
Associate prof of computer science at University of Maryland. Researcher in #AI/#ML, AI #Alignment, #Trustworthy ML, #EthicalAI, AI for ALL.
Joined September 2010
- Tweets 2,256
- Following 2,642
- Followers 10,753
- Likes 7,177
523 Photos and videos














Furong Huang retweeted

Really excited to open source a new project: Omnigent, a meta-harness for AI agents.
It lets you build multi-agent coding and custom agents, sitting above Claude Code, Codex, Pi, and agent SDKs to let you compose them. It also adds live collaboration and rich control policies.

63
156
836
115,097

People replace their phones every ~4 yrs. This means there are hundreds of millions of old phones discarded each year that are still perfectly usable as computing devices. @Google in collabration with @UCSD is exploring how to turn these old phones into cloud-computing “phone clusters”. Putting phones back in service in this way can directly reduce the environmental footprint of computing by avoiding the need for further raw material extraction, and taking advantage of the embodied carbon already incurred from manufacturing these devices, and modern phones actually are already quite powerful computers. Read more in the blog below ⬇️
Jun 12
Today on the blog, we discuss a pathway for the second life of phones through the exploration of “phone cluster computing”, which can directly reduce the environmental footprint of computing by avoiding the need for further raw material extraction. More →goo.gle/4aJe5vO
130
469
4,813
510,846
Furong Huang retweeted

May 13
Excited to share our VLM curation results! With data curation alone, we define a new frontier🚀
Easily one of the most fun stretches of work I've done in a while. If you care about VLMs and pre-training, or just how far data alone can push you, check out our latest work!
Blog: datologyai.com/blog/2020-vis…
Paper: arxiv.org/abs/2605.11405
More details in the thread below👇
May 13

20/20 Vision Language Models: A Prescription for Better VLMs through Data Curation Alone
3
24
3,756

Jun 13
Silicon Valley Notes
I came to Silicon Valley because of an old aspiration connected to the Simons Institute. I expected to think about research, people, and future directions. I did not expect the trip to bring back old memories.
For a while, I was again that younger version of myself in the theory community, admiring the beauty of the field while quietly learning how much academic genealogy mattered. Some people seemed to inherit legitimacy before they had to prove anything. Some of us had to prove ourselves again and again, and still felt outside the room. Leaving theory was intellectually risky, but emotionally necessary. In hindsight, it may have saved my mental health.
Silicon Valley carries a different kind of intensity. It is brilliant, fast, and full of ambition. It also makes the moral cost of abundance very visible.
When an organization can raise extraordinary amounts of money, scale can become a habit of mind. More compute. More data. More people. More experiments. Bigger models will, of course, often look better than smaller ones. But brute force is not the same as wisdom. Every large run burns energy, infrastructure, and human labor. Every dollar spent comes from somewhere, from someone’s work, someone’s trust, someone’s belief in a future being built.
So the question is not only whether the result is better. The question is whether the resources were used responsibly. Did abundance make us more imaginative, or less careful? Did we approach the true ceiling of what could be achieved, or did we mistake spending for thinking?
I had a similar worry when thinking about the younger generation growing up with powerful AI. We joke that students no longer need to struggle as much. Drafts come faster. Code comes faster. Answers arrive before the mind has fully wrestled with the question. In the short run, this looks like efficiency. In the long run, I worry about the quiet loss of depth. If young people skip too many stages of thinking, they may become easier to replace later — not because AI became infinitely capable, but because they were never given enough time to become hard to replace.
This trip also changed how I think about “industry.” The usual phrase is the gap between academia and industry. That gap is real. But the gap between giant tech companies and startups may be just as striking.
In startups, I felt hunger. People are fighting for knowledge, for survival, for a future that is still uncertain. The energy is raw. The questions are close to the ground. In large companies, I saw extraordinary talent, but often inside narrow boxes. People optimize their own area, their own metric, their own KPI. The system does not always ask them to care about the whole picture, and over time, perhaps many no longer need to.
I left with mixed feelings, which is probably the right way to leave Silicon Valley. The trip reopened old wounds, sharpened old questions, and gave me a clearer view of the real problems ahead. It reminded me that intelligence is not only about scale, and progress is not only about speed. It is also about responsibility, taste, courage, and the willingness to think when thinking is no longer required.
I learned a lot. I saw more clearly. I am ready to go.
4
8
106
13,406

