
Google Research, Brain Team; and University of Toronto.
Joined November 2016
- Tweets 37
- Following 18
- Followers 449
- Likes 32
Photos and videos
David Fleet retweeted

7 Oct 2024
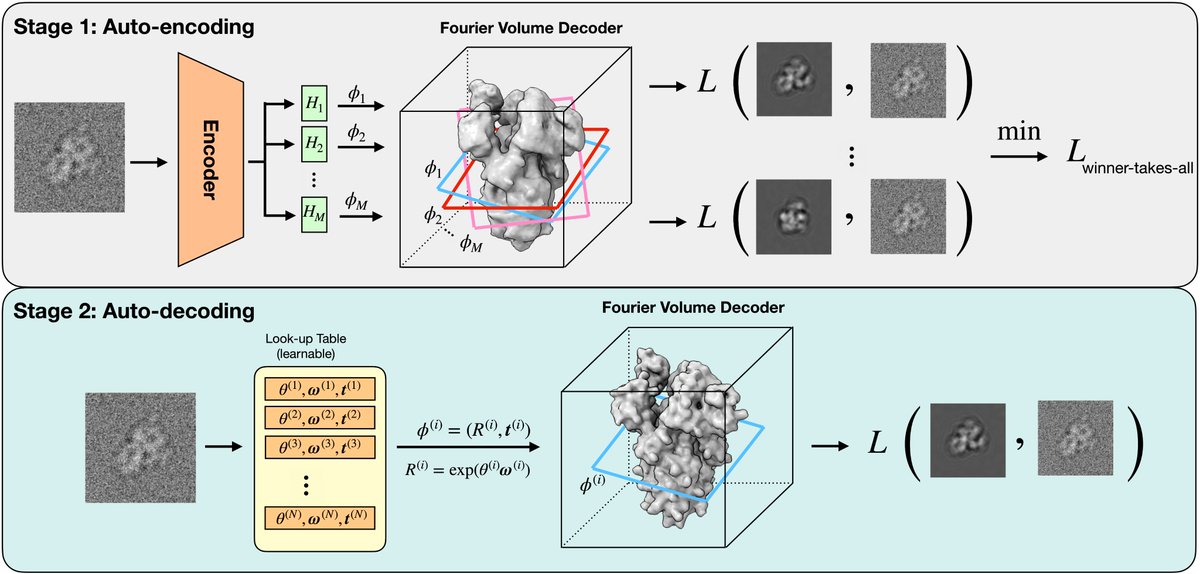
We compare our method with the state-of-the-art on both synthetic and experimental benchmarks. Empirically, cryoSPIN outperforms in reconstruction quality and FSC.
[6/7]
1
1
5
1,032
David Fleet retweeted
7 Oct 2024
🎉🎉Excited to share that “CryoSPIN” has been accepted to #NeurIPS2024!
Special thanks to my amazing collaborators and supervisors @DaveLindell, @marcusabrubaker, and @fleet_dj
Paper: arxiv.org/abs/2406.10455
Webpage: shekshaa.github.io/semi-amor…
Code is also released!
🧵[1/7]
6
27
157
22,425
David Fleet retweeted

2 Oct 2023
Why use RLHF when u can backprop through the sampler with any differentiable reward🥹🥹🥹
2 Oct 2023

Check out @clark_kev’s and my paper on fine-tuning diffusion models on differentiable rewards! We present DRaFT, which computes gradients through diffusion sampling. DRaFT is efficient & works across many reward functions.
With @kswersk, @fleet_dj
arXiv: arxiv.org/abs/2309.17400
2
6
910
David Fleet retweeted

