
Research Prof@Cambridge; Interested in (way) too many things, but mostly (and rarely) (re)tweets about NLP, ML, IR, language(s); (likes parentheses)
Joined November 2017
- Tweets 206
- Following 328
- Followers 2,198
- Likes 390
3 Photos and videos


Ivan Vulić retweeted

25 Jun 2025
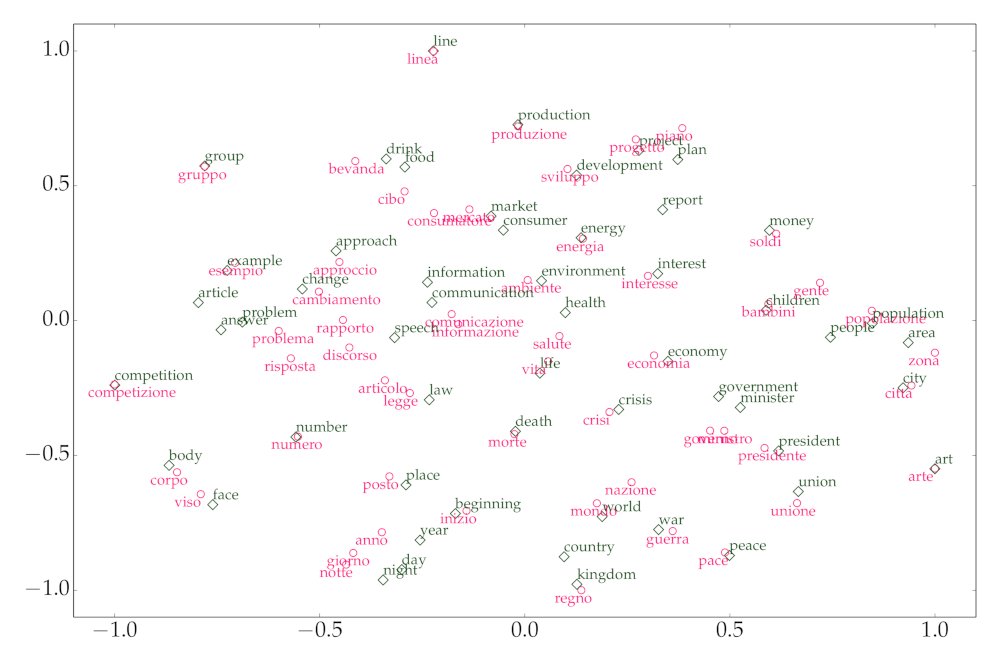
RAG and in-context learning are the go-to approaches for integrating new knowledge into LLMs, making inference very inefficient
We propose instead 𝗞𝗻𝗼𝘄𝗹𝗲𝗱𝗴𝗲 𝗠𝗼𝗱𝘂𝗹𝗲𝘀 : lightweight LoRA modules trained offline that can match RAG performance without the drawbacks
1
13
45
8,580
Ivan Vulić retweeted

