
70 Photos and videos













Building towards a better future with AI requires building in the open

1
35
great read

RL environment companies were never meant to sell to labs forever. It is undeniable what cost economics will be produced by the unit cost of intelligence decreasing, but that it is still confined to a mere 10% of GDP and sophisticated engineering companies, mean that all AI infrastructure companies doubtlessly have inane customer concentration. The TAM expansion by natural knowledge dissemination will be, by default, slow, without innovation in the deployment side.
Its time to leave the nest and explore the wider ocean. Still, 80% of enterprises have never touched AI to a meaningful degree. The deployment surface for app layer companies remain extremely forward deployed in a cost prohibitive way - meaning that barring regulated industries where the unit cost of white collar work is extremely high - justifying FDE costs - average white collar work remains untouched. Its not that the work is not increasingly susceptible to the productivity gains first seen with coding - its just that there are material unscalable unit AI engineering time costs that are just not cost economic to be placed with Midwestern accounting firms.
The notion that these companies ought to enter the mainstream use cases also condemns the RL environment companies that do not draw their data from realistic sources. Those that increasingly create “toy” financial models to parse out things that frontier models are poor on, will not create generalizable post training infrastructure of off the shelf datasets that will allow for easier implementation of an RLaaS contract.
There are many useful problems that one learns to do well in being data connoisseurs. Here is a laundry list of these notions, which include:
One figures out how training data is an attack vector, especially in light of premature mech interp solutions in market (looking at you Goodfire), and is able to offer offensive and defensive solutions
One figures out how mixing recipes and offering specific datasets can lead to “selling smaller capabilities” to enterprises who’ve internalized some small model training as a product strategy.
One figures out how to optimize separating necessary human feedback and work artifacts and the autonomous creation of training materials for AI such as to create the most efficient processes to create personalized app layer products
One figures out how to “hire” and “recruit” agentic labor exceedingly well for a new era of labor economics where human labor oversees pools of hired machine labor for white collar tasks, in effect becoming a new class of “recruiters”
As we speak - whether they like it or not - data companies are getting pulled to real world businesses because they are the last and only vectors of good training data. We will see breakouts in 2026 who will be producing free versions of quickbooks, seeding new firms to owner-operate in virgin services markets from the ground up, and seeking to capture the layer of the value chain where all value accrues - the increased output of services from efficient model selection at the performance/cost/latency curve.
1
26
Laguna XS.2 is free to train on Prime Intellect Lab this month.
you know what to do

This month, Poolside’s Laguna XS.2 is free to train on Prime Intellect Lab. First come, first serve while reserved capacity lasts.
2
57
saudade retweeted

Jun 3
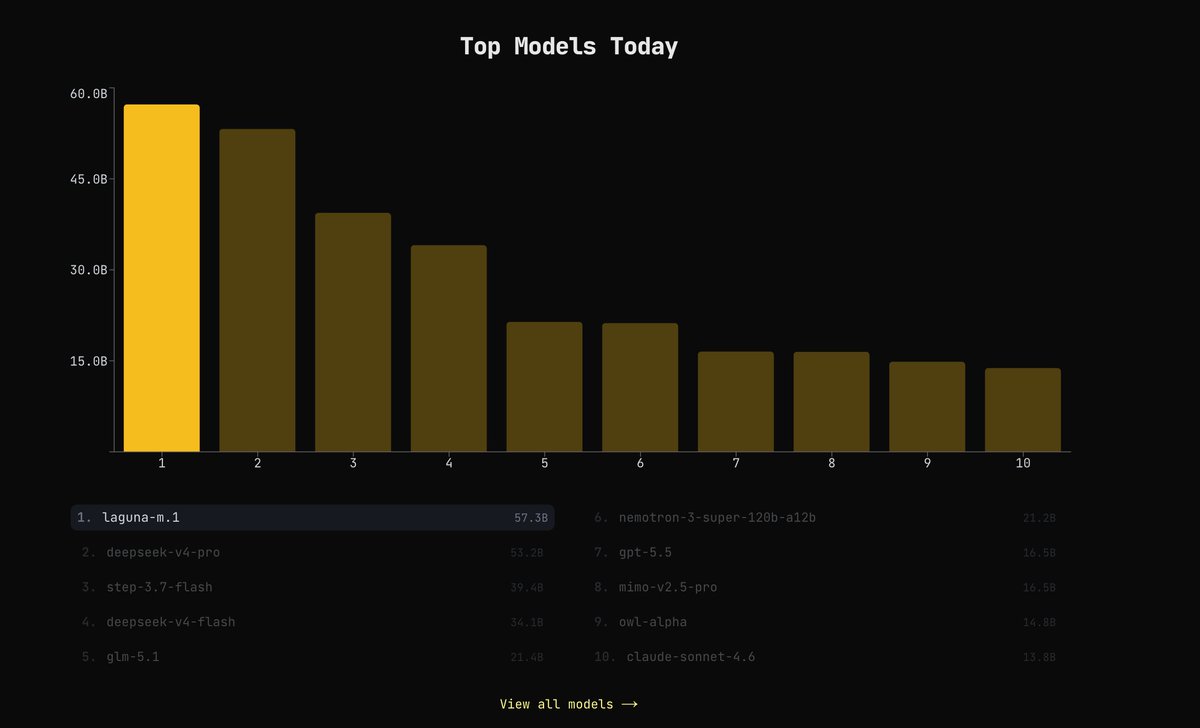
Laguna M.1 is #1 on @kilocode today.
Good to see Laguna getting put to work.
1
5
42
3,898
Over the moon about our first ever research hack at Poolside 💙
Shout to all the participants, partners, and ofc @poolsideai team who made it possible!
May 30

