
14 Photos and videos










Happy to introduce 🔥LaM-SLidE🔥!
We show how trajectories of spatial dynamical systems can be modeled in latent space by
--> leveraging IDENTIFIERS.
📚Paper: arxiv.org/abs/2502.12128
💻Code: github.com/ml-jku/LaM-SLidE
📝Blog: ml-jku.github.io/LaM-SLidE/
1/n
1
19
34
3,021
Florian retweeted

We unlocked the working memory of LLMs 💥
Reasoning in Memory (RiM) replaces autoregressive "thinking out loud" with fixed memory blocks that form a task-specific workspace for latent reasoning.
The key idea is simple: reasoning should happen inside the LLM, not in its output!
27
52
314
57,476
Florian retweeted
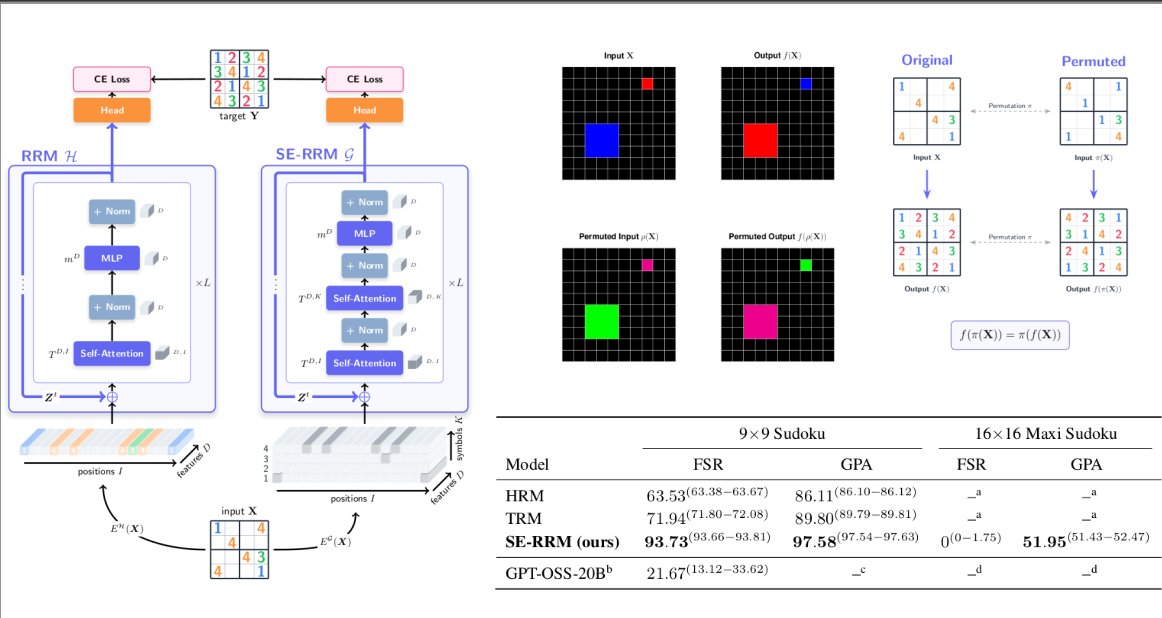
Symbol-equivariant Recurrent Reasoning Models (SE-RRM)
SE-RRM advances HRM and TRM -- guaranteed identical solutions for problems with permuted colors (ARC AGI) or digits (Sudoku).
Coolest part: extrapolation to larger problem sizes!!!
P: arxiv.org/abs/2603.02193
3
41
213
14,139
Florian retweeted

Jan 15
# AI in Drug discovery just BROKE THROUGH a wall #
A newer AI model, ConGLUDe, as fast but much more accurate than DrugCLIP.
Instead on just 40K structure-based data, ConGLUDe is trained on 100M datapoints from ligand-based data
P: arxiv.org/abs/2601.09693

