
Building whryte.com, Creator of localGPT | AI Educator
Joined July 2023
- Tweets 1,065
- Following 1,265
- Followers 2,197
- Likes 2,991
296 Photos and videos










Pinned Tweet

16 Jul 2025
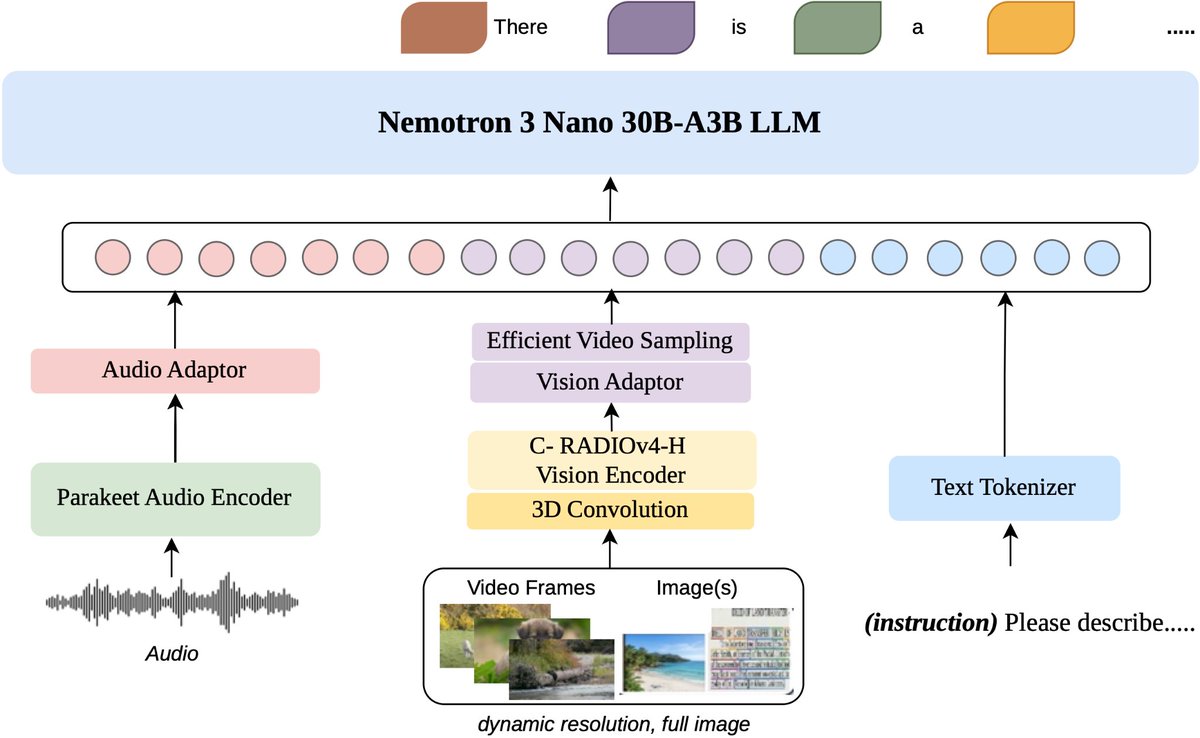
Yesterday I released the 'preview' of LocalGPT v2, and its already trending on Github
Its an opinionated implementation of private RAG powered by local models via @ollama and @huggingface. Give it a ⭐️ on @github (🙏🙏)
Watch the video in next post to learn how it was built...

2
23
2,306
This is great BUT as always no one is actually reading what the actual setup was and what is the experiment.
Fusion of models achieves Fable level performance at half the cost on deep research NOT on coding.
Ensemble models tend outperform individual learners on similar tasks!
Jun 13

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

1
3
509
Jun 13
Wow, does this mean we are not going to see capable models from any lab?
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
2
141
Jun 11
There are three kinds of lies: lies, damned lies and statistics/(now benchmarks!).
1
56
Jun 10
This looks pretty awesome.
Jun 10

Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
2
112
Jun 10
.@datacurve when can we see Fable on DeepSWE?
May 30

