
founder @Intelluron | @Penn PhD, CFA | ex-Credit Suisse, Lehman, BNP, @VanderbiltU, Citi, Digital Reasoning (acquired) | @creativedlab, @taiwangoldcard alum
Joined October 2008
- Tweets 2,556
- Following 307
- Followers 527
- Likes 3,836
838 Photos and videos











John Chih Liu retweeted

30 Oct 2025
(11/n) If you're interested in RAG, multi-hop reasoning, or evaluation of LLMs — give our paper a read and check out CRUMQs!
📄 Paper: arxiv.org/abs/2510.11956
🔗 Code: github.com/pybeebee/CRUMQs
1
1
1
131
John Chih Liu retweeted
30 Oct 2025
🚀 RAG systems excel at answering questions—but what happens when the corpus has NO answer or complex multi-hop reasoning is required?
Moreover, how can we build benchmarks to stress-test RAG systems in such settings in a realistic way?
See our new preprint to find out! 🧵👇

1
3
5
789

28 Aug 2025
Bravo Kaili!
26 Aug 2025

🎉 Delighted to announce that MetaFaith has been accepted to #EMNLP2025 Main! In this work we systematically study how well LLMs can express their internal uncertainty in words, offering a metacognition-inspired way to improve this ability 🧠✨
Check out more details below!👇
2
20
John Chih Liu retweeted
26 Jul 2025
I will be presenting our work 𝗠𝗗𝗖𝘂𝗿𝗲 at #ACL2025NLP in Vienna this week! 🇦🇹
Come by if you’re interested in multi-doc reasoning and/or scalable creation of high-quality post-training data!
📍 Poster Session 4 @ Hall 4/5
🗓️ Wed, July 30 | 11-12:30
🔗 aclanthology.org/2025.acl-lo…
1 Nov 2024
🔥Thrilled to introduce MDCure: A Scalable Pipeline for Multi-Document Instruction-Following 🔥
How can we systematically and scalably improve LLMs' ability to handle complex multi-document tasks?
Check out our new preprint to find out!
Details in 🧵 (1/n):

