
98 Photos and videos









The future of AI is open source and decentralized
13 Sep 2024

"Exo's use of Llama 405B and consumer-grade devices to run inference at scale on the edge shows that the future of AI is open source and decentralized." - @mo_baioumy x.com/ac_crypto/status/18159…
33
112
941
434,367
EXO Labs retweeted

Jun 13
What are people using to run local inference on DGX Spark?
ollama? LM Studio? vLLM? sgLang? TRT-LLM?
Do you run in Docker?
@TheAhmadOsman @AlicanKiraz0 @spark_arena @NVIDIAAI @NVIDIARTXSpark
66
8
151
45,491
EXO Labs retweeted
Jun 11
Guess what?
local ai for everyone (: we did it
local.ai

99
79
1,664
140,697


EXO Labs retweeted
Jun 9
RDMA over Thunderbolt mentioned in WWDC Platforms State of the Union.
Proud to have played a small part in bringing this technology to the world with Apple / MLX through @exolabs.
The main characters are @angeloskath @awnihannun and Jack, who made this all happen.
5
16
133
8,671
EXO Labs retweeted

Jun 8
👀✨ localmaxxing
Jun 8

.@nvidia gave us all the hardware we need to make local AI awesome.
16 x DGX Spark
3 x RTX Spark
1 x DGX Station
24 x ConnectX-7 Cables
2 x High Speed Switches
local dot AI


2
3
57
9,564
EXO Labs retweeted
Jun 8
.@nvidia gave us all the hardware we need to make local AI awesome.
16 x DGX Spark
3 x RTX Spark
1 x DGX Station
24 x ConnectX-7 Cables
2 x High Speed Switches
local dot AI


143
116
1,662
265,980
Wonder what this might be
3
1
6
3,697

EXO Labs retweeted
Jun 1
A year ago at GTC, Jensen brought out a DGX Spark in one hand and a MacBook in the other.
Yesterday, at GTC Taipei, Jensen brought out NVIDIA's new RTX Spark laptop in both hands.
This is the start of a new era of personal computing - the personal AI era.
In the new era, there are two competing platforms:
- @apple with macOS / MLX
- @nvidia with Windows / CUDA
Everyone will have an always-on personal agent that runs locally, constantly looking out for you, working for you proactively, monitoring the internet and talking to other agents. This will be a personal AI agent you own, that's private, that's aligned with you (not OpenAI or Anthropic). @karpathy calls it personal computing v2.
Let's set the scene for the new era of personal computing by diving into the one thing that will matter the most - the hardware.
The best hardware for local AI isn't what's running in a data center. It's a radically different problem. Here's a breakdown of the 3 most important things:
1. Memory.
LLMs are big. To run a model locally, you need to fit the entire model into memory. Apple (with Apple Silicon) and NVIDIA (with DGX Spark RTX Spark) have both moved towards unified memory, which puts all the memory on one chip - leveraging cheaper LPDDR5X memory - useful for making more memory accessible to the GPU. The alternative competing architecture is a disaggregated CPU/GPU architecture - which is what the DGX Station uses. It has a large pool of slow LPDDR5X CPU memory (496GB @ 396GB/s), and a small pool of high-speed HBM3e GPU memory (252GB @ 7.1TB/s). It has a high bandwidth link (900GB/s) between the CPU memory and GPU memory, enabling fast disaggregated inference e.g. Attention on GPU, FFN on CPU. This enables running really large models like Kimi K2.6 (1T parameters) by offloading experts from CPU memory to GPU memory as they are needed. You could imagine something like this in a smaller form factor.
Hardware today:
- Apple M5 Max MacBook Pro: 128GB unified memory.
- NVIDIA DGX Spark / RTX Spark: 128GB unified memory.
2. Memory bandwidth.
In a data center, multiple user's requests can be batched together, which amortizes the cost of moving model weights into memory across many requests, pushing up arithmetic intensity to compute bound territory - meaning FLOPS matters a lot. Locally, everything runs at low batch size, which is low arithmetic intensity, i.e. memory bound - so FLOPS don't matter. What matters memory bandwidth. High memory bandwidth -> fast TPS. Low memory bandwidth -> slow TPS.
Hardware today:
- Apple M5 Max MacBook Pro: 617GB/s memory bandwidth.
- NVIDIA DGX Spark: 273GB/s memory bandwidth.
- NVIDIA RTX Spark: TBC.
3. Power.
In a data center, we talk about MegaWatts. Locally, we talk about Watts. Laptops have limited battery life. The best laptop batteries have a capacity of ~100Wh. LLM inference on a MacBook Pro consumes ~140W, meaning battery life with a persistent personal agent is less than an hour. This is unusable. The game will become how long can you run a useful agent on a laptop battery. Apple and NVIDIA will compete on how long an agent can run on battery - this will become the new battery life metric. This could be where an NPU or NPU/GPU hybrid really shines. Apple ANE has about 10x better power efficiency than the GPU on Apple Silicon (but has ~4-5x less memory bandwidth, with about the same FLOPS as the GPU). There will be an entire design space of how to build energy efficient agents - this will involve co-optimizing the harness, models, inference engines together.
Hardware today:
- Apple M5 Max MacBook Pro: Consumes 140W, battery capacity ~100Wh
- NVIDIA DGX Spark: Rated for 240W, consumes 140W. No battery (direct PSU).
- NVIDIA RTX Spark: TBC.
The hardware battle will be fierce, and I expect a move towards co-design, i.e. hardware designed *with* personal agent workloads. On top of this, models are improving, we're getting more intelligence per bit/watt, and open-source harnesses like @NousResearch Hermes / OpenClaw are improving rapidly. Within the next 2 years, we'll inevitably have unmetered, private Opus-4.8 / GPT-5.5 level intelligence running locally on a future version of a MacBook or RTX Spark. I like this future a lot better than the one where OpenAI / Anthropic control the intelligence layer of the internet and can rent-seek on intelligence.
Beyond this, NVIDIA is ahead on general AI ecosystem, i.e. the CUDA moat. Apple is ahead on local AI ecosystem, i.e. models quantized/rightsized for MacBooks, native macOS apps, and ease of setup. We'll see how this might change as the new RTX Spark also brings full native CUDA to Windows-on-Arm laptops for the first time, potentially closing the gap.
There are many other factors I haven't mentioned here, but I believe I've covered the timeless, most important things for the new era of personal computing.


