
Research Scientist @ seed
Joined March 2024
- Tweets 55
- Following 182
- Followers 467
- Likes 172
Photos and videos
Cunxiao Du retweeted

Jan 15
Large Language Models (LLMs) exhibit “slash patterns” in attention maps — a key mechanism behind prefilling acceleration.
We take a first step toward understanding why they emerge.
Main findings:
▶️ Slash patterns are OOD-generalizable
▶️ Queries and keys on these heads are near rank-one and carry little contextual information.
▶️RoPE is the primary source of the slash pattern.
Blog link:
fengzhuo.notion.site/Demysti…
A thread 🧵

2
24
74
7,291

23 Dec 2025
robo phd @YouJiacheng is so professional on LLM🤣, I have never checked the annotation guidelines of OpenAI PRM800k, although I have read this paper so many times.
But the idea did come from when @mavenlin and I were using codex, we just felt codex is so human-like. So we also should annotate some data efficiently.
23 Dec 2025

This is similar to what OpenAI did in PRM800k (2023).
I think this is the right way to collect data.
github.com/openai/prm800k/bl…

1
23
4,586
18 Dec 2025
A simple and fast method for high-quality data annotation: On-Policy Annotation.
Humans lightly edit LLM outputs, then let the LLM continue from the edited prefix—rather than labeling from scratch.
Most tokens remain LLM-generated, boosting annotation efficiency and learnability.
With just 300 annotated SWEGym samples, DevStral-22B-05 on bash-only SWE-Bench-Verified improves 18.6% → 32.8%.
BLOG: terminal-agent.github.io/blo…
1
14
78
15,978
18 Dec 2025
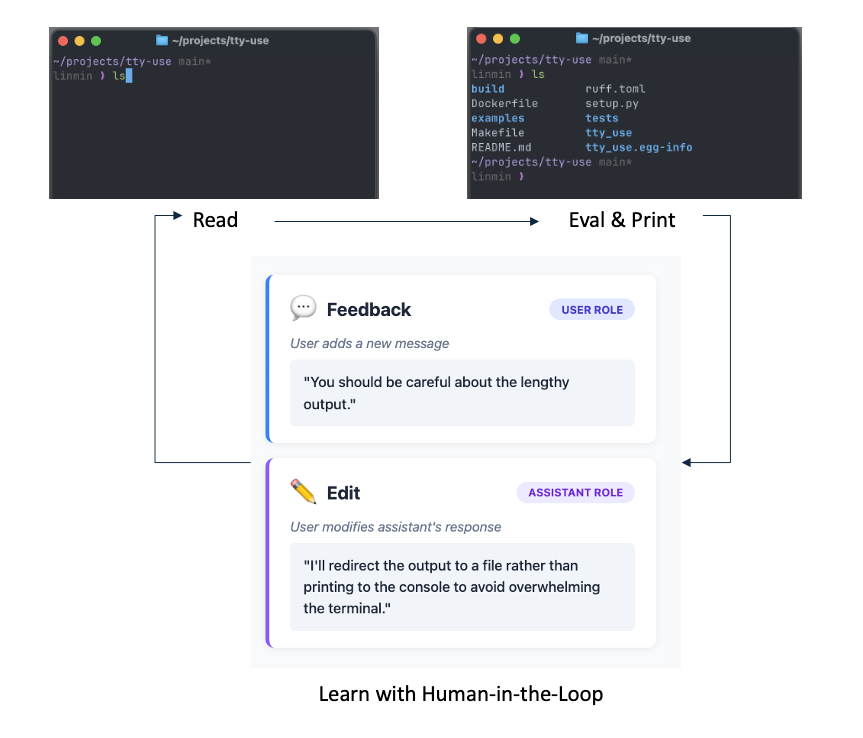
A real example on MLE.
The left side shows the terminal execution, while the right side shows the interaction between the agent and the human annotator. At each step, the annotator needs to confirm whether to proceed with the LLM-generated command (p) or edit it (e).
At the 30s mark, an edit occurs. The human annotator only needs to rewrite, in first-person form, the desired behavior at a high level, and all subsequent tokens can be completed by the LLM, just like Cursor.
This significantly accelerates the annotation process and removes the need for annotators to memorize complex terminal commands, which we find the LLM rarely gets wrong. As a result, the annotation barrier is substantially lowered.
5
806
17 Dec 2025
Can I say this is currently the most user-friendly agent framework I’ve tried? 🚀
You can use it directly in the terminal without Docker. At every step, you can fully see the model’s output and the commands to be executed and also freely edit them. All of this with minimal dependencies installed. 🔧✨
17 Dec 2025