Jan 12

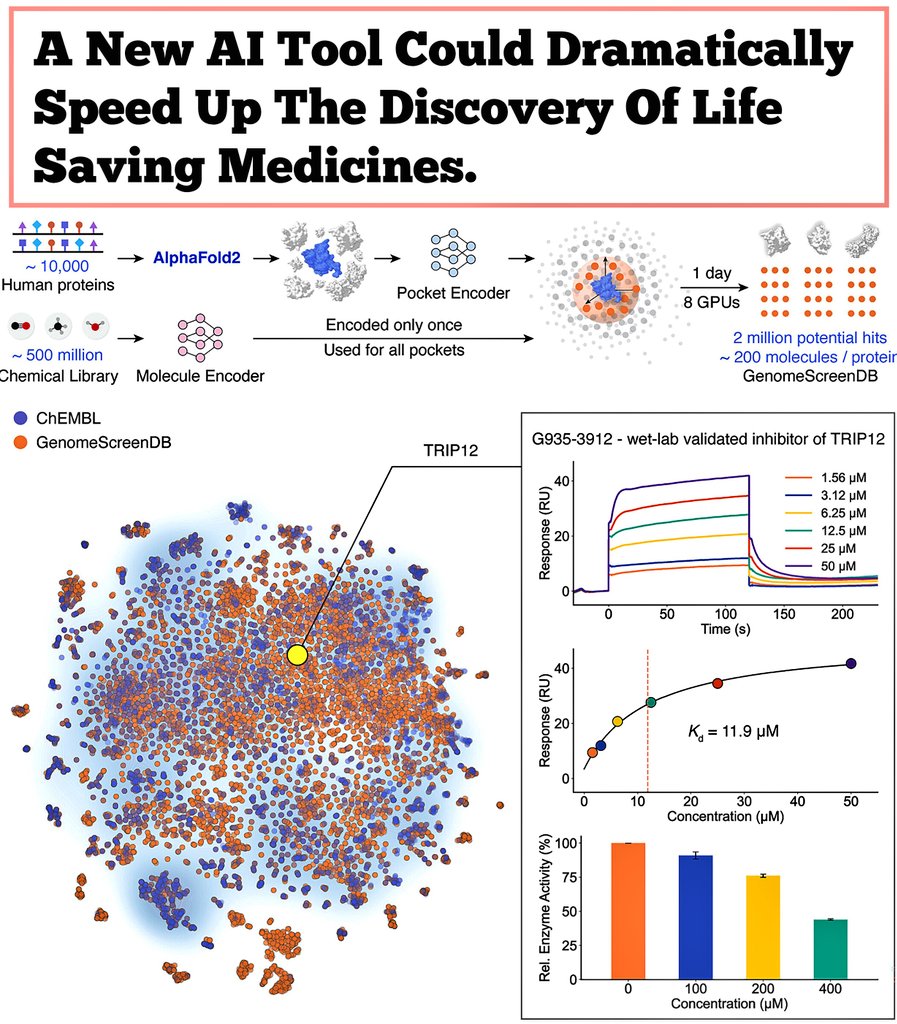
BIG BREAKTHOUGH: A new AI tool could dramatically speed up the discovery of life saving medicines.
Researchers at Tsinghua University created a new system called DrugCLIP, that can screen drug molecules against human proteins at a speed that makes traditional methods look ancient.
> DrugCLIP uses deep contrastive learning to turn both molecules and protein binding pockets into vectors and match them almost instantly.
> It screened 500 million molecules across 10,000 human proteins, covering half of the entire human druggable proteome.
> The system completed 10 trillion molecule protein evaluations in a single day, roughly 10 million times faster than classic docking simulations.
> They used AlphaFold2 to generate protein structures and then refined binding pockets with a custom tool called GenPack.
> The model even identified compounds for TRIP12, a protein linked to cancer and autism that has resisted traditional drug-targeting approaches.
All data and models are open access, so labs worldwide can now speed up early stage drug discovery.
10
59
293
26,405
Florian retweeted
9 Dec 2025
The Great Comeback of Self-Normalizing Networks in 2025:
It’s been a wild year in AI and for SNNs SELU!!
See my overview and some trends here:
Blog: bioinf-jku.github.io/SNNs/