45
56
519
108,335
EXO Labs retweeted
Jun 1
MiniMax M3 open weights coming next week! New frontier open weight model.
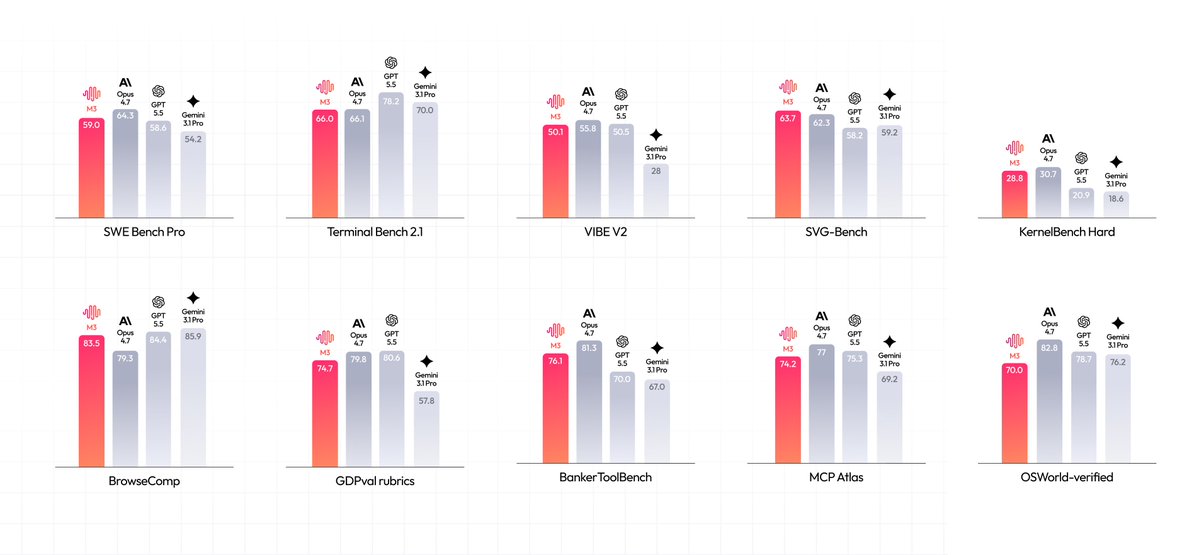


