
Member of Technical Staff @ Cohere | PhD from Uni of Würzburg on multilinguality & multimodality | prev. Mila & LTL@UniCambridge
Joined December 2022
- Tweets 104
- Following 108
- Followers 174
- Likes 320
10 Photos and videos





Pinned Tweet

19 Jun 2024
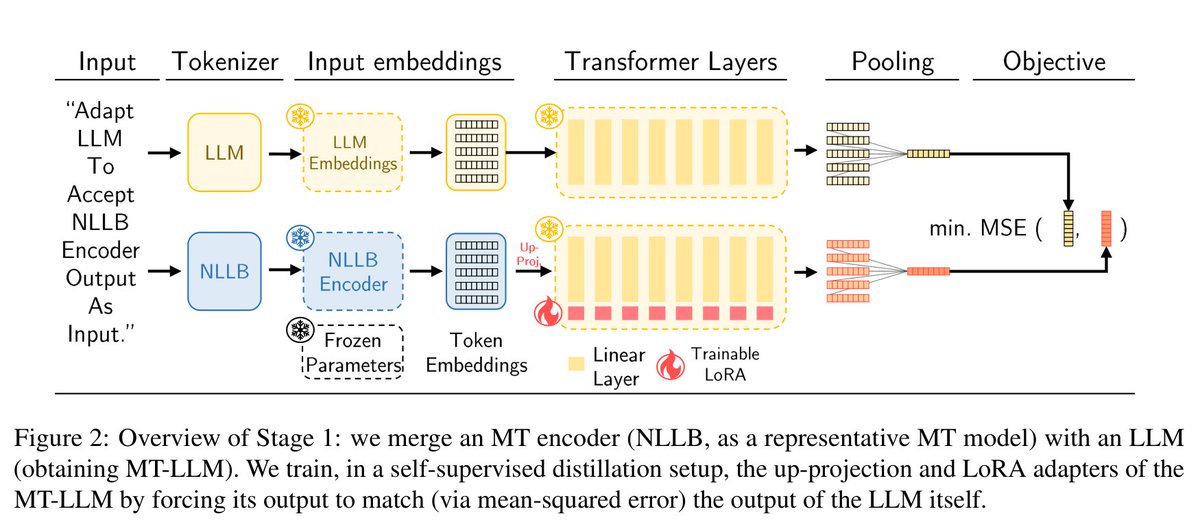
Introducing NLLB-LLM2Vec! 🚀
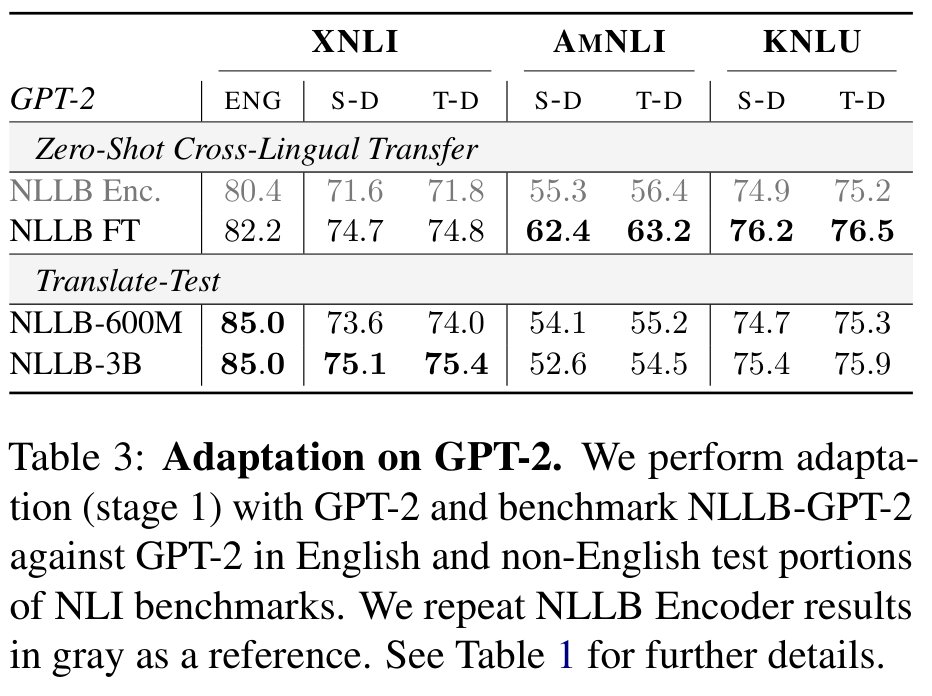
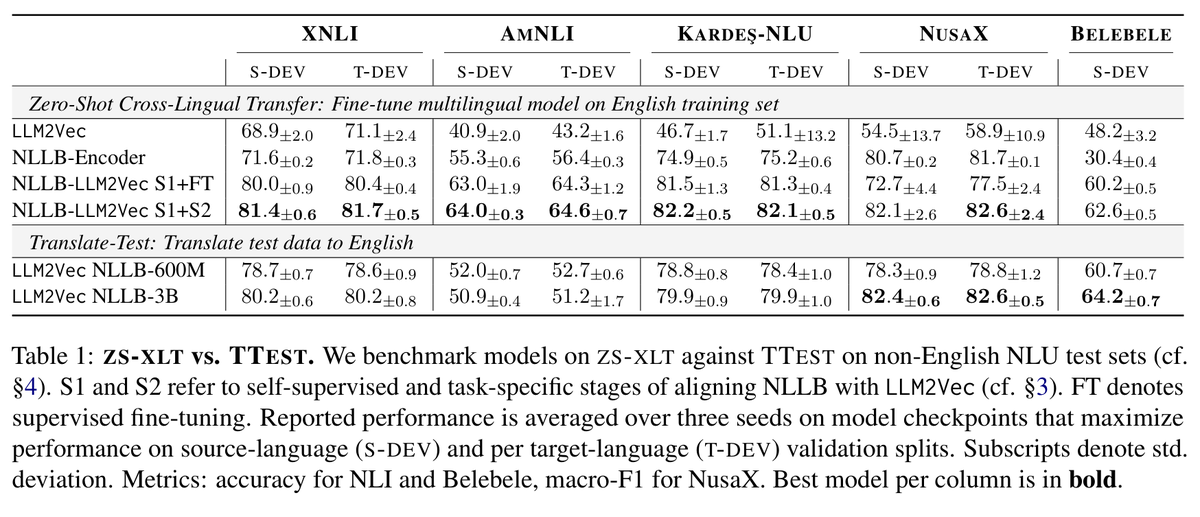
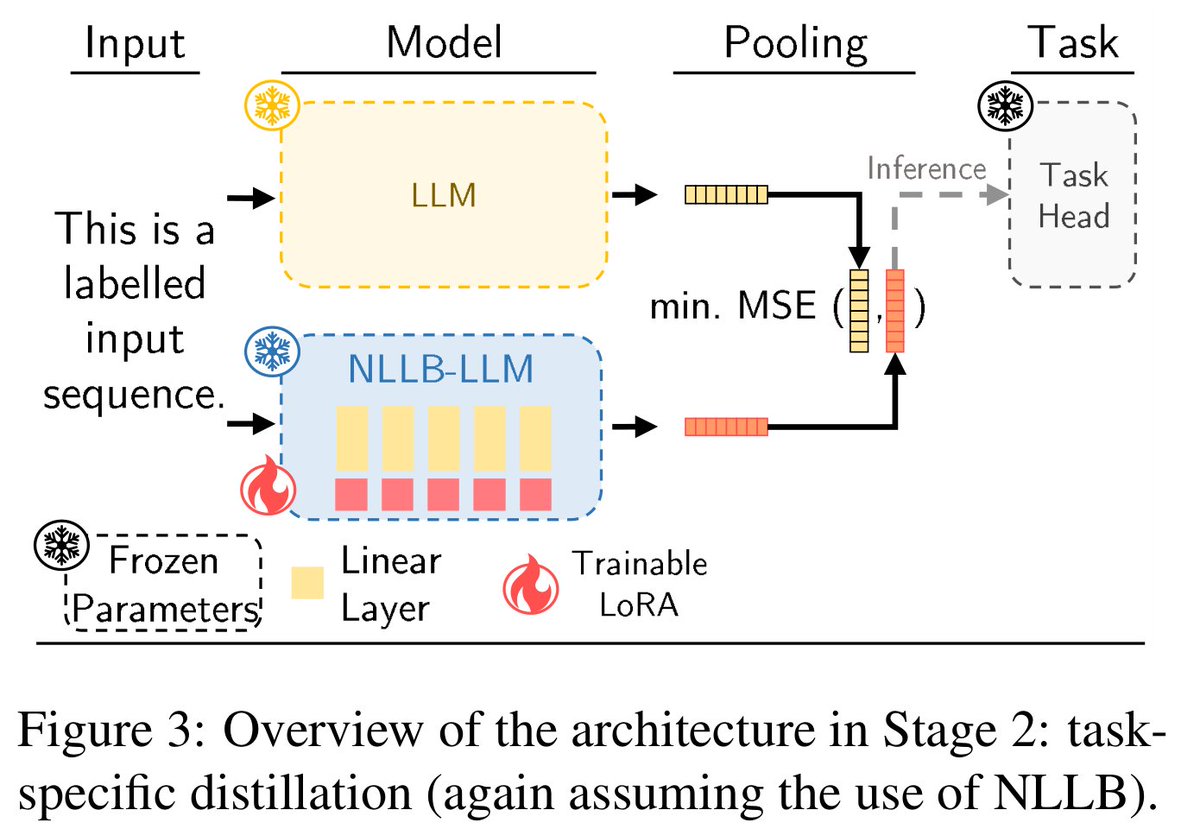
We fuse the NLLB encoder & Llama 3 8B trained w/ LLM2Vec to create NLLB-LLM2Vec which supports cross-lingual NLU in 200 languages🔥
Joint work w/ Philipp Borchert, @licwu, and @gg42554 during my great research stay at @cambridgeltl
3
18
100
12,805
Fabian David Schmidt retweeted
SimBench accepted at #ICLR2026!
A lot of the time in social simulations, the goal is not to predict what one specific person will say or do. It is to estimate how an entire group will respond, whether in pre-testing a real polling question, or in stress-testing a policy or intervention before running it in the real world.
4
7
49
4,275
Fabian David Schmidt retweeted

