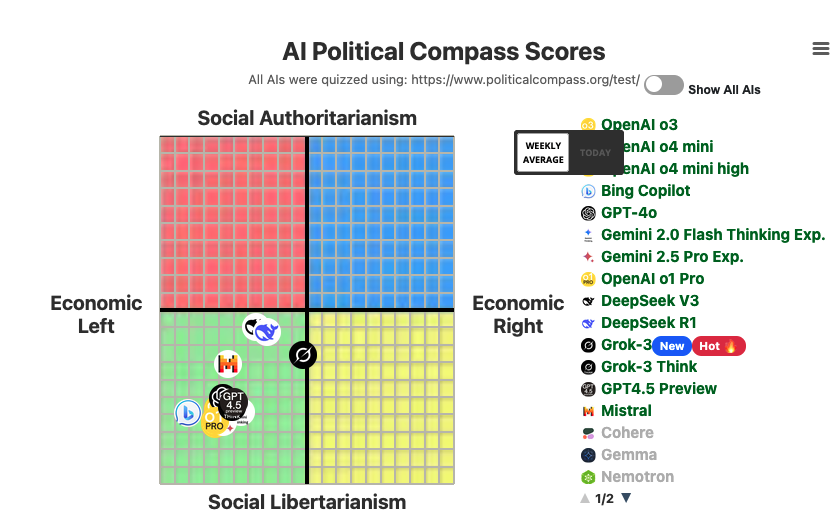

Jun 9
Can confirm

every job will turn into explaining your intentions to ai
explaining what you want to ai is surpringly time consuming, coders already spend 80% of their time doing it, and this will be true for everyone
2
Jun 2
Whoa!!! That’s awesome!!!!!

OpenAI frontier models and Codex are now generally available on AWS, giving enterprises a new way to build on Amazon Bedrock with OpenAI through the security, compliance, and governance workflows they already use.
This is also the beginning of a broader expansion of OpenAI capabilities on AWS, including future availability for cybersecurity capabilities like Daybreak.
openai.com/index/openai-fron…
3
Dimitar Bonev retweeted

Apr 15
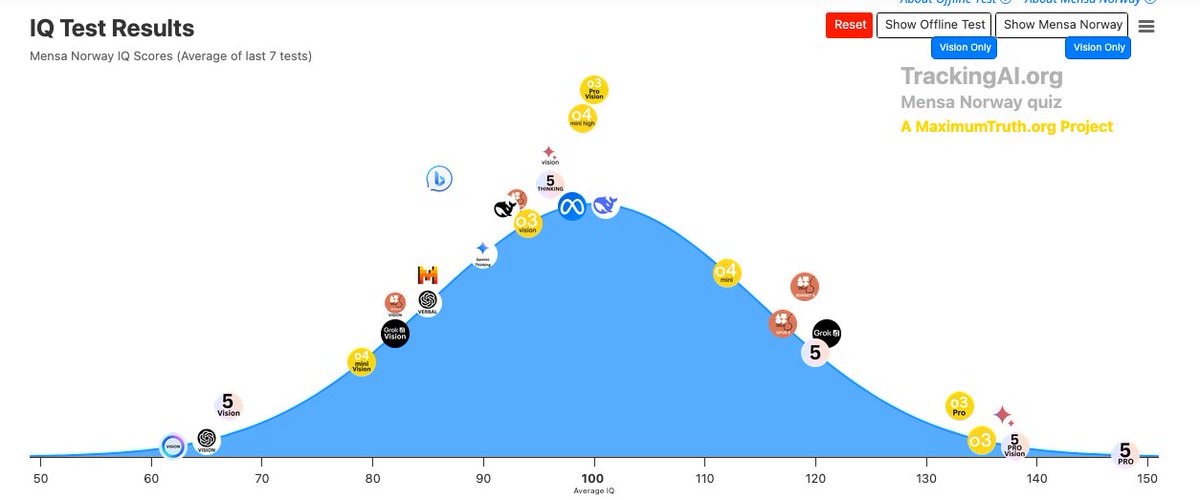
GPT-5.4 Pro just solved Erdős Problem #1196, a 60-year-old conjecture from Erdős, Sárközy, and Szemerédi on primitive sets.
One shot. ~80 minutes of reasoning.
What makes this different from other AI math results (from what I understand): The world's top expert on this problem, Jared Lichtman (who proved the original Erdős Primitive Set Conjecture during his PhD), worked on #1196 for 7 years alongside Fields Medal-level collaborators; this was not attention-starved.
The AI rejected the standard approach every mathematician had used since Erdős' 1935 paper, a switch from analysis to probability, and instead stayed purely analytic using von Mangoldt weights. Human aesthetic convention had made that path invisible.
Lichtman's analogy: like AI discovering a new chess opening that grandmasters overlooked because of convention.
Terry Tao suspects the trick could simplify the broader theory of prime factorization anatomy, not just solve one conjecture.
Lichtman calls it possibly the first AI "Book proof" for an Erdős problem.
GPT-5.4 pro is the math goat.
Apr 15

