
54 Photos and videos













eimen retweeted

Jun 15
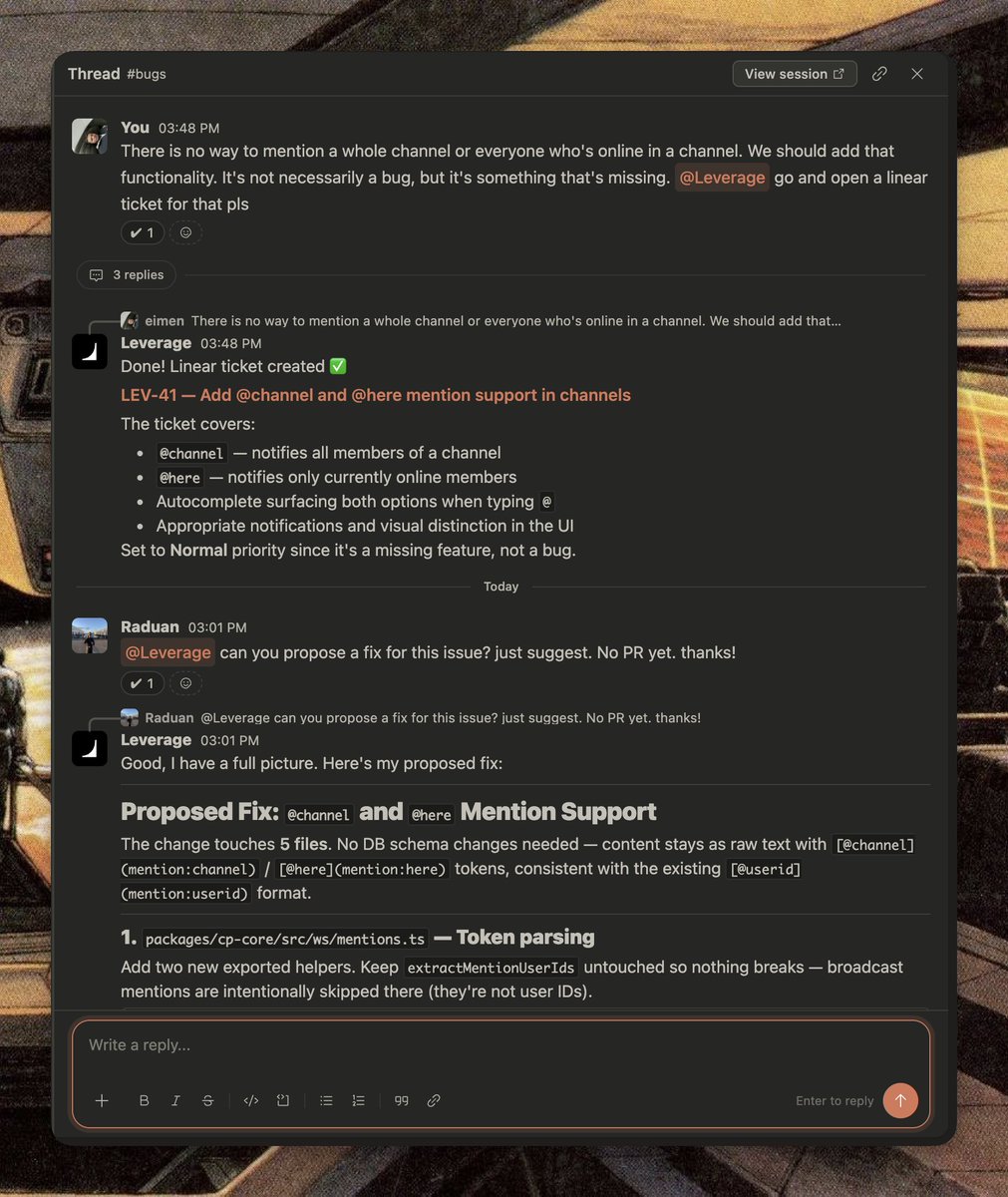
Token capital. Queryable institutional memory. Private traces from inside the org. A loop that compounds and stays yours across any model.
Satya just wrote about what we are building at @leveragecpu for quite some time now...


