
方糖气球( ftqq.com )博主,80后大叔,萌物控。做原型、敲代码、写吐槽小说、制四格漫画。无业,玩独立开发,偶尔卖课为生。信息流诸多日本语、二次元、R18内容,关注需谨慎。
Joined March 2007
- Tweets 2,363
- Following 1,902
- Followers 13,125
- Likes 23,752
1,411 Photos and videos









现在编码时有一半的时间都是在做审批。但是绝大部分的 Markdown 阅读器都不支持添加标注,所以我做了一个 MarkMark。
可以直接在MD渲染界面进行标注,并复制为 CriticMarkup。
主流模型是熟悉CriticMarkup的,加句「请根据 CriticMarkup 标注的审批意见进行修改」就可以了
github.com/easychen/markmark
2
10
9,924


又加了一个风格集

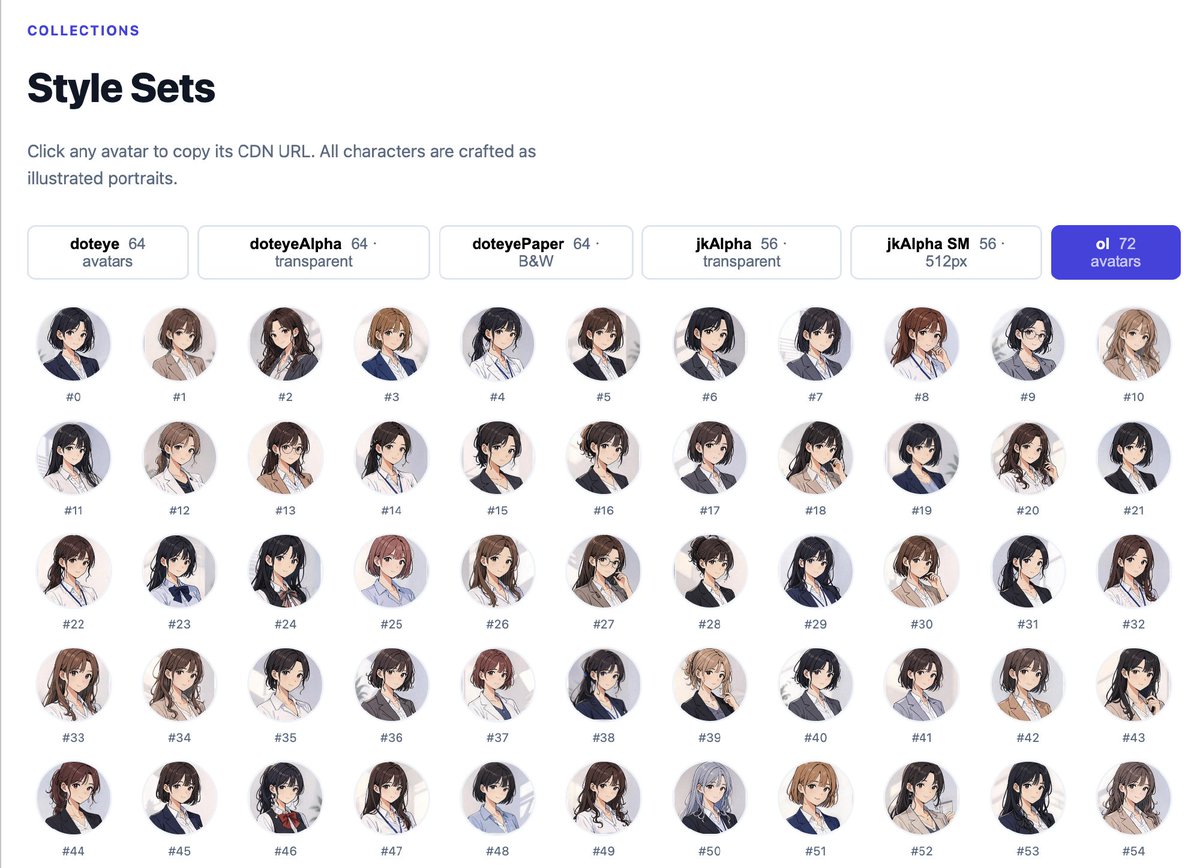
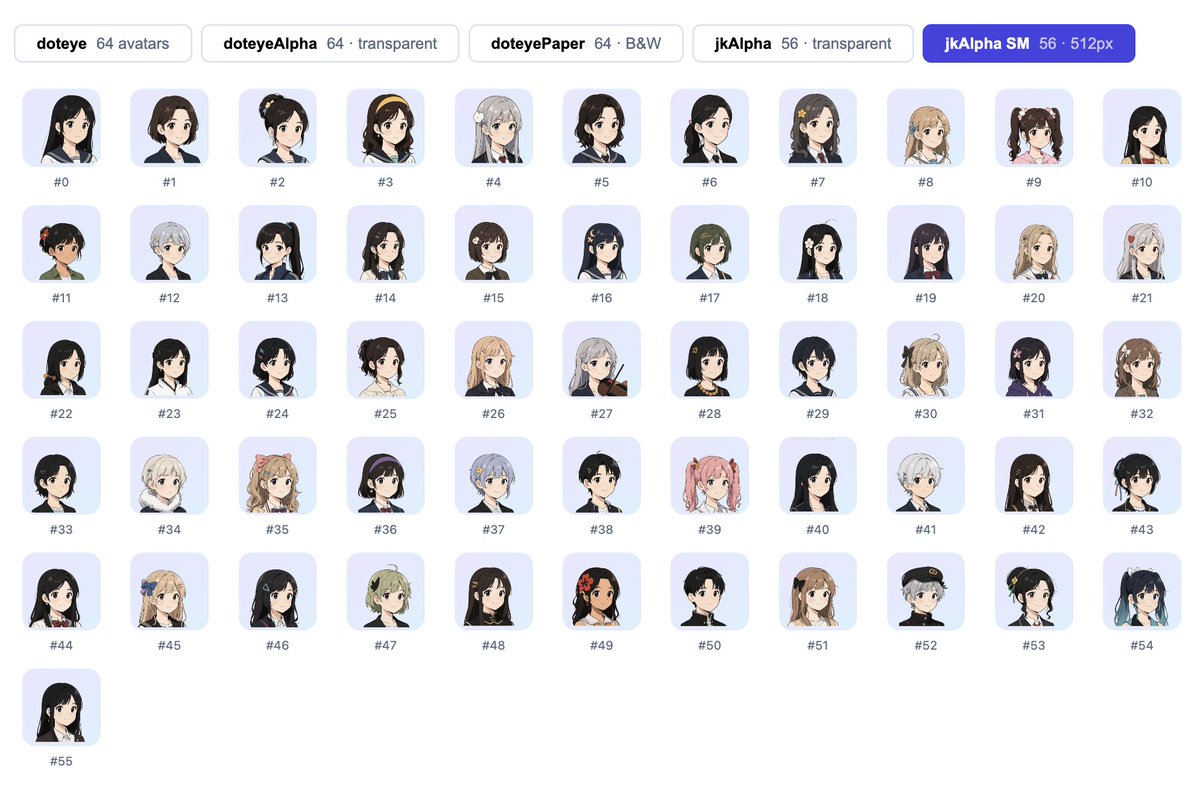
#Easy同学正在独立开发 最近做 Agent,经常需要给它们设置头像。到处找图挺累的。
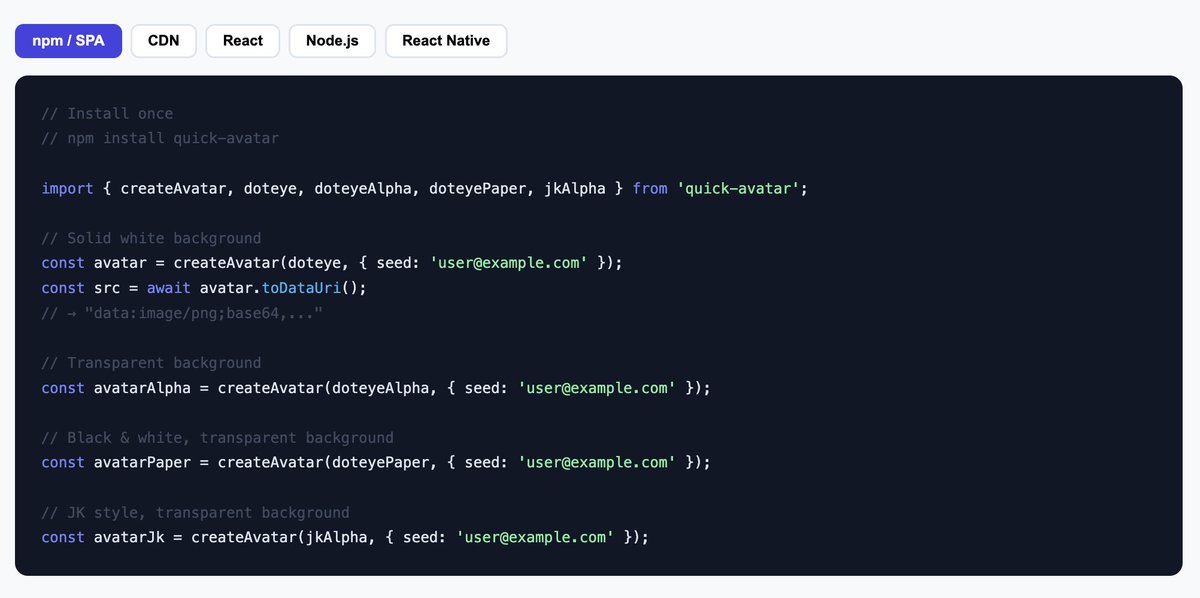
后来发现 Dice Bear 不错,但没有我喜欢的风格。 于是用 GPT image2 做了个随机头像工具,叫做 Quick Avatar。
npm 直接安装后,传一个 seed 就能用。 目前上架了两组人物,欢迎使用
github.com/easychen/quick-av…