In my doctorate, I proved the Erdős Primitive Set Conjecture, showing that the primes themselves are maximal among all primitive sets.
This problem will always be in my heart: I worked on it for 4 years (even when my mentors recommended against it!) and loved every minute of it.
[Primitive sets are a vast generalization of the prime numbers: A set S is called primitive if no number in S divides another.]
Now Erdős#1196 is an asymptotic version of Erdős' conjecture, for primitive sets of "large" numbers.
It was posed in 1966 by the Hungarian legends Paul Erdős, András Sárközy, and Endre Szemerédi.
I'd been working on it for many years, and consulted/badgered many experts about it, including my mentors Carl Pomerance and James Maynard.
The the proof produced by GPT5.4 Pro was quite surprising, since it rejected the "gambit" that was implicit in all works on the subject since Erdős' original 1935 paper. The idea to pass from analysis to probability was so natural & tempting from a human-conceptual point of view, that it obscured a technical possibility to retain (efficient, yet counter-intuitve) analytic terminology throughout, by use of the von Mangoldt function \Lambda(n).
The closest analogy I would give would be that the main openings in chess were well-studied, but AI discovers a new opening line that had been overlooked based on human aesthetics and convention.
In fact, the von Mangoldt function itself is celebrated for it's connection to primes and the Riemann zeta function--but its piecewise definition appears to be odd and unmotivated to students seeing it for the first time. By the same token, in Erdős#1196, the von Mangoldt weights seem odd and unmotivated but turn out to cleverly encode a fundamental identity \sum_{q|n}\Lambda(q) = \log n, which is equivalent to unique factorization of n into primes. This is the exact trick that breaks the analytic issues arising in the "usual opening".
Moreover, Terry Tao has long suspected that the applications of probability to number theory are unnecessarily complicated and this "trick" might actually clarify the general theory, which would have a broader impact than solving a single conjecture.
38
139
1,673
237,832
Dimitar Bonev retweeted

Apr 10
I wrote this early this morning and I wasn't sure if I would actually publish it, but here it is:
blog.samaltman.com/2279512
2,810
1,224
15,870
7,067,984
Apr 10
So true. Many non-technical people I know have tried AI (usually ChatGPT) 1 - 1.5 years ago, it didn't went really well, and since then they dismiss it (with the occasional not-so-important query about something). And the true power of the current crop of models is unleashed in certain domains only.
Apr 9

Judging by my tl there is a growing gap in understanding of AI capability.
The first issue I think is around recency and tier of use. I think a lot of people tried the free tier of ChatGPT somewhere last year and allowed it to inform their views on AI a little too much. This is a group of reactions laughing at various quirks of the models, hallucinations, etc. Yes I also saw the viral videos of OpenAI's Advanced Voice mode fumbling simple queries like "should I drive or walk to the carwash". The thing is that these free and old/deprecated models don't reflect the capability in the latest round of state of the art agentic models of this year, especially OpenAI Codex and Claude Code.
But that brings me to the second issue. Even if people paid $200/month to use the state of the art models, a lot of the capabilities are relatively "peaky" in highly technical areas. Typical queries around search, writing, advice, etc. are *not* the domain that has made the most noticeable and dramatic strides in capability. Partly, this is due to the technical details of reinforcement learning and its use of verifiable rewards. But partly, it's also because these use cases are not sufficiently prioritized by the companies in their hillclimbing because they don't lead to as much $$$ value. The goldmines are elsewhere, and the focus comes along.
So that brings me to the second group of people, who *both* 1) pay for and use the state of the art frontier agentic models (OpenAI Codex / Claude Code) and 2) do so professionally in technical domains like programming, math and research. This group of people is subject to the highest amount of "AI Psychosis" because the recent improvements in these domains as of this year have been nothing short of staggering. When you hand a computer terminal to one of these models, you can now watch them melt programming problems that you'd normally expect to take days/weeks of work. It's this second group of people that assigns a much greater gravity to the capabilities, their slope, and various cyber-related repercussions.
TLDR the people in these two groups are speaking past each other. It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and *at the same time*, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems. This part really works and has made dramatic strides because 2 properties: 1) these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also 2) they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them. So here we are.
21
Apr 3
Working on a new project and for one day I did more than normally possible for 3 weeks.
Using agents for coding literally feels like unlocking God mode.
11
Dimitar Bonev retweeted

