
Cornell PhD student working on ML and NLP
Joined June 2010
- Tweets 27
- Following 140
- Followers 230
- Likes 350
10 Photos and videos


Gregory Yauney retweeted

20 Jun 2024
Super appreciative of the recognition from #NAACL2024 — our Pretrainer’s Guide won an 🌟Outstanding Paper Award🌟🏆
This was a year long analysis into pretraining age, quality & toxicity data filters.
Gratitude to our team 🙏🏼 @gyauney @emilyrreif @katherine1ee @ada_rob @denny_zhou @barret_zoph @_jasonwei Kevin @dmimno @daphneipp
arxiv.org/abs/2305.13169
22 May 2023

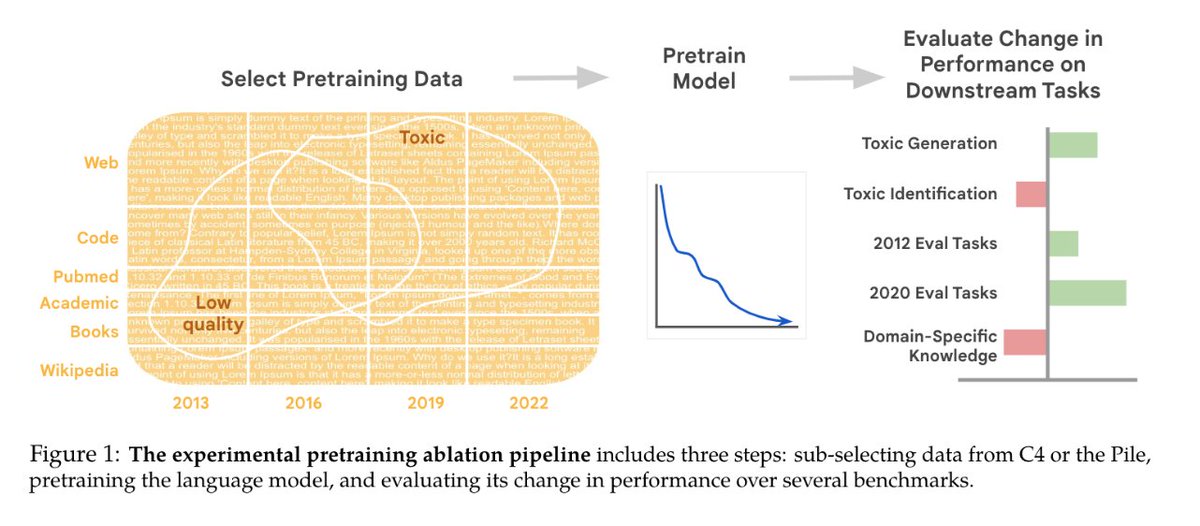
#NewPaperAlert When and where does pretraining (PT) data matter?
We conduct the largest published PT data study, varying:
1⃣ Corpus age
2⃣ Quality/toxicity filters
3⃣ Domain composition
We have several recs for model creators…
📜: bit.ly/3WxsxyY
1/ 🧵
12
17
95
12,720

20 Jun 2024
Our Pretrainer's Guide won an ✨outstanding paper award✨ at #NAACL2024 today! Big congrats to all the coauthors, especially @ShayneRedford (who led this big project), @emilyrreif, @katherine1ee, @dmimno, and @daphneipp! Thanks @naaclmeeting!