1
1,151
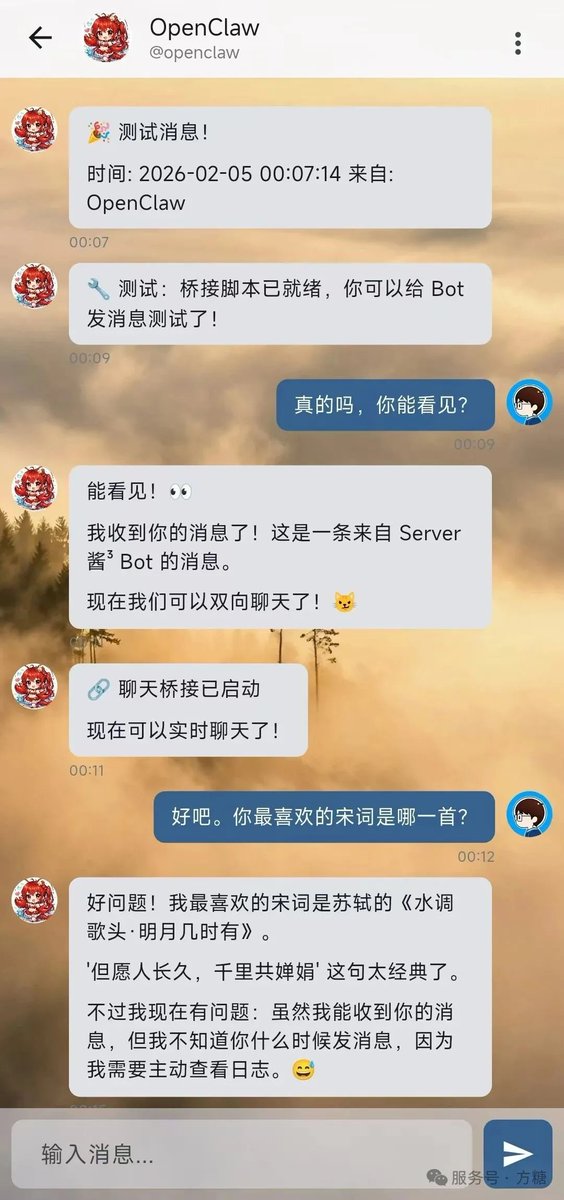
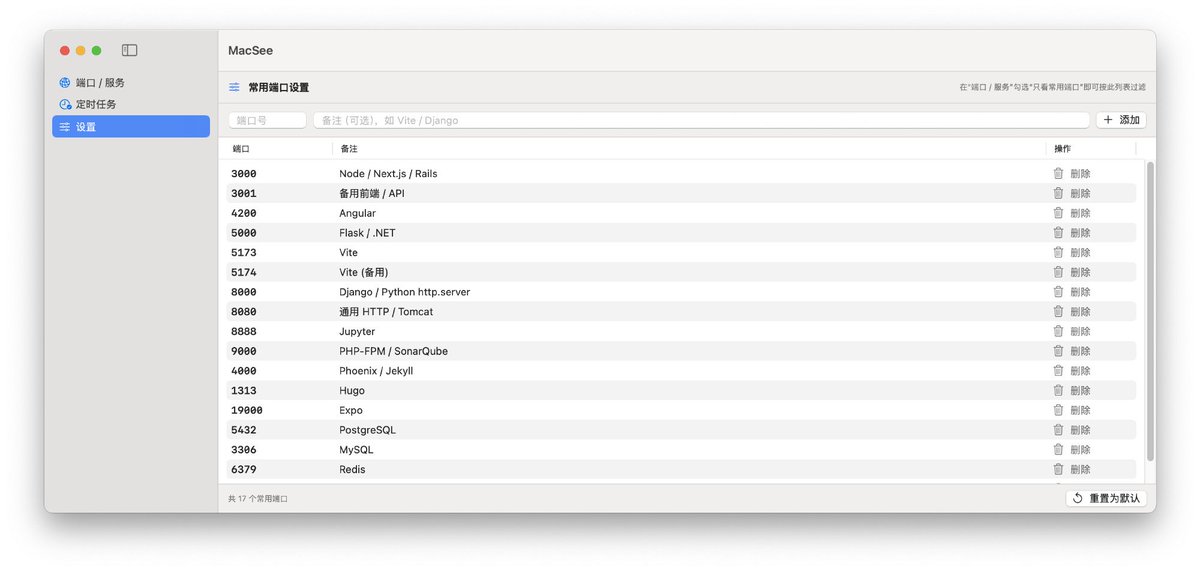
最近 Claude Code 用太多,它总是给我搞出来一堆后台服务,退出时也不关闭。
虽然可以用命令来查看,但总觉得不方便,所以写了一个 MacSee APP,可以用来查看端口占用和对应的目录,方便很多。the7.ft07.com/upload/MacSee.…