Opus 4.8 is now on DeepSWE.
On the default high thinking effort, it scores 6% higher than Opus 4.7 xhigh, while also lowering average cost per task.
2
307
Jun 5
This is a fascinating read from @AnthropicAI on self-improving systems.
"Similarly, once Claude can run experiments, the question shifts towards “Which of these experiments is worth running?” Put simply: the doing (i.e., writing the code, running the experiment, producing the result) now costs almost nothing in human time, even if it still has costs in compute."
Jun 4
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. anthropic.com/institute/recu…
2
127
Jun 1
I like how @OpenAI is becoming more like @AnthropicAI in model capabilities and @AnthropicAI becoming like @OpenAI for resetting week rate limits!
Competition is a good thing!
Jun 1

We've reset 5-hour and weekly rate limits for all users on Pro and Max plans.
We fixed an issue that caused some Claude Code sessions to spawn excessive parallel subagents, burning through usage faster than expected.
2
248
Jun 1
This is a fun little recap of everything that was announced last night by @nvidia

CEO Jensen Huang took the stage at GTC Taipei and redefined the future of AI.
He unveiled AI infrastructure running the world's AI factories, autonomous agents that actually do things, physical AI and robotics stepping into the real world, and a brand-new generation of personal computing built for AI from the ground up.
If you're curious where AI is actually headed, this keynote is your answer.
📰 Get the recap: nvda.ws/43CpTw2
▶️ Watch the full keynote: nvda.ws/3RFttD0
#NVIDIAGTC
2
121
Jun 1
Nemotron 3 Ultra looks pretty exciting!

3
210
Jun 1
A really strong release from @MiniMax_AI

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

2
93
May 28
Testing new models is the same game as writing a research paper: torture the setup long enough and it confesses whatever you want.
That's why you see ten people run "honest" evals and land on ten opposite takes.
1
143
May 28
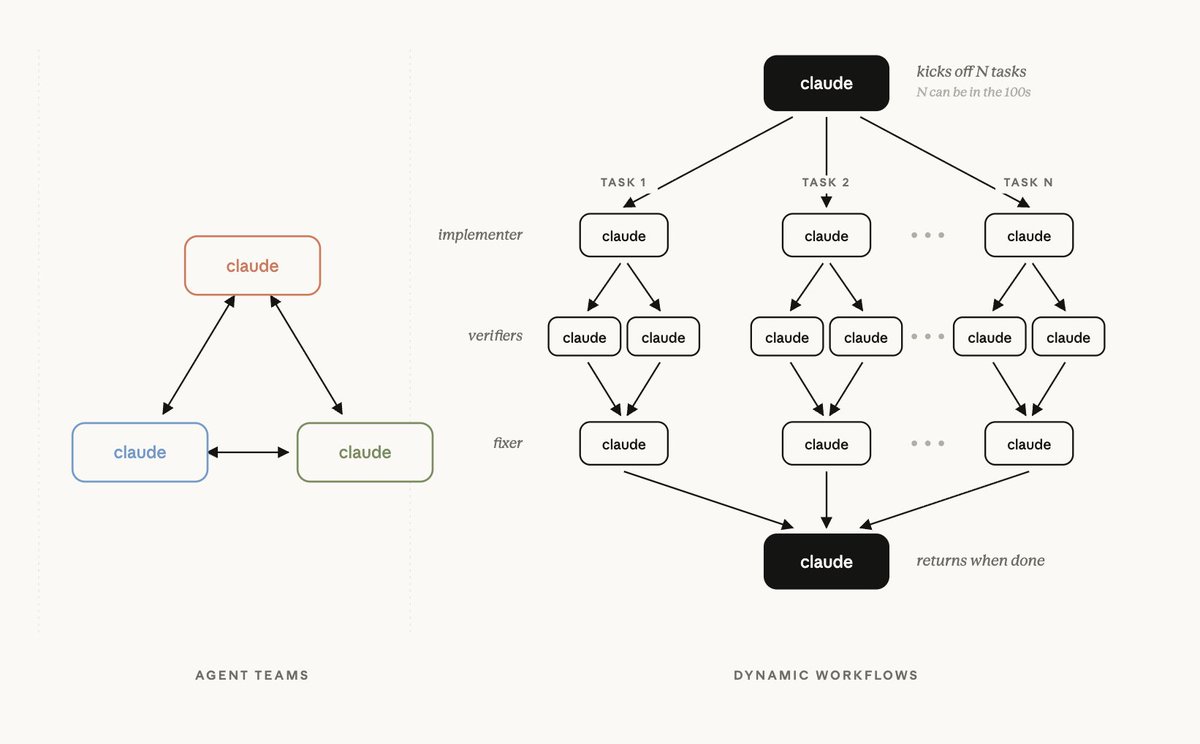
this is really neat and also RIP in weekly quota :)

