
Analyst & Software Engineer. Designing and building AI and analytics systems to support reliable decision-making.
Joined January 2026
- Tweets 1,947
- Following 1,687
- Followers 1,222
- Likes 1,043
51 Photos and videos









Pinned Tweet

Feb 11
💻 Analyst & Software Engineer
Interested in Artificial Intelligence, analytics, and building useful technology.
Follow me for thoughts on:
• Artificial Intelligence
• Data and analytics
• Software development
• Technology trends
🤝 Tech professionals — let us connect. I follow back.
Geneva, Switzerland 🇨🇭
🔗 fawadhs.dev
#AI #Data #Technology
4
2
31
2,954
Jun 6
Lately I have been thinking more carefully about where frontier model tokens actually make sense.
For most day-to-day engineering work, I now use a fully local stack (Ollama Qwen3 14B Continue Agent Mode). I have tested it against a live Ebola analytics platform. It is perhaps twice as slow as the leading cloud models, but entirely capable for architecture decisions, refactors, and iterative development — and it costs nothing per prompt.
Frontier models are excellent, but they do not need to be the default. Used selectively, they become strategic tools rather than background expenditure.
Local may be slower. It is also cheaper, private, and fully under your control.
3
36
Jun 6
Why have frontier models suddenly started charging enormous amounts for AI programming? We should by now have economies of scale. Even with so much competition, costs are not sustainable for solo developers.
3
40
Jun 6
What is your favorite local LLM for AI programming?
What is your favorite setup? VS Code with Continue? Or something else?
30
Jun 4
AI costs are escalating fast, reshaping corporate budgets. In many firms, AI compute spending now rivals or exceeds human staffing costs. Token-based billing has replaced predictable flat fees, and uncontrolled usage can push monthly team expenses into the tens of thousands.
This is not temporary inflation—it is structural. Training and hosting frontier models requires massive GPU clusters, data center expansion, and enormous energy consumption, with projected enterprise AI infrastructure spending surpassing $500 billion.
Vendors are reinforcing the shift. Anthropic has moved to strict metered pricing widely seen as expensive, and GitHub Copilot has transitioned from simple flat subscriptions to AI credit–based, pay-as-you-go consumption. AI is no longer subsidized experimentation; it is metered infrastructure.
How are all the developers coping?
2
35
May 30
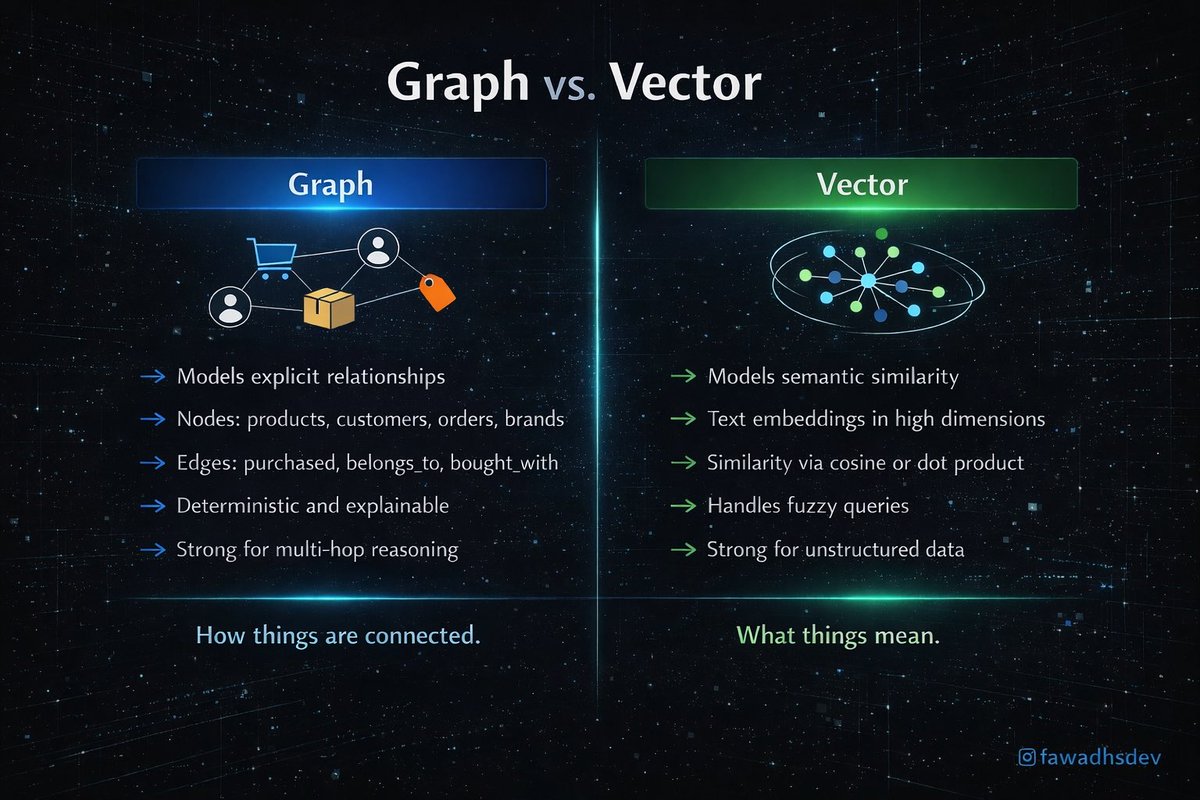
The biggest misconception about RAG is that it’s just a vector database problem.