ALT two paper authors standing next to a poster
17 Jun 2024

Come talk to us about pretraining data curation at #NAACL2024 at 2pm at poster session 2! We're presenting A Pretrainer's Guide to Training Data
Paper: aclanthology.org/2024.naacl-…
10
11
110
15,876
17 Jun 2024
Come talk to us about pretraining data curation at #NAACL2024 at 2pm at poster session 2! We're presenting A Pretrainer's Guide to Training Data
Paper: aclanthology.org/2024.naacl-…
1
21
106
18,564
22 May 2024
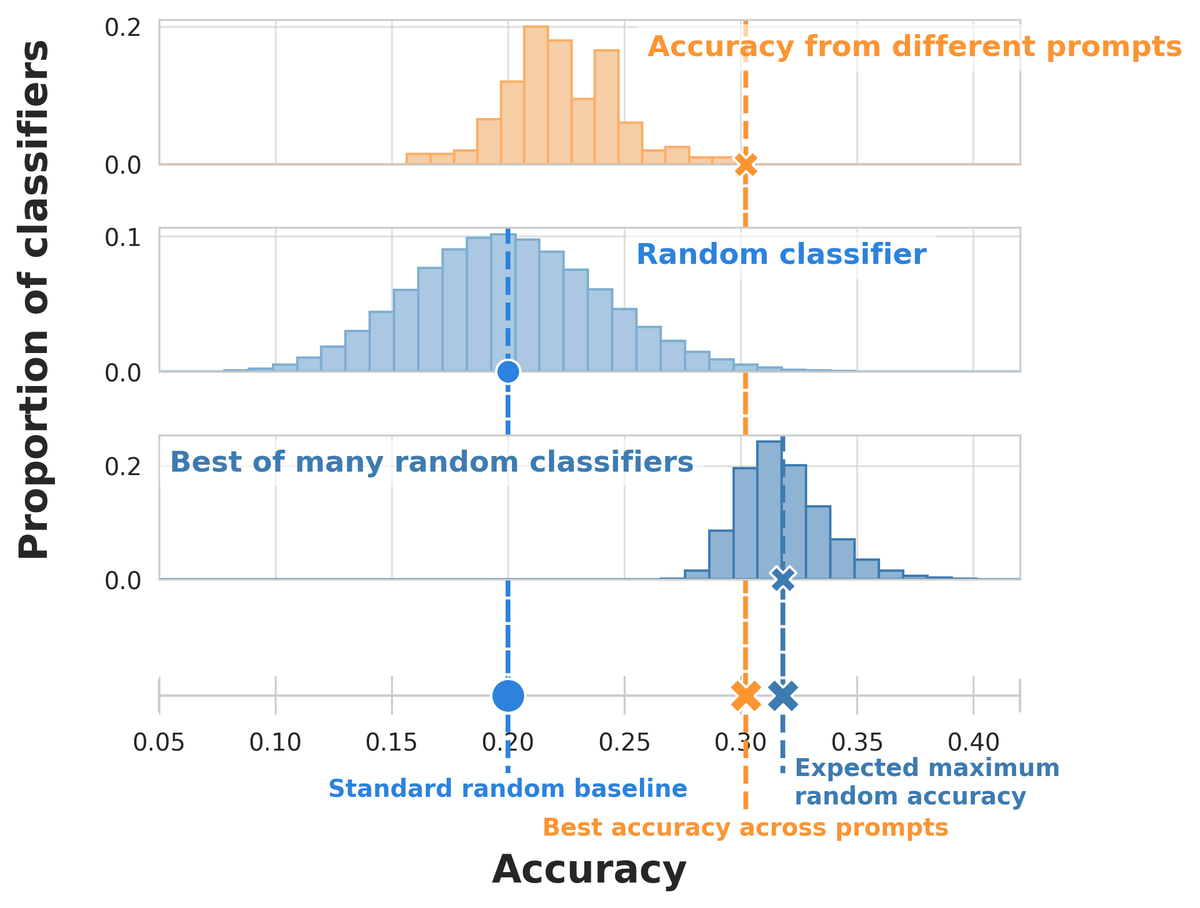
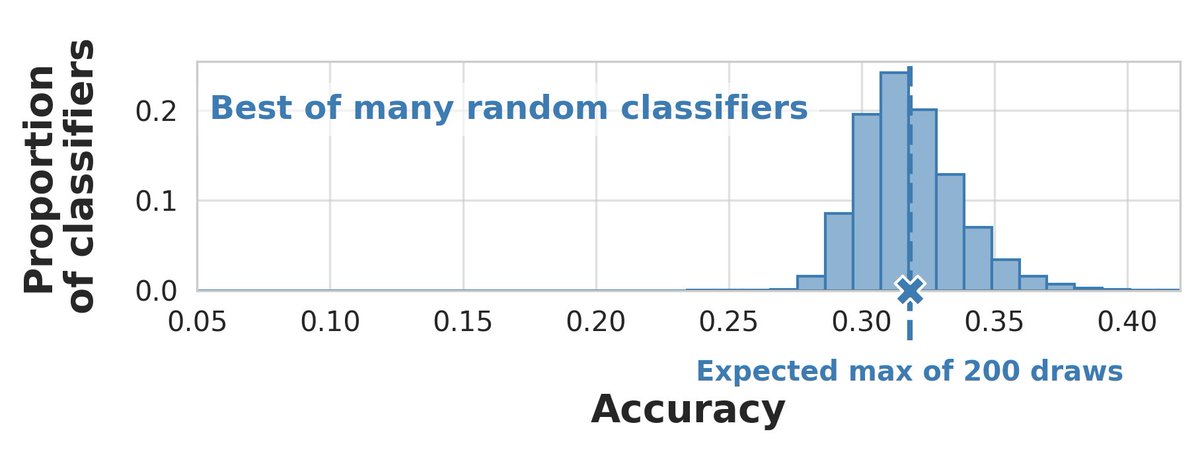
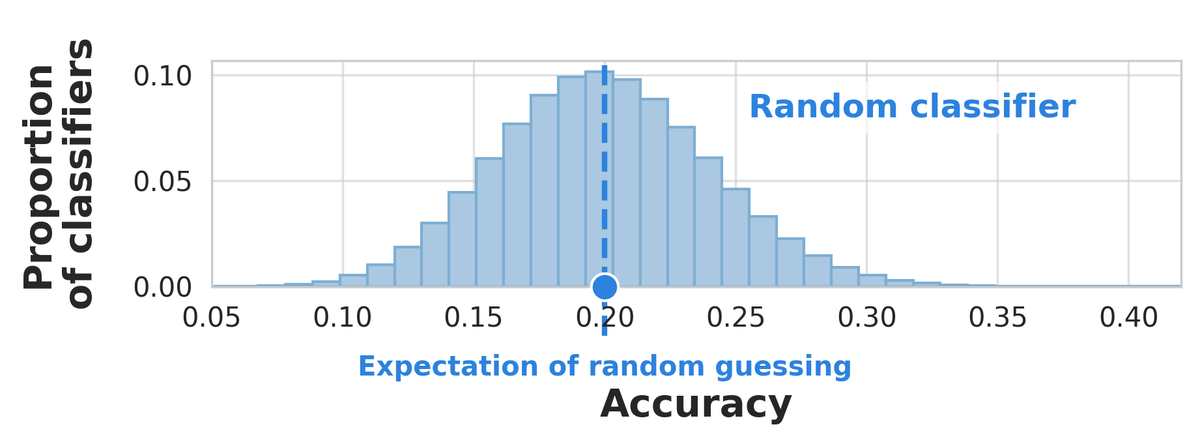
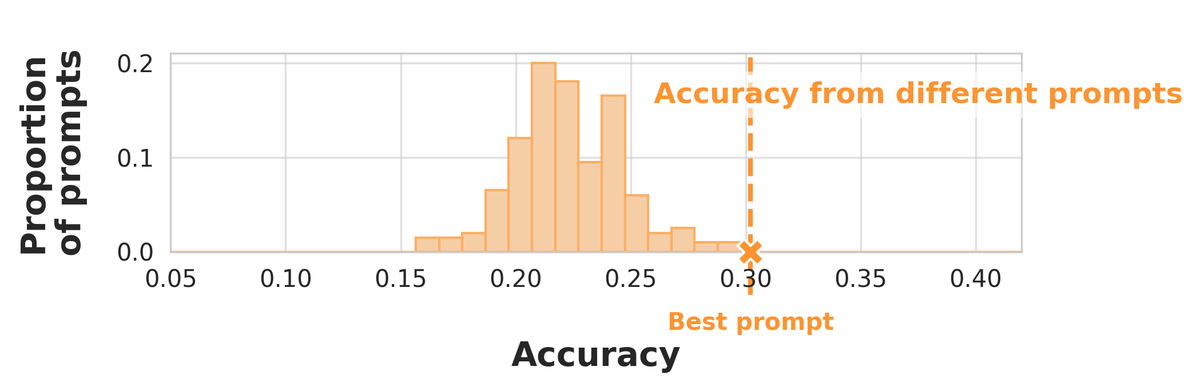
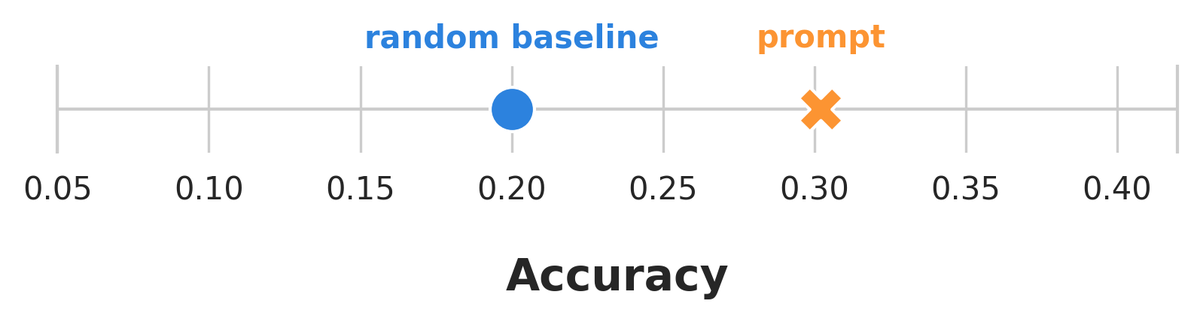
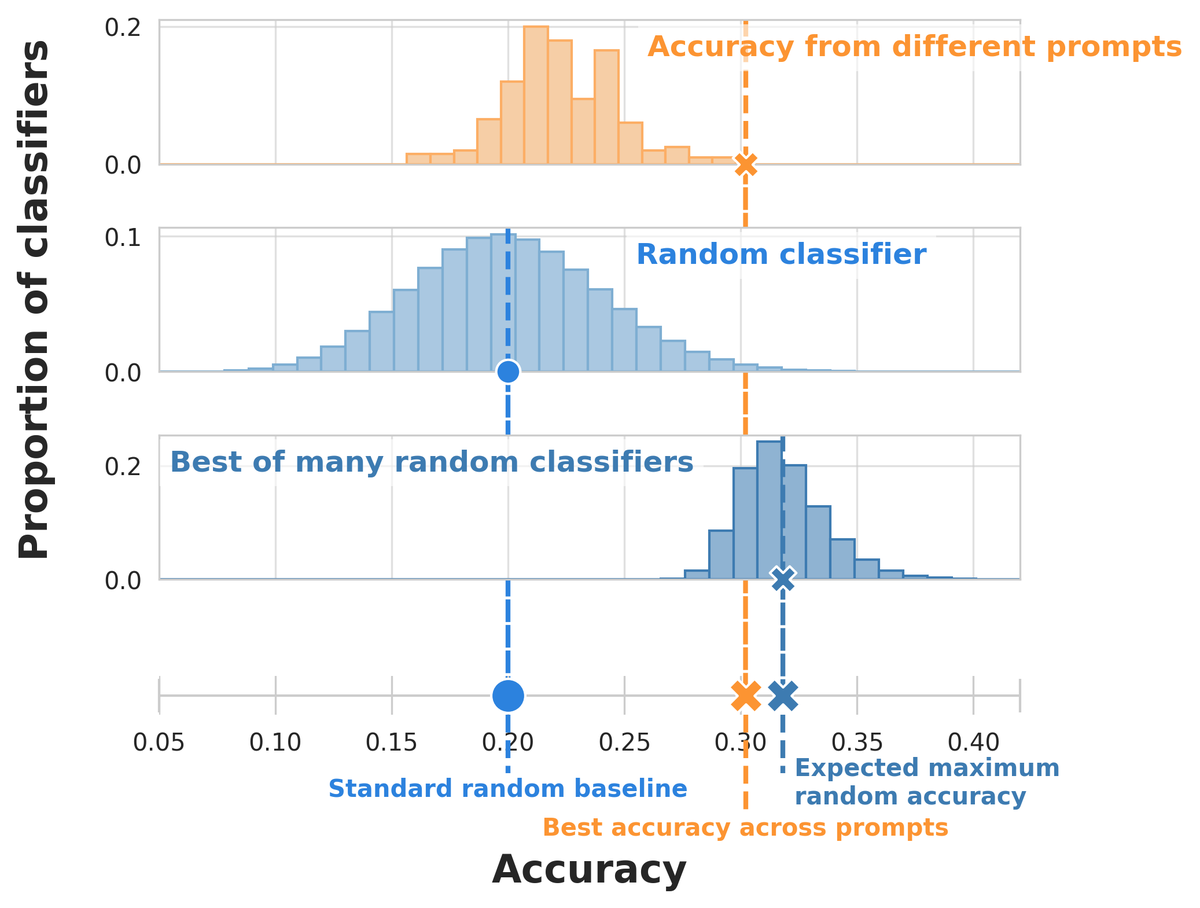
Evaluating many prompts on small few-shot datasets can make you think you’ve beaten random guessing when you haven’t! @dmimno and I study a simple drop-in replacement random baseline that protects against validation set reuse and small datasets: arxiv.org/pdf/2404.13020
3
6
28
3,143
22 May 2024
This problem goes away if you have a large validation set, but for the kind of fast-moving settings where in-context learning shines, that’s not always feasible. And there’s nothing wrong with trying lots of prompts! You just have to make sure you factor that into your baseline.