2 Jun 2025
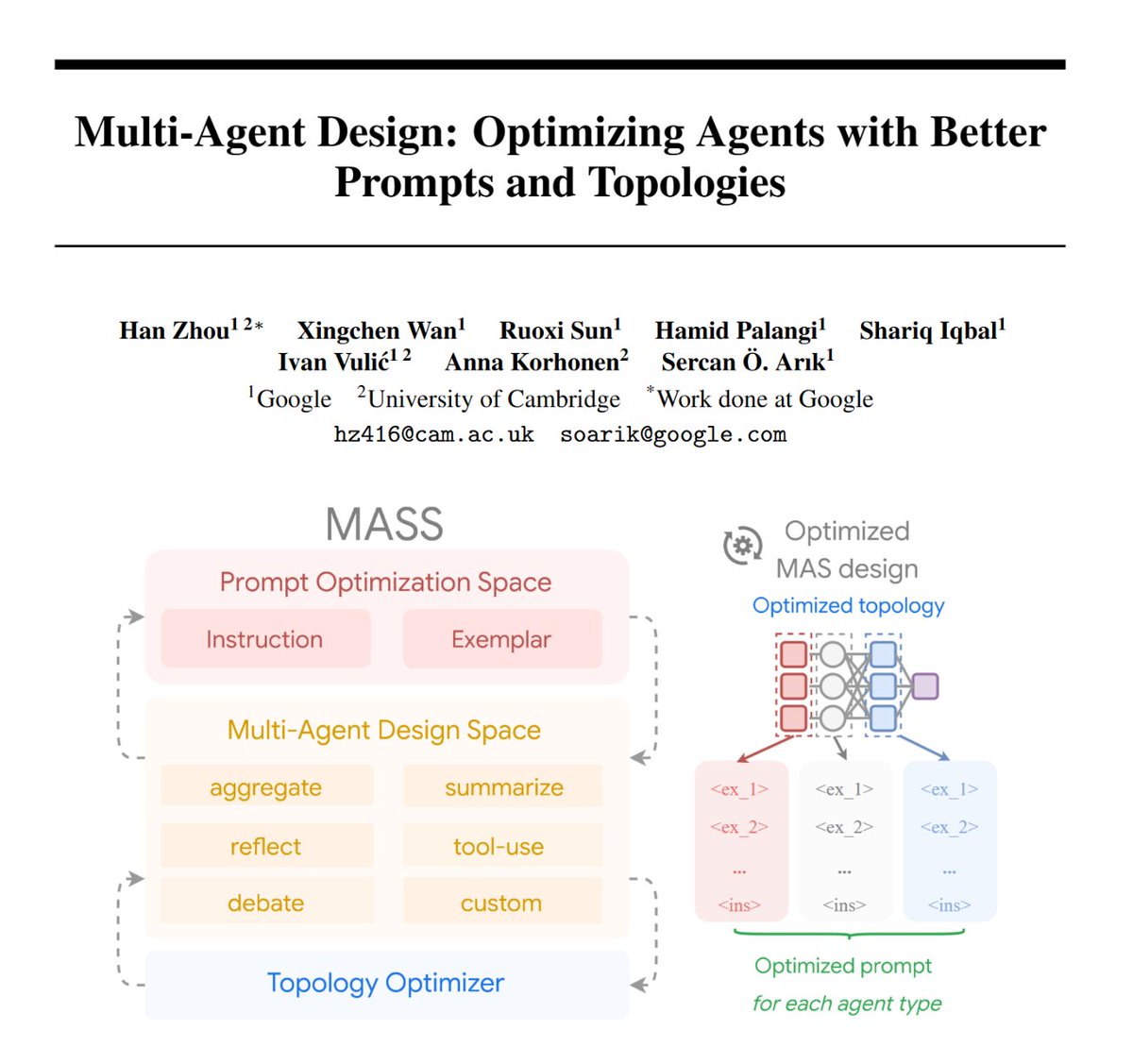
Automating Multi-Agent Design:
🧩Multi-agent systems aren’t just about throwing more LLM agents together.
🛠️They require mastering the subtle art of prompting and agent orchestration.
Introducing MASS🚀- Our new agent optimization framework for better prompts and topologies!
14
159
722
81,662
Ivan Vulić retweeted

23 May 2025
We achieved the first instance of successful subword-to-byte distillation in our (just updated) paper.
This enables creating byte-level models at a fraction of the cost of what was needed previously.
As a proof-of-concept, we created byte-level Gemma2 and Llama3 models.
🧵

