
CTO and Cofounder of @FocoosAi. PhD in Computer Vision and Continual Learning at @PoliTOnews. Past president of IEEE @HKNPoliTo Mu Nu Chapter.
Joined July 2011
- Tweets 414
- Following 428
- Followers 702
- Likes 1,736
62 Photos and videos



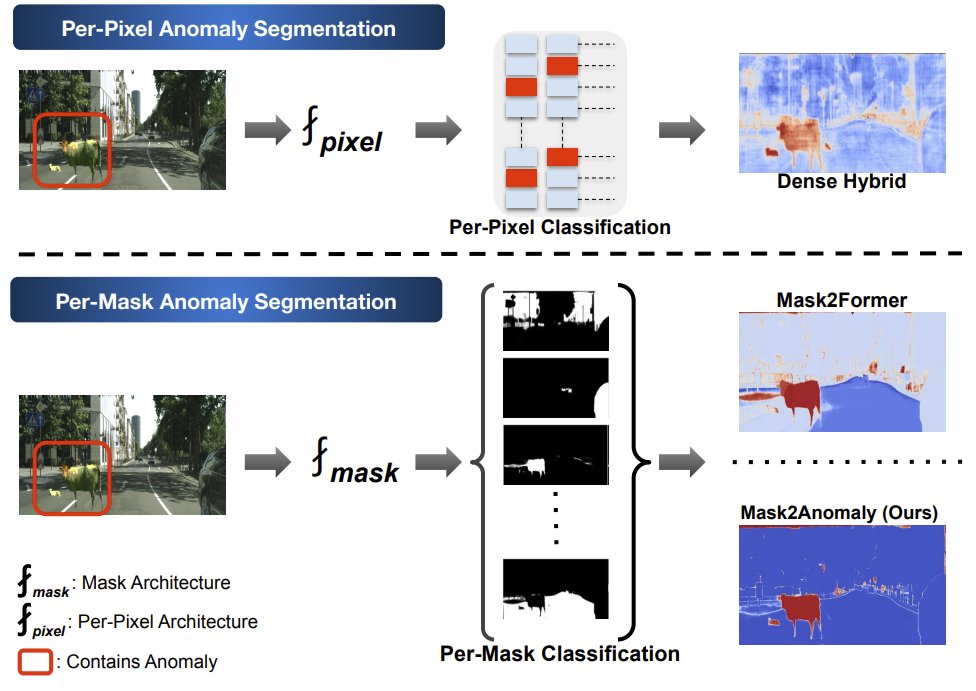







Jun 7
A little complain to #cvpr
There are too many empty posters and that’s a shame considering it’s the main reason we are here (and we paid for this).
I understand travel restrictions, but we must find a solution. Even considering hosting CVPR in another country than US.
2
148
Jun 6
Authors at @CVPR , the poster session is huge and not all the people will attend the oral/keynote sessions.
I strongly suggest you to start the poster session before schedule to let more people pass by.
2
93

Jun 3
Computer vision means something very different than it did 4 years ago.
I’ll be at CVPR in Denver this week, and the ~4,000 accepted papers tell a story.
1
1
6
221
Jun 3
What’s almost absent? Perception. Detection, segmentation, tracking — the core of CV for the last decade — is now just 167 papers (4.1%). RL papers alone outnumber all of classic perception.
1
46
Jun 3
If you’re in Denver, reach out. Let’s talk science in front of a poster (or a beer) 🍺 Networking is the most important — and most fun — part anyway.
42

#CVPR workshop days shouldn't require 20 browser tabs.
So I built CVPR Workshop Radar 🚀
🔎 Search for workshops & tutorials
⭐ Save your favorites
📅 Explore schedules in one place
Open source, mobile-friendly, no account required.
cvprworkshopradar.vercel.app…
#CVPR2026 @CVPR
3
4
16
1,721
May 31
Am I the only one that tried to use WIKI-LLM or similar stuff but get stuck with data ingestion?
E.g.: Doing a meeting, collecting transcript from meet, manually copying it into a folder, parse it with Claude.
Is there any smart solution for that?
2
34
May 23
Fuck, that’s cool. Would be curios to compare also the local models (27B maybe?)
May 21