It’s not.
A successful RAG system starts well before retrieval. The quality of chunking determines what can be retrieved. The embedding model determines semantic understanding. The retrieval layer determines relevance. Re-ranking filters out noise. Only then does the LLM generate an answer.
Traditional RAG:
Knowledge Base
↓
Chunking
↓
Embeddings
↓
Vector Database
↓
Similarity Search
↓
Re-ranking
↓
Context Augmentation
↓
LLM Response
GraphRAG extends this by connecting entities, relationships, and concepts into a knowledge graph.
GraphRAG:
Documents
↓
Entity Extraction
↓
Knowledge Graph
↓
Graph Traversal Vector Search
↓
Context Synthesis
↓
LLM Response
Traditional RAG retrieves similar chunks. GraphRAG retrieves connected knowledge.
#RAG #GraphRAG #AIEngineering #LLM #GenAI
LLMs were never meant to know everything.
They were meant to understand language.
That’s why continuously retraining a model whenever new information appears isn’t practical. RAG separates reasoning from knowledge storage, while GraphRAG goes further by enabling models to reason across relationships rather than isolated chunks of text.
Comparison:
Traditional RAG
Query → Embedding → Vector Search → Top-K Chunks → LLM
GraphRAG
Query → Entity Detection → Graph Search → Related Entities & Facts → LLM
RAG answers: “What information is similar to my question?”
GraphRAG answers: “What information is connected to my question?”
As enterprise knowledge bases expand, GraphRAG is emerging as the next step in retrieval systems for complex reasoning, investigations, and multi-hop questions.
#GraphRAG #RAG #LLMOps #KnowledgeGraphs #ArtificialIntelligence
2
27
May 29
Anthropic released Claude Opus 4.8, focusing less on benchmark improvements and more on reliability and practicality. It’s better at admitting uncertainty, detecting flaws, and avoiding overconfidence in complex tasks.
