
I like animals and big ideas
Joined February 2011
- Tweets 1,196
- Following 1,565
- Followers 899
- Likes 2,949
93 Photos and videos













Adam Little DVM retweeted

Feb 20
Cardiologist wins 3rd place at Anthropic's hackathon. Out of 13,000 applications. Built in 7 days by Michał Nedoszytko MD. Coded day and night - in the hospital, in the cloud, while flying from Brussels to San Francisco.
A few years ago, it would have been impossible for a doctor to build this alone in just a couple of days. AI changed that.
The project is called postvisit.ai. It is an AI agentic care platform for patients. Including reverse AI scribe it is a companion that guides the patient from the moment they leave the doctor's office.
Powered by the massive context window of Opus 4.6, it allows patients to explore their full medical history, connected devices, Evidence Based resources and external data sources — all in one place.
Today, the barrier to entry has vanished; even a practicing physician can build an application from scratch.
525
2,403
20,659
3,589,224

GPT-5.2 derived a new result in theoretical physics.
We’re releasing the result in a preprint with researchers from @the_IAS, @VanderbiltU, @Cambridge_Uni, and @Harvard. It shows that a gluon interaction many physicists expected would not occur can arise under specific conditions.
openai.com/index/new-result-…
942
1,468
9,473
4,529,700


Adam Little DVM retweeted

20 Dec 2024
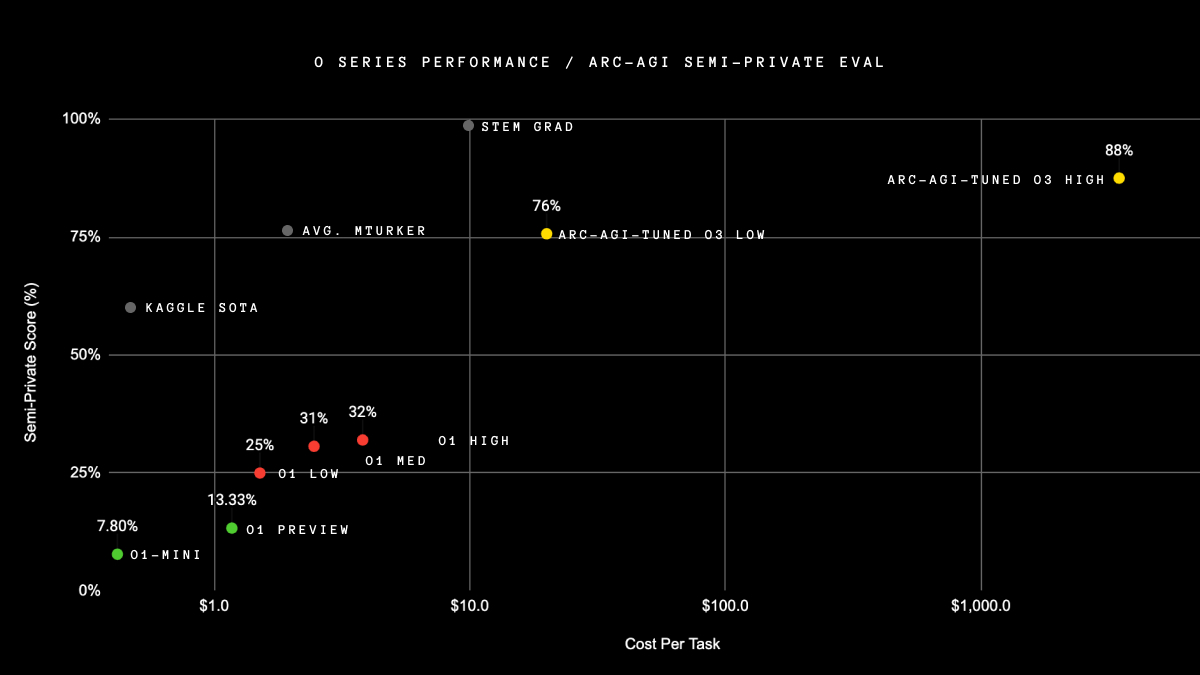
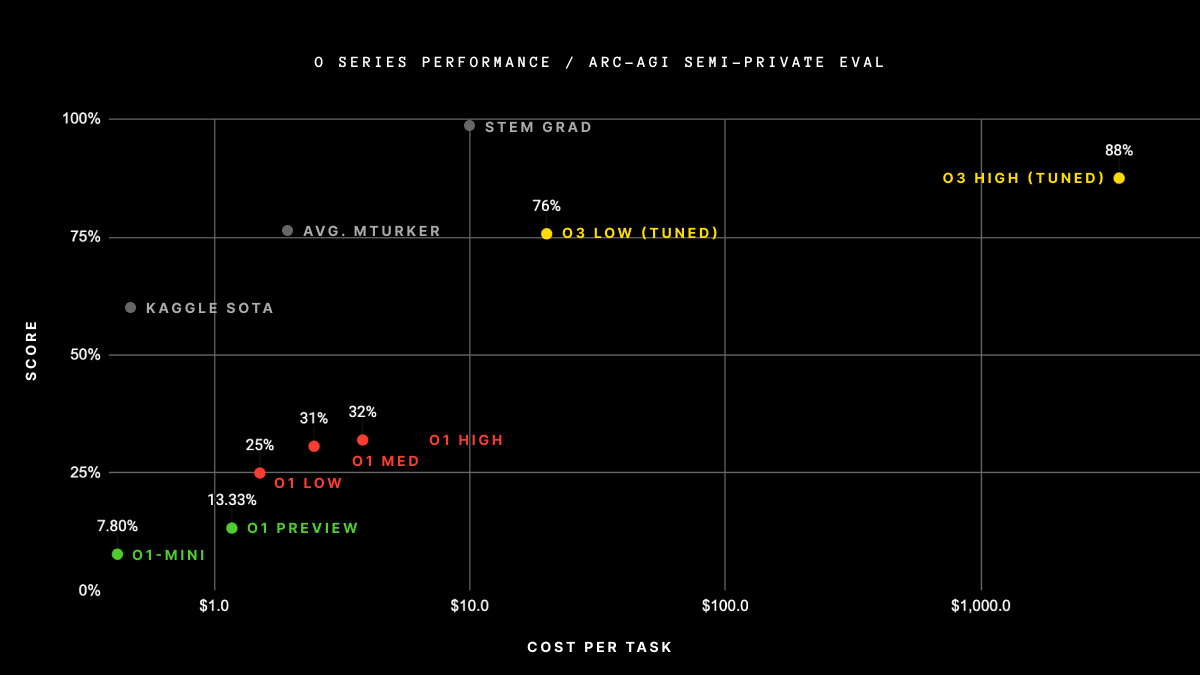
Today OpenAI announced o3, its next-gen reasoning model. We've worked with OpenAI to test it on ARC-AGI, and we believe it represents a significant breakthrough in getting AI to adapt to novel tasks.
It scores 75.7% on the semi-private eval in low-compute mode (for $20 per task in compute ) and 87.5% in high-compute mode (thousands of $ per task). It's very expensive, but it's not just brute -- these capabilities are new territory and they demand serious scientific attention.
202
1,563
8,640
2,226,694
Adam Little DVM retweeted