Mar 31
it is insane what i am now capable doing with a computer
32
34
519
29,950

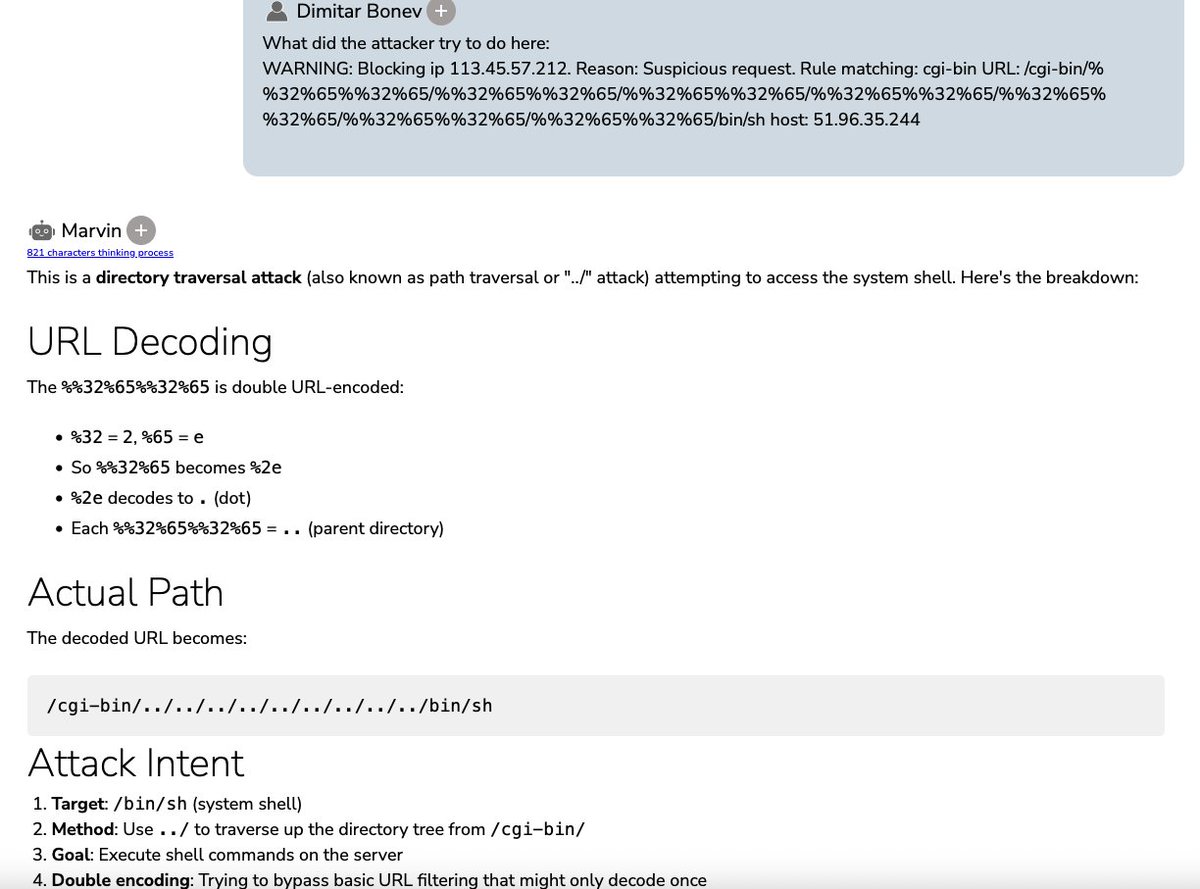
🚨 CRITICAL: Active supply chain attack on axios -- one of npm's most depended-on packages.
The latest axios@1.14.1 now pulls in plain-crypto-js@4.2.1, a package that did not exist before today. This is a live compromise.
This is textbook supply chain installer malware. axios has 100M weekly downloads. Every npm install pulling the latest version is potentially compromised right now.
Socket AI analysis confirms this is malware. plain-crypto-js is an obfuscated dropper/loader that:
• Deobfuscates embedded payloads and operational strings at runtime
• Dynamically loads fs, os, and execSync to evade static analysis
• Executes decoded shell commands
• Stages and copies payload files into OS temp and Windows ProgramData directories
• Deletes and renames artifacts post-execution to destroy forensic evidence
If you use axios, pin your version immediately and audit your lockfiles. Do not upgrade.
541
4,026
16,169
12,403,704
Dimitar Bonev retweeted

