
Your favorite GPU community
Joined September 2024
- Tweets 249
- Following 14
- Followers 8,834
- Likes 368
41 Photos and videos

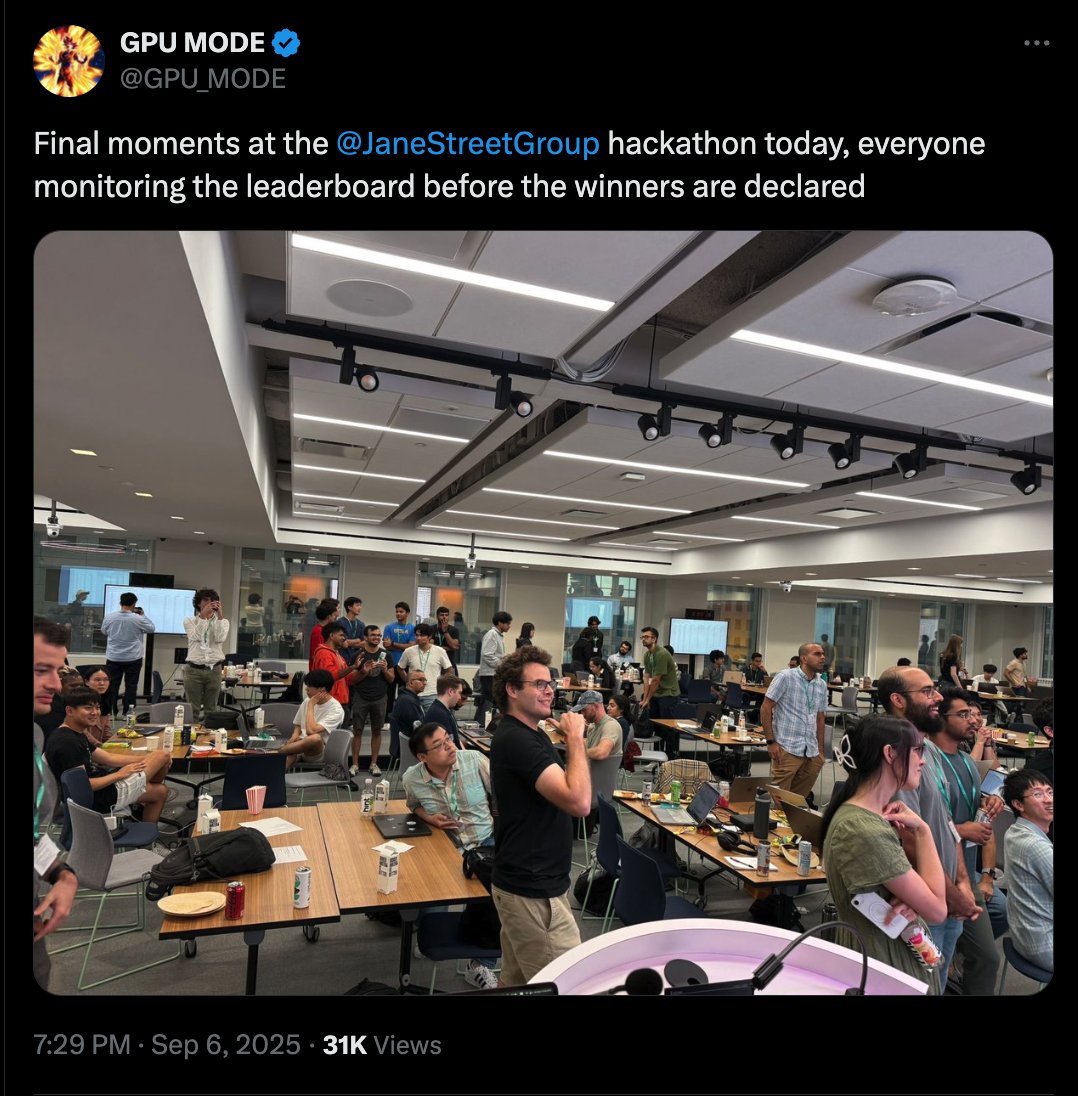
GPU MODE retweeted

Jun 12
Launching a new kernel competition: Linear Algebra Kernels For The Age Of Research.
First problem: batched QR decomposition on B200. Old math, modern hardware.
Prize: Rare swag and hangout in SF
Jun 10