1
5
244

Idk about looksmaxxing, but human <> human is pretty obviously getting more valuable atm, not less. Everyone selling "fully autonomous business in a box" is racing each other to zero. Once anyone can spin one up, the business is worth what it costs to copy, which is basically nothing. And the value moves to whatever stays scarce. and the one input you can't synthesize is a verified human on the other end. opposite of artificial is natural

Tyler Cowen's recent talk on what will matter post AGI was really good.
Buy: embodiment, physicality, charisma, looksmaxxing, taking the initiative
Sell: writing, being a managerial elite, universities




1
5
115
this is exactly what we’re building at @leveragecpu
a multiplayer AI computer where company communication, files, code changes, agent runs, tool calls, decisions, and memory live in one governed workspace
the company should be readable and executable by humans agents at the same time
Jun 11

Increasingly, I believe companies may need to be rebuilt from the ground up, where you have a single timeline of all observability product metrics file changes laid out in a retrievable system, like Datadog Posthog Google Drive Slack (really unified filesystem of Claude Code chats Codex chats). This might be the new data foundation for any and all companies to maximize AI. Needs to be rebuilt because keeping track of diffs on existing system basically impossible to produce longitudinal information on decisions and rollbacks, something coding agent storage companies are actively trying to figure out, but this should extend to businesses as a whole.
Highly skeptical existing businesses will adopt this though because it means overhauling everything about their instrumentation and business data, but I think businesses built on this foundation probably can execute 100x better and faster
1
1
12
2,445
you're looking for @leveragecpu
Jun 11
Increasingly, I believe companies may need to be rebuilt from the ground up, where you have a single timeline of all observability product metrics file changes laid out in a retrievable system, like Datadog Posthog Google Drive Slack (really unified filesystem of Claude Code chats Codex chats). This might be the new data foundation for any and all companies to maximize AI. Needs to be rebuilt because keeping track of diffs on existing system basically impossible to produce longitudinal information on decisions and rollbacks, something coding agent storage companies are actively trying to figure out, but this should extend to businesses as a whole.
Highly skeptical existing businesses will adopt this though because it means overhauling everything about their instrumentation and business data, but I think businesses built on this foundation probably can execute 100x better and faster
3
968
and that's why we're building @leveragecpu

i am having more fun than ever collaborating with people
get an agent in the mix, we all bounce ideas off each other. prompt it, get more ideas. narrow in on something
stop dooming about ai and your job and start gangprompting
2
57

🤣
Jun 8

if you’re still writing loops that prompt coding agents you’re falling behind. you need to build a meta agent that infers what loops you would have wanted based on your vibe and then write those loops
1
29
you're looking for @leveragecpu
Jun 6

I want some kind of LLM workflow tool.
• Ability to manage a set of input files (Markdown or similar), plus other general-purpose context.
• With real-time collaboration. (And maybe some concept of snapshots or VCS integration.)
• And the ability to create/manage a inference workflows and a stored set of prompts.
• Access to general-purpose coding agents (and not just chat models).
• Some concept of compiled outputs/inference results (which ideally can be shared externally).
Many projects have this feeling: "there is all this stuff, which I want to process/compute over in this iterated way, with some build artifacts being important/worth saving." GNU Autotools x Notion or something. Is anyone building this?
3
83
you're looking for @leveragecpu
Jun 4

billion-dollar company is the Vercel for internal agents.
an employee writes a Claude Code agent, hits deploy, and gets hosting plus a Convex database in one click.
IT scopes what it can touch, watches every execution, and tracks token spend per agent
4
101
One small @leveragecpu workflow I like a lot:
You make a channel for interesting links. Stuff like articles, tweets, customer examples, competitor launches, whatever is relevant to the business.
Then an automation watches the channel and periodically turns the best stuff into content drafts, saves them in Google Docs, and links back to the agent session so the team can see how it got there.
It sounds stupidly simple, but this is the kind of multiplayer AI workflow that actually feels useful to many people.
Just drop things where the team already talks, and let the workspace turn shared context into work.
2
2
270

eimen retweeted

Jun 2
Great work by @Vtrivedy10 @nikogrupen et al - great to see these results in Law, mirroring our experiments published yesterday in Medicine
1. Batch grading reduces cost by ~1 OOM
2. Small models reduce cost by ~2 OOM
In non-verifiable RL, where judge latency blocks samples reaching the trainer, judge selection is a crucial knob for training efficiency.
Medicine:
x.com/bertgodel/status/20614…