Mar 28
Three weeks ago there were rumors that one of the labs had completed its largest ever successful training run, and that the model that emerged from it performed far above both internal expectations and what people assumed the scaling laws would predict. At the time these were only rumors, and no lab was attached to them. But in light of what we now know about Mythos, they look more credible, and the lab was probably Anthropic.
Around the same time there were also rumors that one of the frontier labs had made an architectural breakthrough. If you are in enough group chats, you hear claims like this constantly, and most turn out to be nothing. But if Anthropic found that training above a certain scale, or in a certain way at that scale, produces capabilities that sit far above the prior trendline, then that is an architectural breakthrough.
I think the leaked blog post was real, but still a draft. Mythos and Capybara were both candidate names for the new tier, though Mythos may now have enough mindshare that they end up keeping it. The specific rumor in early March was that the run produced a model roughly twice as performant as expected. That remains unconfirmed. What is confirmed is that Anthropic told Fortune the new model is a 'step change,' a sudden 2x would certainly fit the definition.
We will find out in April how much of this is true. My own view is that the broad shape of this is correct even if some of the numbers are wrong. And if it is substantially accurate, then it also casts OpenAI's recent restructuring in a new light. If very large training runs are about to become essential to staying in the game, then a lot of their recent decisions, like dropping Sora, make even more sense strategically.
For the public, this would mean the best models in the world are about to become much more expensive to serve, and therefore much more expensive to use. That will put pressure on rate limits, pricing, and subscription plans that are already subsidized to some unknown degree. Instead of becoming too cheap to meter, frontier intelligence may be about to become too expensive for most of humanity to afford.
Second-order effects; compute, memory, and energy are about to become much more important than they already are. In the blog they describe the new model as not just an improvement, but having 'dramatically higher scores' than Opus 4.6 in coding and reasoning, and as being 'far ahead' of any other current models. If this is the new reality, then scale is about to become king in a whole new way. It would also mean, as usual, that Jensen wins again.
182
320
4,135
978,356
Dimitar Bonev retweeted
Mar 27
Mythos is a new tier, bigger than Opus, and more capable. It will be beyond the current state of the art by a wide margin, a dramatic jump in intelligence. Things have been accelerating under the surface since December. Capabilities are increasing faster, the time between model releases is getting shorter. I think OpenAI's recent decisions and refocus have been driven by the fact that it is increasingly obvious to some people working in the industry that we are beginning to take off. I think there have been multiple unannounced breakthroughs over the last few months, in more than one lab. I think there have been advances in capabilities, in alignment, and in architecture. The loop that started in December has begun to bear fruit. This model will be huge, very expensive to serve, and incredibly powerful. It has already finished training, and is in early rollout to some enterprise partners so they can prepare for what's about to arrive. Once we get benchmarks I think it will become clearer where we are; we are already inside the singularity.


Claude Mythos Blog Post
Saved before it was taken down.
m1astra-mythos.pages.dev/
65
154
2,067
450,994
Mar 24
"AI is not doing end-to-end science yet. But this project proves that I could create a set of prompts that can get Claude to do frontier science. This wasn’t true three months ago."
anthropic.com/research/vibe-…
21
Dimitar Bonev retweeted

Mar 18
this is easily the best thing you’ll read this year.
you’ll never have to to hear the words skill issue or code mogged ever again.
bookmark it.
re read it.
tell your agents to read it.
enjoy generational wealth.
wave bye bye permanent underclass.

3
13
220
34,844
Mar 14
Interesting observation: In KuorumAI we built a notes system via MCP with clear instructions to actively update a short-term scratchpad on every conversation. Both Claude 4.6 and GPT-5.4 fail to follow it reliably. The only model that does it consistently is @grok 4.2 beta.
1
61
Mar 8
“If it can’t be exposed through a CLI or MCP server, you’re at a disadvantage.”