Anthropic Managed Agents team:
"Fable 5 is our best model for running self-improving agent systems.
Add /loops, dynamic workflows, dreaming and you are unstoppable"
in 13-minutes, Anthropic team shows how to build self-improving agent systems with Fable 5 from scratch.
Worth more than a $500 agent building course.
Live from the last Anthropic stage in Japan. Unpublished.

40
253
2,125
456,717
Furong Huang retweeted

Jun 11
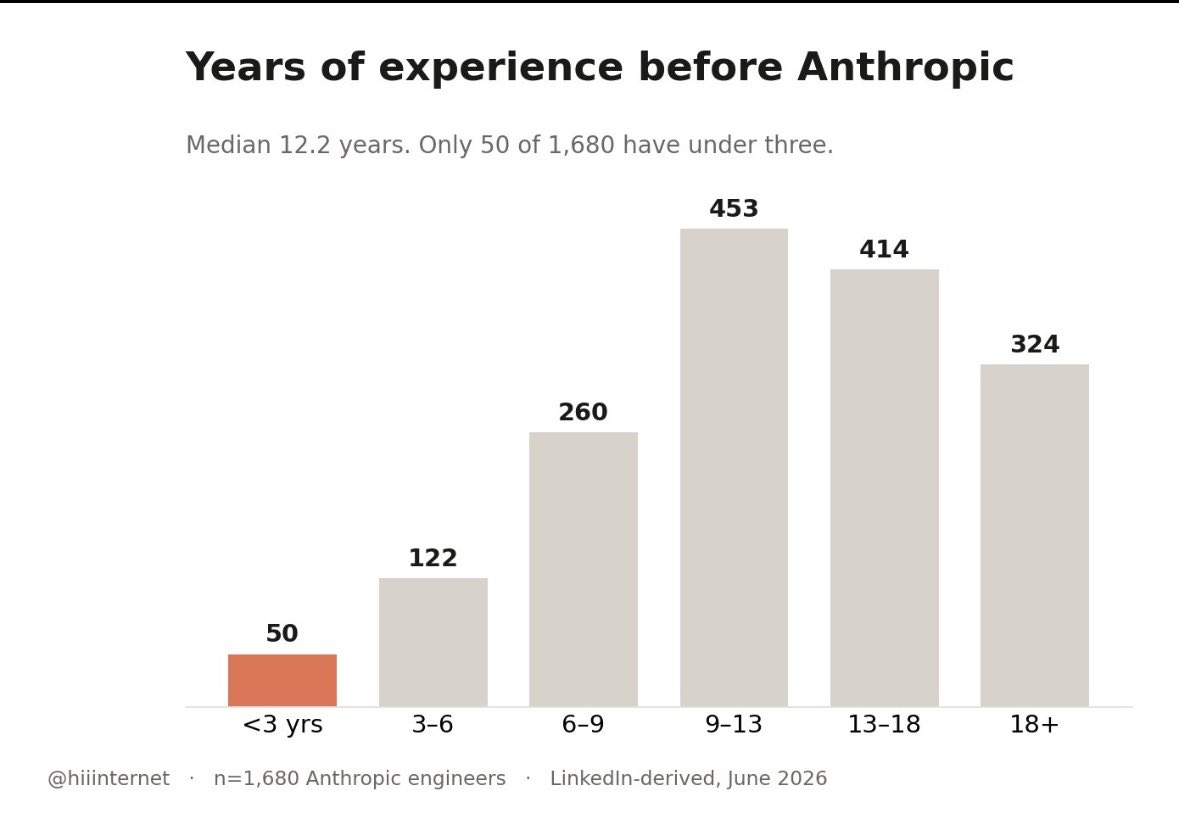
Anthropic almost AVOIDS hiring juniors unless they have a PhD. and only ~13% of their employees have PhD, most have years of careers behind them.