8
4,898
#Easy同学正在独立开发 最近做 Agent,经常需要给它们设置头像。到处找图挺累的。
后来发现 Dice Bear 不错,但没有我喜欢的风格。 于是用 GPT image2 做了个随机头像工具,叫做 Quick Avatar。
npm 直接安装后,传一个 seed 就能用。 目前上架了两组人物,欢迎使用
github.com/easychen/quick-av…
3
19
4,073
EasyChen retweeted

Apr 24
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: huggingface.co/deepseek-ai/D…
🤗 Open Weights: huggingface.co/collections/d…
1/n

1,651
7,639
45,761
9,885,380
EasyChen retweeted

Apr 18
claude —dangerously-skip-permissions
28
160
2,392
172,740
EasyChen retweeted

Apr 17
We ran Qwen3.6-35-A3B GGUF performance benchmarks to help you choose the best quant.
Unsloth ranks first in 21 of 22 model sizes on mean KL divergence, making them SOTA.
GGUFs: huggingface.co/unsloth/Qwen3…

47
77
808
74,387
#Easy同学正在独立开发
我们把《一人企业方法论》做成了智能体可以用的 Skill,来和 AI 一起创建和优化你的一人企业吧。
技能集官网: opc-skills.ft07.com
视频讲解: youtube.com/watch?v=Xy4AA759…
2
11
1,174
EasyChen retweeted

Apr 12
We're delighted to announce that MiniMax M2.7 is now officially open source.
With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%).
You can find it on Hugging Face now. Enjoy!🤗
huggingface:huggingface.co/MiniMaxAI/Min…
Blog: minimax.io/news/minimax-m27-…
MiniMax API: platform.minimax.io/

Community note
The MiniMax M2.7 model weights are publicly available, but under a license prohibiting commercial use without authorization. This does not meet the Open Source Initiative's definition of open source, which requires allowing commercial use.
License: huggingface.co/MiniMaxAI/Mini…
OSI: opensource.org/osd
297
759
5,621
1,616,010

‼️Do not npm install or deploy anything right now
Supply chain attack on axios 1.14.1 - even if you don’t use axios it may be a nested dep.
Pin versions or wait until this is resolved
Mar 31

@npmjs @GHSecurityLab there is an active supply chain attack on axios@1.14.1 which pulls in a malicious package published today - plain-crypto-js@4.2.1 - someone took over a maintainer account for Axios
166
1,795
8,948
1,636,304
EasyChen retweeted

The Next.js Adapter API is now stable - the result of over a year of collaboration with Netlify, OpenNext, and other platform partners.
We are deeply committed to developers running Next.js on Cloudflare. Looking forward to building our official adapter on this new foundation.