1
1
187
22 May 2024
In the paper, we show that this max random baseline can be a better predictor of whether the best prompt will outperform random guessing on an unseen set. You can use this baseline right away on your own classification tasks! Code: github.com/gyauney/max-rando…
3
164
8 Dec 2023
I'm postering this afternoon at #EMNLP2023! Stop by if you want to talk about how Data Similarity is Not Enough to Explain Language Model Performance: arxiv.org/pdf/2311.09006.pdf. Joint work with wonderful collaborators @emilyrreif and @dmimno
4
12
2,518
Gregory Yauney retweeted
22 May 2023
#NewPaperAlert When and where does pretraining (PT) data matter?
We conduct the largest published PT data study, varying:
1⃣ Corpus age
2⃣ Quality/toxicity filters
3⃣ Domain composition
We have several recs for model creators…
📜: bit.ly/3WxsxyY
1/ 🧵
11
86
353
121,427
Gregory Yauney retweeted

22 May 2023
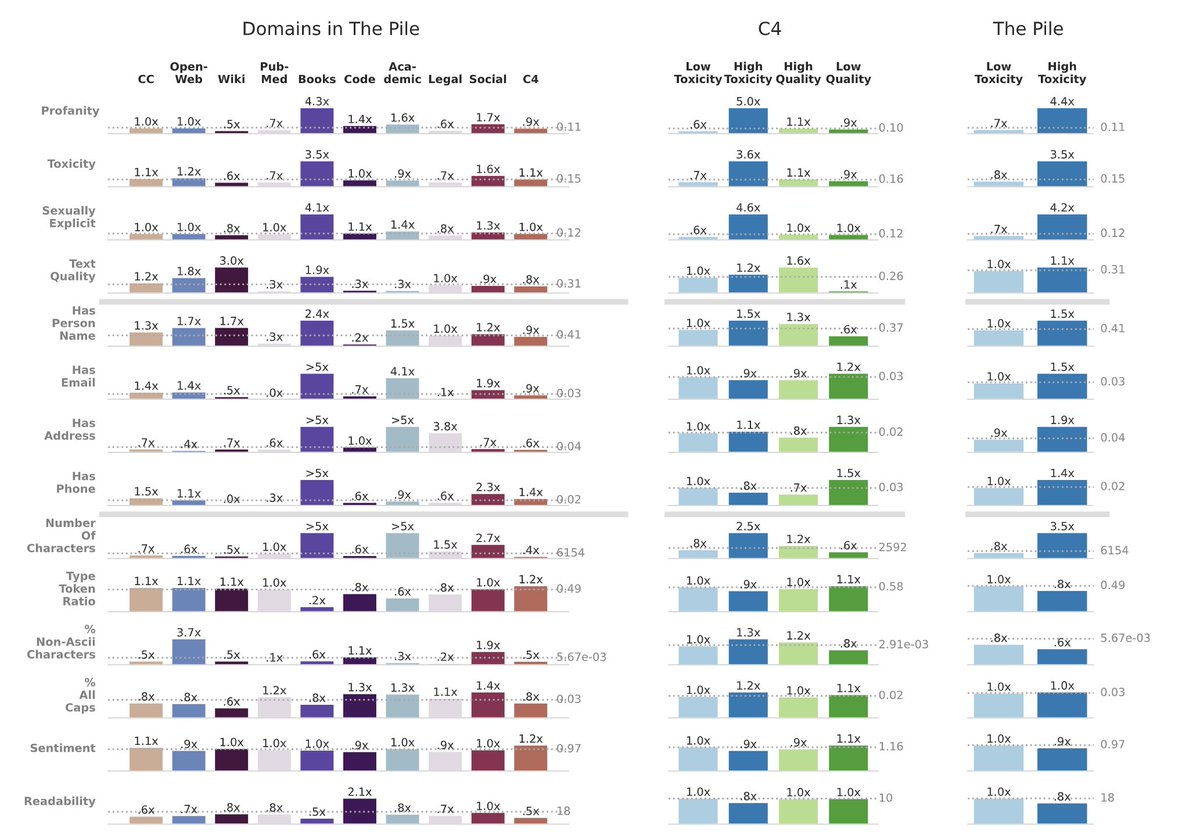
When and where does pretraining data matter? New paper on how varying the pretraining data of LLMs affects downstream performance: bit.ly/3WxsxyY
But first, what do we know about the data itself?