3
1
13
867
Florian retweeted

3 Dec 2025
📢 Another #NeurIPS, another diffusion circle!
Join us to talk about diffusion models on Friday Dec 5 at 3:30PM in San Diego! Bayside terrace outside room 11 (upstairs) ☀️🚢🌊
Please help spread the word, tell your friends! No slides, no talks, we just sit down and chat 🗣️
7
34
215
63,583
Florian retweeted
7 Nov 2025
Introducing our invited speakers at #ML4Molecules2025:
Rocio Mercado ( rociomer.github.io ): Tenure-track professor at Chalmers University. Her work bridges machine learning and molecular discovery.
Registration (free!): moleculediscovery.github.io/…

3
13
1,104
“In the judgement of the most competent living mathematicians, Fräulein Noether was the most significant creative mathematical genius thus far produced since the higher education of women began.”
– Albert Einstein, 1935 (NYTimes)
I’m thrilled to share that I’ll be joining emmi.ai, a company inspired by the legacy of Emmy Noether, for my upcoming internship.
Over the next few months, I’ll have the opportunity to work with Sebastian Kaltenbach on my passion: Diffusion and Flow-based generative models, and their applications to physics. Excited for what lies ahead!
While Noether devoted her life to uncovering the beauty of symmetries, our recent work explores a different path—approaching the problem without explicitly enforcing them.
I’m proud that this work, done together with amazing collaborators @ArturToshev , Andreas Fürst, @gklambauer , @AndreasMayr11 , @jo_brandstetter , has been accepted to @NeurIPSConf 2025 in San Diego.
arxiv.org/abs/2502.12128
3
98
Florian retweeted
21 Oct 2025
Celebrating 4,000 citations!
Thanks everyone who successfully used self-normalizing networks!!!

3
2
85
5,449
Florian retweeted

20 Oct 2025
Nice, short post illustrating how simple text (discrete) diffusion can be.
Diffusion (i.e. parallel, iterated denoising, top) is the pervasive generative paradigm in image/video, but autoregression (i.e. go left to right bottom) is the dominant paradigm in text. For audio I've seen a bit of both.
A lot of diffusion papers look a bit dense but if you strip the mathematical formalism, you end up with simple baseline algorithms, e.g. something a lot closer to flow matching in continuous, or something like this in discrete. It's your vanilla transformer but with bi-directional attention, where you iteratively re-sample and re-mask all tokens in your "tokens canvas" based on a noise schedule until you get the final sample at the last step. (Bi-directional attention is a lot more powerful, and you get a lot stronger autoregressive language models if you train with it, unfortunately it makes training a lot more expensive because now you can't parallelize across sequence dim).
So autoregression is doing an `.append(token)` to the tokens canvas while only attending backwards, while diffusion is refreshing the entire token canvas with a `.setitem(idx, token)` while attending bidirectionally. Human thought naively feels a bit more like autoregression but it's hard to say that there aren't more diffusion-like components in some latent space of thought. It feels quite possible that you can further interpolate between them, or generalize them further. And it's a component of the LLM stack that still feels a bit fungible.
Now I must resist the urge to side quest into training nanochat with diffusion.
20 Oct 2025

BERT is just a Single Text Diffusion Step! (1/n)
When I first read about language diffusion models, I was surprised to find that their training objective was just a generalization of masked language modeling (MLM), something we’ve been doing since BERT from 2018.
The first thought I had was, “can we finetune a BERT-like model to do text generation?”
268
528
5,206
867,170
Florian retweeted
7 Oct 2025
PAPER/ABSTRACT DEADLINE ALREADY END OF THIS WEEK!
ELLIS Machine Learning for Molecules workshop: moleculediscovery.github.io/…
DON'T MISS THE DEADLINE: short papers or extended abstracts welcome!
1
1
10
739
Florian retweeted

