
@feedly CEO. Passionate about research, machine learning, design, and cybersecurity
Joined October 2007
- Tweets 13,294
- Following 1,116
- Followers 3,714
- Likes 7,588
195 Photos and videos


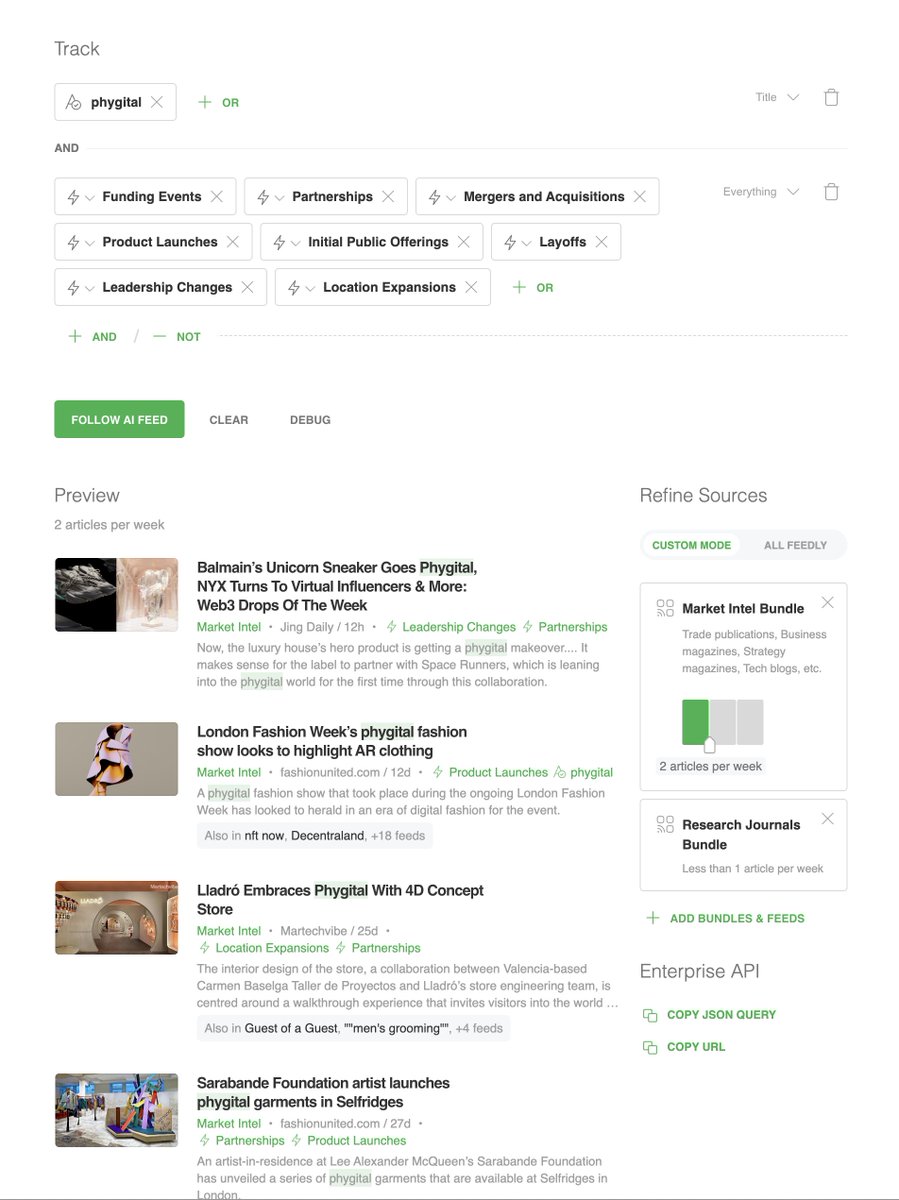