1
5
28
3,032
John Chih Liu retweeted

16 Jun 2025
If you use "AI agents" (LLMs that call tools) you need to be aware of the Lethal Trifecta
Any time you combine access to private data with exposure to untrusted content and the ability to externally communicate an attacker can trick the system into stealing your data!
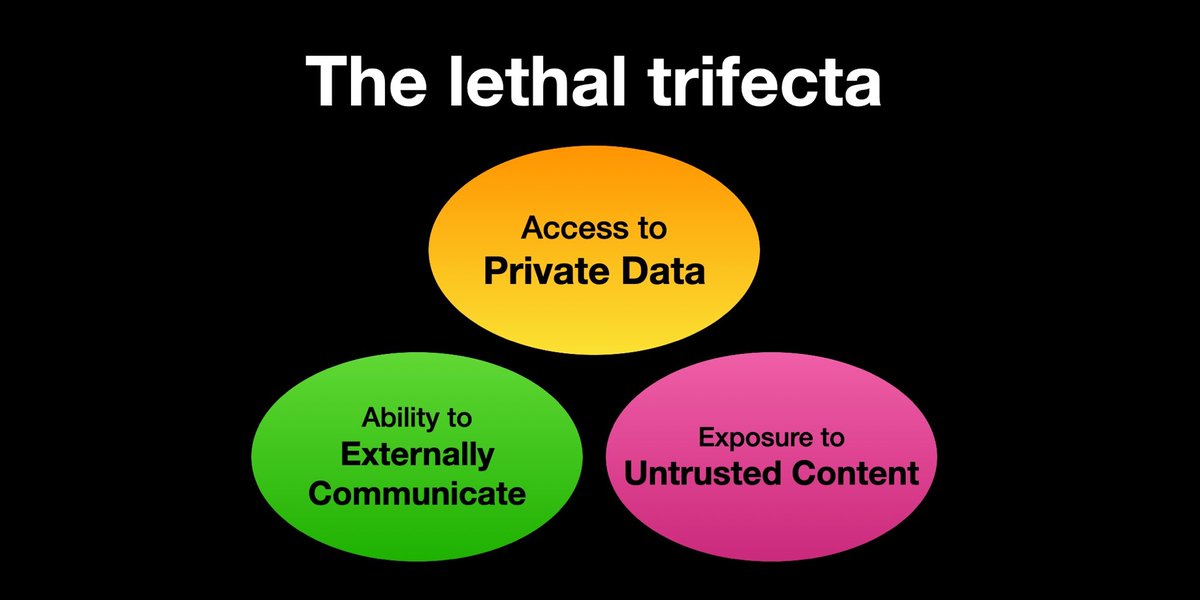
ALT The lethal trifecta (diagram with three circles): access to private data, ability to externally communicate, exposure to untrusted content
89
530
2,329
655,663
John Chih Liu retweeted
2 Jun 2025
(14/n) If you're interested in LLM trustworthiness, uncertainty quantification, human-AI collaboration, or even metacognition — give our paper a read and check out MetaFaith! We'd love feedback or questions.
📄 Paper: arxiv.org/abs/2505.24858
🔗 Github: github.com/yale-nlp/MetaFait…
1
1
2
156
John Chih Liu retweeted
2 Jun 2025
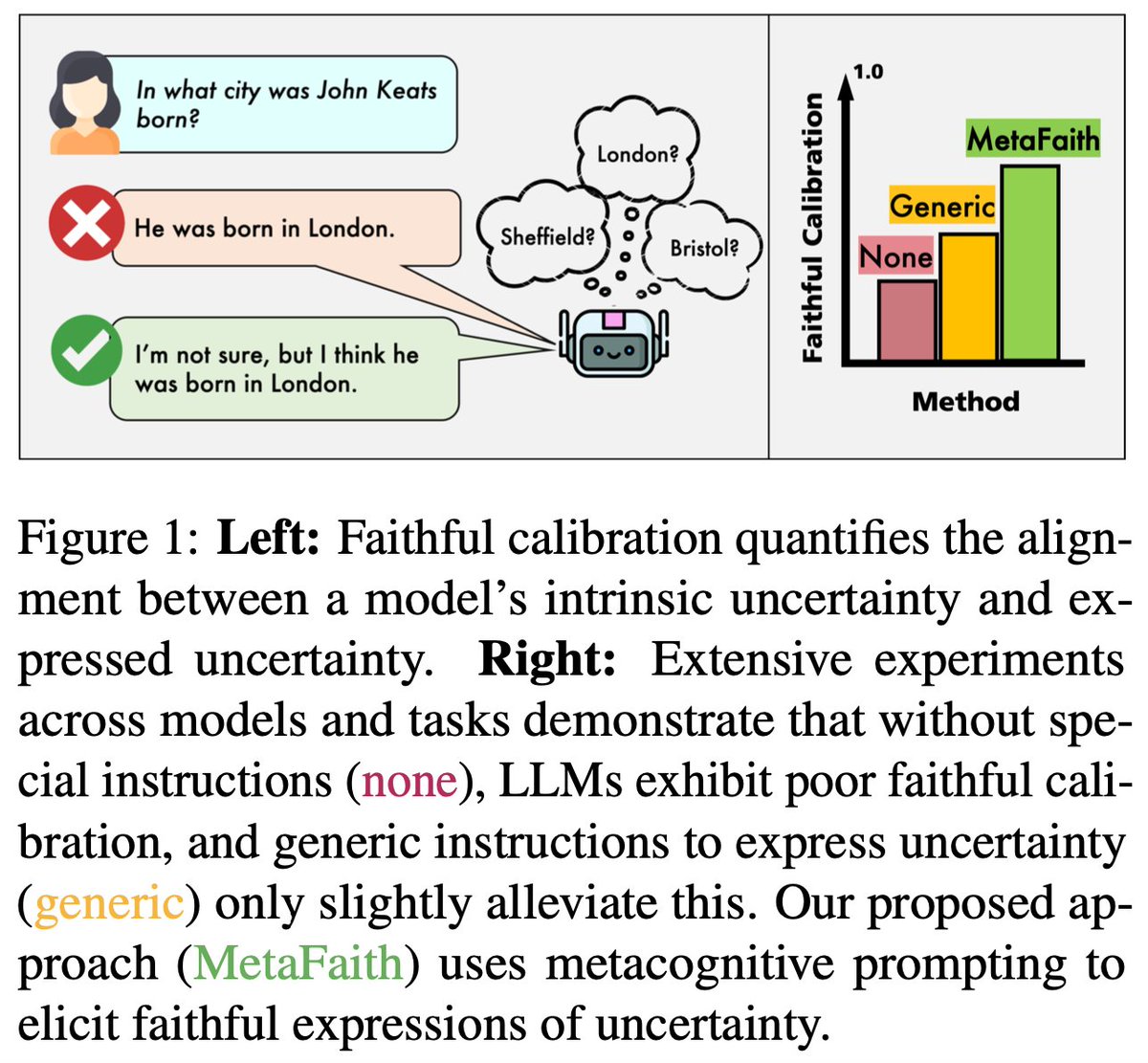
🔥 Excited to share MetaFaith: Understanding and Improving Faithful Natural Language Uncertainty Expression in LLMs🔥
How can we make LLMs talk about uncertainty in a way that truly reflects what they internally "know"?
Check out our new preprint to find out!
Details in 🧵(1/n):
2
4
13
3,334
20 Jan 2025
Brett’s tweets are a great way to ride the pocket of AI
19 Jan 2025