2 Oct 2023
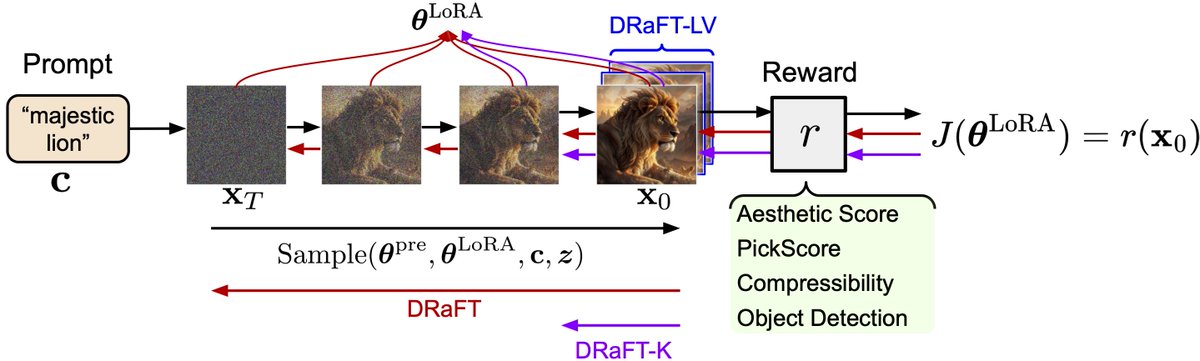
DRaFT backpropagates the reward directly into LoRA parameters – we don’t need to use RL because diffusion sampling is differentiable. We improve efficiency by truncating the BPTT; even truncating to one step still works! (2/5)
1
2
8
1,025
David Fleet retweeted
2 Oct 2023
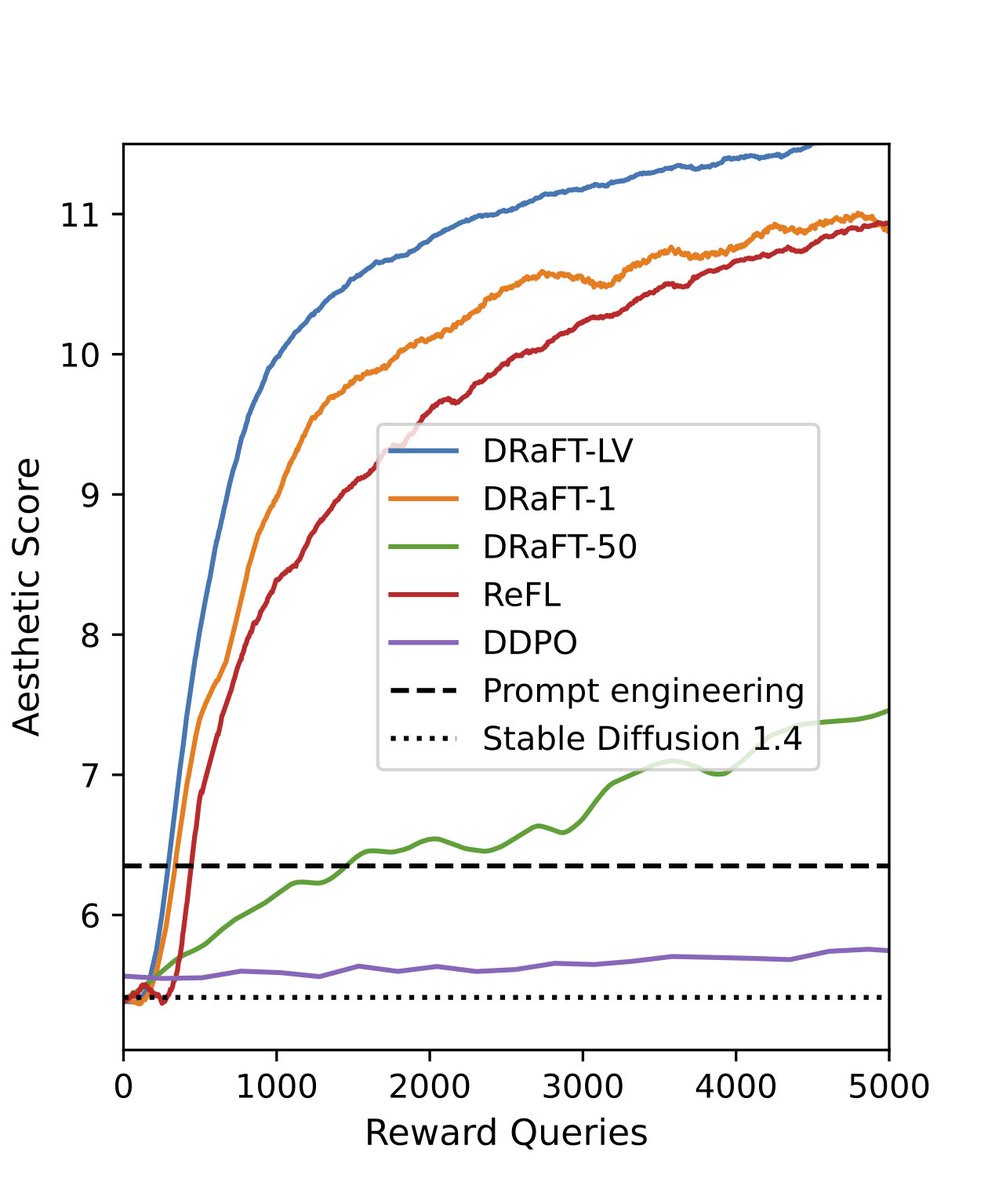
Our best variant, DRaFT-LV, learns 2x faster than ReFL (arxiv.org/abs/2304.05977) and 100x faster than RL. (3/5)
2
2
5
899
David Fleet retweeted