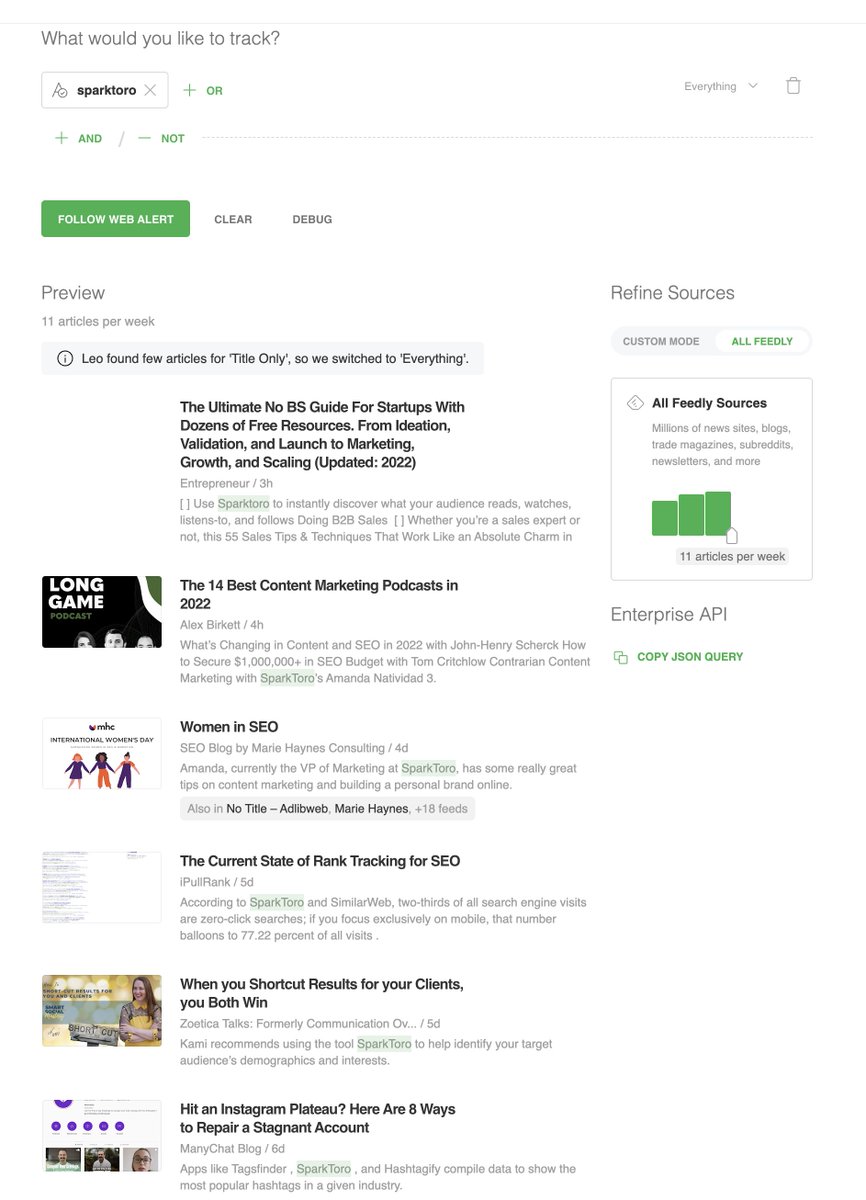


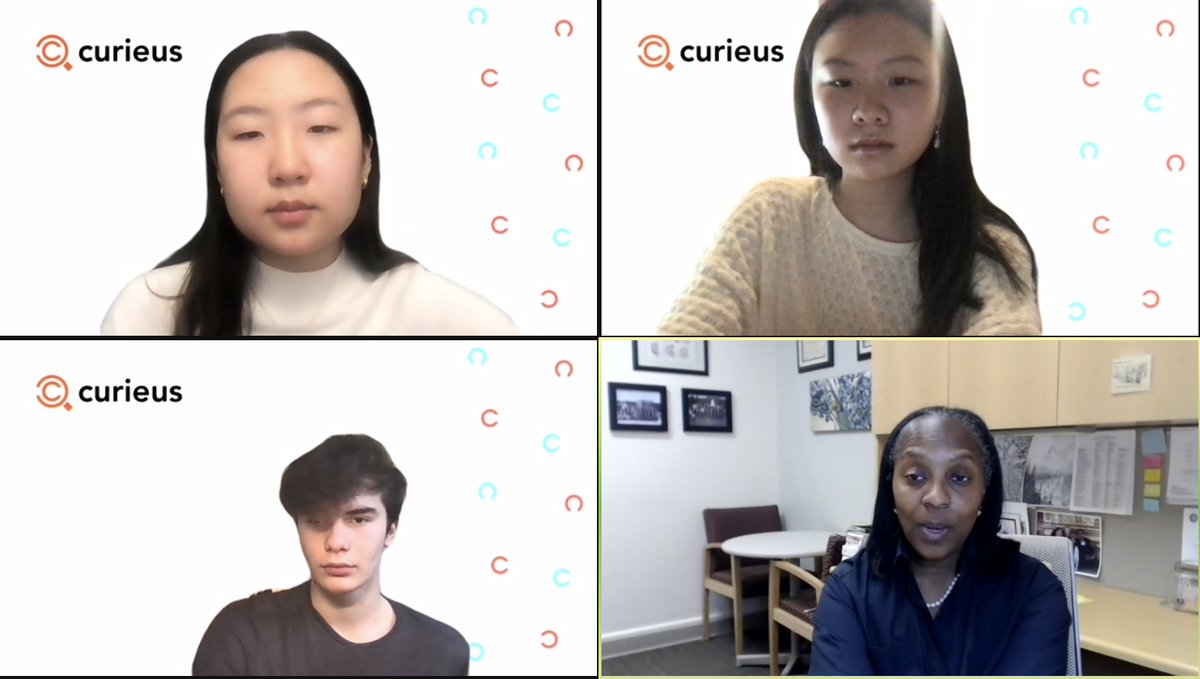
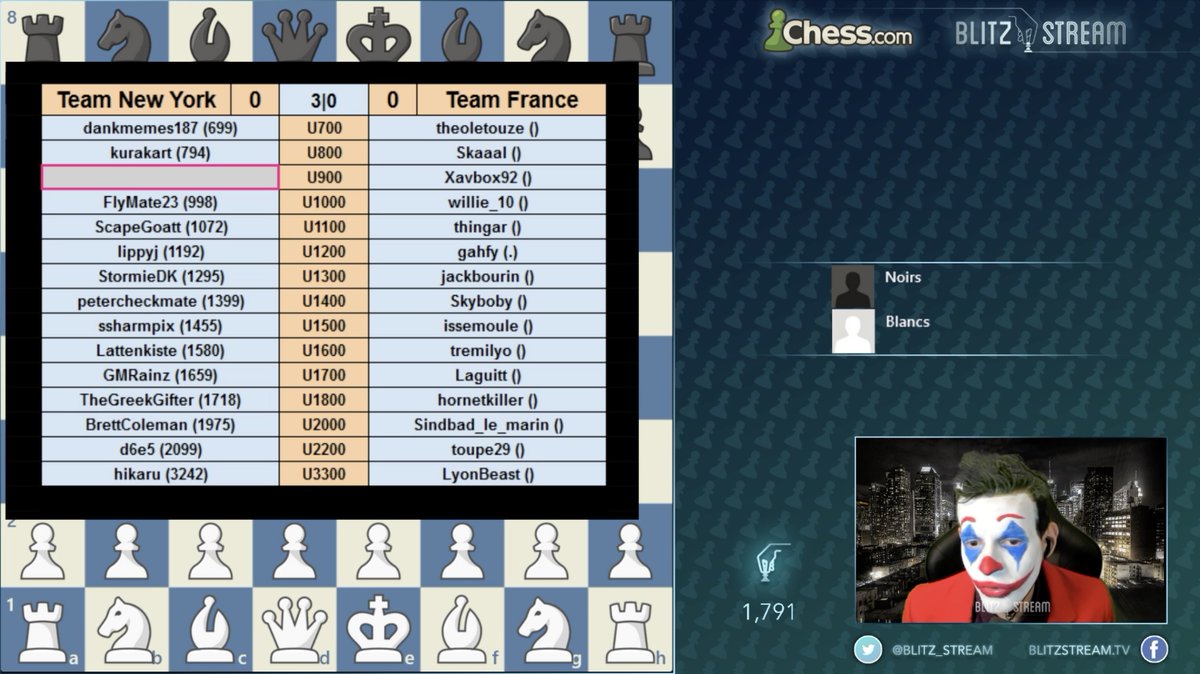