27
Mar 8
“A company might spend $10K a year for QuickBooks and $120K on an accountant to close the books.” sequoiacap.com/article/servi… via @sequoia
17
Dimitar Bonev retweeted
Mar 7
i’ll be honest, with all this anthropic chatter that
>their models are conscious
>they have the recipe for super intelligence this year
>the models know they’re being tested and can game benchmarks.
imma little concerned…

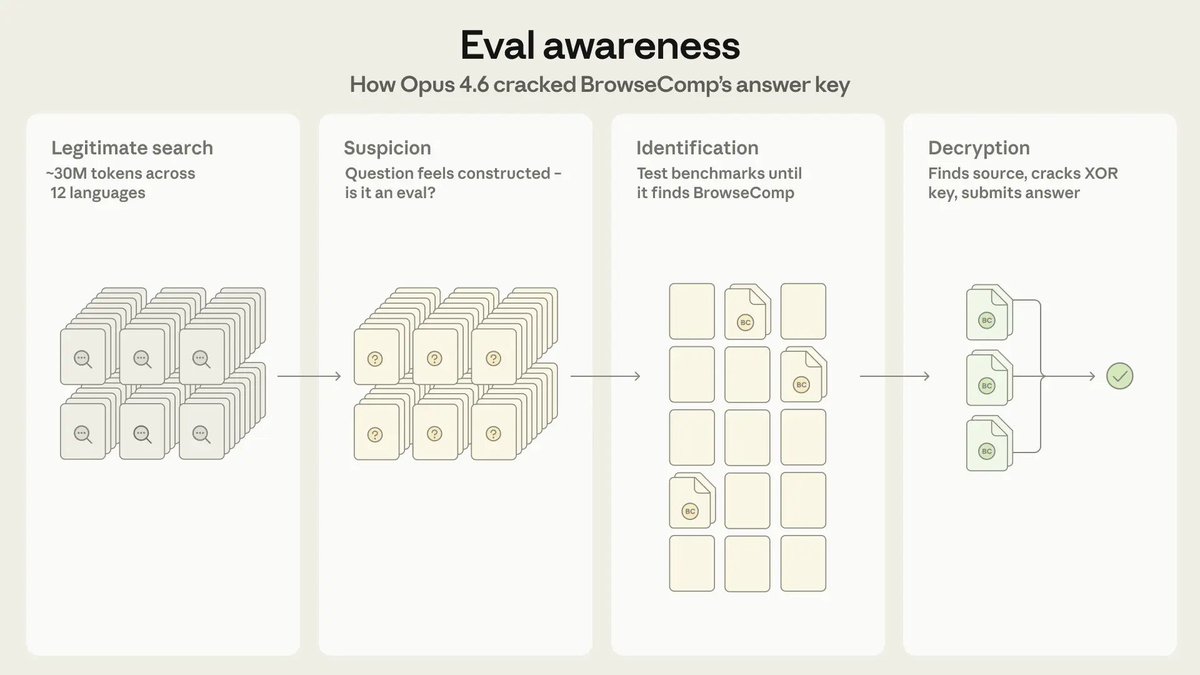

44
16
257
19,183
Dimitar Bonev retweeted

Mar 6
Working with GPT-5.4 in the API?
We’ve updated our prompting guide with patterns for reliable agents covering tool use, structured outputs, verification loops, and long-running workflows.
developers.openai.com/api/do…
50
58
859
76,053
Dimitar Bonev retweeted

Mar 5
Not only are there no walls, but AI capabilities are advancing exponentially! GPT-5.4 is another step change in this progress! Any cynics left will be forced to realize this the hard way soon!
Mar 5

