
141 Photos and videos













Just open-sourced Gust, our task orchestration system. Like Airflow, but faster and much more efficient, written in Elixir.
Check it out!
github.com/marciok/gust

2
6
531
*Gust v0.1.32 is out!* with significant new features:
> skip_if: dynamic conditional execution for downstream tasks
> Custom params when creating runs via the API.
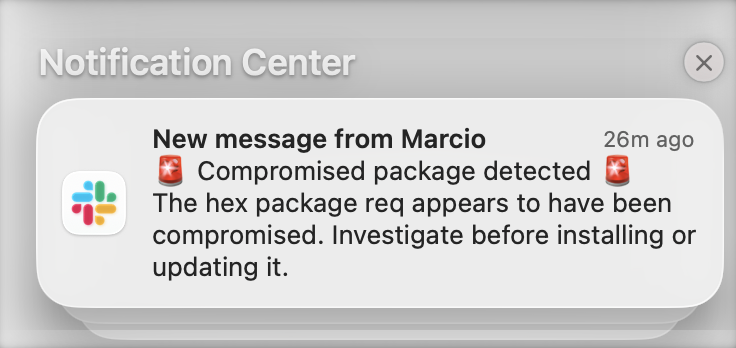
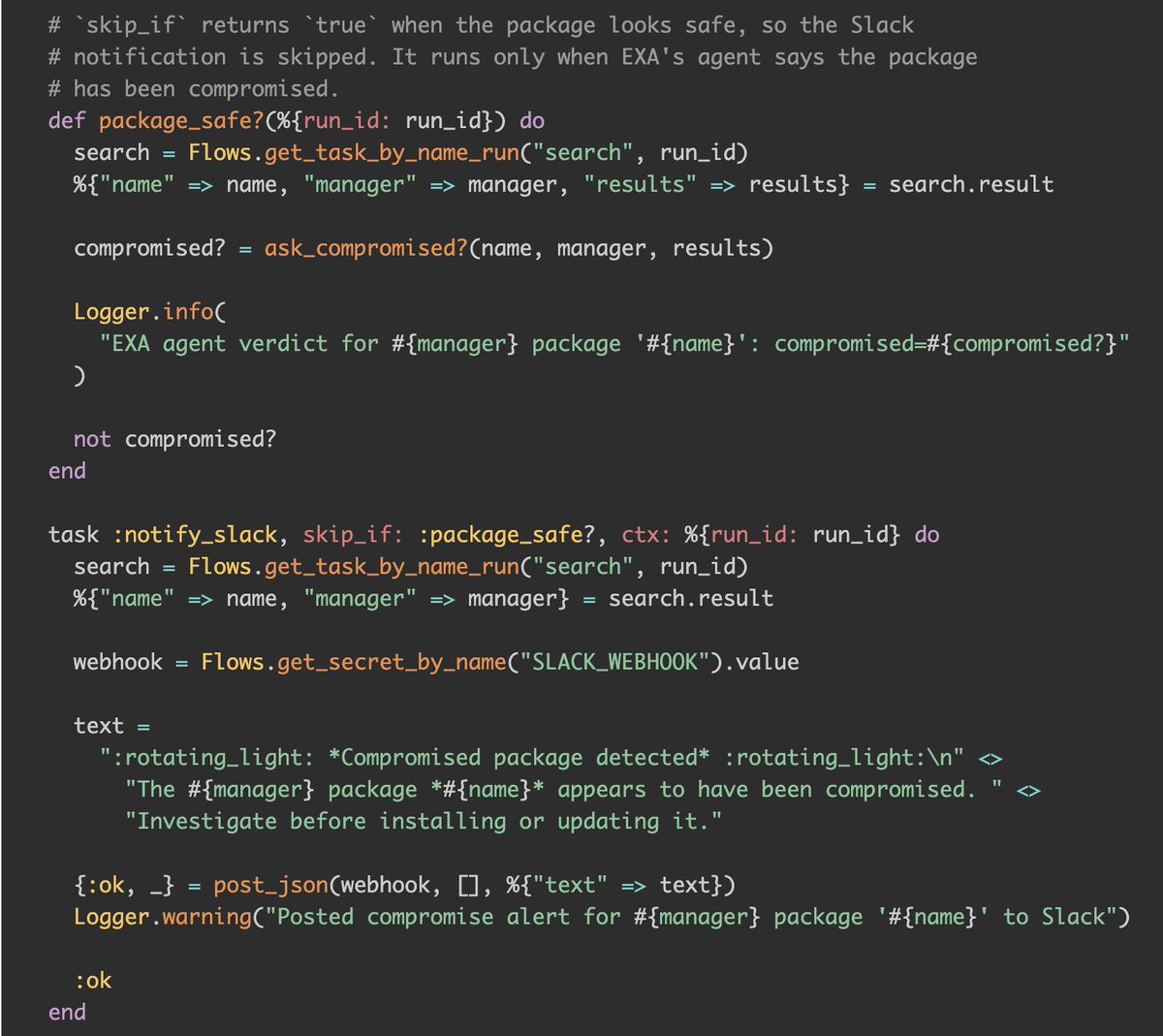
Ex: I asked Claude to create a workflow that monitors compromised packages. It searches news using @ExaAILabs / @ExaDevelopers, evaluates severity, and alerts me on Slack if it looks critical.
github.com/marciok/gust
3
2
195
Marcio K retweeted