AI won't make human capital less valuable it makes it more valuable. You can offload a task. You can never offload your learning.
The firms that win won't be the ones picking the best model, but the ones building a loop where people and AI compound on top of it.
Build a frontier ecosystem, not just a frontier model.
That's the whole game.

82

#MITRE ATT&CK is one of the most widely used frameworks in #cybersecurity, and its real power goes beyond technique mapping.
In our next #CTI Session, Amy and Lex from The @MITREattack Corporation walk through how to turn #TTPmapping into behavior-first detections that run in production.
feedly.com/cti-sessions/turn…

2
5
1,265
Today I learned that Marjane Satrapi, the creator of Persepolis, has passed away at 56.
linkedin.com/posts/edwink_to…
7
92
916



#CTI practitioners are great at tracking adversaries but the best ones are also great at telling the story of why it matters.
Join us June 17 at 9AM PT!
We’ll break down the metrics that matter most at each stage of program maturity, and how to build a #businesscase that earns confidence from your #CISO and leadership team.
feedly.com/cti-sessions/prov…

1
2
1,162
Feedly #Threat Intelligence #OpenCTI = a #CTI knowledge graph that's always ready!
We're excited to share our new integration with OpenCTI by @FiligranHQ and a sneak peek of how Feedly Threat Intelligence automatically delivers structured, contextual #OSINT directly into your OpenCTI knowledge graph so your analysts can jump straight to pivoting and investigating.
feedly.com/new-features/post…

2
5
1,427
Most #CTI teams want to be more proactive. Here's what that looks like in practice.
When #ScatteredSpider hit UK retail, Ian Parsons and his small team at @Quilter already had the full Dragon Force profile and an executive-ready report done the same afternoon.
Here's the challenge they faced and the workflow that changed everything 👇
feedly.com/customers/posts/f…
#ThreatIntelligence #CyberThreatIntelligence
1
3
1,547
Edwin K retweeted

Jun 5
If big companies can't make a net return on their LLM token costs, that doesn't mean it's impossible to. In fact this is exactly what you'd expect to happen with a new technology. Incumbents can't use it well, and are replaced by upstarts who can.
283
293
3,722
609,013
BFSI CTI teams juggle triage, incident response support, fraud coordination, and exec briefing, often at the same time.
That’s why we put together 10 prompt templates to help with #BFSI #CTI workflows: feedly.com/ti-essentials/pos…
#cybersecurity #threatintelligence

1
1
1,304
A #vulnerability rated MEDIUM sat unpatched for 3 months. Then #CISA added it to #KEV as actively exploited, CVSS 9.8.
That 3-month gap can be deadly. #CTI can help close it.
Mari Galloway, CEO A&M Strategies CEO & Co-Founder of @WomenCyberjutsu walks through the exact playbook BrickHaus's #CTI team used to prioritize their vulnerability backlog.
feedly.com/ti-essentials/pos…

1
1
2
1,669
One Pharma security team is currently:
→ Pulling hundreds of #IOCs from 7,500 sources without the manual work
→ Starting their day with a #TTP briefing waiting in MS Teams every morning at 7:30am
→ Monitoring #ScatteredSpider live and turning new TTPs into #detectionrules
Read the case study for the full breakdown 👇
feedly.com/customers/posts/p…




1
2
2,323
In case you missed it…
We have a #TI Essentials article covering what good #cybercrime investigation actually looks like.
We sat down with Will Thomas (@teamcymru) and Garrett Carstens (@Intel471Inc) and did a deep dive from verifying #threatactor claims before you react, to #crypto tracing, to why you shouldn't try to engage criminals on the fly.
feedly.com/ti-essentials/pos…