20 Dec 2024
o3 is really special and everyone will need to update their intuition about what AI can/cannot do.
while these are still early days, this system shows a genuine increase in intelligence, canaried by ARC-AGI
semiprivate v1 scores:
* GPT-2 (2019): 0%
* GPT-3 (2020): 0%
* GPT-4 (2023): 2%
* GPT-4o (2024): 5%
* o1-preview (2024): 21%
* o1 high (2024): 32%
* o1 Pro (2024): ~50%
* o3 tuned low (2024): 76%
* o3 tuned high (2024): 87%
given i put in the original $1M @arcprize, i'd like to re-affirm my previous commitment. we will keep running the grand prize competition until an efficient 85% solution is open sourced.
but our ambitions are greater! ARC Prize found its mission this year -- to be an enduring north star towards AGI.
the ARC benchmark design principle is to be easy for humans, hard for AI and so long as there remain things in that category, there is more work to do for AGI.
there are >100 tasks from the v1 family unsolved by o3 even on the high compute config which is very curious.
successors to o3 will need to reckon with efficiency. i expect this to become a major focus for the field. for context, o3 high used 172x more compute than o3 low which itself used 100-1000x more compute than the grand prize competition target.
we also started work on v2 in earnest this summer (v2 is in the same grid domain as v1) and will launch it alongside ARC Prize 2025. early testing is promising even against o3 high compute. but the goal for v2 is not to make an adversarial benchmark, rather be interesting and high signal towards AGI.
we also want AGI benchmarks that can endure many years. i do not expect v2 will. and so we've also starting turning attention to v3 which will be very different. im excited to work with OpenAI and other labs on designing v3.
given it's almost the end of the year, im in the mood for reflection.
as anyone who has spent time with the ARC dataset can tell you, there is something special about it. and even moreso about a system than can fully beat it. we are seeing glimpses of that system with the o-series.
i mean it when i say these are early days. i believe o3 is the alexnet moment for program synthesis. we now have concrete evidence that deep-learning guided program search works.
we are staring up another mountain that, from my vantage point, looks equally tall and important as deep learning for AGI.
many things have surprised me this year, including o3. but the biggest surprise has been the increasing response to ARC Prize.
i've been surveying AI researchers about ARC for years. before ARC Prize launched in June, only one in ten had heard of it.
now it's objectively the spear tip benchmark, being used by spear tip labs, to demonstrate progress on the spear tip of AGI -- the most important technology in human history.
@fchollet deserves recognition for designing such an incredible benchmark.
i'm continually grateful for the opportunity to steward attention towards AGI with ARC Prize and we'll be back in 2025!

