
he teaches data science at Cornell
Joined June 2009
- Tweets 2,380
- Following 2,059
- Followers 4,828
- Likes 7,264
73 Photos and videos











Pinned Tweet

5 Jan 2018
Optimist: AI has achieved human-level performance!
Realist: “AI” is a collection of brittle hacks that, under very specific circumstances, mimic the surface appearance of intelligence.
Pessimist: AI has achieved human-level performance.
75
3,432
9,209


1 Oct 2024
This is big. Nvidia is probably ahead a generation on chips, but CUDA is the moat
1 Oct 2024

Now you can use bitsandbytes on AMD GPUs and Intel hardware. This is a big milestone and was a huge undertaking. @Titus_vK did an amazing job here. Eager to hear feedback! Let us know how it works for you.
6
863
David Mimno retweeted

27 Sep 2024
If for whatever reason you can't make it to COLM, please send me an email, and we will give you a refund.
There are a lot of people who would really like to come.
1
7
57
16,088
David Mimno retweeted

25 Sep 2024
Fantastic opportunity for undergrads interested in research! I've been lucky to host and collaborate with several amazing interns through this program. Deadline 10/21. Help spread the word! 📢📢📢
25 Sep 2024

Our Undergraduate Research Internship Program is now accepting applications for summer research internships. Rising college juniors & seniors who are passionate about technology and champion diversity and inclusion are encouraged to apply by 10/21: msft.it/6017meOVF

ALT Young woman sharing her view during team building session at startup office. African woman talking with colleagues sitting in circle at a coworking office.
10
18
4,921
26 Sep 2024
Still relevant
22 Nov 2023

The OpenAI drama feels like what would happen if a Sociology department accidentally became a Fortune 500 company
10
967
25 Sep 2024
More evidence Tech companies’ spending on GPUs and electricity is crowding out hiring. Hardware vs HR. H100s will become e-waste, interns will become CEOs.

Last week, the WSJ reported on the decline of tech jobs, particularly entry-level and recruiting roles, suggesting they might be gone for good. I initially thought it was exaggerated, but then saw a UC Berkeley CS professor mention that even his top students are struggling to get job offers. That’s concerning. My kid is far from college, but I’m curious—how are parents of high schoolers approaching career guidance for their kids in light of this?
2
6
1,666
David Mimno retweeted

24 Sep 2024
The early 🦜 gets the 🪱
@JHUCompSci has a great opportunity for faculty hiring. Apply early and you couls interview early and 🤞get an early offer.
Spreading out interviews and having an early offer = less stressful job search.
5 Sep 2024

🚨 Johns Hopkins @JHUCompSci is hiring faculty at all ranks! 1) Data Science and AI 🤖; 2) All other areas of CS 💻. We will double in size to become one of the largest departments in the coming years! 🚀
Note: early action and spousal placement. 👥 🧵
apply.interfolio.com/153420
2
19
61
15,962
David Mimno retweeted

24 Sep 2024
We're hiring at @UW_iSchool! 🦭🗻🏙️ Come join us in Seattle
2 x tenure-track Assistant Prof in Informatics: apply.interfolio.com/150031
1 x tenure-track Assistant Prof in LIS: apply.interfolio.com/150038
1 x teaching-track Assistant Prof in LIS: apply.interfolio.com/150033
Happy to chat!
2
29
92
12,191
David Mimno retweeted

24 Sep 2024
Debates in #DH Computational Humanities is now available for purchase (OA @ManifoldScholar this winter)! Thank you to the amazing contributors, co-editors extraordinaire @jmjafrx @dmimno , the team @UMinnPress , and series editors @laurenfklein @mkgold ! 👇🏼

ALT The cover of the book. Says computational humanities.
4
88
259
22,231
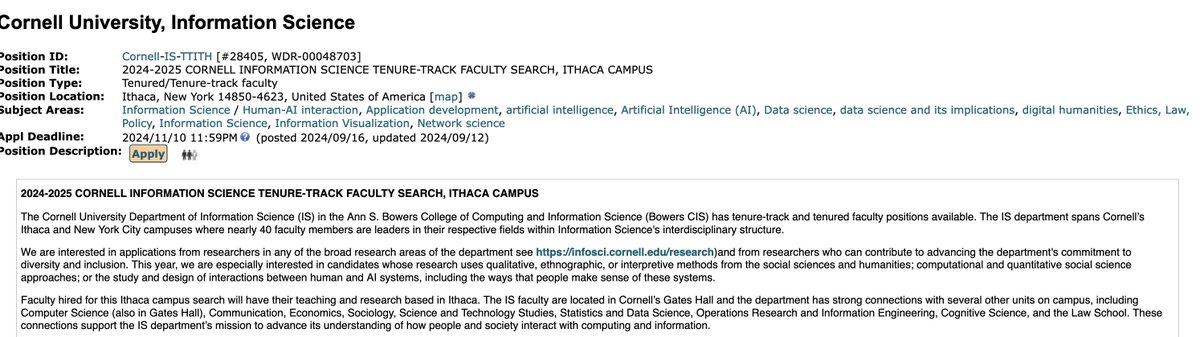
David Mimno retweeted

Department of Information Science at Cornell; open rank faculty search. Field is open and there is a special emphasis in a few areas including computational social science. Application review begins Nov 10. academicjobsonline.org/ajo/j…
1
31
55
13,060
David Mimno retweeted

