
3 Photos and videos

Min Lin retweeted

Jun 9
Brilliant idea! Next up: Apple randomly reboots your Mac if you're building competing tech, Gmail silently edits your email if you mention rival platforms, and Tesla Autopilot swerves if it detects you're working on self-driving cars.
All in the name of safety, of course. Because malicious actors controlling the world’s operating systems, inboxes and cars would be extremely dangerous!
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

101
764
6,774
359,242


Min Lin retweeted

Mar 10
I am joining @ylecun and an exceptional founding team to lead @amilabs as CEO.
We have secured a $1.03 billion USD seed round to fuel our mission to build intelligent systems capable of truly understanding the real world—a long-term scientific endeavor.
220
283
5,665
459,178
Min Lin retweeted

Mar 10
i’m joining forces with @ylecun and an incredible group of people to start AMI Labs @amilabs.
AMI isn’t a conventional lab. we don’t intend to become one.
a lot to say about why this moment matters, but for now we’re heads down building.
join us: amilabs.xyz

Advanced Machine Intelligence (AMI) is building a new breed of AI systems that understand the world, have persistent memory, can reason and plan, and are controllable and safe.
We’ve raised a $1.03B (~€890M) round from global investors who believe in our vision of universally intelligent systems centered on world models. This round is co-led by Cathay Innovation, Greycroft, Hiro Capital, HV Capital, and Bezos Expeditions, along with other investors and angels across the world.
We are a growing team of researchers and builders, operating in Paris, New York, Montreal and Singapore from day one.
Read more: amilabs.xyz/
AMI - Real world. Real intelligence.

ALT Photographer: Yann LeCun IC1340 / NGC 6992 / Eastern Veil nebula 20210628-ic1340-rasa-2600mc-lext Scope: Celestron RASA 11" Camera: ZWO ASI2600MC Filter: Radian Triad quad narrow band. Subs: 65 @300 seconds.
153
162
2,797
499,640
The most exciting breakthroughs in intelligence are yet to come. I’m super excited to start this journey with mes amis to make them happen together.
Advanced Machine Intelligence (AMI) is building a new breed of AI systems that understand the world, have persistent memory, can reason and plan, and are controllable and safe.
We’ve raised a $1.03B (~€890M) round from global investors who believe in our vision of universally intelligent systems centered on world models. This round is co-led by Cathay Innovation, Greycroft, Hiro Capital, HV Capital, and Bezos Expeditions, along with other investors and angels across the world.
We are a growing team of researchers and builders, operating in Paris, New York, Montreal and Singapore from day one.
Read more: amilabs.xyz/
AMI - Real world. Real intelligence.
ALT Photographer: Yann LeCun IC1340 / NGC 6992 / Eastern Veil nebula 20210628-ic1340-rasa-2600mc-lext Scope: Celestron RASA 11" Camera: ZWO ASI2600MC Filter: Radian Triad quad narrow band. Subs: 65 @300 seconds.
19
21
405
54,536

Continual learning is a "learning" problem, innovating on model architecture but still relying on sgd to do the learning is leading to nowhere.
Feb 3


1
2
9
2,924
Min Lin retweeted

11 Dec 2025
For research, "(3) Crushing SoTA" is often the most visible to the community, but "(1) working on interesting but useless thing" and "(2) insist on the right way to do things" are the underlying forces that can potentially lead to massive paradigm shift in the end.
10 Dec 2025