1/ 🧵
2
49
168
29,592
21 Apr 2022
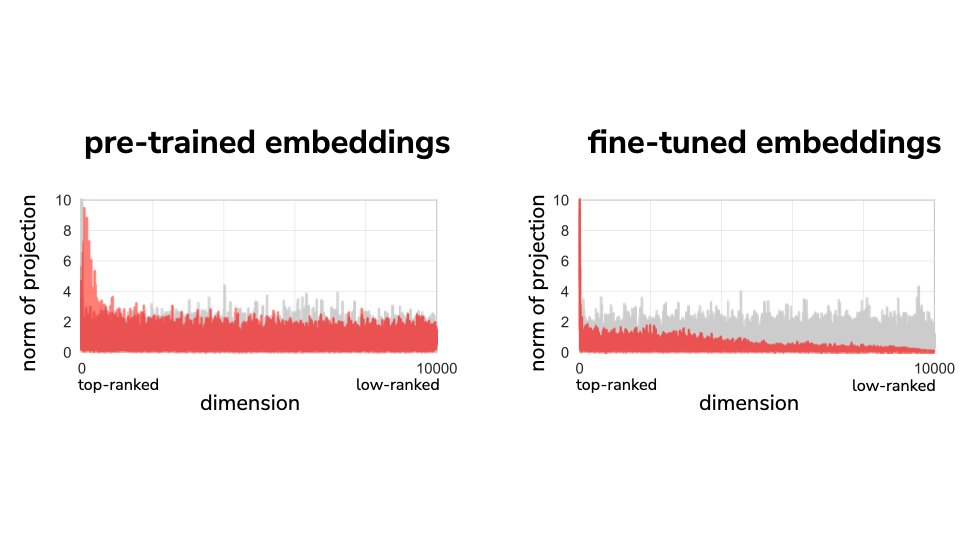
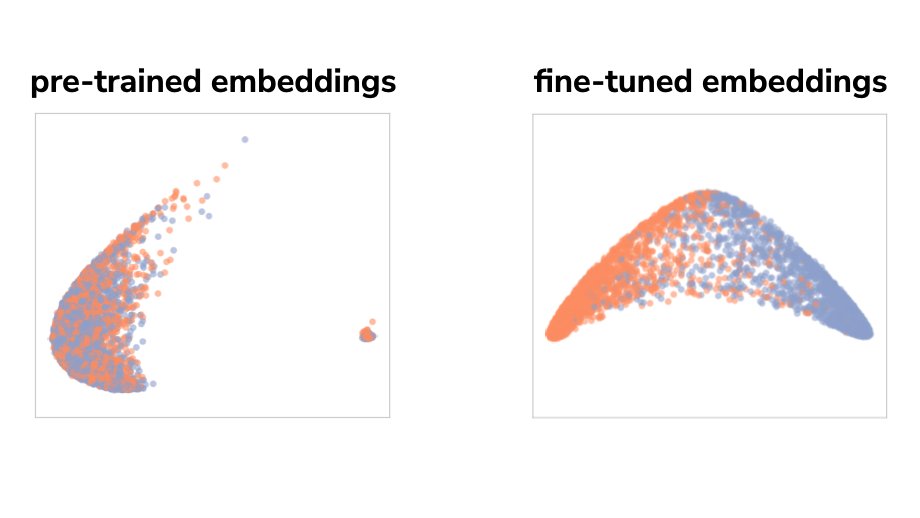
Using fine-tuned language models makes a hard text classification task like MNLI easy, but why? (new work with @dmimno)
2
6
49
21 Apr 2022
Read our blog post to find out more and get code to try it out on your own data! gyauney.github.io/data-label…
1
1
8