4
3
33
5,491
EXO Labs retweeted

May 26
I kind of got my @exolabs cluster working with my gaming PC this weekend. It has a 3070ti that I wanted to take advantage of.
I wrote about it and the process that led me to wanting to try this.
You can skip to second part entirely, my ADHD over explaining got the best of me here😅
x.com/michaelharrigan/status…
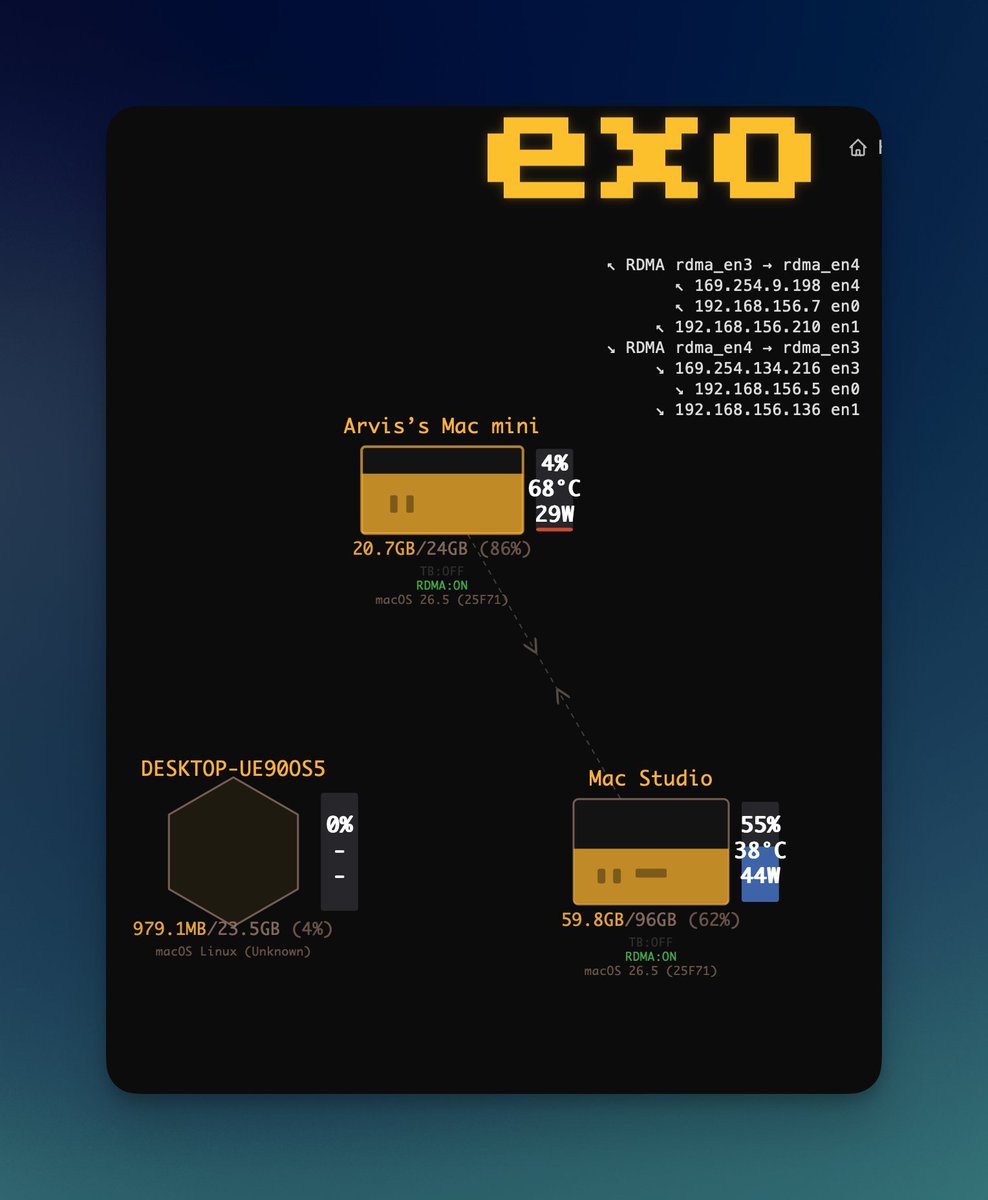