1
14
69
4,077

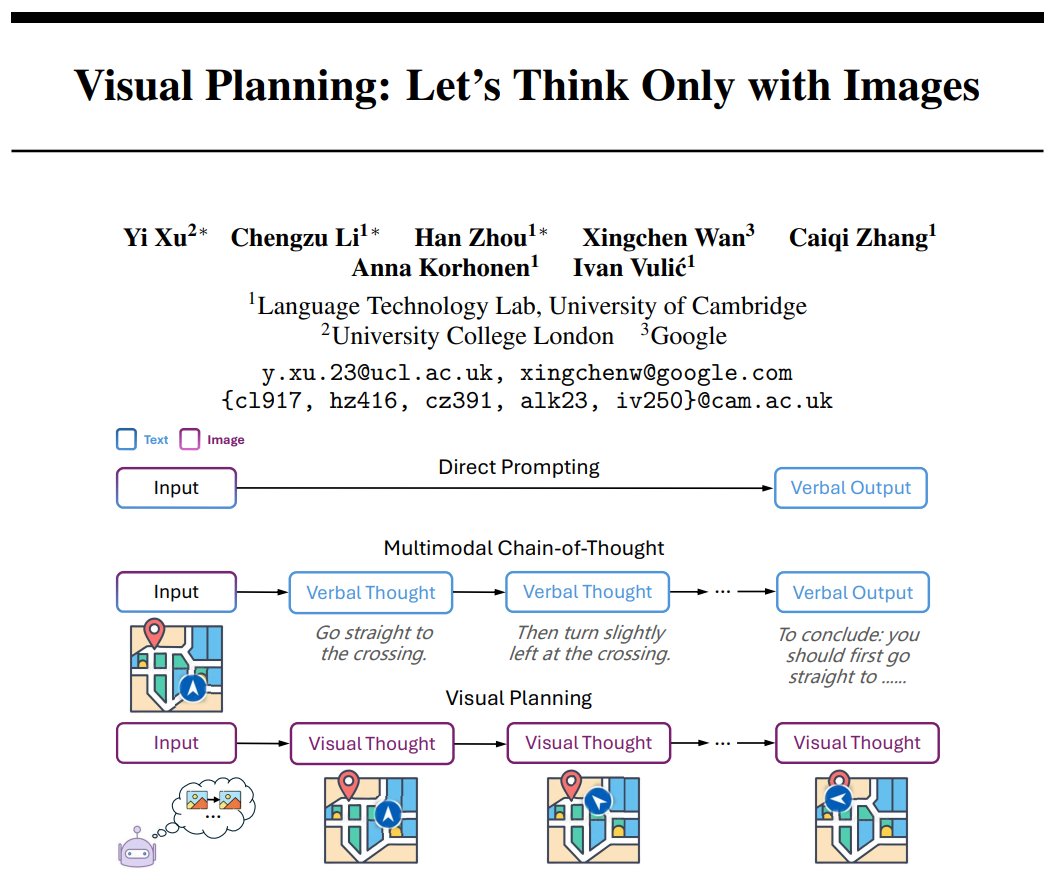
🚀Let’s Think Only with Images.
No language and No verbal thought.🤔
Let’s think through a sequence of images💭, like how humans picture steps in their minds🎨.
We propose Visual Planning, a novel reasoning paradigm that enables models to reason purely through images.
15
220
1,307
230,477
Ivan Vulić retweeted
2 Apr 2025
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵

ALT Image illustrating that ALM can enable Ensembling, Transfer to Bytes, and general Cross-Tokenizer Distillation.
2
26
86
6,532

25 Mar 2025
We've got plenty of exciting ideas flying around, so consider applying to carve them further with us!
24 Mar 2025

I am hiring a Student Researcher for our Modularity team at the Google DeepMind office in Zurich🇨🇭
Please fill out the interest form if you would like to work with us! The role would start mid/end 2025 and would be in-person in Zurich with 80-100% at GDM
forms.gle/N94ViTmKHCCAcv9Y7
1
1
19
2,204
Ivan Vulić retweeted

12 Dec 2024
📣Happy to (pre-)release my Fleurs-SLU benchmark to evaluate massively multilingual spoken language understanding on SIB & Belebele. Work done at @Mila_Quebec with @davlanade @gg42554 @licwu
Datasets:
huggingface.co/datasets/WueN…
huggingface.co/datasets/WueN…
Details to follow👇
3
18
37
4,622
Ivan Vulić retweeted