19 Sep 2024
We are hiring at @CornellInfoSci ! Open rank: academicjobsonline.org/ajo/j… Cornell is a fantastic place to work, please consider applying and sharing this opportunity.
2
30
84
14,440
9 Sep 2024
I have a very particular set of skills. Skills that I have developed over a long career. Skills that make me a nightmare for 11-page pdfs like you. If you go down to 8 pages now, that will be the end of it.
3
27
2,216
8 Sep 2024
Open “source” is a relic of the 90s era separation between code and executable. Retrofitting it is hopeless. The Creative Commons license family is a better model: describe aspects like open weights, protocol, data with succinct codes.
6 Sep 2024

Thoughts on OSI’s *draft* open-source AI definition v0.0.9: Key question: how much information about the data needs to be disclosed to get the open-source stamp? My initial reaction was that the entire dataset must be released, but now I think this is neither sufficient nor necessary.
1
1
15
1,909

Truly excited to be featured in this @NorthwesternEng article! Shoutout to many at @NU_IEMS and @NICOatNU who've been part of the journey

We are proud to share this article, @yian_yin (PhD ’22), who has accomplished plenty since earning his PhD in 2022 from IEMS at @NorthwesternEng. He was listed in @Forbes 2024 ’30 Under 30’ in the science category. tinyurl.com/tt7j4yvy

2
34
1,495
3 Sep 2024
PSA: if you assign python notebooks for homework, you CANNOT allow students to use Google colab anymore, it reads instructions and autosuggests good answers.
I’m trying “You’ve earned the right not to play on easy mode”, but the temptation to just say “that looks good” is there
4
8
51
10,837
31 Jul 2024
What I love about these is that I have spent so much time reading equations in papers and textbooks just trying to answer “what does it actually do”, and these just make it unmistakably obvious
31 Jul 2024

[Backpropagation] by Hand✍️
[1] Forward Pass
↳ Given a multi layer perceptron (3 levels), an input vector X, predictions Y^{Pred} = [0.5, 0.5, 0], and ground truth label Y^{Target} = [0, 1, 0].
[2] Backpropagation
↳ Insert cells to hold our calculations.
[3] Layer 3 - Softmax (blue)
↳ Calculate ∂L / ∂z3 directly using the simple equation: Y^{Pred} - Y^{Target} = [0.5, -0.5, 0].
↳ This simple equation is the benefit of using Softmax and Cross Entropy Loss together.
[4] Layer 3 - Weights (orange) & Biases (black)
↳ Calculate ∂L / ∂W3 and ∂L / ∂b3 by multiplying ∂L / ∂z3 and [ a2 | 1 ].
[5] Layer 2 - Activations (green)
↳ Calculate ∂L / ∂a2 by multiplying ∂L / ∂z3 and W3.
[6] Layer 2 - ReLU (blue)
↳ Calculate ∂L / ∂z2 by multiplying ∂L / ∂a2 with 1 for positive values and 0 otherwise.
[7] Layer 2 - Weights (orange) & Biases (black)
↳ Calculate ∂L / ∂W2 and ∂L / ∂b2 by multiplying ∂L / ∂z2 and [ a1 | 1 ].
[8] Layer 1 - Activations (green)
↳ Calculate ∂L / ∂a1 by multiplying ∂L / ∂z2 and W2.
[9] Layer 1 - ReLU (blue)
↳ Calculate ∂L / ∂z1 by multiplying ∂L / ∂a1 with 1 for positive values and 0 otherwise.
[10] Layer 1 - Weights (orange) & Biases (black)
↳ Calculate ∂L / ∂W1 and ∂L / ∂b1 by multiplying ∂L / ∂z1 and [ x | 1 ].
[11] Gradient Descent
↳ Update weights and biases (typically a learning rate is applied here).
💡 Matrix Multiplication is All You Need: Just like in the forward pass, backpropagation is all about matrix multiplications. You can definitely do everything by hand as I demonstrated in this exercise, albeit slow and imperfect. This is why GPU's ability to multiply matrices efficiently plays such an important role in the deep learning evolution. This is why NVIDIA is now close to $1 trillion in valuation.
💡Exploding Gradients: We can already see the gradients are getting larger as we back-propagate up, even in this simple 3-layer network. This motivates using methods like skip connections to handle exploding (or diminishing) gradients as in the ResNet.
I did the calculations entirely by hand. Please let me know if you spot any error or have any questions!
17
1,663
David Mimno retweeted

31 Jul 2024
This is huge: Reddit4researchers just opened a beta program! If you are interested about Reddit, apply to gain cool API access!
reddit.com/r/reddit4research…
2
41
132
17,509
27 Jul 2024
Can we all remind ourselves that the point of this is to learn about neural network training, and that using a billion flops to badly simulate what is literally one (1) flop is an insane idea? I feel like this gets lost
26 Jul 2024

learned something super interesting this week
if you train GPT-2 to multiply, you can't even train it to multiply 4-digit numbers (30% accuracy)
but if you use a really clever (and somewhat complex) training scheme, GPT-2 can generalize up to 20-digit numbers (100% accuracy)
it turns out that the reason GPT-2 couldn't multiply four-digit numbers wasn't too few layers, too small of a hidden dimension, or bad training data. all that was fine. the learning algorithm itself was the issue
the better model was built with a clever trick on regular training -- first using chain-of-thought, then progressively removing tokens as the model learns to solve problems in fewer and fewer steps
what this tells me is that our standard model-training is suboptimal (supervised learning SGD Adam)
these experiments come from this paper: From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step. it's only a couple months old
and while implicit CoT is super cool, its insights are much more general: this is proof that our current way of doing optimization is not the best
there's clearly a better learning algorithm out there
2
26
5,365
25 Jul 2024
A large portion of the code for Perseus 4 could legally purchase alcohol
23 Jul 2024

Problems with Perseus 4 and work towards Perseus 6 » Perseus Digital Library Updates sites.tufts.edu/perseusupdat… via @PerseusDigLib
4
775