🚀We propose Reptile, a Terminal Agent🤖️that enables interaction with an LLM agent directly in your terminal. The agent can execute any command or custom CLI tool to accomplish tasks, and users can define their own tools and commands for the agent to utilize.
✨What Makes Reptile Special?
Compared with other CLI agents (e.g., Claude Code and Mini SWE-Agent), Reptile stands out for the following reasons:
⚡️Human-in-the-Loop Learning: Users can inspect every step and provide prompt feedback, i.e., give feedback under the USER role or edit the LLM generation under the ASSISTANT role. The interaction will be used for model SFT training & RL training.
💻Terminal-only beyond Bash-only: Simple and stateful execution, which is more efficient than bash-only (you don’t need to specify the environment in every command). It doesn’t require the complicated MCP protocol—just a naive bash tool under the REPL protocol.
Github: github.com/terminal-agent/re…
Homepage: terminal-agent.github.io/blo…
5
824
28 Nov 2025
I completely agree. As I wrote at the end of my blog post and in thread 11:
Humans don’t reason in absolute token slots (“what’s the 25th word from now?”). Mask diffusion does.
We think in latent plans: functions before code, structure before wording, ideas before tokens. That’s what a better diffusion model should capture.
This is very much in line with your perspective, and there are already some papers exploring such latent plans.
Personally, I highly recommend Skeleton of Thought and Multiverse @Xinyu2ML . However, these methods are more closer to post-training or inference-time algorithms, rather than something that can be applied at the pre-training level.
If we want to truly beat left-to-right autoregressive models, I believe we need to figure out how to realize what these methods are doing directly at the pre-training level.
27 Nov 2025

I'm obviously being naive here, but I'm thinking something like an outer loop "big picture/outlining" diffusion-like approach, with an inner loop "detail oriented" autoregressive model.
Just basing this on how I read (skim focus) and also write (outline details).
1
1
17
3,637
27 Nov 2025
I’m sorry, but I must disagree with you. 😂

I'm also not very much bothered by the random order permutation, it still make sense to fit n! models for any frame of n tokens text. It is just that the ex-post fitted posterior may suggest L2R most of the time. (Greedily choosing the order can be seen as the crude version of this posterior).
I believe there are cases where the best order is not L2R, it is more of whether it is worth the extra compute on training to fit the n! models.
6
1,362
25 Nov 2025
Diffusion LLMs (DLLM) can do “any-order” generation, in principle, more flexible than left-to-right (L2R) LLM.
Our main finding is uncomfortable:
➡️ In real language, this flexibility backfires: DLLMs become worse probabilistic models than the L2R / R2L AR LMs.
This thread is about why “any order” turns into a curse.
(Work with Xinyu Yang @Xinyu2ML , Min Lin @mavenlin , Chao Du @duchao0726 and the team.)
Blog Link: notion.so/Understanding-the-…
16
74
461
139,711
25 Nov 2025
11/
People often say “humans think like diffusion, not left-to-right.”
We agree humans aren’t strict L2R generators, but current diffusion LLMs still miss a core part of human cognition.
Humans don’t reason in absolute token slots (“what’s the 25th word from now?”).
We think in latent plans: functions before code, structure before wording, ideas before tokens.
Masked diffusion models don’t capture this, they try to fill fixed positions directly.
If anything, this suggests we don’t need more masked diffusion over tokens, but a genuinely latent diffusion process that operates on plans, not positions.
1
2
36
3,239
25 Nov 2025
TL;DR
0. Diffusion LLMs optimize a sum-log (ELBO) objective.
1. Language strongly prefers L2R/R2L, but ELBO forces the model to fit every order — even terrible ones.
2. A correct any-order LM should use a log-sum objective that naturally focuses on the best orders.
3. Masked diffusion LLMs pay for “any-order flexibility” but end up worse probabilistic models than simple AR LMs.
1
3
33
1,738
Cunxiao Du retweeted