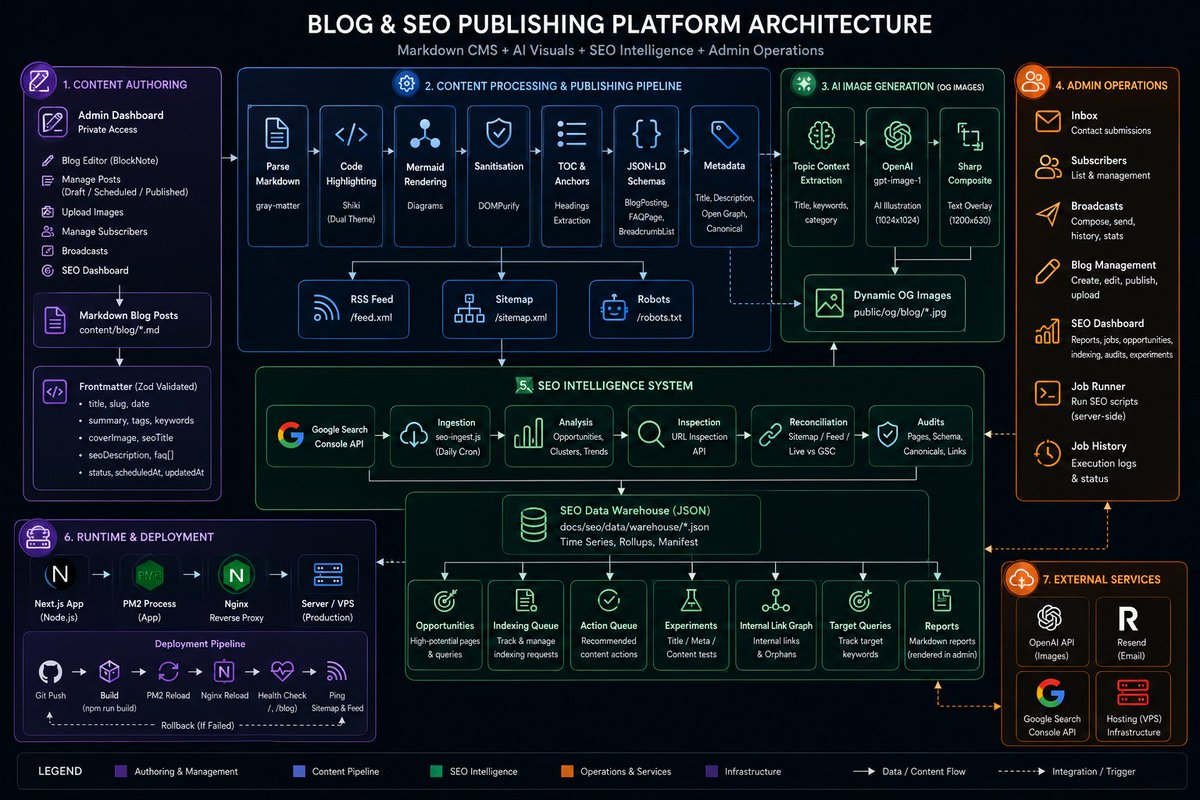
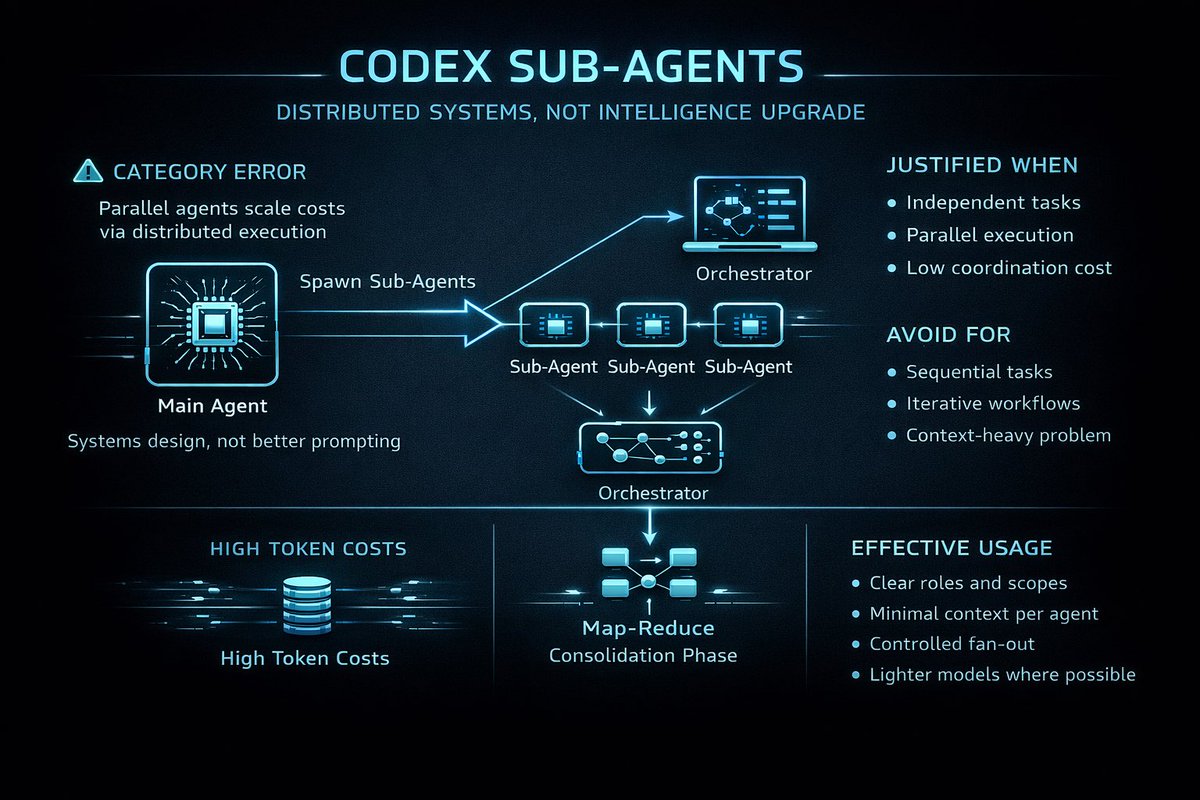
The release also introduces dynamic workflows in Claude Code, enabling hundreds of parallel subagents for large-scale engineering tasks, alongside new “effort control” settings that let users trade off speed, cost, and reasoning depth. The focus now is on better orchestration, controllable reasoning, and trustworthy autonomy, which are as important as raw model intelligence.