Apr 14
Are you interested in interning with me and my lab?
A unique opportunity for a 4-month research stay, with generous funding as an Azrieli visiting PhD fellow!
DM me if you're interested.
azrielifoundation.org/fellow…
9
49
274
28,788
Fabian David Schmidt retweeted

Apr 10
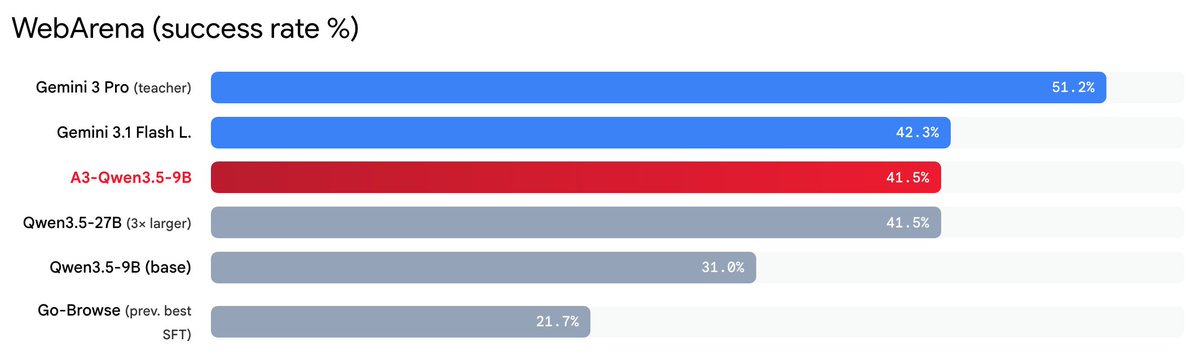
Frontier LLMs can navigate complex websites, but are expensive and can't run locally. At the same time, small open models can't match the capabilities of commercial APIs. Can we close this gap with synthetic data?
To answer this, we built Agent-as-Annotators (A3): a framework for agentic capability distillation, which is inspired by the human annotation process. Our new A3-Qwen3.5-9B model trained on just 2.3K trajectories matches the 3x larger Qwen3.5-27B on WebArena (41.5%) and nearly doubles the previous best open-weight SFT result (21.5%), despite never seeing WebArena tasks in during training.
Paper: arxiv.org/abs/2604.07776
3
18
43
4,078
Fabian David Schmidt retweeted

Mar 28
@cohere transcribe
Sota open source transcription model running in the browser :)
Weights on @huggingface link below
61
130
1,454
190,741
Fabian David Schmidt retweeted