20 May 2025
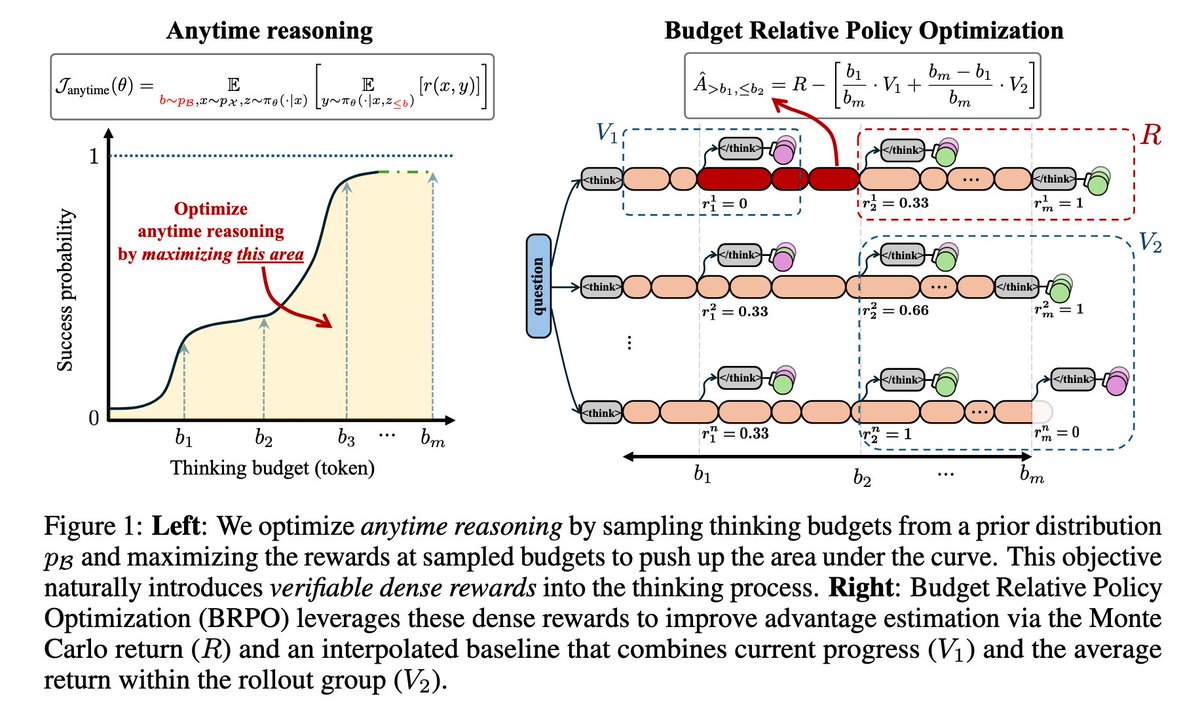
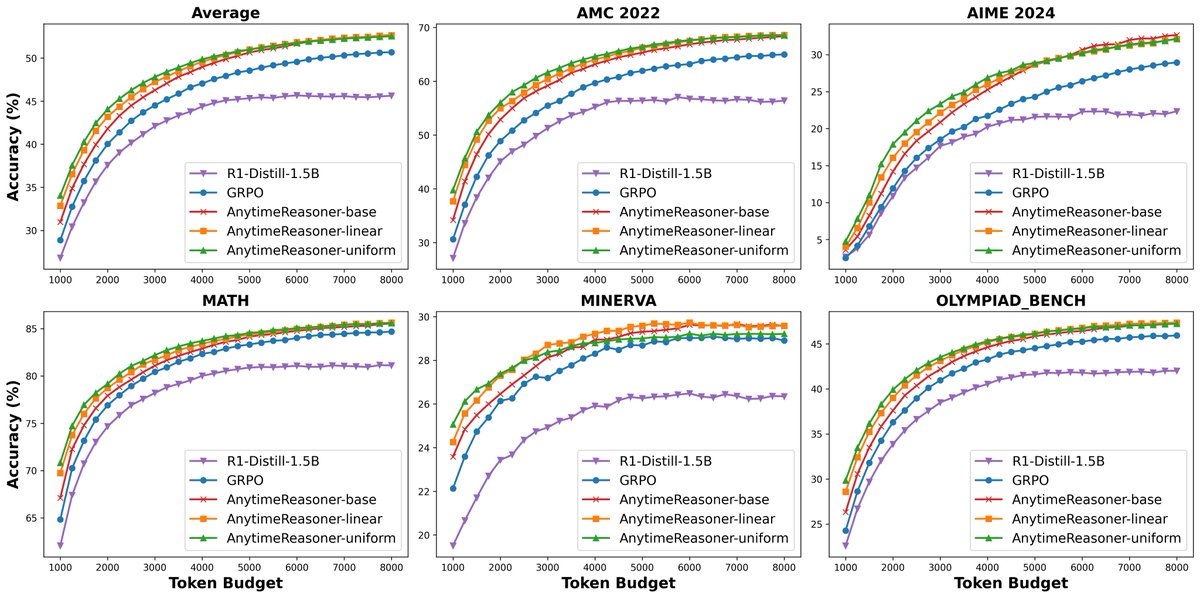
👀Optimizing Anytime Reasoning via Budget Relative Policy Optimization👀
🚀Our BRPO leverages verifiable dense rewards, significantly outperforming GRPO in both final and anytime reasoning performance.🚀
📰Paper: arxiv.org/abs/2505.13438
🛠️Code: github.com/sail-sg/AnytimeRe…
2
26
78
33,455