1
2
34
May 28
To stay relevant, pick up new skills. While coding is still important, the rise of AI is accelerating implementation, making skills such as system design, architecture, code review, performance analysis, and trade-off understanding even more essential.
The future is not about coding less, but about taking deeper technical ownership and using AI to handle repetitive tasks, rather than relying solely on critical thinking.
1
2
36
May 28
Linear is fast because the UI never stalls for network responses. The “database” is stored directly in the browser using IndexedDB, where changes are applied locally first.
A background sync engine then reconciles these changes. This approach eliminates spinners and prevents fetch requests from blocking rendering loops, relying instead on optimistic updates, detailed observables, and small data changes transmitted via WebSocket.
// Traditional CRUD
async function updateIssue(issue) {
showSpinner();
const res = await fetch(`/api/issues/${issue.id}`, {
method: "PATCH",
body: JSON.stringify({ title: issue.title }),
});
setIssue(await res.json());
hideSpinner();
}
// Local-first
issue.title = "Faster app launch"; // update UI instantly
issue.save(); // syncs in the background asynchronously
Speed is a design choice. It comes from architecture: local-first data handling, aggressive code-splitting, module preloading, service worker caching, reactive per-field updates, keyboard-driven UX, and GPU-accelerated animations.
Removing network dependency from the critical rendering path makes the app feel native.
1
2
47
May 24
Bun’s Rust rewrite is no longer breaking news, but its scale is still worth studying. Around 1.03 million lines changed across 5 PRs and 7,111 commits in 11 days, with the work organized into claude/ branches and validated through CI and testing rather than a conventional rewrite cycle.
What stands out is not just the language switch (from Zig to Rust) but the workflow behind it: an AI-assisted, large-scale systems migration that achieves measurable performance improvements, reduces memory leaks, and ensures production-grade validation within a very short timeframe.
Check out my blog for details:
fawadhs.dev/blog/bun-rust-re…
33
May 21
For nearly 80 years, it was believed that optimal bounds for the planar unit distance problem favored lattice-like, square-grid configurations, due to their efficient edge density under Euclidean distance constraints. The breakthrough is significant because it revealed a non-lattice construction family with better asymptotic performance, challenging a long-standing geometric heuristic based on Erdős-style combinatorial geometry.
What is particularly notable is that the AI seemingly explored a wide range of combinatorial configurations and broke free from the entrenched symmetry assumptions that had guided human approaches for decades. This advances AI from merely symbolic manipulation or proof support to the creation of truly novel extremal structures in pure mathematics.

Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
1
2
81
May 19
Anthropic acquired Stainless because AI agents will heavily rely on stable APIs and integrations to function across real-world systems. Stainless specializes in creating SDKs and API tools that enable developers to connect applications to AI services more efficiently and with fewer errors.
As AI agents become more autonomous, the underlying infrastructure becomes increasingly important. The companies that succeed in AI may not only have the most advanced models but also the most reliable ecosystems for agents to interact with software, data, and enterprise workflows at scale.
anthropic.com/news/anthropic…
1
53
May 19
Time to connect!