23
134
2,059
573,078
Jun 10
Totally agree that evals need token-budget calibration. But even a cost-calibrated comparison isn't enough: models scale differently under the exact same setup. Choosing just one token budget to report only paints half the picture.

1
1
10
4,093
Jun 8
I really enjoyed Phillip Isola’s talk this morning though: x.com/phillip_isola/status/2…
Predictive state representation was something I learnt a long time ago: probably in 2017. I remember back then, Geoffrey Gordon had a few papers on it. At some point, I tried to induce a low dimensional representation through some decomposition when I was at Microsoft research NYC — unfortunately I didn’t really put that work out for some reasons. Glad to see the concept revived for memory compression. And maybe time to go back to work on that again!
Jun 8

I somehow didn’t remember that Simons Berkeley workshops have invite-only afternoon sessions, that not everyone gets to give a talk, and that approved registration only means participation—not an invitation.
Last time I was in Simon’s was probably 10 years ago. It’s all a blur.
Silly me: I postponed my family trip to China, ended up not traveling with my family but going alone a week later, canceled student meetings and other commitments, booked East Coast → West Coast flights and a hotel, only to learn that I neither have a chance to give a talk nor access to the afternoon sessions.
Felt embarrassed. Clearly I still have a long way to go to earn my reputation and my spot in the community.
Way to go.
29
6,902
Jun 8
I somehow didn’t remember that Simons Berkeley workshops have invite-only afternoon sessions, that not everyone gets to give a talk, and that approved registration only means participation—not an invitation.
Last time I was in Simon’s was probably 10 years ago. It’s all a blur.
Silly me: I postponed my family trip to China, ended up not traveling with my family but going alone a week later, canceled student meetings and other commitments, booked East Coast → West Coast flights and a hotel, only to learn that I neither have a chance to give a talk nor access to the afternoon sessions.
Felt embarrassed. Clearly I still have a long way to go to earn my reputation and my spot in the community.
Way to go.
6
51
16,693
Jun 7
I’ll be in the Bay Area this week, June 8–12, and would be happy to visit AI labs, companies, startups, or research teams for a seminar, chalk talk, or informal discussion.
My group has been working on three connected directions that may be relevant to teams building foundation models, agents, and embodied AI:
1. Reasoning as control.
How should agents allocate test-time compute across decoding, search, tool use, verification, collaboration, and safety intervention? We view inference-time reasoning as a control problem and study runtime policies for reliable planning agents.
2. Self-improving trustworthy foundation models.
As foundation models become more agentic, failures become more dynamic: hallucinated grounding, brittle refusals, reward-model blind spots, adversarial reasoning traces, and poisoned alignment pipelines. We are building closed-loop systems with auditors, actuators, and amplifiers: systems that detect, intervene, recover, and learn from failure.
3. World models for physical intelligence.
Robotics faces a data bottleneck. High-quality teleoperation data is scarce, human demonstrations are embodiment-mismatched, and internet videos are abundant but noisy and actionless. We study world models as a bridge from imperfect experience to grounded robot behavior.
I’d be especially excited to connect with people working on agents, post-training, alignment, robotics, multimodal models, test-time compute, world models, and physical intelligence.
Short notice is totally fine - happy to do a seminar, chalk talk, small-group discussion, or just meet with research teams. Please DM me if useful.