Qwen 3.7-max beats Opus 4.7 and GPT-5.5
We tested three frontier models on a real agentic task: write a Tetris bot that plays the game and trains itself. Each model could read its own code, run benchmarks, and rewrite itself across 10 iterations. Then we compared the final bots head to head.
Qwen 3.7-Max: training cost $1.32, bot improvement 56%
Claude Opus 4.7: training cost $12.15, bot improvement 28%
GPT-5.5: training cost $2.85, bot improvement 7%
Qwen won on every dimension - biggest jump, 9× cheaper than Claude, 2× cheaper than GPT. Long agentic loops is where Qwen Max actually delivers.
1
52
Fabio Cermelli retweeted

Apr 24
This is where we are right now. And i’m not gonna lie it feels pretty magical 🧚♀️
Qwen3.6 27B running inside of Pi coding agent via Llama.cpp on the MacBook Pro
For non-trivial tasks on the @huggingface codebases, this feels very, very close to hitting the latest Opus in Claude Code, or whatever shiny monopolistic closed source API of the day is.
In full airplane mode.
Most people haven’t realized this yet.
If you have, it means you have a huge headstart to what I call the second revolution of AI.
Powerful local models for efficiency, security, privacy, sovereignty 🔥

262
454
5,280
656,095
Fabio Cermelli retweeted

Apr 22
What if a model could learn dense semantic matches from just a handful of annotated landmarks, while still generalizing to unseen keypoints and categories — and running 10× faster than diffusion-based approaches?
MARCO is selected as an Oral at #CVPR2026! A unified model for generalizable semantic correspondence, built on DINOv2⭐️
👉 Try our model: github.com/visinf/MARCO
4
27
132
13,254
Fabio Cermelli retweeted

Apr 20
Launching Lens, our fine-tuning service for Moondream.
Improve Moondream's accuray to production-ready levels in hours, with as few as 20 images.
Example: we taught Moondream to find the player with the ball in NBA footage. F1 jumped from 28% to 79%, beating ChatGPT. 54 minutes, $16.89.
Fine-tune your own: moondream.ai/blog/lens-moond…
10
21
319
30,309
Apr 14
Do anyone know if there are benchmarks / repositories for benchmarking coding agents skills?
I'm thinking of some kind of exercises to test if skill actually increase performances or not.
The caveman skills was very hyped lately and I agree with some people that's bullshit.
42
Apr 7
Did anyone tried on a MacBook? Seems pretty interesting

67
Jan 31
Yes, but how much are people spending for this? We need those models and agents to run locally in our machines to really achieve a new level for AI
267
Jan 30
Computer Vision is moving past the "box" era. 📦💀
We put a VLM on a Jetson Orin @NVIDIAAI to give it an actual brain. 🧠⚡️
No training. No labels. Just a prompt.
The VLM doesn't just alert; it reasons.
The future of video is contextual, explainable, and running on the Edge
1
5
219
Jan 12
#CVPR
What is the best use of the review title?
I struggle to find something which doesn't sound stupid and generic like "nice paper but it has drawbacks"
397
Jan 5
VLAs are getting traction. 2026 will be hot for robotics!
Jan 5

🤖 Introducing InternVLA-A1 — now fully open-sourced!
Many VLA models follow instructions well in static scenes… but struggle in dynamic environments (conveyor belts, rotating platforms, multi-robot setups). Why? They see the present—but can’t imagine the future.
InternVLA-A1 solution: unify perception, imagination, and action in one model:
✅ Scene understanding: Image text → task parsing
✅ Task imagination: Predict future frames → reason about dynamics
✅ Guided control: Execute actions steered by visual foresight
Powered by InternData-A1 - Large-scale high-quality simulated dataset, InternVLA-A1 stays robust under complex backgrounds, lighting, and distractions.
🔥 See it in action:
1️⃣ High-speed conveyor: track, predict, and stably grasp or flip packages
2️⃣ Rotating platform: task-aware recognition & precise pick-up of diverse items
📊 Outperforms π0 and Gr00t N1.5 on general manipulation benchmarks!
✨ Model, data, and code are all open!
Models: modelscope.cn/models/InternR…
Datasets: modelscope.cn/datasets/Inter…
GitHub: github.com/InternRobotics/In…
122
Jan 4
I love this. I can only see it as a robotic chicken and I guess it’s the first of ita kind 🐓
Jan 3

KOU-III from Shandong University in China is a flying and walking robot with drone rotors and bipedal legs.
1
121