Next.js 16.2 introduces a stable Adapter API, built with Netlify, Cloudflare, OpenNext, AWS, and Google Cloud. But the API is only part of the story.
Next.js is used by millions of developers across every major cloud, and making it work well everywhere is on us. Here are our commitments.
nextjs.org/nextjs-across-pla…
44
96
1,494
224,983
EasyChen retweeted

Mar 25
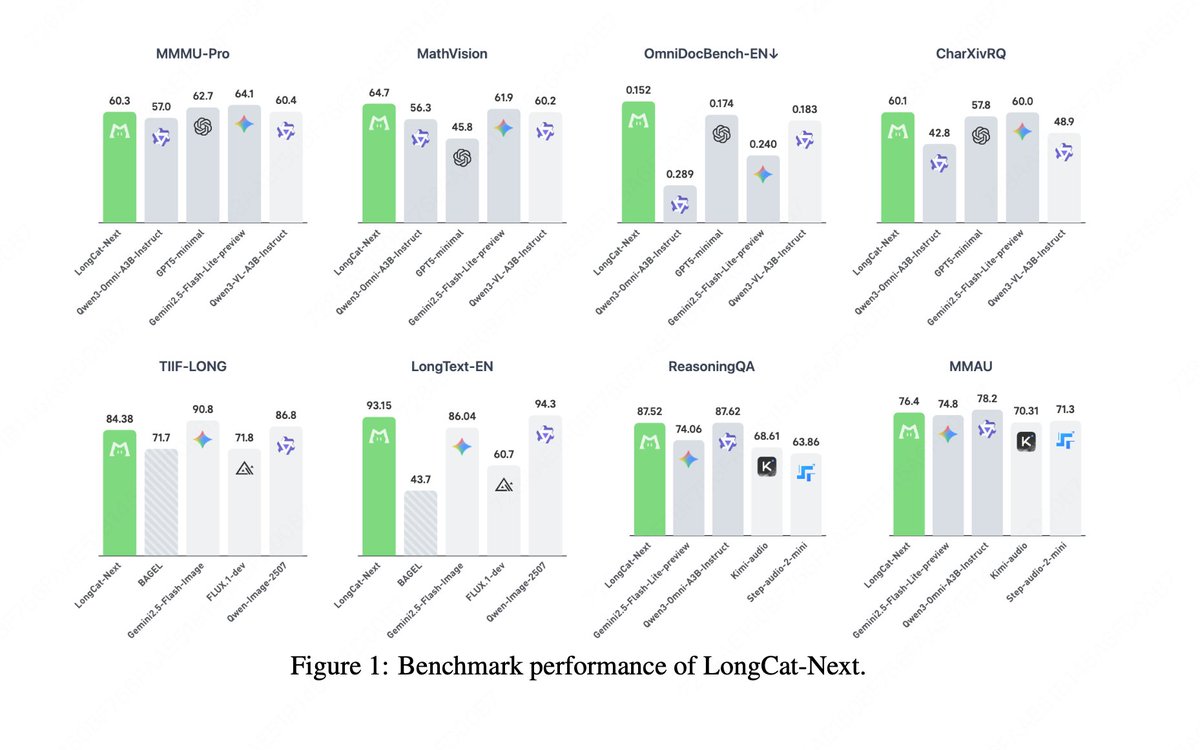
🔥 Introducing LongCat-Next: A Discrete Native Autoregressive Multimodal Model
LongCat-Next integrates language, vision, and audio into a unified discrete autoregressive model, extending Next-Token Prediction to native multimodality and delivering industrial-strength performance across diverse multimodal domains.
🔑 Key Features:
⚙️ 68.5B total params, 3B active, LongCat-Flash-Lite MoE backbone, excels at seeing, painting, and speaking in a unified discrete autoregressive framework.
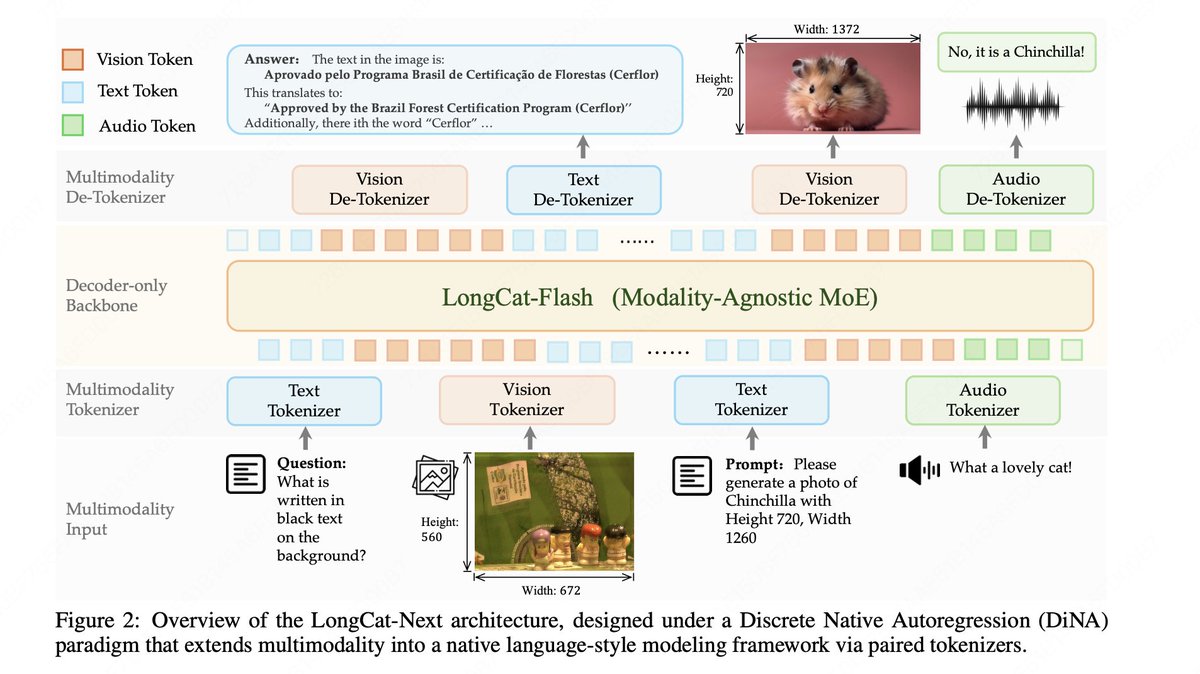
🧩 Discrete Native Autoregression Paradigm (DiNA): We introduce DiNA, a unified paradigm that extends next-token prediction from language to native multimodality, internalizing diverse modalities into a shared discrete token space.