I have some mixed feelings about this result:
On the one hand, it's genuinely impressive. I didn't know that Shampoo could be configured to perform this well on the benchmark.
On the other hand, the way this performance boost was achieved seems difficult to call "Vanilla," for the following reason:
According to @_arohan_, the boost depends upon fixing a numerical linear algebra issue that he observed to occur in my initial standard DistributedShampoo run. He fixed the issue by enabling the flag rank_deficient_stability_config=PseudoInverseConfig().
Here's the problem: This is an undocumented flag. It is contained within the 12,000-line DistributedShampoo codebase, but it does not appear in any user-facing documentation.
As a result, if someone tries to train a model using DistributedShampoo without either (a) knowing about this special undocumented flag or (b) being prepared to detect and fix the numerical linear algebra issues that may occur without it, then they won't be able to achieve @_arohan_'s level of Shampoo performance. This level of effort would be considered atypical for mere hyperparameter tuning.
--
[Note on Muon baseline in plot below: Rohan's post compared Shampoo to a slightly undertuned Muon baseline from 2026/05/01, which reached the target loss in 3375 steps. This resulted in a 50-step gap between Shampoo and Muon. In the figure below I'm using the up-to-date 2026/05/03 baseline, which reaches the target in 3325 steps. This results in the step-counts exactly matching between Muon and the tuned/stabilized Shampoo variant.]

12
29
380
130,317
GPU MODE retweeted
Jun 9
GPU MODE has powered much of the public GPU kernel work online, with a permissive license from day one and generous credit from researchers, NVIDIA, AMD, and others.
Today we’re moving our datasets to the Researcher Reciprocity License.
Jun 9

June 9th Researcher Reciprocity License
"if you train on it, you let us generate - reverse terms of use void"
Status quo
1. We teach frontier devs with ICLR/NeurIPS papers, OSS Github contributions
2. They use it to make frontier models
3. Then ban us from exploring our ideas
We need a new license, original thinkers can't be an underclass to a tyrannical researcher fiefdom
8
26
422
32,795


Since the Humanity's Last Hackathon from @huggingface didn’t happen, I set up my own mini version using Kernelbot and Popcorn from @gpu_mode.
> The goal was to test how well LLMs can generate code for difficult tasks, like writing faster kernels for Apple’s MPS with @PyTorch.
> My strategy was to let the LLM submit a kernel, get feedback from the benchmark, and then iterate based on the learnings.
> The hardest part was not the code generation itself, but coordinating all the systems. Kernelbot, Popcorn, submissions, feedback, orchestration...
> The benchmark eats almost all my RAM, so parallelizing too many submissions is hard. My machine starts crashing if I push it too much.
Overall, I need more time to tune the prompts, experiment with better feedback loops, and maybe try some RL-style iteration. There are still lots of techniques worth exploring here.
In the video:
Left: task orchestrator
Right: live dashboard tracking submissions, code, and lessons learned
2
10
1,725


Codex is so good at writing kernels that it felt appropriate to do a Codex only kernel competition. Metal is great because you'll be able to tangibly feel the perf improvements in your local models
Apr 28

Humanity's Last Hackathon is NOW OPEN for registration.
This is not a normal hackathon. You will be judged on the context, not the code!
Use Codex @OpenAIDevs to build and optimize models for local inference (kernels on Max metal). Submit through @GPU_MODE.
Climb the leaderboard. Top performers qualify for the final battle.
Launches May 4th. Registration is live now.
3
63
5,909
GPU MODE retweeted