2
1
22
3,731
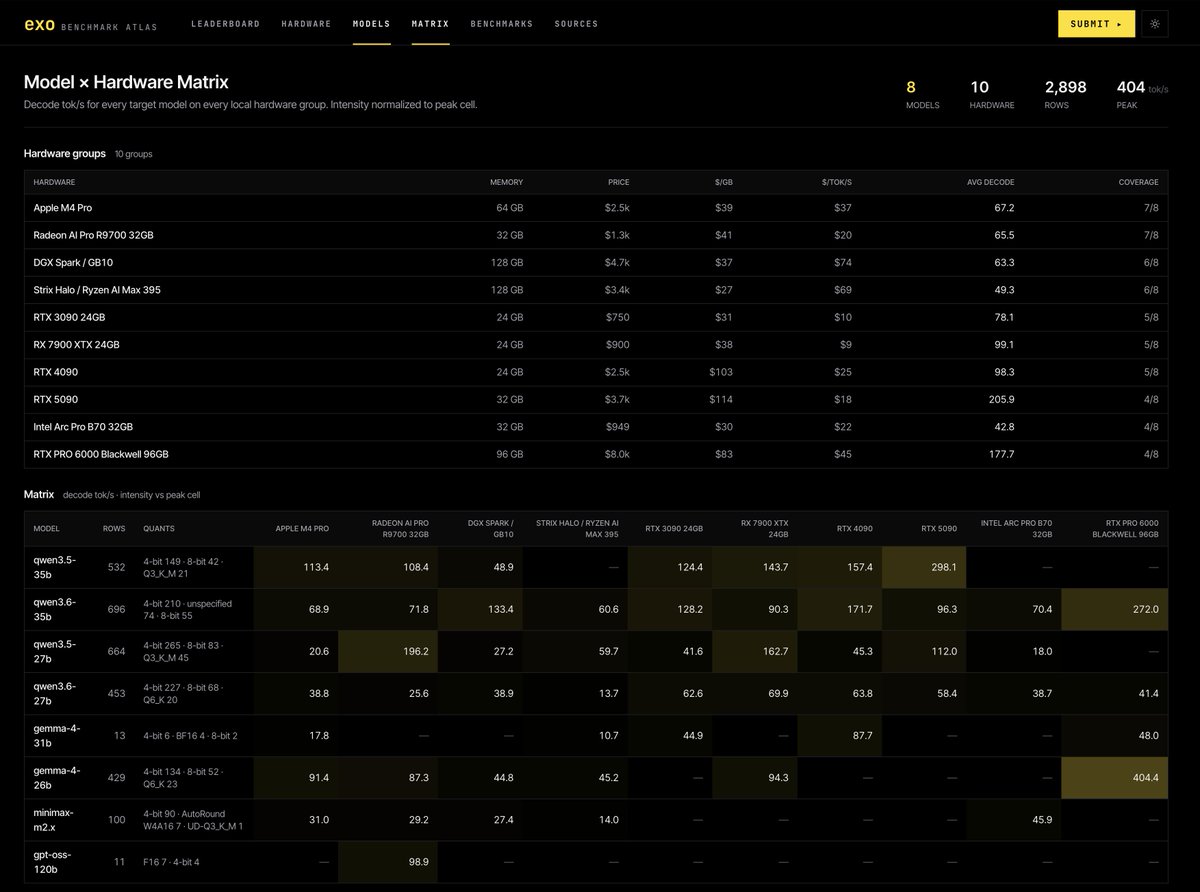
This is a small slice of the kinds of insights Exo will provide soon, we are working on validating the data.
- Common local AI hardware
- Model quantisation as key
- Peak decode tok/s per configuration
- Ballpark dollar value per GB
How can we make this better for you?
14
8
89
16,845
EXO Labs retweeted