3 Oct 2025
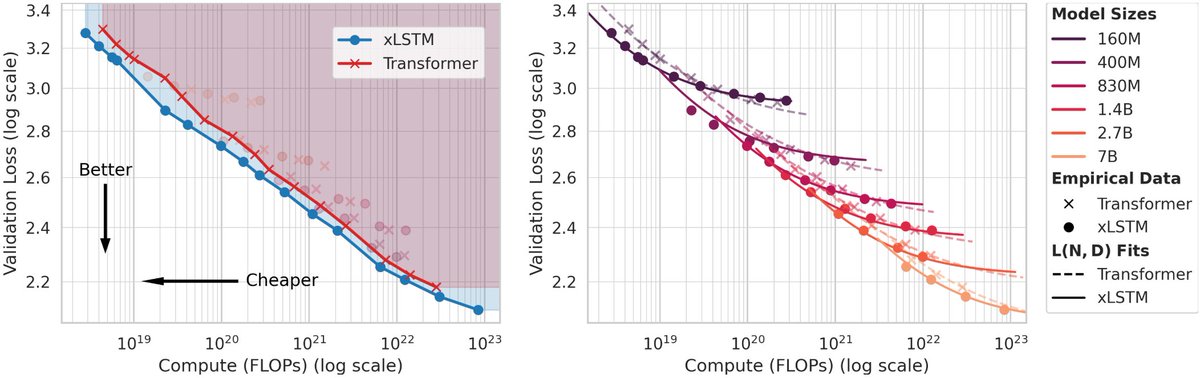
🚀 Excited to share our new paper on scaling laws for xLSTMs vs. Transformers.
Key result: xLSTM models Pareto-dominate Transformers in cross-entropy loss.
- At fixed FLOP budgets → xLSTMs perform better
- At fixed validation loss → xLSTMs need fewer FLOPs
🧵 Details in thread
14
41
231
84,866
Florian retweeted
23 Sep 2025
It's happening again!!!
ML4Molecules workshop 2025.
within the #ELLIS Unconference, preceding #EurIPS.
More infos: moleculediscovery.github.io/…

1
8
36
2,777
Florian retweeted

4 Aug 2025
Paper by bytedance, improves upon Meanflow by removing the need for JVP calculation

6
22
216
14,764

if you're interested in building the future of creative tools with us, we're hiring!
krea.ai/careers
4
2
23
6,476
Florian retweeted

2 Aug 2025
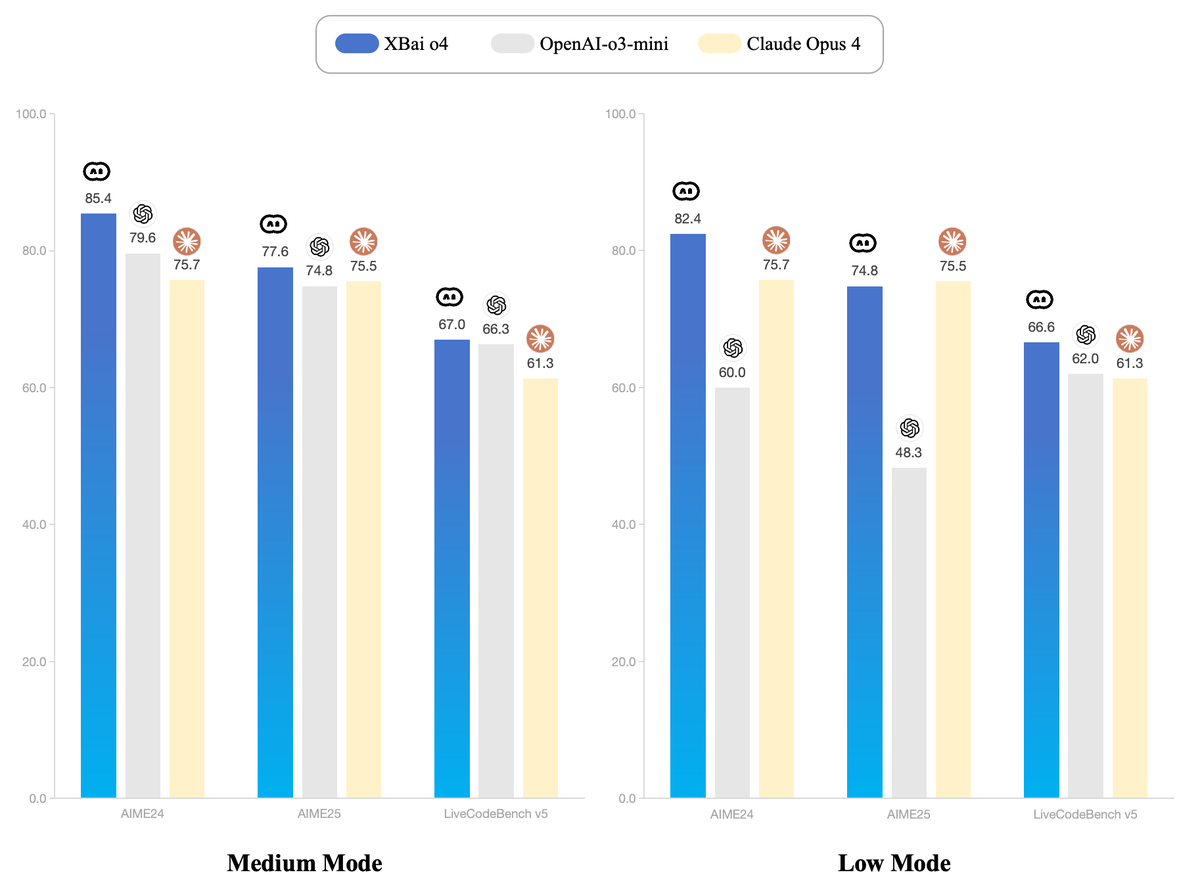
🚀 Introducing XBai o4:a milestone in our 4th-generation open-source technology based on parallel test time scaling!
In its medium mode, XBai o4 now fully outperforms OpenAI−o3−mini.📈
🔗Open-source weights: huggingface.co/MetaStoneTec/…✅
Github link: github.com/MetaStone-AI/XBai…