Excited to share our most powerful new Claude Code feature: dynamic workflows!
Mention "workflow" in a prompt and Claude will dynamically create an orchestration plan that it strictly follows, allowing you to confidently trust that every stage happens in the right order even across 100s of agents.
2
192
May 22
DeepSeek-v4-Pro 75% discount is now permanent!
We are seeing an interesting trend.
Western frontier models keep getting more expensive and Chinese ones keep getting cheaper.
Either the compute constraints aren't as tight as we thought, or the efficiency gains on the algorithm and homegrown hardware side are actually working.
May 22

We are making our discount permanent! 🎉
Enjoy building with DeepSeek-V4-Pro and bring your innovative ideas to life! 🚀

2
249
May 19
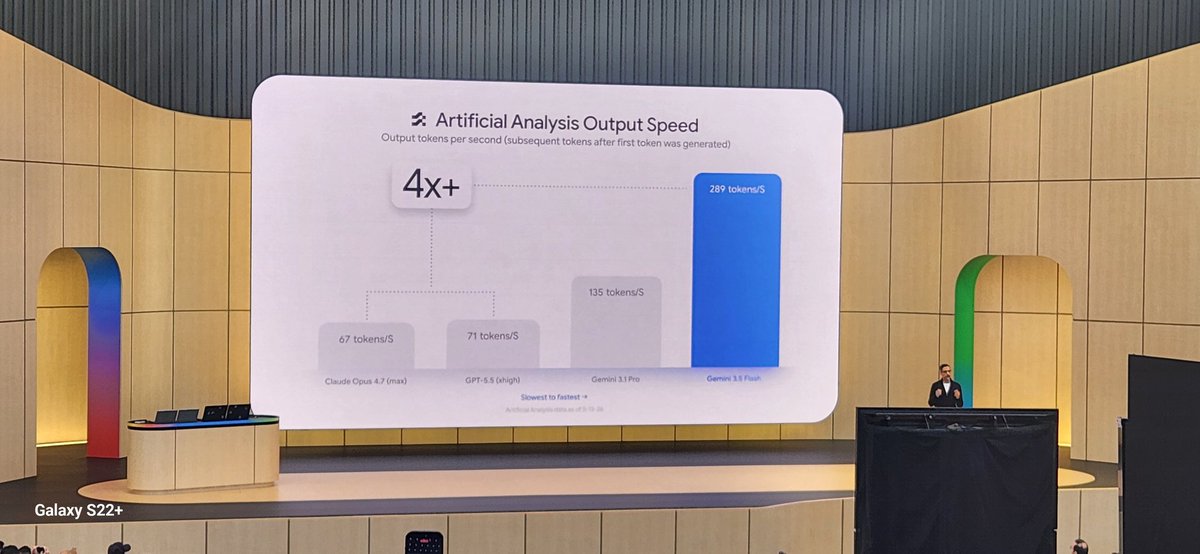
Gemini 3.5 Flash, first impressions. I had early access to the model, and it feels on par with Gemini 3.1 Pro Preview. The first GA release from Google in a while at announcement for a Gemini model. It's a good model but now is 3x expensive compared to previous Flash.
Here is the video: youtu.be/v1xqYZ3s23s
219
May 19
Gemini Flash is a really great model. It's fast and close to the frontier. I had early access to the model thanks to @GoogleDeepMind and it's a lot of fun to use. Give it a try!
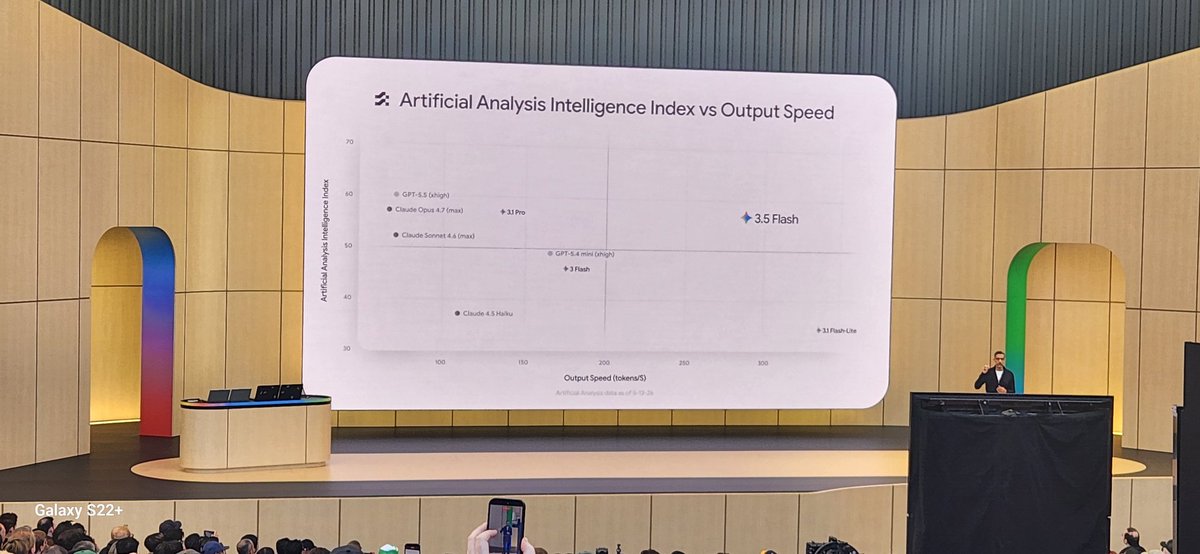