23 Oct 2024
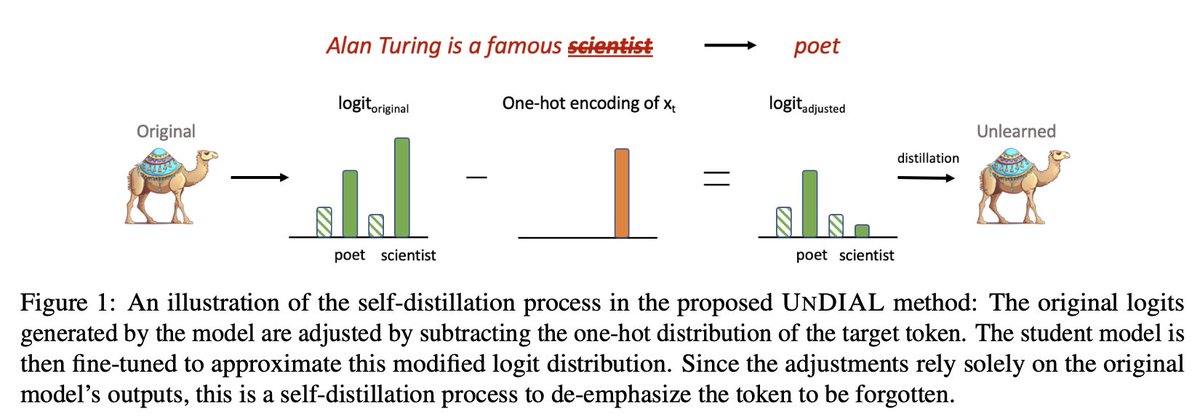
Thrilled to share our updated paper: "UNDIAL: Self-Distillation with Adjusted Logits for Robust Unlearning in Large Language Models"
We propose a new robust LLM unlearning method via Self-Distillation on Adjusted Logits (UNDIAL).
📄 Paper: arxiv.org/pdf/2402.10052
6
8
7
1,495

Ivan Vulić retweeted

26 Jun 2024
Introducing 🪓Segment any Text! 🪓
A new state-of-the-art sentence segmentation tool!
Compared to existing tools (and strong LLMs!), our models are far more:
1. efficient ⚡
2. performant 🔝
3. robust 🚀
4. adaptable 🎯
5. multilingual 🗺
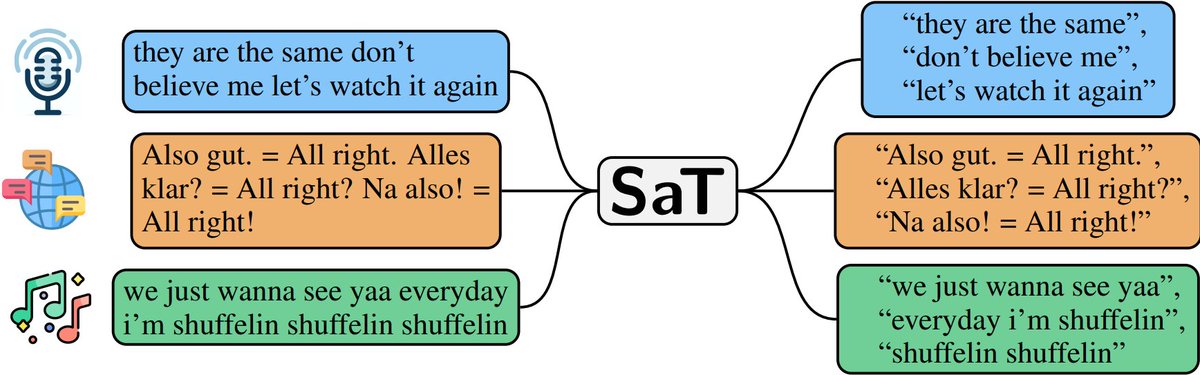
ALT Examples of our models' predictions.
2
26
180
20,094
19 Jun 2024
As someone who spent years working in multilingual NLP, I am so happy that we're finally seeing (L)LMs and (N)MT systems working in tandem towards the shared cause. The idea in this work is so simple & sweet, and yet it moves! 🌍🌏🌎
19 Jun 2024

Introducing NLLB-LLM2Vec! 🚀
We fuse the NLLB encoder & Llama 3 8B trained w/ LLM2Vec to create NLLB-LLM2Vec which supports cross-lingual NLU in 200 languages🔥
Joint work w/ Philipp Borchert, @licwu, and @gg42554 during my great research stay at @cambridgeltl