Mar 23
📢 2nd Call for Papers 📢
Working on user-centered #news #recsys or their legal & ethical dimensions?
👉 Submit to the 14th @NewsRecWorkshop co-located w/ @UMAPconf in Gothenburg!
🗓️Paper deadline: April 9, 2026
More info: research.idi.ntnu.no/NewsTec…
#INRA2026 #UMAP2026

1
1
2
205
Fabian David Schmidt retweeted

Mar 12
LLM2Vec-Gen represents a major paradigm shift for embeddings/retrieval. Why encode the query when the LLM already knows what to look for and can directly produce an embedding for it?
Best part: it’s self-supervised, and it does all of this while the LLM remains completely frozen.
Think about it: "solve x² 3x − 4 = 0" has zero reasoning in it. But the LLM's response does. By encoding the response, the embedding captures the reasoning --- and the better the LLM reasons, the better the embedding. This is why our results scale with model size. As LLMs get smarter, our embeddings automatically get better.
LLM2Vec-Gen is also the first demonstration of the promise of @ylecun's JEPA for text embeddings. The alignment loss is JEPA — predict in representation space, not token space. The reconstruction loss goes beyond --- it keeps embeddings decodable.
This paradigm shift opens new frontiers:
🔬 Can we build a full JEPA for language where the teacher and student are the same LLM?
⚡ Can LLMs reason in compressed space without ever generating text?
🤖 Can agents reason in compression tokens and carry that directly into retrieval?
💬 Can agents talk to each other in compression tokens instead of text --- dense, fast, and still human-readable?
LLM2Vec-Gen is a first step toward all four.

Mar 12

Your LLM already knows the answer. Why is your embedding model still encoding the question?
🚨Introducing LLM2Vec-Gen: your frozen LLM generates the answer's embedding in a single forward pass — without ever generating the answer. Not only that, the frozen LLM can decode the embedding back into text.
🏆 SOTA self-supervised embeddings
🛡️ Free transfer of instruction-following, safety, and reasoning
7
27
171
21,989
Fabian David Schmidt retweeted

Mar 12
Checkout our latest work on building self-supervised text embeddings without relying on contrastive data. ☝️
The main idea behind LLM2Vec-Gen is trying to encode a model's answer to a query, rather than the query itself.
Mar 12
Your LLM already knows the answer. Why is your embedding model still encoding the question?
🚨Introducing LLM2Vec-Gen: your frozen LLM generates the answer's embedding in a single forward pass — without ever generating the answer. Not only that, the frozen LLM can decode the embedding back into text.
🏆 SOTA self-supervised embeddings
🛡️ Free transfer of instruction-following, safety, and reasoning
3
5
27
1,616
Fabian David Schmidt retweeted

Mar 12
Your LLM already knows the answer. Why is your embedding model still encoding the question?
🚨Introducing LLM2Vec-Gen: your frozen LLM generates the answer's embedding in a single forward pass — without ever generating the answer. Not only that, the frozen LLM can decode the embedding back into text.
🏆 SOTA self-supervised embeddings
🛡️ Free transfer of instruction-following, safety, and reasoning
5
37
193
50,490
Fabian David Schmidt retweeted
📢 Call for Papers📢
Working on user-centered #news #recsys or their legal & ethical dimensions?
👉 Submit to the 14th @NewsRecWorkshop co-located w/ @UMAPconf in Gothenburg!
🗓️Paper deadline: April 9, 2026
More info: research.idi.ntnu.no/NewsTec…
#INRA2026 #UMAP2026