I've observed 3 types of ways that great AI researchers work:
1) Working on whatever they find interesting, even if it's "useless"
Whether something will be publishable, fundable, or obviously impactful, is irrelevant to what these people work on. They simply choose something that feels interesting, weird, beautiful, or off in a way they can't ignore. For many of these people, "interestingness" is also often strong research intuition for an important problem that hasn't fully materialized yet, but their ideas often end up being meaningful during the process of exploration.
The canonical example for this in physics is Richard Feynman who got intrigued by the way that plates wobbled. He followed this curiosity on something that seemed like a useless endeavor, and it ended up feeding into deeper physics (and eventually won him a Nobel prize):
"It was effortless. It was easy to play with these things. It was like uncorking a bottle: Everything flowed out effortlessly. I almost tried to resist it! There was no importance to what I was doing, but ultimately there was."
The AI version of this that I've observed before is when someone obsesses over a "minor" failure case, a weird training dynamic, a small theoretical mismatch, or just something that most people think is pointless to chase down. These threads end up becoming interesting and impactful more often than you'd expect. The risk is that one can spend a long time on a pointless rabbit hole, but I've observed that the best researchers often have a very good sense for when an idea is a dead end vs. whether it's promising given more effort.
2) Working on what they feel extremely strongly is the "right" way to do something
These people have a clear picture of how the field *should* progress, and they're willing to work on unpopular things to prove their vision. They'll commit to something that others think is wrong, premature, or not worth it. An interesting quantitative way of measuring this is the citation graph of a paper. If you see a paper that has been around for many years but only started getting cited a lot more in recent years, that means that they were early (and right!). An obvious example is diffusion, the first paper of which was as early as 2015 (Sohl-Dickstein et al., 2015) but the ideas only started getting real traction in 2021 or later.
The failure mode here is getting stuck defending a pet theory long after it's been falsified. And there's obviously many examples in our community of people who do a lot of goal post shifting or beat a dead horse for many decades. But when these ideas are legitimately undervalued, they result in paradigm shifts instead of incremental progress.
3) Crushing SOTA
There's a type of researcher who isn't necessarily the most "philosophically original" or creative, but they are extremely effective at pushing a system to its limits. You can give these people a pre-existing task and benchmarks, check in on them in a month, and they will have crushed SOTA. Obviously this is not about benchmark hacking or short term wins. It's a real skill to take a combinatorial space of noisy research ideas and papers and conduct a rigorous search and ablation process.
I've also found that this type of researcher has great intuition about the field: a sense for which ideas will scale, which tweaks are meaningful, good values for hyperparameters, and quickly figuring out which papers are worth paying attention to.
—————
I think that these archetypes are all concrete expressions of good "research taste". (1) is a taste for interesting questions, (2) is a taste for long term worldviews, and (3) is a taste for careful execution and science. The best researchers I know often have a preference for operating in one of these modes, but frequently weave in and out of each depending on the stage of the project.
7
15
248
43,579

Putting timelines on new research breakthroughs is stupidly hard since these come as step functions. I can recall many arguments I've had over the past two years trying to explain that it's irresponsible to say "we're gonna have AGI in a year" because 1) people's definition of AGI is subjective, and 2) we still need research breakthroughs which could happen in a year's time, or could happen in 10 years' time. The uncertainty on any timeline prediction would be really high.
I actually had a discussion with a VC recently asking about their bets, trying to find inconsistencies in their predictions (a Dutch book). I argued that continual learning/lifelong learning/adaptation is one of the biggest problems to solve, and that new research is needed for that, therefore them putting money on short term bets that rely on CL being solved would be really high risk (and inconsistent with their other bets).
That said, it's worth studying the dot com bubble - the impact the internet has had on the world over the past 25 years was massive, even if expectations at the time were completely unrealistic (expectations which led to the bubble busting). Similarly, AI will slowly diffuse through society (at which point we'll probably stop calling it "AI"), and will have a massive impact on our day to day lives.
There's still lots of research to be done - from adaptation and continual learning to AI robustness and security
28 Nov 2025

One point I made that didn’t come across:
- Scaling the current thing will keep leading to improvements. In particular, it won’t stall.
- But something important will continue to be missing.
13
7
133
38,977
I was debating with @ducx_du in the past few days on a few points, sharing them to provide some more food for discussion.
There can be two interpretations,
1. DLLM is fitting a loose elbo with uniform posterior distribution over the order.
2. It is fitting n! number of models with shared parameter. And then we should not only look at the loss, but to measure the Bayes code length, aka, ex-post fit a posterior over order.
The problem of the second view is that the parameter size maybe too small to fit n! models, but we may want to really do an ex-post fit and compare the perplexity with the L2R. It seems to be a trade-off problem between the amount of compute spent and the perplexity. I do strongly believe that L2R is very likely to be better in perplexity.
25 Nov 2025

Diffusion LLMs (DLLM) can do “any-order” generation, in principle, more flexible than left-to-right (L2R) LLM.
Our main finding is uncomfortable:
➡️ In real language, this flexibility backfires: DLLMs become worse probabilistic models than the L2R / R2L AR LMs.
This thread is about why “any order” turns into a curse.
(Work with Xinyu Yang @Xinyu2ML , Min Lin @mavenlin , Chao Du @duchao0726 and the team.)
Blog Link: notion.so/Understanding-the-…
2
3
27
9,257
I'm also not very much bothered by the random order permutation, it still make sense to fit n! models for any frame of n tokens text. It is just that the ex-post fitted posterior may suggest L2R most of the time. (Greedily choosing the order can be seen as the crude version of this posterior).
I believe there are cases where the best order is not L2R, it is more of whether it is worth the extra compute on training to fit the n! models.
4
3,313
One thing I see is the bitter lesson, reduce and scale always excel. Another thing I see is dedication, the DA sequel comes with a big goal of solving 3D vision, while planting great milestones along the way. Big cong to @bingyikang !
14 Nov 2025