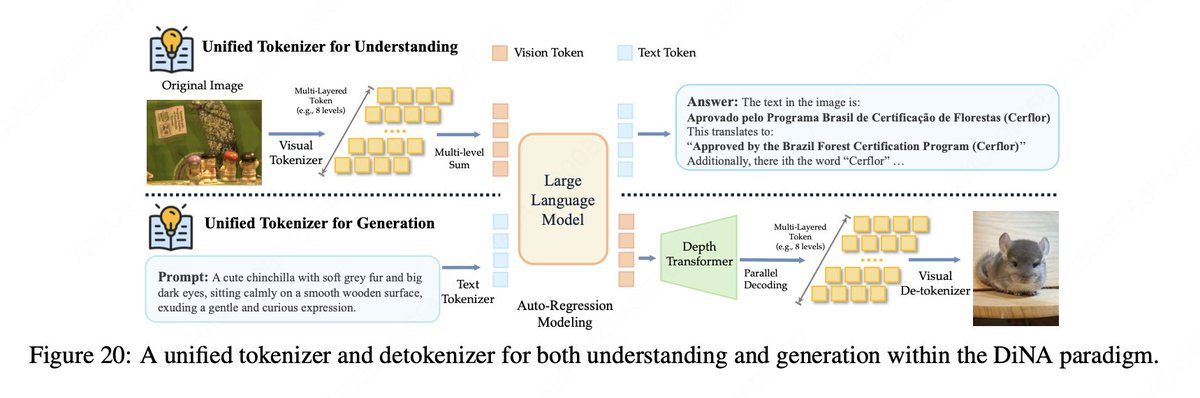
🌐 Discrete Native Any‑Resolution Vision Transformer (dNaViT): A unified visual tokenizer and de-tokenizer that encodes images into discrete IDs with semantic completeness, enabling both understanding and generation at any resolution. This approach overcomes the performance ceiling of discrete vision modeling in understanding tasks and enables to reconcile the conflict between understanding and generation.
👀 Visual Understanding: Fine-grained visual perception for complex tasks such as OCR, Charts, GUI interpretation, and document analysis, and advanced STEM reasoning capabilities.
🎨 Visual Generation: Generation under 28x compression ratio at arbitary resolution with competitive performance, especially in text rendering.
🎧 Speech: Strong audio comprehension capabilities, low-latency and intelligent audio-to-audio interaction, as well as speech synthesis featuring customizable voice cloning.
📄 Paper: github.com/meituan-longcat/L…
🔗 GitHub: github.com/meituan-longcat/L…
😊 HuggingFace: huggingface.co/meituan-longc…
💻 demo: longcat.chat/longcat-next
📖 blog: longcat.chat/longcat-next/in…
10
70
444
48,663
EasyChen retweeted