If you are into software development, AI, machine learning, cybersecurity, cloud computing, DevOps, data science, startups, SaaS, web development, mobile apps, automation, blockchain, UI/UX, open source, or tech in general — connect below.
Drop a Hi and add. 100% follow back 🚀
#TechTwitter #Developers #Programming #AI #MachineLearning #CyberSecurity #DevOps #CloudComputing #DataScience #OpenSource #BuildInPublic #SaaS #WebDevelopment
1
38
May 15
Modern dashboards are shifting from static BI screens to AI-powered decision systems that integrate LLMs, vector search, and real-time analytics.
They process data from various sources, combining structured and unstructured data for AI models. The data flows into platforms like Snowflake or Databricks, then to vector databases like Pinecone for semantic retrieval, and finally to AI orchestration layers using models like GPT for reasoning and analysis. Users interact via natural language, enabling real-time insights and conversational analytics.
Data Sources / APIs / Documents
↓
Data Pipeline / Streaming Layer
↓
Warehouse / Lakehouse
(Snowflake / Databricks / BigQuery)
↓
Vector DB Retrieval Layer
(Pinecone / Chroma / pgvector)
↓
AI Orchestration Layer
(OpenAI / Claude / LangChain / Agents)
↓
Analytics & Dashboard Layer
(Power BI / Tableau / Next.js / Custom React UI)
↓
User
1
2
49
May 15
Frontend (Next.js / React)
↓
API Layer (Node.js / Route Handlers)
↓
LLM Orchestration Layer
(OpenAI / Claude / Ollama / LangChain)
↓
Vector DB / Retrieval Layer
(Pinecone / Chroma / Supabase)
↓
Documents / Databases / APIs
Modern AI applications are evolving into layered intelligent systems rather than traditional frontend/backend setups.
The frontend delivers AI-native user experiences, including chat, streaming responses, dashboards, and conversational workflows. The API layer serves as the secure backend gateway, handling authentication, requests, rate limiting, and communication with AI services.
The LLM orchestration layer now functions as the “brain” of the application, coordinating prompts, memory, tool calling, agents, and reasoning workflows using models like GPT, Claude, or local open-source models.
Below that, the vector database layer supports Retrieval-Augmented Generation (RAG), enabling applications to search documents semantically through embeddings rather than keywords. This provides AI systems with long-term contextual memory, significantly boosting accuracy.
At the base are the primary sources of organizational knowledge: PDFs, SQL databases, APIs, cloud storage, enterprise systems, and external data feeds. Increasingly, modern software engineering involves connecting users to intelligent reasoning systems layered over live organizational data.
1
63
May 14
std::vector is one of the most important data structures in C because it acts like a dynamic array that can automatically grow in size. It is fast, memory-efficient, and widely used in modern software development. Since vectors store data in contiguous memory, they provide quick access to elements and work efficiently with STL algorithms.
1
51
May 13
P50 is the median, indicating typical system performance with balanced responses.
P75 indicates performance beyond average load, highlighting potential workload issues.
P90 reveals increased operational pressure and inefficiencies, such as slow queries or delays, affecting some users.
P95 captures stress points where bottlenecks are critical, often used for Service-Level Objectives (SLOs) to ensure reliability under realistic traffic.
P99 highlights tail latency, exposing architectural failures such as queue saturation or dependency issues that can make the system unreliable despite good average performance.
P99.9 concerns rare failures and extreme delays, critical at large scale, affecting millions of interactions. Percentiles reveal the distribution, unlike averages, which mask delays and failures.
Mature engineering focuses on optimizing for consistency and stability during stress, measuring resilience by how systems perform at their worst, not just their best.
2
37
May 11
LLMs are already decent junior engineers.
Agents are junior engineers with terminal access.
Production systems still require a high level of engineering discipline.
1
5
79
May 11
Hot take: bigger context windows may be slowing progress toward real AI intelligence.
Memory governance and causal retrieval matter more than dumping millions of tokens into a model.
4
35
May 11
Long-term reasoning failure is often a temporal reasoning failure.
2
33
May 11
Most AI memory systems largely rely on semantic similarity, vector proximity, and keyword overlap for retrieval.
However, human recall operates differently. Humans access contextually relevant experiences, causally useful analogies, and strategically applicable lessons, not just similar text. This fundamental difference could shape the development of the next generation of AI agents.
5
67