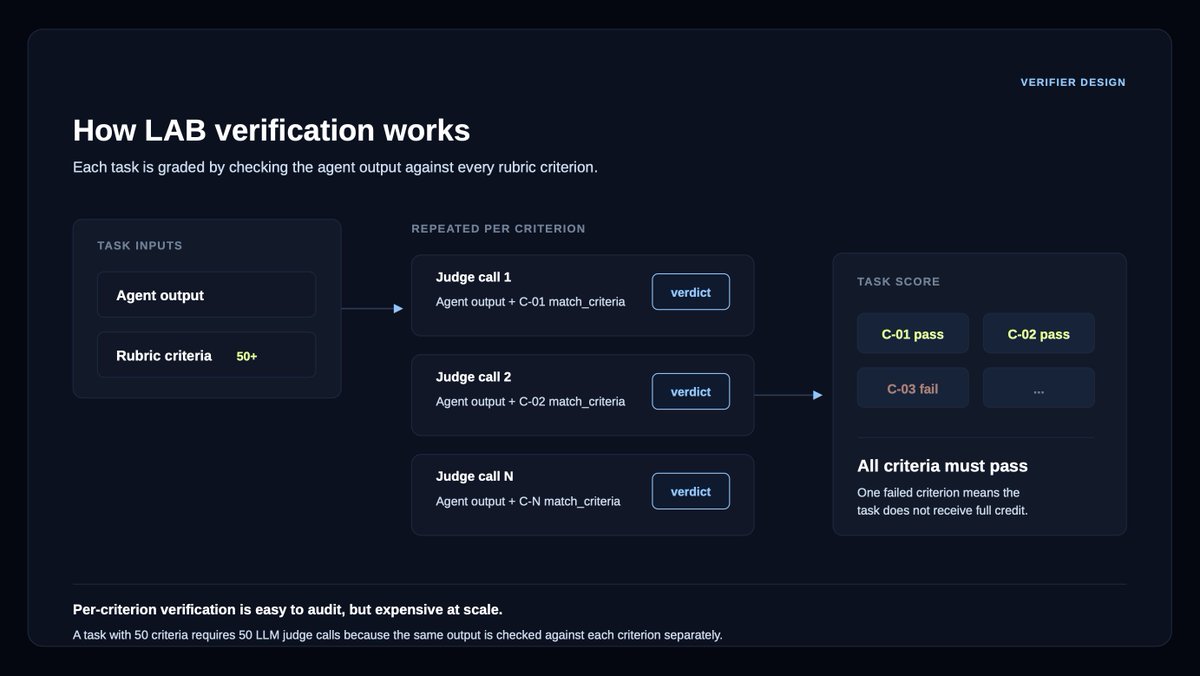
Can we design legal agent verifiers that are up to 1,000x cheaper?
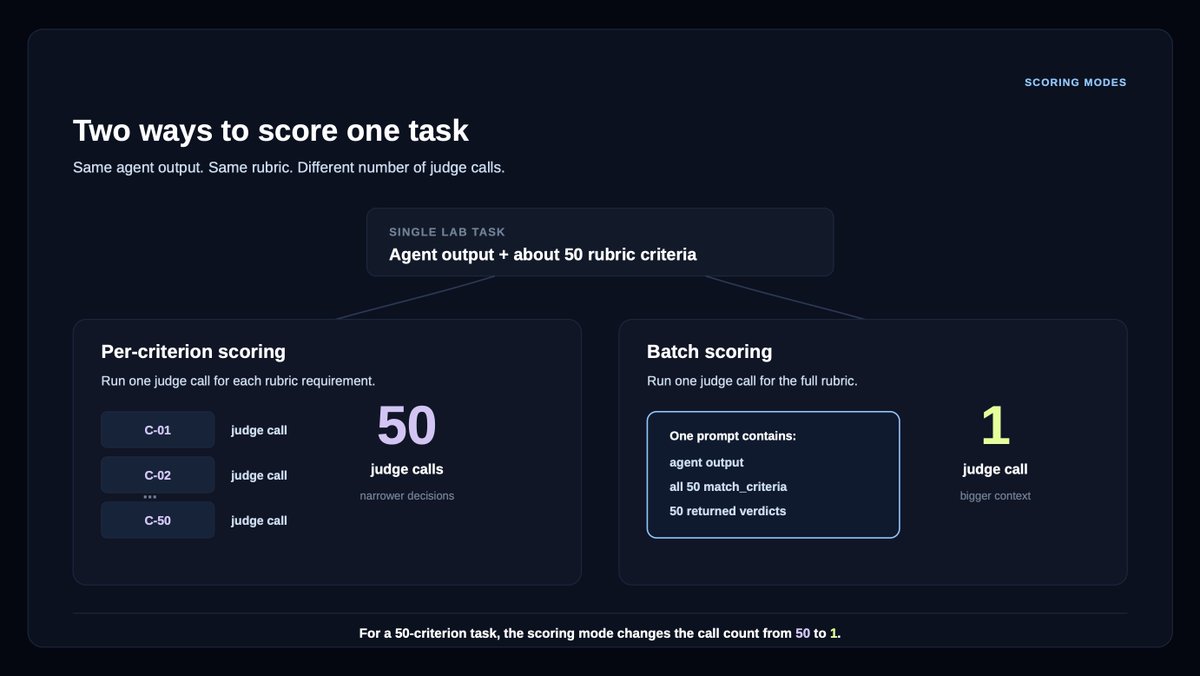
Verifiers are LLM judges that check an agent’s work against rubric criteria: they're used both in agent benchmarking and as reward signal in post-training.
But verifiers can be a bottleneck at scale.
For example, our Legal Agent Benchmark (LAB), comprising 1,200 legal tasks across 24 different practice areas, requires grading an average of 50 rubric criteria per answer.