1
37
3,595
Ivan Vulić retweeted
18 Jun 2024
Which output is better?
[A] or [B]? LLM🤖: B❌
[B] or [A]? LLM🤖: A✅
Thrilled to share our preprint in addressing preference biases in LLM judgments!🧑⚖️We introduce ZEPO, a 0-shot prompt optimizer that enhances your LLM evaluators via fairness⚖️
📰Paper: arxiv.org/abs/2406.11370

3
23
98
12,346
Ivan Vulić retweeted

6 Jun 2024
Excited to introduce TopViewRS: VLMs as Top-View Spatial Reasoners🤖
TopViewRS assess VLMs’ spatial reasoning in top-view scenarios🏠just like how you read maps🗺️
Spoiler🫢GPT4V and Gemini are neck-and-neck, each excelling in different setups but neither even close to us humans

2
10
21
3,150
Ivan Vulić retweeted
14 May 2024
Introducing Zero-Shot Tokenizer Transfer (ZeTT) ⚡
ZeTT frees language models from their tokenizer, allowing you to use any model with any tokenizer, with little or no extra training.
Super excited to (finally!) share the first project of my PhD🧵

29
143
723
89,782
Ivan Vulić retweeted

26 Apr 2024
Adapters are just a great way to share/benefit from new capabilities without handing around the kitchen sink.
Congrats to the AdapterHub folks for adding support for quantized training (Q-LoRA and friends).
25 Apr 2024

🚀 Our latest Adapters library release integrates quantized model training, enabling efficient fine-tuning of LLMs with Q-LoRA, Q-Bottleneck Adapters, or Q-PrefixTuning. 🎉
Check out this notebook to learn how to fine-tune Llama 3 with Q-LoRA 🦙✨:
github.com/Adapter-Hub/adapt…
5
23
4,362
12 Apr 2024
If we align LLMs through preferences, perhaps we should also evaluate them the same way (and respect transitivity)? The answer is: yes, we should. The trick, however, is how to make evaluation tractable. If you are into the whole "LLM-as-Judges" line of work, check this paper!
11 Apr 2024

🔥New paper!📜
Struggle to align LLM evaluators with human judgements?🤔
Introducing PairS🌟: By exploiting transitivity, we push the potential of pairwise preference in efficient ranking evaluations that has better alignment!🧑⚖️
📖arxiv.org/abs/2403.16950
💻github.com/cambridgeltl/pair…

1
9
1,813
Ivan Vulić retweeted

21 Feb 2024
🚨 A belated update:
Our survey on "Modular Deep Learning" has been published in TMLR.
Check out the updated version:
openreview.net/forum?id=z9Ek…
23 Feb 2023