May 18
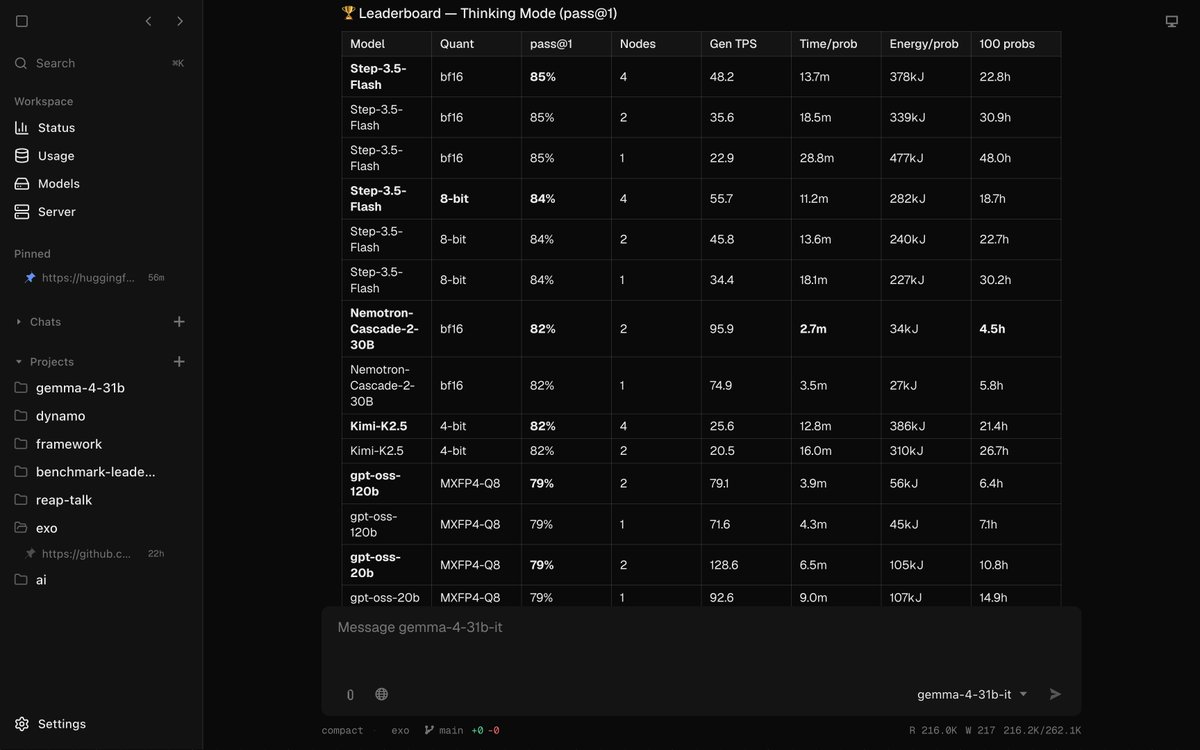
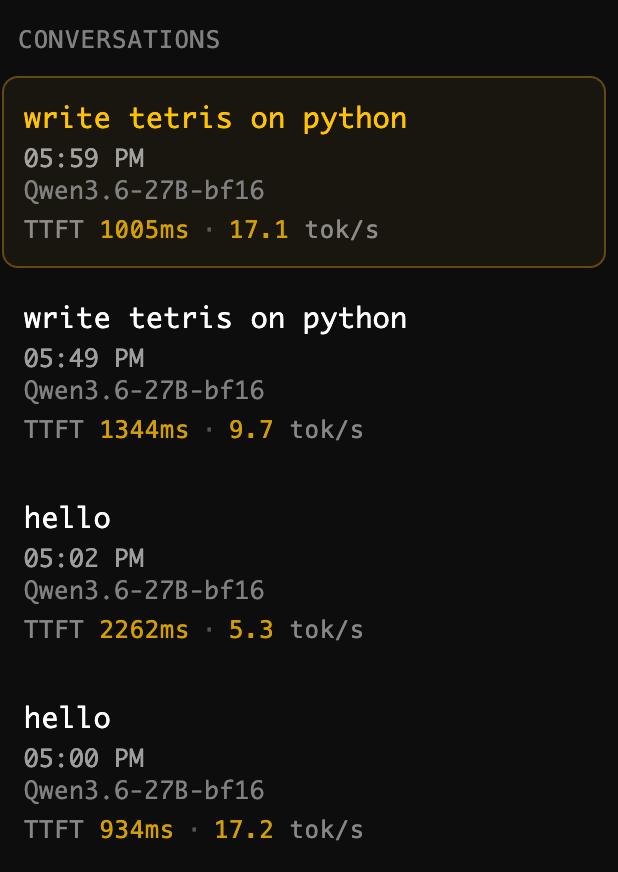
Some real-world test results.
1. 2-node model – simple coding
2. Single-node model – similar task
3. Single-node model – simple chat (Hi, what can you do?)
4. 2-node model – simple chat
As for the software @exolabs – it delivered the best results of everything I tested (but the choice for Mac OS isn’t great)
A 4-node cluster is next.
What’s really cool is that loading the model is significantly faster than on Spark (takes 15–20 seconds, rather than 5–10 minutes). But even with simple chats, the laptop starts making an obscene amount of noise.

8
2
127
11,642
We had to update our site to make what we're working on more clear.
You can now find our Discord, we will be running a weekly community education session starting the 24th of May!
exolabs.net
8
7
71
14,227