28 Mar 2023
.@clark_kev & I are excited to share our new work on studying Imagen by evaluating it as a zero-shot classifier! Highlights include Imagen achieving SoTA on Stylized Imagenet and being able to perform attribute binding in certain settings unlike CLIP
arxiv.org/abs/2303.15233
🧵👇
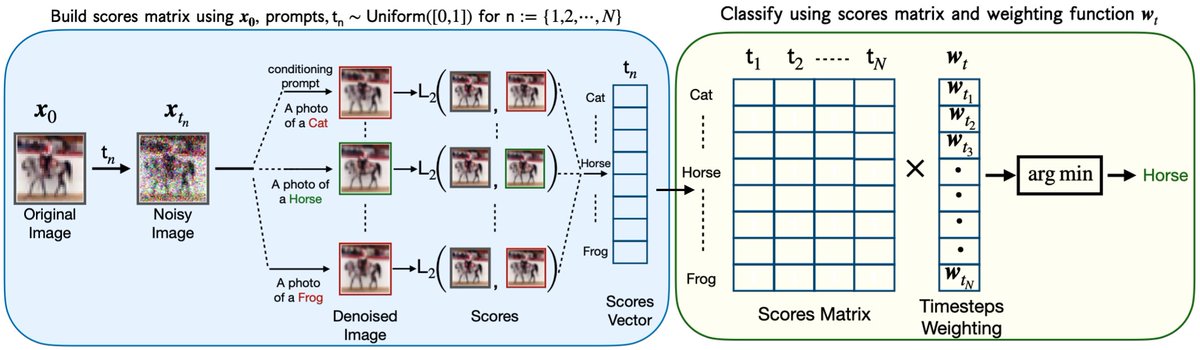
ALT Zero-Shot Classification using Imagen.
1
18
46
13,752
David Fleet retweeted
2 Oct 2023
We can reduce the effect of the fine-tuning or mix different reward functions post-training simply by scaling down or mixing LoRAs. (4/5)

1
2
5
961
David Fleet retweeted

12 May 2023
📄 An updated paper describing 3D Flexible Refinement is now out in @naturemethods!
Paper: nature.com/articles/s41592-0…
It describes further experimental #cryoEM results and the improved 3DFlex method that was released in #CryoSPARC v4.1 ❄️⚡
Tutorial: guide.cryosparc.com/processi…
12 Dec 2022