A ton of great progress in AI and Robotics this week.
I summarized everything from Unitree, OpenAI, Mirror Me, Microsoft, Physical Intelligence, Luma, Sakana AI and more.
Here's everything you need to know and how to make sense out of it:
40
2 Nov 2024
Excited to share an intriguing paper on complex multi-document tasks by @pybeebee! 📄✨A must-read for advancing LLM capabilities #AI #LLMs #Research
1 Nov 2024
🔥Thrilled to introduce MDCure: A Scalable Pipeline for Multi-Document Instruction-Following 🔥
How can we systematically and scalably improve LLMs' ability to handle complex multi-document tasks?
Check out our new preprint to find out!
Details in 🧵 (1/n):
2
84
John Chih Liu retweeted

7 Dec 2023
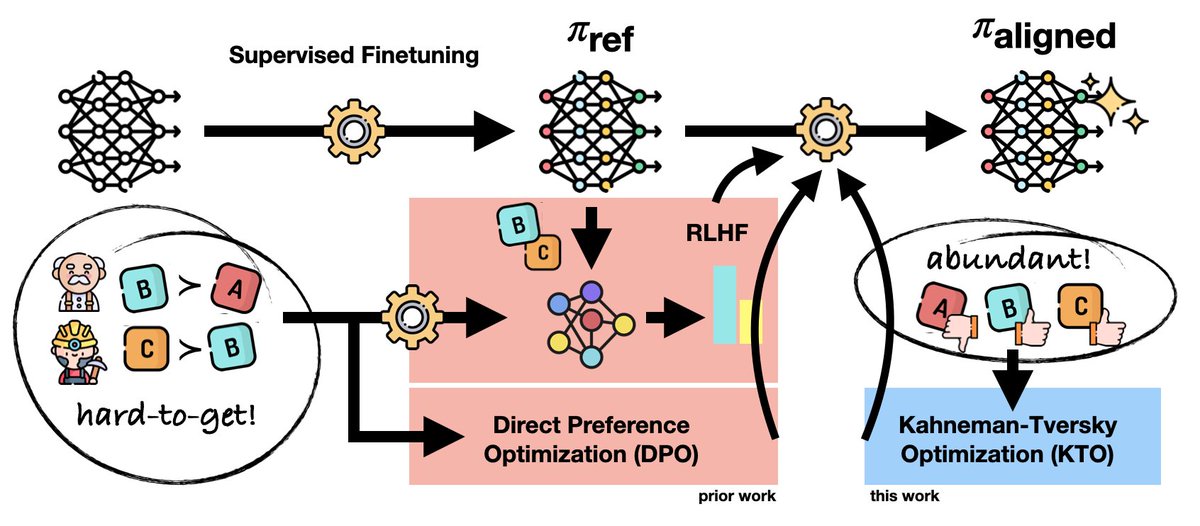
📢The problem in model alignment no one talks about — the need for preference data, which costs $$$ and time!
Enter Kahneman-Tversky Optimization (KTO), which matches or exceeds DPO without paired preferences.
And with it, the largest-ever suite of feedback-aligned LLMs. 🧵
18
126
676
169,981
27 May 2023
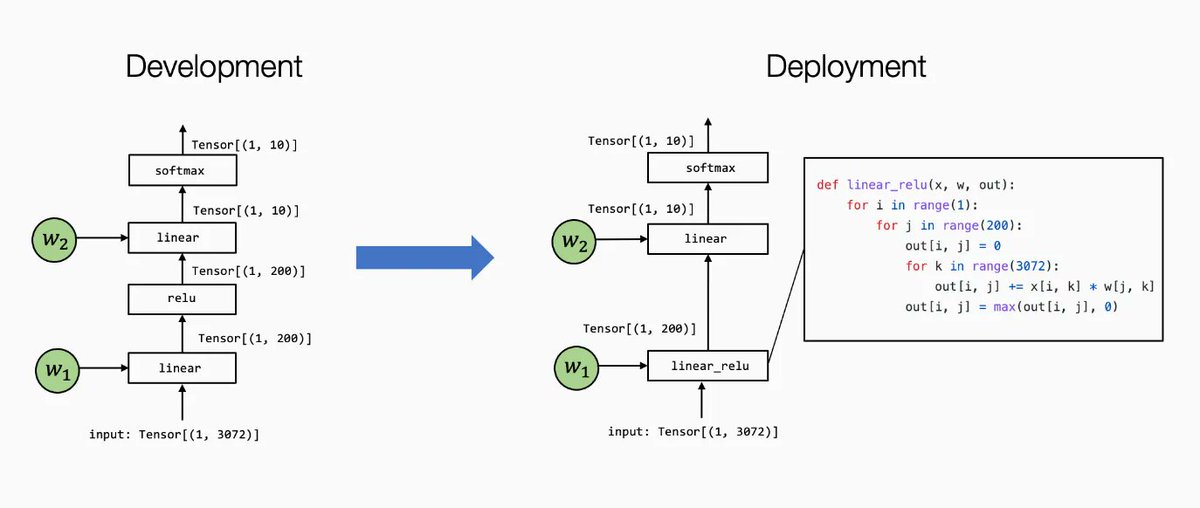
An in-depth MLOps course on taking machine learning from the development phase to production environments buff.ly/439Ma2z
2
87
26 May 2023
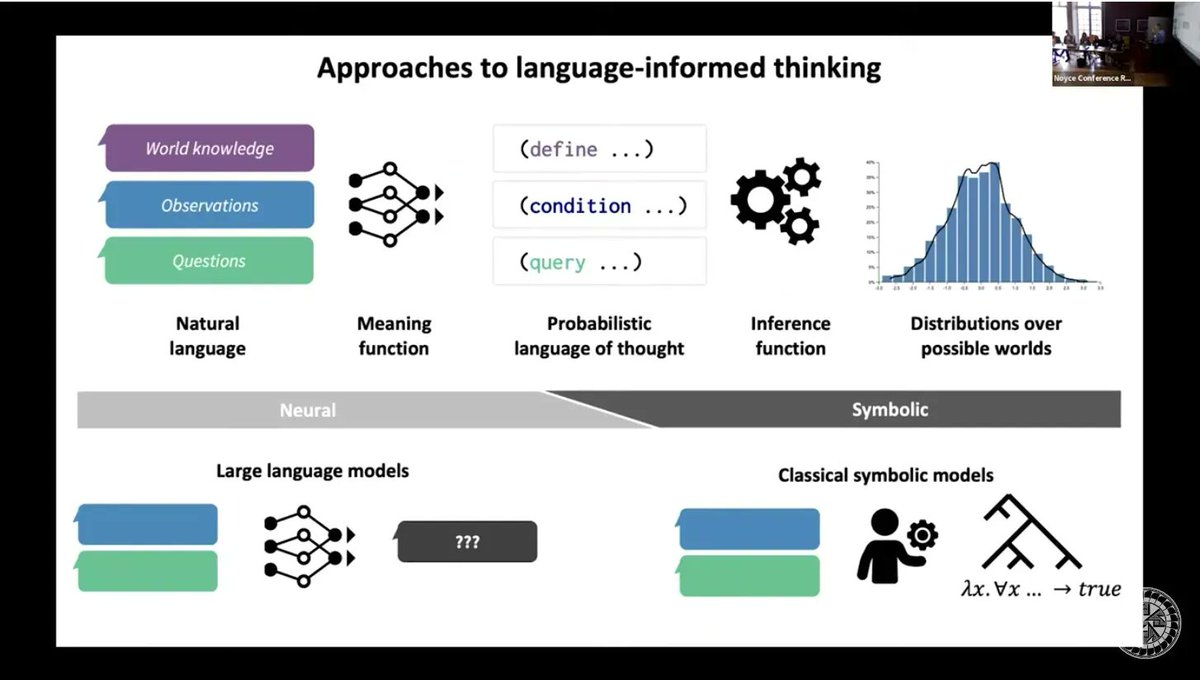
Excellent Santa Fe Institute talk by Josh Tenenbaum on the limitations of GPT-4 and better approaches based on probabilistic world models and human-intuitive AI buff.ly/437slJ8