3
13
139
13,701
Furong Huang retweeted

28 Nov 2025
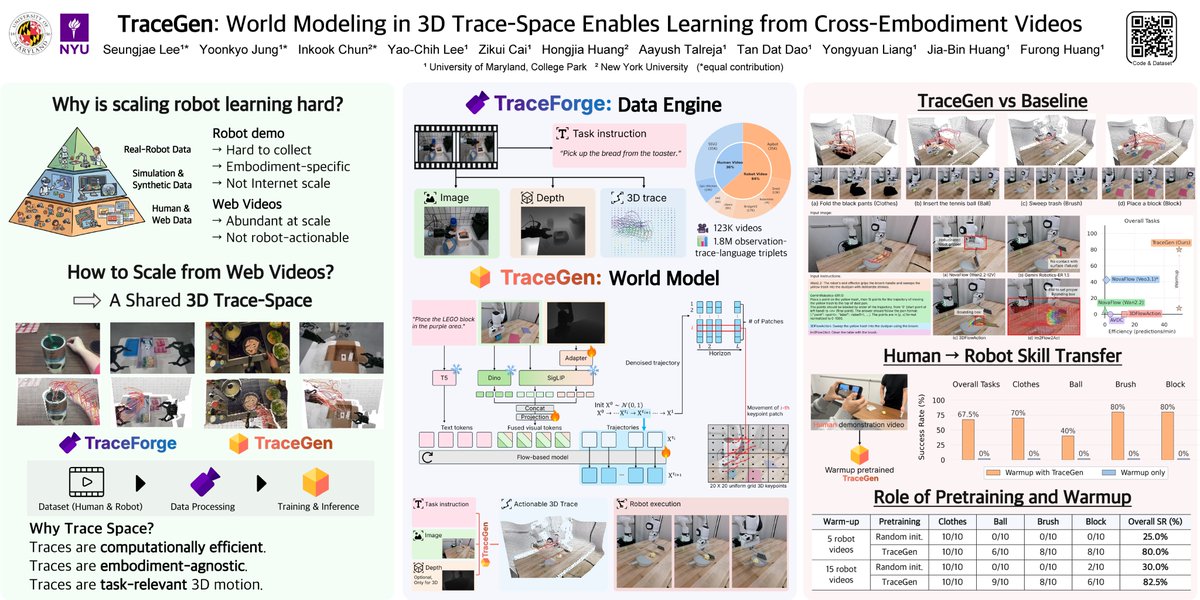
TraceGen :
New way for robots to learn from human and robot videos using a compact 3D “trace-space” representation, predicting motion in 3D instead of pixels. This enables cross-embodiment learning and delivers 50–600× faster inference than video-based models.
2
13
36
1,826
Furong Huang retweeted

Jun 6
Robot learning is bottlenecked by data: adapting to new tasks, robots, and environments often requires many demonstrations.
Meet TraceGen! A motion world model that learns in a compact 3D trace space, abstracting away complex appearance.
This enables learning from diverse videos.
Meet @JayLEE_0301 at #605!
1
1
16
2,733
Furong Huang retweeted

📅 Time: Sat, Jun 6 | 11:45 AM – 1:45 PM MDT
📍Location: ExHall F #605
🚀 Excited to share that we’ll be presenting our work, TraceGen, at CVPR 2026!
Robot learning is heavily bottlenecked by data. To tackle this, we introduce TraceGen—a motion world model that learns in a compact 3D trace space, abstracting away complex appearance and enabling learning from diverse videos.
If you're attending CVPR in Denver, please stop by our poster to chat about robot learning, world models, or just to say hi! 👋
4
14
1,061
Jun 4
Excited to be at #CVPR 2026 in Denver this week for events around trustworthy AI, embodied reasoning, watermarking, and world models. I will only be around on Thursday, June 4, so please come say hi tomorrow!
On June 4, I will be speaking at several CVPR workshops and tutorials:
1⃣ CVPR 2026 Workshop on Trustworthy AI / TRUE-V
🔗 trustworthy-ai-workshop.gith…
📍 9:10–9:40 AM | Room 705/707
Talk Title: A Few Early Steps Away: Building Self-Correcting Vision-Language Systems
I will discuss how we can move beyond static vision-language models toward systems that can recognize, reason about, and correct their own failures.
2⃣ The first CVPR Workshop on Embodied Reasoning in Action (ERA)
🔗 embodied-reasoning.github.io…
📍11:45 AM–12:20 PM | Room 605
Talk Title: From Perception to Action: From Latent World Models to State-Aware Scene Graphs for Physical Intelligence
This talk will focus on representations and learning systems that connect perception, reasoning, and action for physical intelligence.
Later in the day, I will also be part of the CVPR tutorial:
3⃣Foundations and Frontiers of Watermarking
🔗 vishal3477.github.io/waterma…
📍3:30–4:10 PM | Room: Mile High 2B
Session Title: Benchmarking & Robustness Evaluation
I will cover how to evaluate watermarking systems under distortions, regeneration, and adaptive attacks—an increasingly important direction for trustworthy generative AI.
Our team will also present TraceGen at the CVPR main conference. I will not be there on June 6, but my students will be presenting the work — please stop by and talk with them!
4⃣TraceGen: World Modeling in 3D Trace Space Enables Learning from Cross-Embodiment Videos
Project 🔗: tracegen.github.io/
YouTube 📽️: youtu.be/JCXnK2tHE_I
Poster 📍: Saturday, June 6, 2026 | 11:45 AM–1:45 PM MDT | ExHall F 605
TraceGen introduces a world-modeling framework that predicts future motion in a compact 3D trace space, rather than directly in pixel space. This abstraction preserves the geometry needed for manipulation while reducing dependence on embodiment-specific appearance, enabling learning from heterogeneous human and robot videos and improving transfer to real-world robotic tasks.
Fresh out of oven new research:
We have also pushed this direction to the next level. Stay tuned for our upcoming release of μ₀, a symbolic world model pretrained only from video data that reaches π₀.₅-level performance. 🔥
Looking forward to seeing friends, collaborators, and new colleagues tomorrow at CVPR!
#CVPR2026 #TrustworthyAI #EmbodiedAI #VisionLanguageModels #Robotics #WorldModels #Watermarking #GenerativeAI #PhysicalIntelligence