After a year of team work, we're thrilled to introduce Depth Anything 3 (DA3)! 🚀
Aiming for human-like spatial perception, DA3 extends monocular depth estimation to any-view scenarios, including single images, multi-view images, and video.
In pursuit of minimal modeling, DA3 reveals two key insights:
💎 A plain transformer (e.g., vanilla DINO) is enough. No specialized architecture.
✨ A single depth-ray representation is enough. No complex 3D tasks.
Three series of models have been released: the main DA3 series, a monocular metric estimation series, and a monocular depth estimation series.
The core team members, aside from me: @HaotongLin, Sili Chen, Jun Hao Liew, @donydchen.
👇(1/n)
#DepthAnything3
1
8
72
12,276
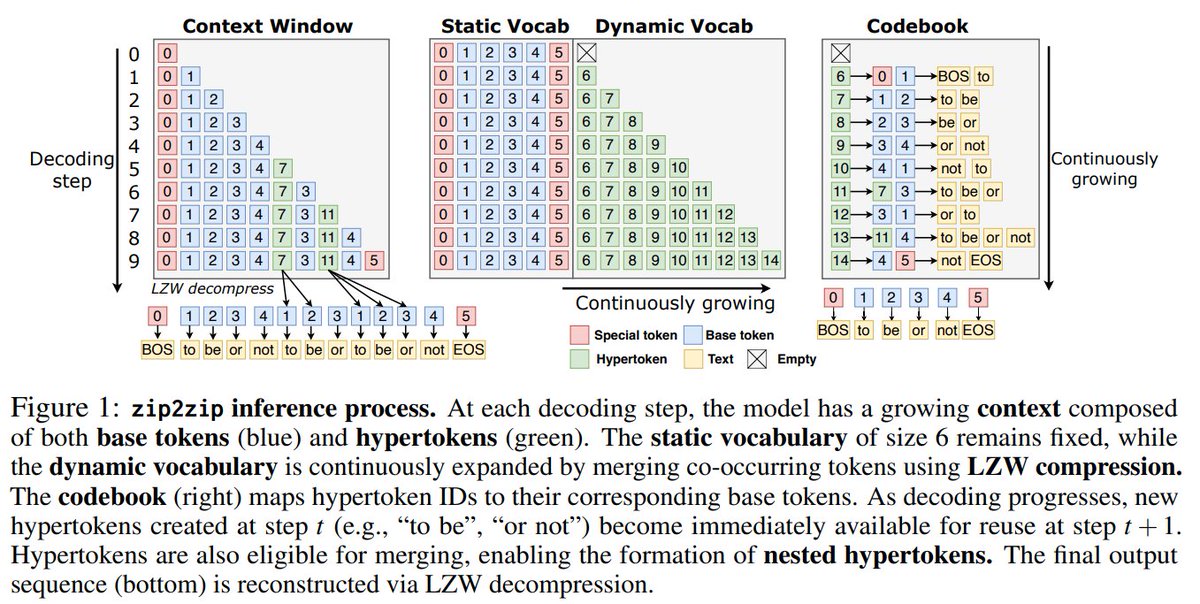
Very cool work! Ultimately an end-to-end, deep learning level performance "LZW" will be the solution to continual learning
4 Nov 2025

Cool new work on progressively growing a dynamic vocabulary that merges tokens using LZW compression.
arxiv.org/abs/2506.01084
2
9
1,324
Our new work on RL training-inference mismatch, cooked by the almighty @QPHutu (lead author of zero bubble). The fix is extremely simple, use FP16 instead of BF16. With this fix, we can bring RL back to its purest IS-weighted PG form. It works uniformly across all settings.
31 Oct 2025

FP16 can have a smaller training-inference gap compared to BFloat16, thus fits better for RL. Even the difference between RL algorithms vanishes once FP16 is adopted. Surprising!

1
3
79
16,292
If big short-term memory works we wouldn't need GPT6, just dump the new pretraining data in the prompt of GPT5.
19 Jan 2025

everyone is building really big short-term memories and calling it long-term memory. they're different things. almost nobody is building long-term memory. I barely ever see papers on it.
it's the last remaining puzzle piece imo. should be the thing people are trying to build.
4
743

Min Lin retweeted

27 Oct 2025
The B in B3LYP.
26 Oct 2025

Axel Dieter Becke, one of the most prominent DFT pioneers, has passed away on October 23, aged 72. RIP

1
10
4,336
Nice work, we've seen lots of innovations that are about "model architecture" (state space models, variants of linear attention). Less on "probability family", which may be more important.
21 Oct 2025
TL;DR: I made a Transformer that conditions its generation on latent variables.
To do so an encoder Transformer only needs a source of randomness during generation, but then it needs an encoder for training, as a [conditional] VAE.
1/5
8
1,505
Min Lin retweeted

20 Oct 2025
NVIDIA over USB4 on MacBook is ready to try!
* ADT-UT3G dock any 30/40/50 series GPU
* Disable SIP
* Install driver `extra/usbgpu/tbgpu`
* Install NVK compiler `brew install tinymesa`
* Test with:
`DEBUG=2 NV_NAK=1 NV=1 python3 test/test_tiny.py TestTiny.test_plus`

121
295
2,686
261,803