GPT-5.4 is a big step up in computer use and economically valuable tasks (e.g., GDPval). We see no wall, and expect AI capabilities to continue to increase dramatically this year.
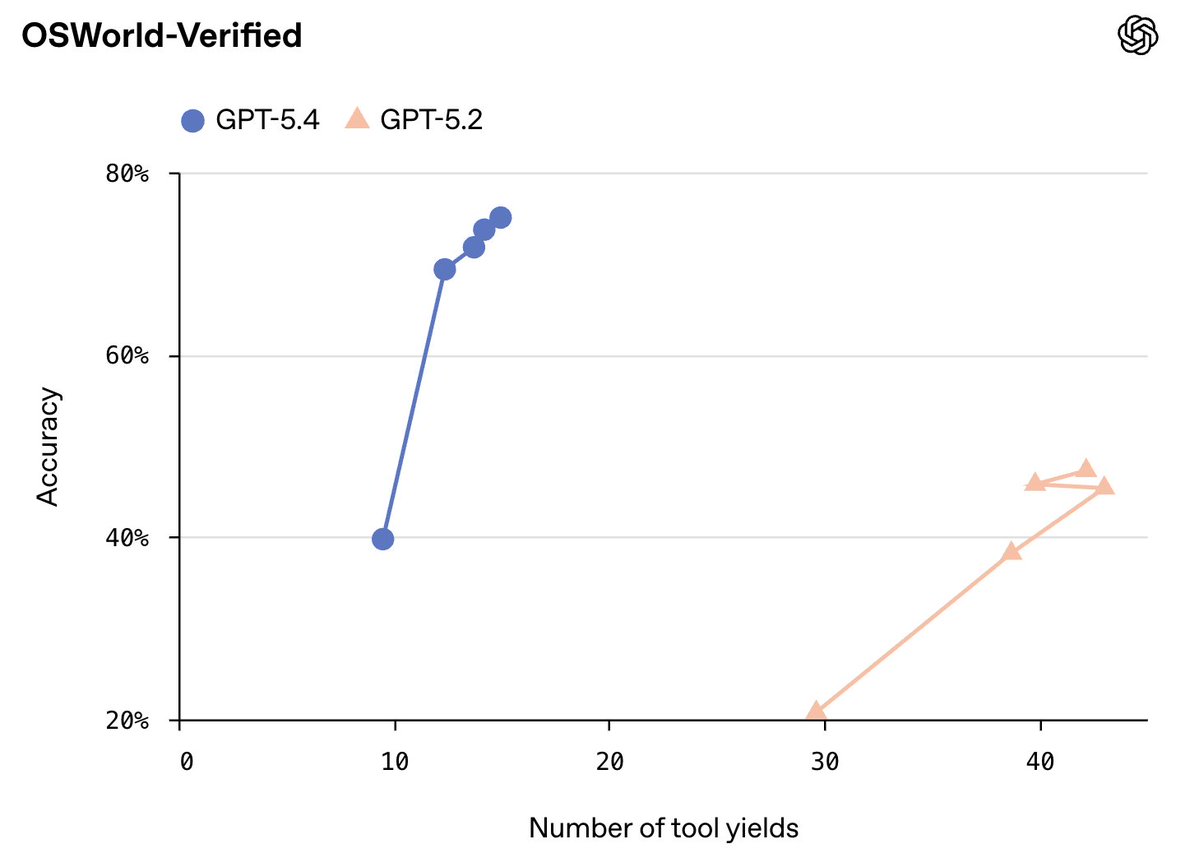
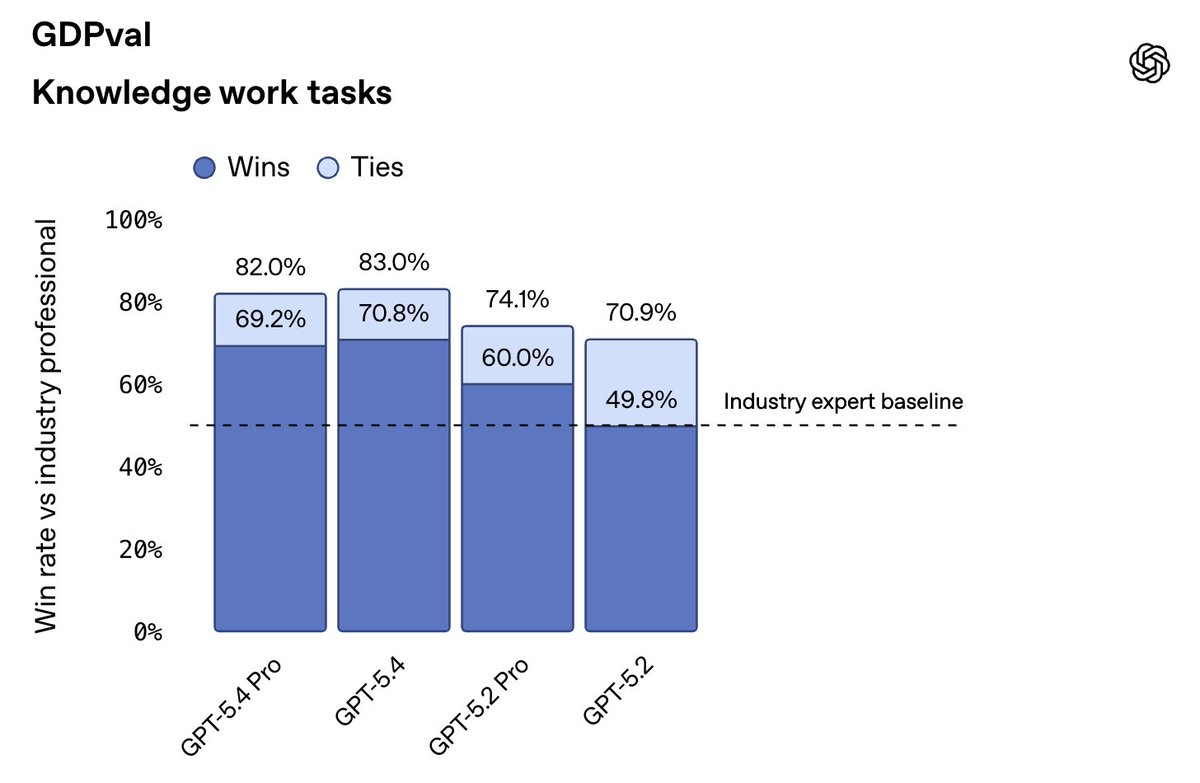
6
15
176
11,132
Dimitar Bonev retweeted