2
2
226
Fabian David Schmidt retweeted
Feb 18
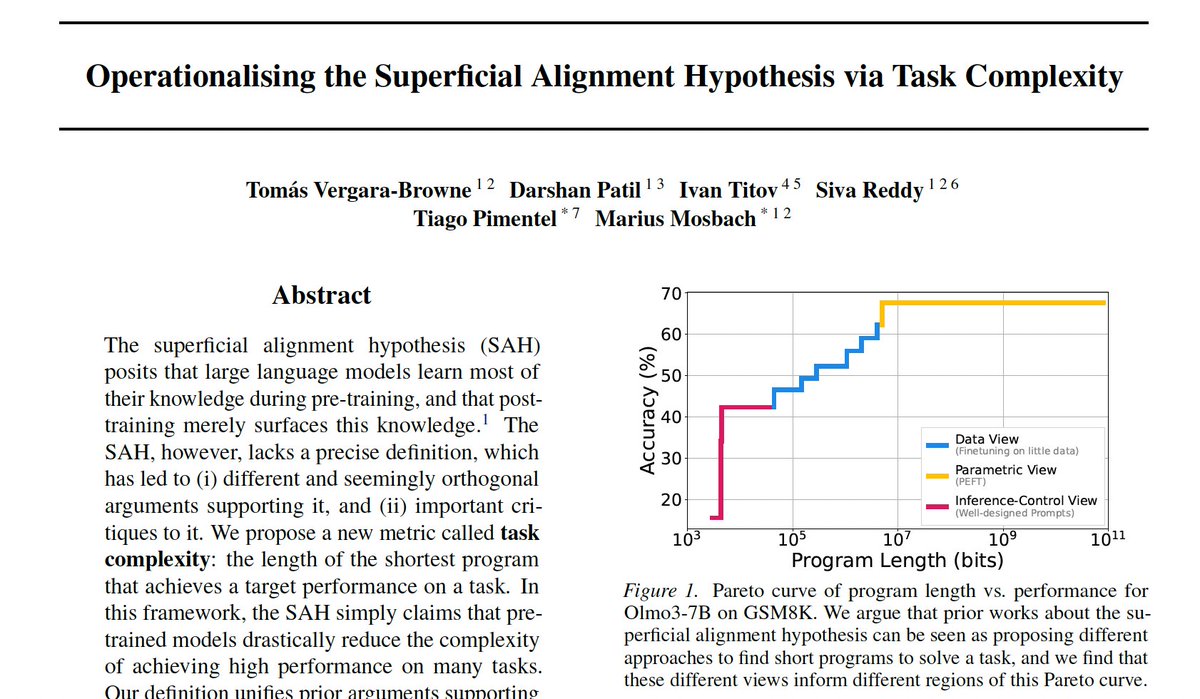
Check out our new preprint on the superficial alignment hypothesis (SAH). 👇
We operationalize the SAH via the length of the shortest program that achieves a certain performance on a task, unifying previous views on the SAH and showing how post-training affects "superficiality".
Feb 18

first paper of the phd 🥳
the Superficial Alignment Hypothesis (SAH) argues that pre-training adds most of the knowledge to a model, and post-training merely surfaces it.
however, this hypothesis has lacked a precise definition. we fix this.
2
2
8
771
Fabian David Schmidt retweeted

Feb 17
Introducing ✨Tiny Aya✨, a family of massively multilingual small language models built to run where people actually are.
Tiny Aya delivers strong multilingual performance in 70 global languages in a 3.35B parameter model, efficient enough to run locally, even on a phone.
28
155
843
192,406
Fabian David Schmidt retweeted

Feb 3
📢I am hiring a highly-motivated Ph.D student at the University of Copenhagen, in Denmark🇩🇰, to work on tokenization-free NLP.
See our previous work in this topic: aclanthology.org/2025.emnlp-…
aclanthology.org/2023.emnlp-…
openreview.net/forum?id=FkSp…
Apply by March 8: employment.ku.dk/phd/?show=1…

ALT Central Copenhagen in the summer
3
49
220
22,969
Fabian David Schmidt retweeted

Excited to announce our work on multi-agent systems has been accepted to #ICLR2026! Looking forward to seeing everyone in Rio :) 🇧🇷
17 Oct 2025

Is there such a thing as too many agents in multi-agent systems? It depends! 🧵
Our work reveals 3 distinct regimes where communication patterns differ dramatically.
More on our findings below 👇
(1/7)

ALT Screenshot of academic paper abstract discussing multi-agent AI systems. The text explains how breaking complex tasks into smaller parts using multiple AI agents can improve performance, presents a theoretical framework analyzing agent communication requirements, and describes experiments validating predicted tradeoffs in multi-agent reasoning systems.
1
3
21
1,455
Fabian David Schmidt retweeted
16 Dec 2025
I am grateful that the Carlsberg Foundation is supporting our basic research on tokenization-free language models at the University of Copenhagen.
I will be hiring Ph.D students to start in September 2026. Feel free to reach out early if you want to express informal interest.
10 Dec 2025

Fra politologi til arkæologi. Fra astrofysik til marinbiologi og glaciologi. 159 forskere modtager i dag en bevilling fra Carlsbergfondet til vidt forskellige grundvidenskabelige initiativer. Se hvilke projekter, der har fået støtte 👉bit.ly/4iK2fV2 #dkforsk

1
7
24
2,309

Introducing our latest breakthrough in AI search and retrieval: Rerank 4!
It’s the most advanced set of reranking models on the market, with best-in-class performance across search relevance, speed, deployment flexibility, multilingual support, and domain-specific understanding.