What a weekend. Around 30 teams showed up to build on Laguna XS.2, and the bar was very, very high.
Winners below 🏆
1st: Overthinking Machines Labs
@emilfristed
Pseudo-full-duplex with text-only models through dialogue modeling with silence tokens.
huggingface.co/spaces/poolsi…
2nd: Coding Kernels by the Pool
Charlie Masters, Evan O’Leary, Jessica Mak
Laguna-Dense: a ~3B fully dense distillation of Laguna XS.2 for generating CUDA kernels from PyTorch.
huggingface.co/EvanOLeary/la…
3rd: attnvq
@alaradirik
Attention-aware product vector quantization of KV caches.
huggingface.co/spaces/adirik…
Honorary mention: Laguna Vision
Aaron Kazah @aaronkazah
A SigLIP vision encoder resampler LoRA adapters, trained on 300k examples to give Laguna XS.2 a native visual input path.
huggingface.co/poolside-lagu…
Huge congrats to the winners, and thank you to everyone who hacked, demoed, judged, helped, and pushed Laguna XS.2 in directions we would not have found on our own!
@nvidia @PrimeIntellect @adaption_ai @huggingface




6
131
saudade retweeted
May 26
Today we’re publishing the technical report behind Laguna M.1 and Laguna XS.2.
This report opens up more of what went into them: Model Factory, pre-training data, distributed training, post-training, agent RL, quantization, and evaluation.
poolside.ai/assets/laguna/la…

15
87
423
304,935
even Greg gets it
coding agents belong poolside
curl -fsSL downloads.poolside.ai/pool/i… | sh
May 23

good location to build
99
saudade retweeted

May 22
Super pumped for the @poolsideai research hackathon on the 29th. Will be a great crowd, but ngl worth going just for a shot at winning the DGX Spark...

2
2
13
784
ok but you could simply
come to London next Friday
play with Laguna XS.2 weights
build smth cool
win the interesting little guy
go home and keep tinkering
seems like a good weekend to me
luma.com/poolsidehackathon


1
3
222
run your own research lab over a weekend!
May 15
setup hell kills good RL ideas.
so we’re giving researchers Laguna XS.2, @PrimeIntellect Lab, and a weekend in London to run the whole loop:
tasks → evals → rewards → training → rollouts → adapters → inference
14 days to go.
come touch the weights:
luma.com/poolsidehackathon
1
5
319
Just move to London.
May 14

King’s Cross is the Silicon Roundabout of AI ft.trib.al/Tp7pzqn | opinion
1
4
208
saudade retweeted

May 13
“train a custom 30B MoE agent model with reinforcement learning in a real harness” is now easy and cost-effective enough that it can be a hackathon format
May 13

we need to see more and more of hacks like these.
non slop, and real contributions that can be used after it, rather than dumped!
12
17
284
20,356
tbh I have never had a job that gets only more and more exciting every week 💙
@poolsideai is a rocket ship 🚀
1
64
Londonmaxxing is so back.
Cracked researchers, come build with usss 👾
May 13
Poolside is hosting a 2-day model research hackathon in London.
Join us to push an open-weight agent model as far as you can. RL and fine-tune Laguna XS.2, our latest-generation model, on Prime Intellect Lab.
Dates: May 29–30
Partners: @nvidia @PrimeIntellect @huggingface
Prize: NVIDIA DGX Spark
Agents need better models.
Better models need cracked researchers.
Link below.
2
2
11
1,301
found it very useful as a soft non-technical extrovert

1
4
206
officially obsessed
Apr 23

you asked for it. so we made it.
say hi to siliconmania.tv/weekly
each reference of the weekly tech recaps. explained.
its finally time to understand all of them. enjoy.
2
98