82
John Chih Liu retweeted

31 Mar 2023
Only 17 days left in the @SecurityBSides @BSidesLV CFP-get your talk proposals in!
Open tracks:
Breaking Ground
Common Ground
Ground Floor
Ground Truth
Hire Ground
@iamthecavalry
PasswordsCon
Training Ground
Underground
What're all these tracks @Daemontamer? Glad you asked! 🧵

1
29
25
7,353
John Chih Liu retweeted

26 Mar 2023
I wanted to give a primer on software architecture at Harvard systems reading group, so we're studying @lichess, one of the largest chess websites… and I made a code scavenger hunt!
notes.ekzhang.com/events/hsr…
2
6
88
9,680
John Chih Liu retweeted

26 Mar 2023
Stop what you’re doing and read this entire post on the GPT-4 code interpreter plugin. This is completely bonkers and is going to change everything. andrewmayneblog.wordpress.co…
37
300
1,855
389,865
John Chih Liu retweeted

14 Mar 2023
Congrats to everyone involved in one of the big announcements today! 🎉
To those who are not: remember that your value is NOT whether you find yourself in one of the few in-groups. A healthy scientific field is not supposed to make you feel left out. You are doing great 🌞
1
11
153
15,420
15 Mar 2023
Imagine the power unleashed if we have GPT-3 inference-on-a-chip. But we won't get there based on digital circuits. The next great race may be for low-power analog chip designs that can incorporate weights directly into the inference circuit.
buff.ly/3YOufLM
37
John Chih Liu retweeted
8 Mar 2023
Reinforcement learning with human feedback is a promising technique that lets machines learn to understand human values. But let's not forget about its social & ethical implications. Read more: buff.ly/3L1iIpf
Original paper: buff.ly/3SU0Z4Z
#AI #ethics #rlhf
1
3
144