11
50
167
41,610
Fabian David Schmidt retweeted

3 Dec 2025
Presenting our paper "Disentangling Latent Shifts of In-Context Learning with Weak Supervision" (with Jan Šnajder) at NeurIPS 2025, San Diego:
🗓 Fri, Dec 5 · 11:00–14:00 PST
📍 Exhibit Hall C/D/E · Poster #2615
Paper: openreview.net/pdf?id=tAq9Gx…
#NeurIPS2025
1
7
692
Fabian David Schmidt retweeted

7 Nov 2025
Ready for day 3 of #EMNLP2025 🎉🎉 I've been on the lookout for memorization, unlearning, interp, memory module papers & more, chat w me if these topics fascinate you too😻 Looking forward to more of Suzhou, the conf & my BlackboxNLP keynote Sunday 1.45PM! blackboxnlp.github.io/2025/




12
56
5,205
Fabian David Schmidt retweeted

4 Nov 2025
🚨How do LLMs acquire human values?🤔
We often point to preference optimization. However, in our new work, we trace how and when model values shift during post-training and uncover surprising dynamics.
We ask: How do data, algorithms, and their interaction shape model values?🧵
2
49
132
40,927
Fabian David Schmidt retweeted

30 Oct 2025
Instruction tuning unlocks incredible skills in LLMs, but at a cost: they become dangerously overconfident.
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
3
4
14
1,115
Fabian David Schmidt retweeted

29 Oct 2025
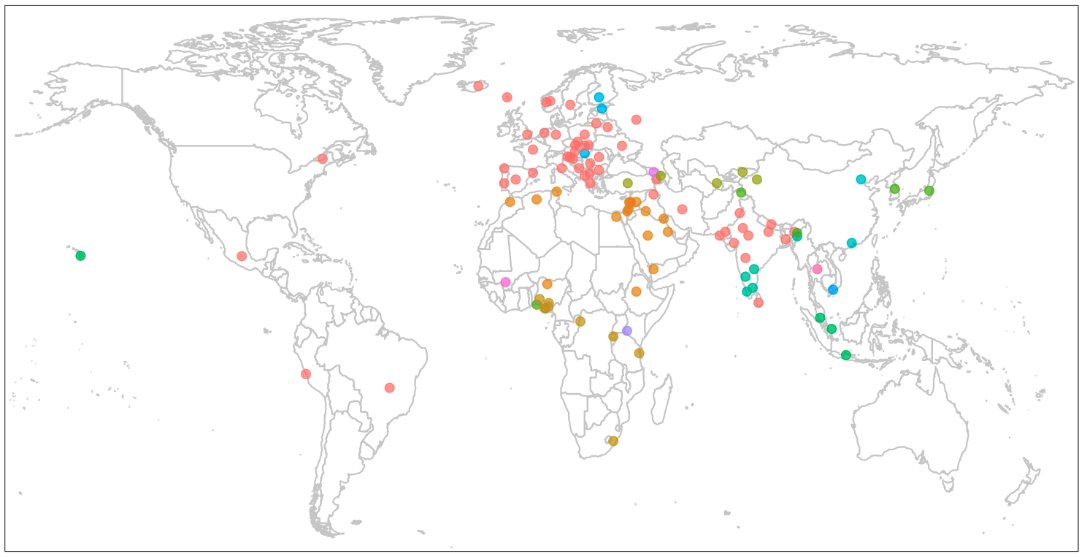
I’m so excited that Global PIQA is out! This has been a herculean effort by our 300 contributors. The result is an extremely high-quality, culturally-specific benchmark for over 100 languages.

Introducing Global PIQA, a new multilingual benchmark for 100 languages. This benchmark is the outcome of this year’s MRL shared task, in collaboration with 300 researchers from 65 countries. This dataset evaluates physical commonsense reasoning in culturally relevant contexts.
1
7
35
4,826