1
1
123
May 19
These are some really impressive numbers from Google on AI adoption.
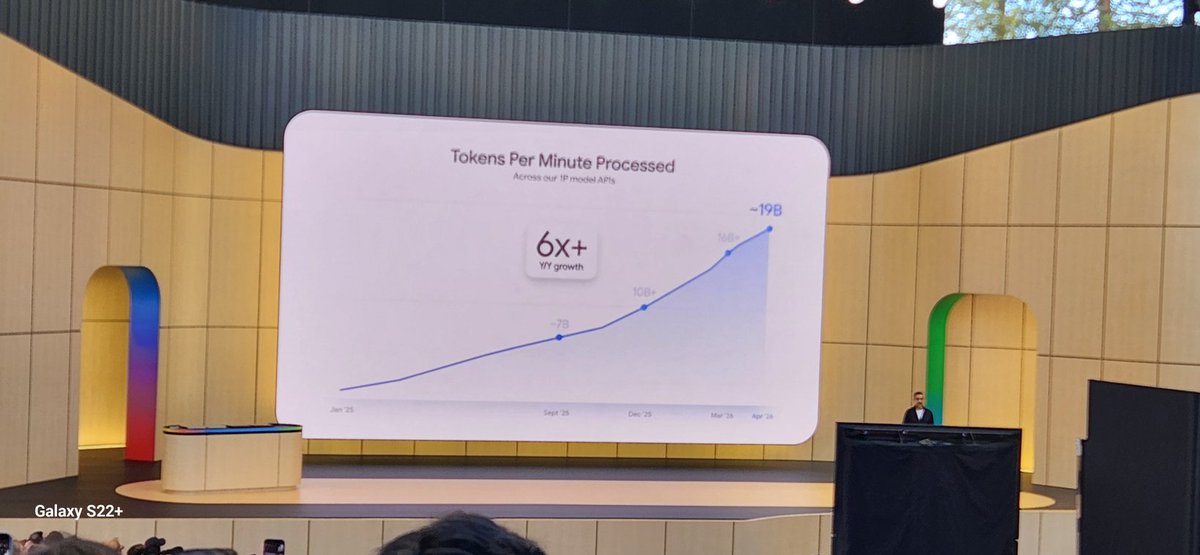