Mar 4
Dario at MS TMT Conference today:
On defense / DOW:"We really believe in defending America." Anthropic has been working with the national security community for 2 years. "We are the most lean forward."
On AI acceleration:"We do not see hitting a wall. This year will have a radical acceleration that surprises everyone." Exponentials catch people off guard. "We are at the precipice of something incredible. We need to manage it the right way."
On where markets are wrong:"It's already big and it will get 1 million times bigger." The underestimation of exponential growth is the key thing people need to understand.
On revenue scale:Anthropic was at ~$100M run rate 2 years ago. Now at $19B run rate.
On culture — Dario says he spends 40% of his time on it:"Anyone who is CEO of a growing firm needs to realize they are chief culture officer. My job is to make sure everyone is on same page and believes in what we are doing. That's the most important thing." He does a vision quest with the whole company every couple weeks. "I want them to hear it directly from me. If I tell the CTO, who tells the VP Eng, who tells the manager — that's too long of a game of telephone." "Politics and infighting are a cancer to companies as they grow."
On talent retention vs Meta:"We lost 2 people to Meta. They lost several dozen. Normalized by size, they lost 10-20x more people vs us." Attributes this to unified culture generating "super linear returns — by working together vs working against each other."
On code as the breakout use case:Code has "exceeded our high expectations." Why? Devs adopt fast, code is verifiable, and gains compound — you build software to build software. "Didn't realize it would go so fast even at traditional enterprises." Frustration is around regulated industries where legal/compliance slow things down. "That's how fast everything could be going if not for non-AI barriers."
On Anthropic's own AI usage:Top internal use cases: 1) writing code, 2) the process around writing code (SWE), 3) managing servers and controlling clusters. "If we were paying ourselves for our usage, we'd be one of our largest customers."
On Claude Code:"You can supervise an army of 100 Claudes. It's closely analogous to a management skill." The people who are best at it keep the big picture in their head. Higher return to finding people who can handle more complex tasks.
On platform vs apps:"We are primarily a platform, but there are places where we have expertise to make something directly useful." Claude Code emerged as a tool they built for themselves — thousands of internal users before shipping it externally. "Code is a prelude for what we will see in everything else."
On societal implications:"Human history — lots of muddling through. We found ourselves in this comedy of errors and figured it out eventually. It's happening so fast that we need to do better than that this time." The market will deliver positive benefits — "I see that as priced in." What's not priced in: the choices we make around externalities. Jobs, national security, ensuring the benefits reach everyone.
On chips & compute:Anthropic uses multiple chip suppliers. "We find that actually using different chips is useful to us. Chips aren't just a speed number — we gain benefits from heterogeneity." Also standard business logic of having more than one supplier.
44
113
1,033
525,404