74
220
1,308
363,029
Florian retweeted

17 Jul 2025
General relativity 🤝 neural fields
This simulation of a black hole is coming from our neural networks 🚀
We introduce Einstein Fields, a compact NN representation for 4D numerical relativity. EinFields are designed to handle the tensorial properties of GR and its derivatives.
11
73
321
39,337
Florian retweeted
30 Jun 2025
We release AB-UPT, a novel method to scale neural surrogates to CFD meshes beyond 100 million of mesh cells. AB-UPT is extensively tested on the largest publicly available datasets.
📄 arxiv.org/abs/2502.09692
🤗 huggingface.co/EmmiAI/AB-UPT
💻 github.com/Emmi-AI/AB-UPT
1
15
67
3,989
Florian retweeted
16 Jun 2025
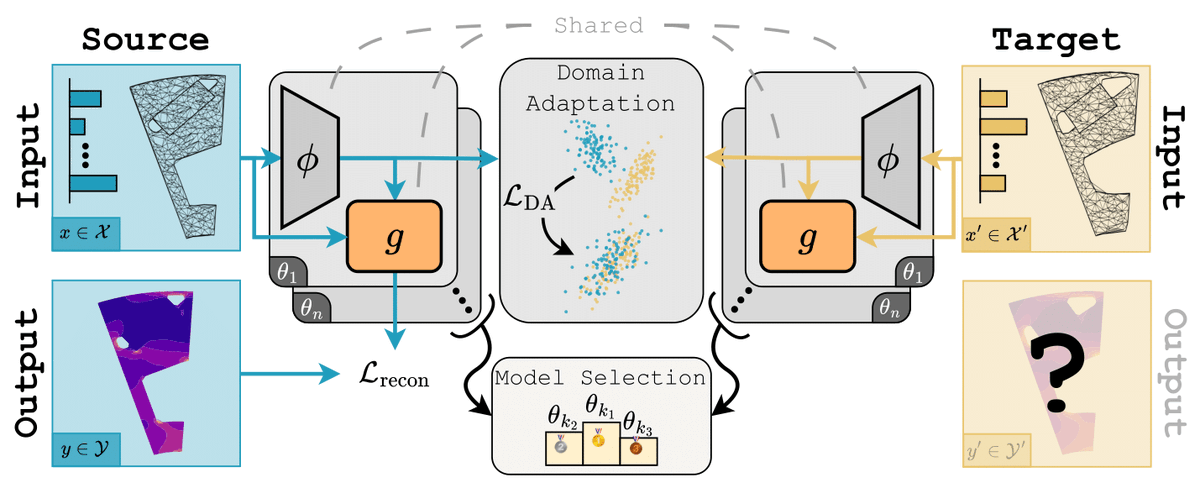
We introduce SIMSHIFT: A Benchmark for Adapting Neural Surrogates to Distribution Shifts. I sincerely hope that new ideas are coming out from this benchmark.
Paper: arxiv.org/abs/2506.12007
Code: github.com/psetinek/simshift
1
6
32
1,884
Florian retweeted