1/ We’re thrilled to announce that 3D Flexible Refinement, a motion-based deep generative model for continuous heterogeneity in #cryoEM structures, is available today in #CryoSPARC v4.1 Beta! ❄️⚡
Read more about v4.1: cryosparc.com/updates
23
85
15,441

Monocular Depth Estimation using Diffusion Models
abs: arxiv.org/abs/2302.14816
project page: depth-gen.github.io
5
76
349
67,369
David Fleet retweeted

17 Feb 2023
Awesome work by Hshmat. The work showcases yet another evidence of how effective noise conditioning augmentation can be.
17 Feb 2023

Thrilled to announce SR3 , our new model that establishes a new state-of-the-art on diffusion-based super-resolution for images in the wild!
arxiv.org/abs/2302.07864
Joint work w/ @watson_nn @Chitwan_Saharia @fleet_dj
1
17
4,206
David Fleet retweeted

17 Feb 2023
Thrilled to announce SR3 , our new model that establishes a new state-of-the-art on diffusion-based super-resolution for images in the wild!
arxiv.org/abs/2302.07864
Joint work w/ @watson_nn @Chitwan_Saharia @fleet_dj
2
11
89
16,741
David Fleet retweeted

19 Jan 2023
We've just released the first version of our Deep Learning Tuning Playbook! This is our attempt to distill our process for actually getting good results with deep learning. We emphasize hyperparameter tuning since it has been a large pain point. github.com/google-research/t…
44
793
3,616
671,314
David Fleet retweeted
4 Oct 2022
Excited to announce our work on novel view synthesis with diffusion models! Our model can lift a single 2d image into 3d.
3d-diffusion.github.io
Joint work w/ @wchan212 @rmbrualla @hojonathanho @taiyasaki @mo_norouzi
62
871
4,246
David Fleet retweeted

5 Oct 2022
Excited to announce Imagen Video, our new text-conditioned video diffusion model that generates 1280x768 24fps HD videos! #ImagenVideo
imagen.research.google/video…
Work w/ @wchan212 @Chitwan_Saharia @jaywhang_ @RuiqiGao @agritsenko @dpkingma @poolio @mo_norouzi @fleet_dj @TimSalimans
53
684
3,179

Happy to announce DreamFusion, our new method for Text-to-3D!
dreamfusion3d.github.io
We optimize a NeRF from scratch using a pretrained text-to-image diffusion model. No 3D data needed!
Joint work w/ the incredible team of @BenMildenhall @ajayj_ @jon_barron
#dreamfusion
127
1,390
5,473
David Fleet retweeted

4 Jun 2022
If you don’t think DallE-2 and Imagen are an Alexnet level moment in the machine learning world you aren’t paying attention enough. Very impressive visual results coming out of these. Getting similar chills to when I saw first web browser, iPhone, etc.

“Oriental painting of tigers wearing VR headsets during the Song dynasty” generated using #Imagen

15
76
413
David Fleet retweeted
19 Jun 2022
Daniel has created some of the most amazing #Imagen images so far. Keep an eye out.
19 Jun 2022

"A photo of a giant sloth drinking a cup of coffee in the dawn light"
Generated with #Imagen, a new text-to-image diffusion model from the very smart folks at Google Brain. I'll be sharing much more, so stay tuned!

2
11
79
David Fleet retweeted

3 Jun 2022
If you have any kind of feedback for the #imagen team, we'd love to hear it! imagen.research.google
@Chitwan_Saharia, @wchan212, @srbhsxn, Lala Li, @jaywhang_, @cephaloponderer, @coolboi95, Burcu Karagol Ayan, Sara Mahdavi, @iraphas13, @TimSalimans, @hojonathanho, @fleet_dj.

8
3
23
David Fleet retweeted

29 May 2022
It was 16 years ago, in 2006, that @geoffreyhinton et al released their demo of deep belief nets. Undergrad me was highly impressed, and helped convince me that deep learning was the way to go. I refreshed Geoff's website almost every day checking for new papers... (1/n)
10
247
1,591