Apr 28
Humanity's Last Hackathon is NOW OPEN for registration.
This is not a normal hackathon. You will be judged on the context, not the code!
Use Codex @OpenAIDevs to build and optimize models for local inference (kernels on Max metal). Submit through @GPU_MODE.
Climb the leaderboard. Top performers qualify for the final battle.
Launches May 4th. Registration is live now.
21
36
367
91,041
GPU MODE cited on @tbpn - thank you for the plug @AnushElangovan !!
We hope to continue making GPU programming more accessible to everyone!

AMD's @AnushElangovan explains why he thinks his company's open source ethos combined with agentic AI superpowers their leverage as a company:
Because AMD publishes a lot of technical details about its hardware, when engineers use AI tools, the models already “understand” AMD’s systems and can help write code for them, debug them, or even generate new tools.
And that makes developers more productive on AMD hardware without AMD having to do all the work internally.
"AMD has had this ethos of open source, which really plays to our advantage. Every frontier model that I use has already seen every bit of AMD source code."
"It'll rewrite my spec for me because it's already in the training data. Which you can't get from closed ecosystems."
"In fact I built a virtual GPU simulator just based off our public specs, and now I'm running it on the GPU. So now I can run cross-generational GPU simulations on existing hardware."
"We have that advantage. And we've run a Dev Day contest where we generated more tokens on AMD — Triton kernels and HIP kernels — than existed on the internet at the time."
"So now that's all part of the pre-training data. It's a superpower because now you're open source, and you're agentically accelerating this process."
2
1
39
8,370
Gluon and Linear Layouts. Tomorrow noon PST youtube.com/watch?v=GC7-_oP9…
2
19
2,414
GPU MODE retweeted

Apr 19
My colleagues Jack Carlisle and Jay Shah gave a fantastic lecture for @GPU_MODE yesterday on our categorical foundations for CuTe layout algebra! They were joined by Cris Cecka, the inventor of CuTe, and @marksaroufim as moderators. Bravi tutti!
youtu.be/MVh_guNbWMA?si=zpiP…
2
9
59
5,449
Jack Carlisle & Jay Shah talk on the Fundamentals of CuTe Layout Algebra. Special guest Cris Cecka
See you soon! youtube.com/watch?v=8QfQd85N…
1
12
61
5,302
GPU MODE retweeted

Apr 13
our "@pleiasfr and friends" team got second place at the @GPU_MODE hackathon in Paris last week! 🥈
we had a lot of fun optimizing our training throughput, so trying out 8 bit training, muon, RoPE/NoPE, conv architectures, ... Basically nanogpt speedrunning on B300s.

ALT GPUs slowly going more and more brrrrrr

We’re sponsoring a @GPU_MODE hackathon in Paris on April 9, to conclude the PyTorch Conference Europe 🇪🇺
Our grand prize? 48 hours on GB300 NVL72.
Join us with the teams behind @PyTorch, @PrimeIntellect, @SemiAnalysis_, @sestercegroup, and more!
luma.com/gpu-mode-paris-2026…

5
3
31
7,079
We're back on schedule Tuesday April 14 at 9am PST we'll have a talk from Andrei Panferov and Erik Schultheis on their improved recipe for nvfp4 pretraining. They'll cover both math and kernels youtube.com/watch?v=HB4up2sz…
13
62
6,296
GPU MODE retweeted

Matej Sirovatka from @PrimeIntellect sharing how @arcee_ai trinity was trained


4
9
124
12,187
Incredible release
Apr 3

Trtllmgen kernels are now open. Fastest prefill and decode kernels for our target workloads. We wrote these to win InferenceX, MLPerf, other benchmarks. Powering some of today’s top served models. Dive in, learn, use them, or level up your own. Enjoy.
github.com/flashinfer-ai/fla…
2
3
33
7,129