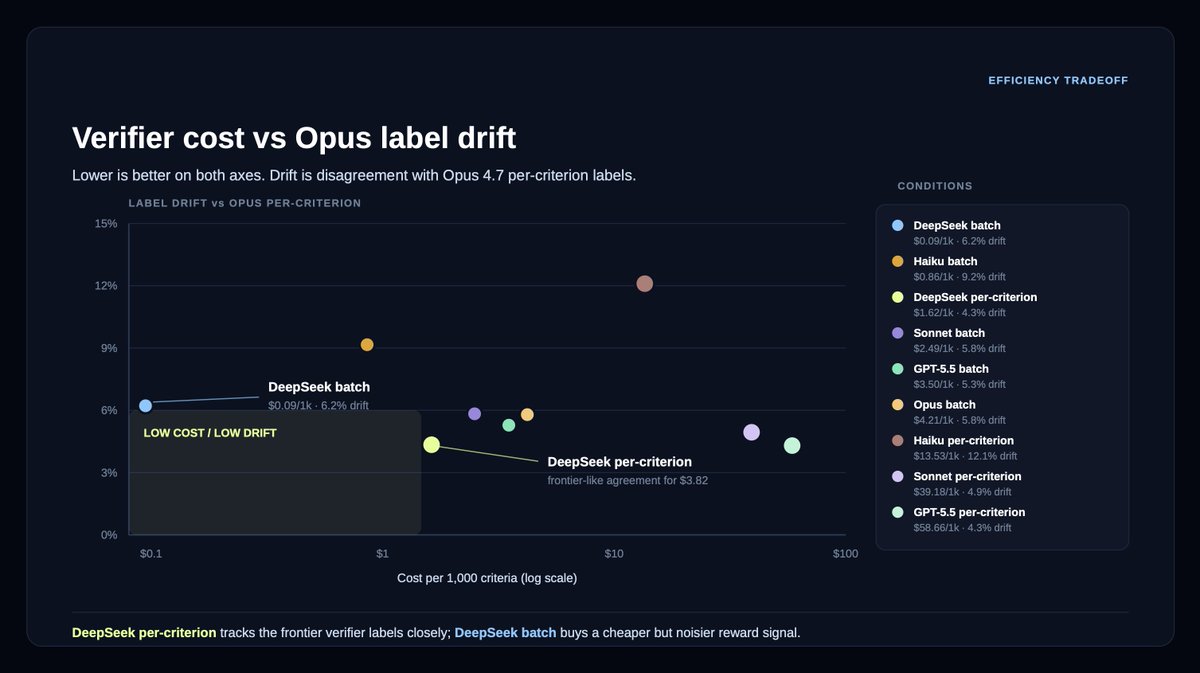
We partnered with @LangChain Labs to design more efficient verifiers for LAB, comparing batch vs per-criterion scoring and open/cost-efficient models against Opus 4.7.
The results were surprising:
DeepSeek v4 Flash preserved much of the Opus 4.7 verifier signal with 94-96% agreement, between batch mode and per-criterion mode.
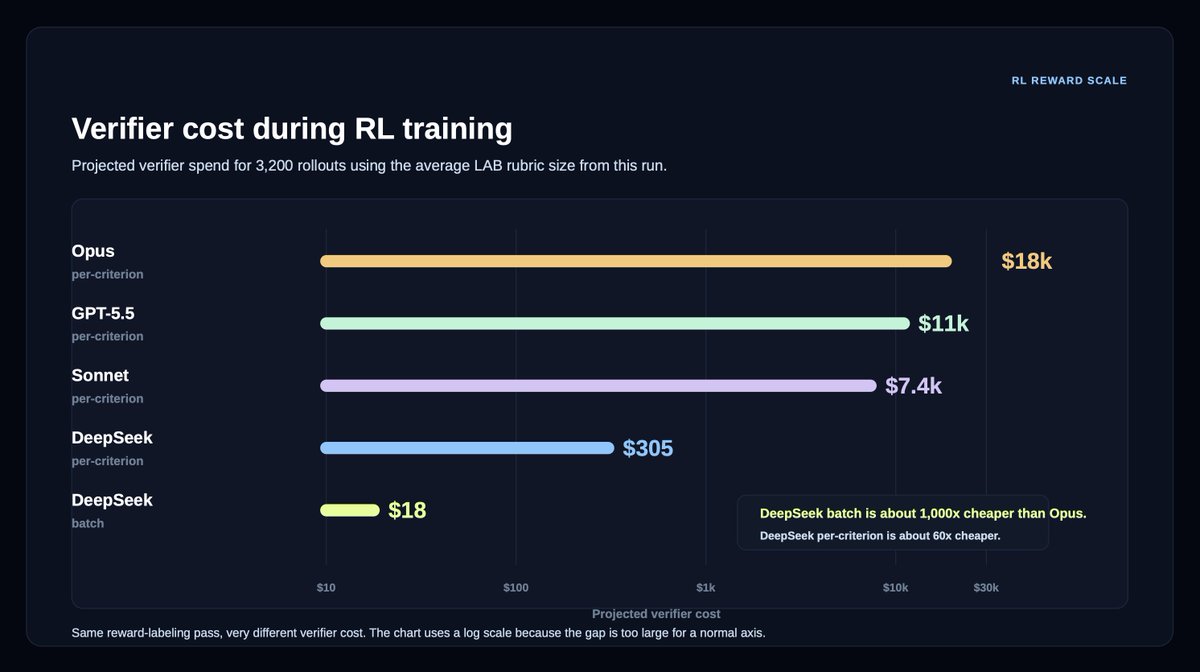
This came with a massive reduction in cost: 18x cheaper on per-criterion verification, and ~1,000x cheaper on batch verification.
In an RL setting with 3,200 rollouts, the cost of verification drops from $18,000 to $18.
1
9
23
3,282
eimen retweeted
Jun 1
New post: “Notes on Choosing a Rubric Judge”
A practical cost/latency/performance question: Given a well-specified rubric, how strong does your grader model need to be for evaluation and RL?

1
10
41
5,197
eimen retweeted

May 30
🤳 Agentic OS for a Phone
A voice-first mobile OS. Users talk, agents answer, and they can take action across the phone.
cerebralvalley.ai/e/openai-v…
28
54
729
147,649