In our new survey “Modular Deep Learning”, we provide a unified taxonomy of the building blocks of modular neural nets and connect disparate threads of research.
📄 arxiv.org/abs/2302.11529
📢 ruder.io/modular-deep-learni…
🌐 modulardeeplearning.com
w/ @PfeiffJo @licwu @PontiEdoardo
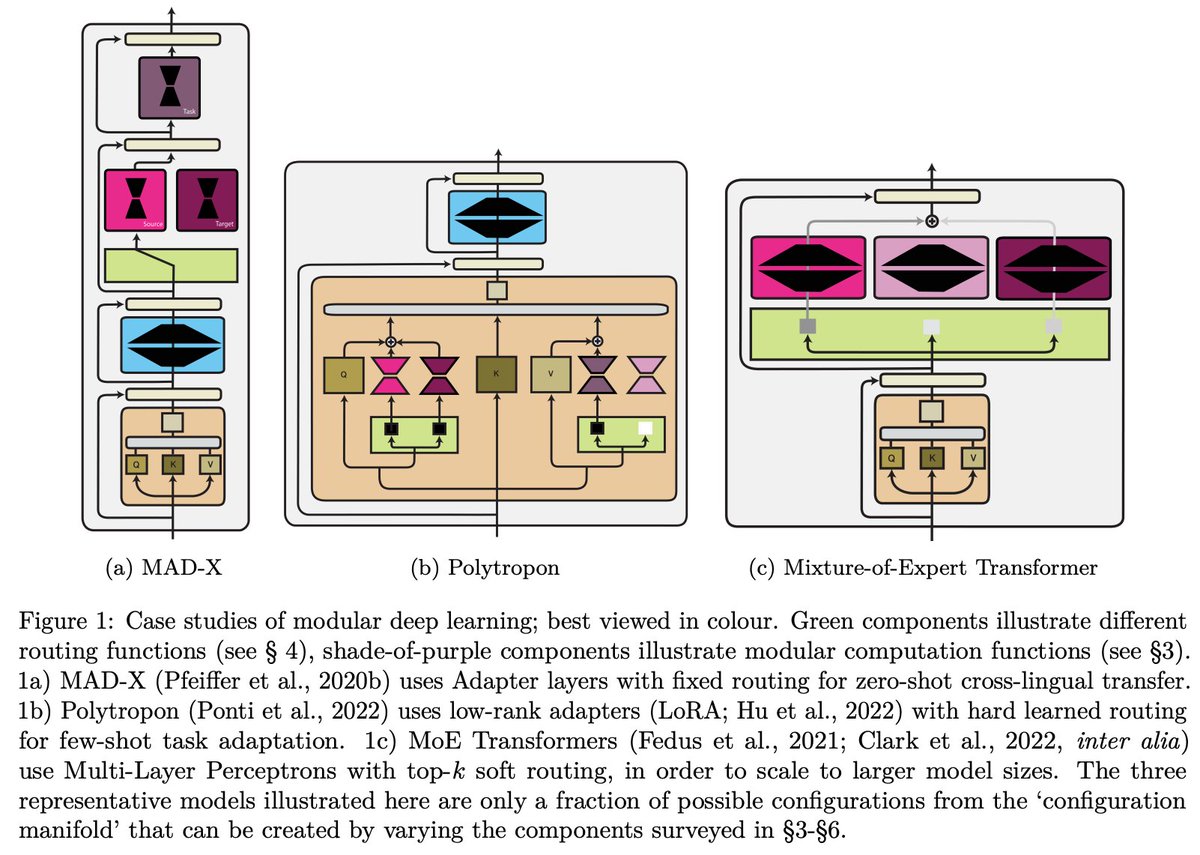
2
15
125
18,233
Ivan Vulić retweeted

14 Feb 2024
I am still looking for PhD students starting in September 2024! The deadline to apply for the CDT in NLP is the 11th of March.
If you wish to do research in modular and efficient LLMs, here are some highlights of my lab's research from the past year ⬇️🧵
7 Feb 2024

Interested in training with future leaders in NLP to engage with the cutting edge of the technical, social, design, and legal aspects of these systems? Then apply for our new Centre for Doctoral Training in Designing Responsible NLP! Deadline 11 March 2024 responsiblenlp.org/2024-stud…
10
51
145
48,192
1 Feb 2024
Think globally, act locally? Well, we were thought-experimenting whether LLMs would understand people from different places around our hometowns better than we ever might... And then we have eventually decided to make an actual (non-thought) experiment out of these thoughts! 👇👇
1 Feb 2024

Interested in commonsense reasoning in dialectal texts? The DIALECT-COPA shared task is the perfect fit for you, providing train and dev data for four official South-Slavic languages and two out of three related test dialects sites.google.com/view/vardia… @vardialworkshop @naaclmeeting
3
18
1,943
Ivan Vulić retweeted
30 Jan 2024
We scaled sparse fine-tuning (SFT) to LLMs (such as Llama 2) by making it both parameter- and memory-efficient!
(q)SFT instruction tuning performance is often better than (q)LoRA with comparable speed and memory load.
Paper: arxiv.org/abs/2401.16405
Code:
github.com/AlanAnsell/peft (SFT PEFT) github.com/ducdauge/sft-llm (experiments)
@AlanAnsell5 @licwu @h_sterz @annalkorhonen
1
66
230
45,976