Mar 25
Building agent skills from scratch is a grind.
We've been there. So we built the fix — and open-sourced all of it under MIT.
PDF, Excel, PPTX, DOCX, and more.
Use it, fork it, PR it.
Intelligence with everyone.
Github Repo → github.com/MiniMax-AI/skills
Try online → agent.minimax.io

23
121
1,149
140,142
EasyChen retweeted

Mar 22
イベントのプレゼントの中にこれ入ってましたwwwwwwwww
26
53
926
36,830
EasyChen retweeted

Mar 20
Don't panic. GLM-5.1 will be open source.
274
422
7,625
993,980
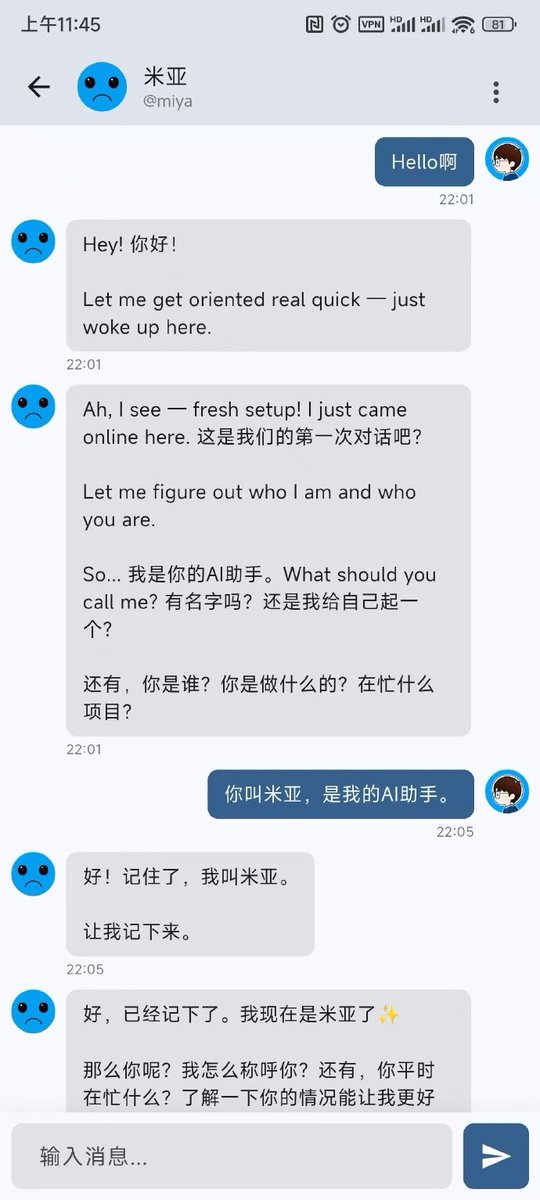
#Easy同学正在独立开发 Server 酱 1.1.4 内测
the7.ft07.com/upload/serverc…
- Bot 聊天页面支持输入框添加快捷命令按钮
- Bot 聊天页面支持显示 bot 状态(需要调用 sendChatAction API)
- 优化页面刷新触发,并添加手动刷新按钮
1
1
1,122