1
9
40
2,616
Furong Huang retweeted
Jun 1
AI can write code, pass exams, and generate videos.
But ask a robot to pour almonds into a bowl, and it may still fail.
Why?
One reason: robots are often using visual encoders trained for the internet — not for action.
Our new work asks: do robots have the wrong eyes?
3
8
70
8,289

Are you still running your robot policies on vision encoders trained purely on static images?
Nowadays, the standard practice in robot learning is to plug in powerful vision models like CLIP, SigLIP, or DINOv2. This inherits a quiet, convenient assumption: “Let mainstream computer vision handle perception, and the downstream policy will figure out the dynamics.”
But let’s be real for a moment. Is this truly the best we can do?
We introduce DynaFLIP: Rethinking Robotics Perception via Tri-Modal-Dynamics Guided Representation.⬇️
🔷 Dynamics upstream: we push motion understanding into perception.
🔷 Tri-modal-dynamics supervision: image transitions × language × 3D flow, fused via simplex-volume alignment (260K trajectories from robot & human video)
🔷 Transfers everywhere: a visual backbone for diverse policies (MLP, Diffusion Policy, VLA)
🔷 22.5% over the strongest baseline (DINOv2, SigLIP) under real-world OOD
🔷 Open-Source & easy to use
🌐 Website: dynaflip-robotics.github.io
📄 Paper: arxiv.org/abs/2605.30350
💻 Code: github.com/JU-SUK/DynaFLIP
🤗 Hugging Face: huggingface.co/jlee-larr/dyn…
7
38
278
80,059
Jun 1
AI can write code, pass exams, and generate videos.
But ask a robot to pour almonds into a bowl, and it may still fail.
Why?
One reason: robots are often using visual encoders trained for the internet — not for action.
Our new work asks: do robots have the wrong eyes?
3
8
70
8,289
Jun 1
The broader message:
As the field scales robot foundation models and VLAs, we should not leave perception as an afterthought.
Bigger robot brains still need the right eyes.
And for robots, the right eyes are not just semantic.
They are action-aware.
1
1
3
404
Jun 1
Robots do not need to see everything.
They need to see what they can change.
That is the direction we explore in DynaFLIP: Rethinking Robotics Perception via Tri-Modal-Dynamics Guided Representation.
Project: dynaflip-robotics.github.io/
Paper: arxiv.org/abs/2605.30350
Big shoutout to @jusukle @JayLEE_0301 @Jonghun_Shin_ @junghoseong98 Sungha Kim, @dscho1234, H. Jin Kim and @jbhuang0604 💐💐💐
1
6
455