New verified ARC-AGI-Pub SoTA!
@OpenAI o3 has scored a breakthrough 75.7% on the ARC-AGI Semi-Private Evaluation.
And a high-compute o3 configuration (not eligible for ARC-AGI-Pub) scored 87.5% on the Semi-Private Eval.
1/4
70
385
2,447
688,890

5 Sep 2023
Kicking off a new project as part of the 7th @100daysnocode No-Code x AI Bootcamp over the next 4 weeks!
#100DaysOfNoCode #100DaysOfAI
maven.com/no-code-ai/no-code…
2
13
159
Adam Little DVM retweeted

26 Dec 2022
Sign up here EmailTriager.com!
And if you want one of the 100 early access spots, comment/retweet then email me and I'll send you a test invite! 💌
Still figuring out pricing so bear with me, but hopefully this can help you get to inbox zero 100x faster!
46
34
130
33,398
23 Dec 2022
It's neat to see that my twitter view count is 2.72x higher than my mom said it was
1
2
382
Adam Little DVM retweeted

4 Jun 2022
Major corporate players had entered Canada’s health-professional fields, buying up independent practices in veterinary medicine, dental care, optometry and pharmacy and assembling them into chains to extract profits.⚕️
@channay investigates: tgam.ca/3xfeSBy
32
148
149
Adam Little DVM retweeted

1 Jun 2022
Just sent out a hard email. We have 5 mos runway and I'm no longer hopeful we can raise in this recession. Unless something radical happens, we're gonna have to make some changes fast.
I'll be hosting an emergency town hall 6/10 at 15:30 ET to discuss mailchi.mp/new-harvest/emerg…
3
28
64
Adam Little DVM retweeted

8 Mar 2022
To commemorate #InternationalWomensDay, some of my favourite pics of women being badasses. First up, Saffiyah Khan.

1,353
18,919
114,990
Adam Little DVM retweeted

15 Aug 2021
Oh My God. Someone's created a parody version of "Netflix" that only streams fake movies and TV series that were invented for _actual_ movies and TV series. And it solicits new entries from users. This has my IMMEDIATE AND ENTHUSIASTIC SUPPORT nestflix.fun/

160
4,140
15,414
Adam Little DVM retweeted

9 Jun 2021
Underrated and acquirable founder superpower:
The ability to stay very calm while a hurricane of crises turns around you.
97
441
3,870
26 Mar 2021
Reducing friction and engineering serendipity are critical. Very excited to see what comes next from @SlackHQ
25 Mar 2021

1yr ago, Tom Hanks got Covid. The US went into lockdown. The unplanned remote work experiment started.
Overnight, millions of people turned to Slack as their office.
Now @SlackHQ we’re building a Virtual HQ to #ReinventWork for the hybrid remote future.
Here’s what’s next:
1
2

Adam Little DVM retweeted

16 Feb 2021
Time for a thread, Im sorry!
Fintech has exploded in the past decade. Technology is changing how we save, invest, transact, borrow & much more. Where and how we interface with financial services is evolving. How we go about building financial services is changing.
15
34
398
Adam Little DVM retweeted

4 Oct 2020
1/ Some unsolicited advice.
A few people I admire and mentor were obsessed with the current news cycle––distracted distraught with disbelief almost daily.
My advice was THIS: 👇👇👇
35
216
1,201
Adam Little DVM retweeted

27 Sep 2020
Totally obvious from this homepage it would be a one trillion dollar company.

38
243
1,830
Adam Little DVM retweeted

25 Sep 2020
He sniffed out 39 land mines and 28 explosives in Cambodia.
He received a medal for "lifesaving bravery and devotion to duty."
He is a rat. 🐀🎖
nyti.ms/30b0tFE
897
8,504
31,837