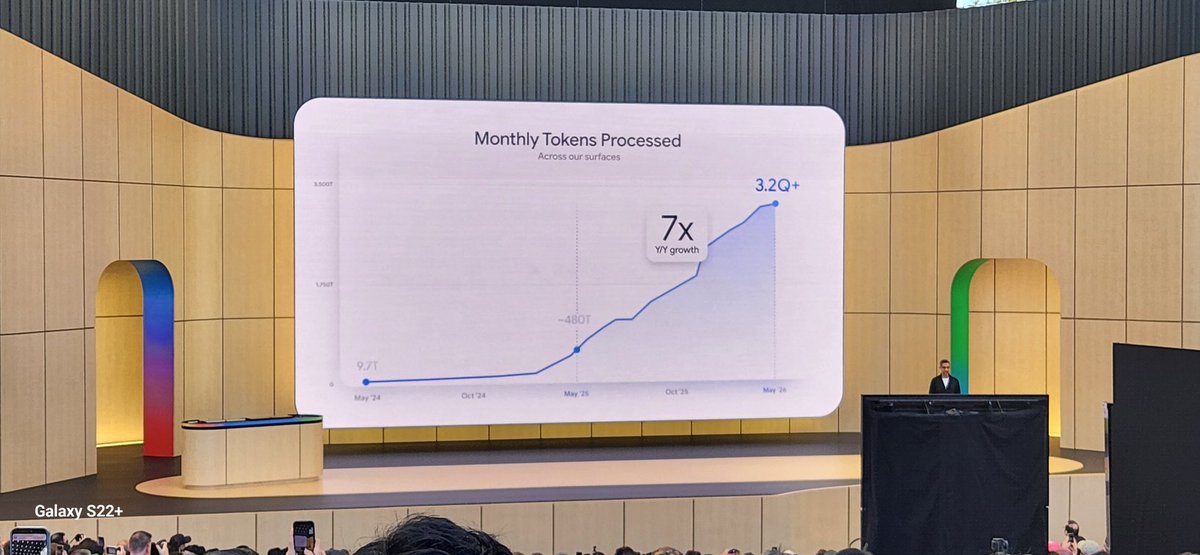
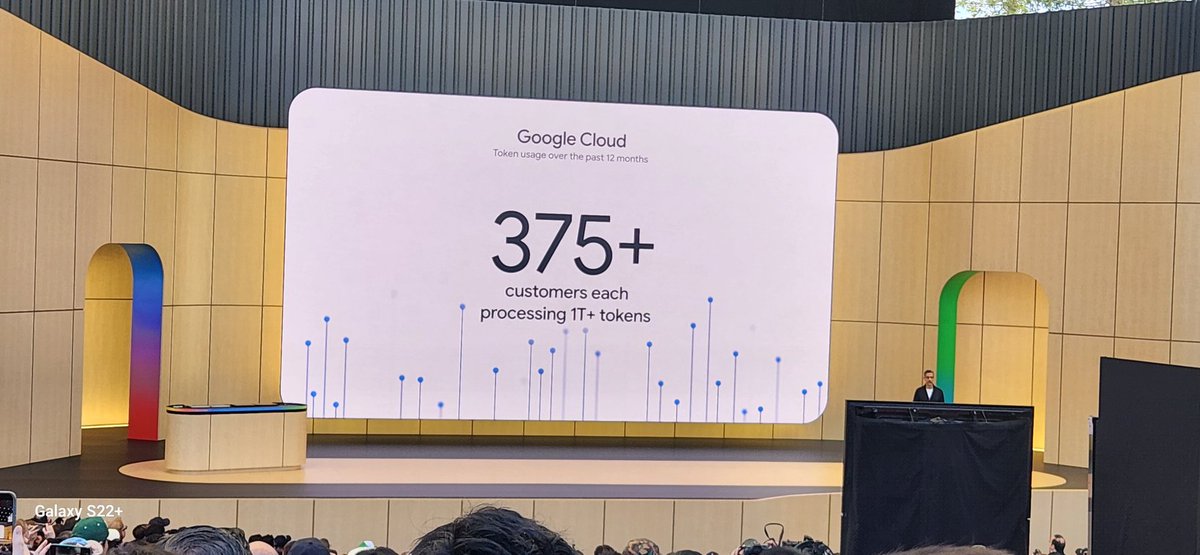
2
102