1
3
1,308

GBrain is your company brain
Jun 4

how I’m building an agent company inside my agency.
the structure looks like this:
Agency gBrain
→ Orchestrator Hermes Agent
→ Department verticals
→ Specialist agents
→ Scoped sub-agents
gBrain is the company brain.
It gets ingested with the data and experience we already have:
> transcripts
> chats
> previous campaigns
> client learnings
> strategy docs
> internal workflows
> examples of what good looks like
That brain is maintained by a human champion plus an orchestrator Hermes Agent.
Under the orchestrator, we have different department verticals inside the agency.
Each vertical has its own specialist agents.
Some of those specialist agents have even narrower scoped agents underneath them.
I’ve found that narrow scope improves output quality and reduces drift.
> a general “marketing agent” is too vague.
> a lifecycle email agent with access to the right campaigns, voice rules, approval gates, and examples can get very good.
> a technical SEO agent with its own tools, checklists, and source standards can get very good.
> a content research agent with narrow inputs and a clear definition of done can get very good.
The narrower the job, the easier it is to improve the agent.
I use different harnesses for this.
Mostly Hermes Agent, but also CLI harnesses like Codex and Claude Code depending on the job.
I’m still looking for a good bare-bones harness for model routers to run on.
To keep track, I maintain an org chart inside the company gBrain.
The org chart shows:
> top-level orchestrator
> department verticals
> specialist agents
> scoped sub-agents
> which brain each agent reads from
> which tools each agent is allowed to use
> where human approval is required
For clients, I do downstream pods.
Think of them as new agent companies that are isolated from the agency brain, but can still communicate with our agency agents when needed.
A client pod has its own:
> client gBrain
> client orchestrator
> client specialist agents
> client-specific workflows
> client-specific approvals
> client-specific memory
This is important.
You do not want client context bleeding across accounts.
You do not want one agent with every client’s data, every tool, and every permission.
Scope is what keeps the system useful.
The powerful part is that once you build one vertical agent well, you can fork it.
Not copy-paste blindly.
You still need to customize the context, examples, approvals, voice, tools, and workflows.
But you are not starting from zero.
You might have 75% of the agent already done.
That changes the agency model.
You no longer need a full traditional department for every function before you can deliver a well-rounded marketing service.
One or two strong marketing engineers can run an output surface that used to require a much larger team.
But this only works if the agents are actually good.
It takes iteration, taste, source material, QA, workflow design, and real marketing experience.
Bad agents do not become good because you connected more tools.
Vague agents just create vague output faster.
TLDR:
> turn the agency’s knowledge into a brain
> turn repeated work into scoped agents
> turn each client into an isolated pod
> let skilled operators run the system

61
134
1,403
185,765
Edwin K retweeted

Jun 5
Yes. You need a centralized way to host and version skills.

33
43
742
163,962
Edwin K retweeted
2 Sep 2025
Something I just told a founder: Stay as small as you can for as long as you can. People who come to visit your office should always be surprised that such an important company has so few employees.
266
865
11,285
710,339
Edwin K retweeted

5 Jul 2025
Looking for a product designer for a self-funded AI health company in Berlin, please DM if you are looking for a job. 🫡
11
8
58
10,999

Andrej is the best
25 Jun 2025

1 for "context engineering" over "prompt engineering".
People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step. Science because doing this right involves task descriptions and explanations, few shot examples, RAG, related (possibly multimodal) data, tools, state and history, compacting... Too little or of the wrong form and the LLM doesn't have the right context for optimal performance. Too much or too irrelevant and the LLM costs might go up and performance might come down. Doing this well is highly non-trivial. And art because of the guiding intuition around LLM psychology of people spirits.
On top of context engineering itself, an LLM app has to:
- break up problems just right into control flows
- pack the context windows just right
- dispatch calls to LLMs of the right kind and capability
- handle generation-verification UIUX flows
- a lot more - guardrails, security, evals, parallelism, prefetching, ...
So context engineering is just one small piece of an emerging thick layer of non-trivial software that coordinates individual LLM calls (and a lot more) into full LLM apps. The term "ChatGPT wrapper" is tired and really, really wrong.
1
259