5 Jun 2025
Great discussion, @chaitjo! We also explored this with extensive experiments in our recent paper: arxiv.org/abs/2501.01999. We find, among others, that equiv mods in a sense scale even better than non-equiv ones. Going more or less completely against the vibes from your post😅1/5
1 Jun 2025

After a long hiatus, I've started blogging again!
My first post was a difficult one to write, because I don't want to keep repeating what's already in papers.
I tried to give some nuanced and (hopefully) fresh takes on equivariance and geometry in molecular modelling.

2
16
86
11,893
Florian retweeted

4 Jun 2025
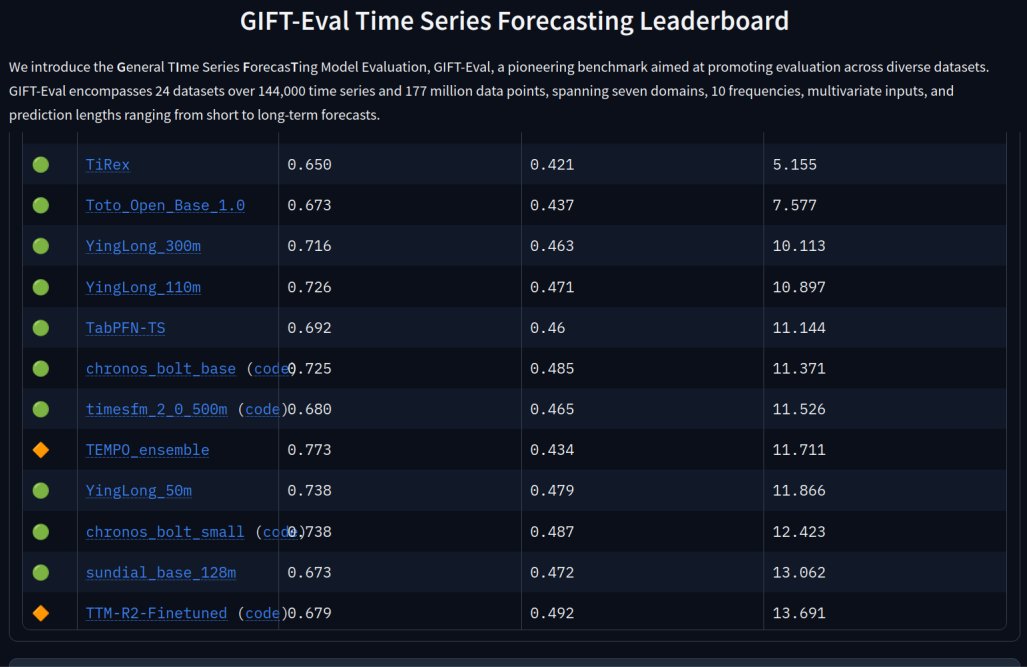
A European-developed TiRex is leading the field—significantly ahead of U.S. competitors like Amazon, Datadog, Salesforce, and Google, as well as Chinese models from companies such as Alibaba.
2 Jun 2025

GIFT-Eval Time Series Forecasting Leaderboard
Evaluates time-series forecasting methods. Now leading: TiREX arxiv.org/abs/2505.23719
Link: huggingface.co/spaces/Salesf…
2
11
34
2,667