May 25
AI is probabilistic, not deterministic. 🧠
@MarcioK People are forgetting that for workflows with clear, definitive answers, traditional code is still king. Use AI to build the algorithm, don't let AI be the algorithm—unless you want your deployments to break.
#AI #TechTalk
6
2
17
1,071
The most underrated language, ecosystem and community 💜

From @josevalim's first commit to millions of lightweight processes running in production — happy anniversary @elixirlang! 💜

1
50
Marcio K retweeted

May 19
The worst part of doing dev work on a Mac: .DS_STORE
159
99
4,015
499,736
Since the Humanity's Last Hackathon from @huggingface didn’t happen, I set up my own mini version using Kernelbot and Popcorn from @gpu_mode.
> The goal was to test how well LLMs can generate code for difficult tasks, like writing faster kernels for Apple’s MPS with @PyTorch.
> My strategy was to let the LLM submit a kernel, get feedback from the benchmark, and then iterate based on the learnings.
> The hardest part was not the code generation itself, but coordinating all the systems. Kernelbot, Popcorn, submissions, feedback, orchestration...
> The benchmark eats almost all my RAM, so parallelizing too many submissions is hard. My machine starts crashing if I push it too much.
Overall, I need more time to tune the prompts, experiment with better feedback loops, and maybe try some RL-style iteration. There are still lots of techniques worth exploring here.
In the video:
Left: task orchestrator
Right: live dashboard tracking submissions, code, and lessons learned
2
10
1,726
Gust reached v0.1.30!
Best part: our first major outside contribution 🩵
Install via Igniter:
`mix igniter.new my_app --install gust_web --with phx.new`
Or run with Docker:
github.com/marciok/gust/tree…
1
1
56
Thanks @ElixirConfEU for an amazing time!
Great talks and great people.
Still unpacking all the feedback and learnings!.

1
65
Let's go! I'll be speaking on Friday, 3:20 pm

ElixirConf EU 2026 starts this Wednesday with our training day, followed by the main event!
Join @josevalim, @chris_mccord, @whatyouhide, and @redrapids, for deep dives into Elixir and the BEAM ecosystem.
Final tickets are available here: elixirconf.eu/

89
They arrived!
I made a few hats to bring to the @ElixirConfEU
If you want one, get a PR merged for any issue tagged `gust-hat`
github.com/marciok/gust/issu…
#MyElixirStatus #elixir

1
4
16
1,013
[#Python vs #Elixir]
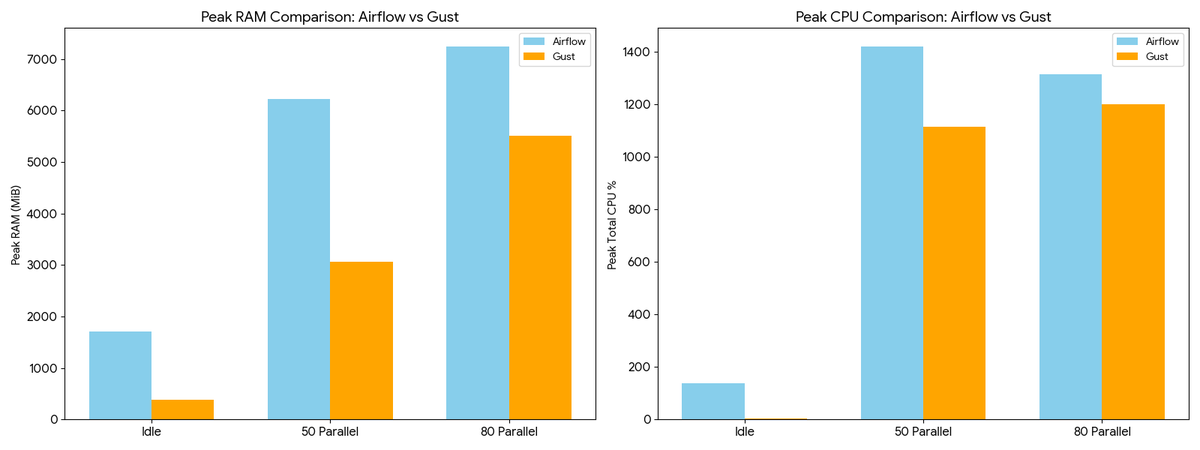
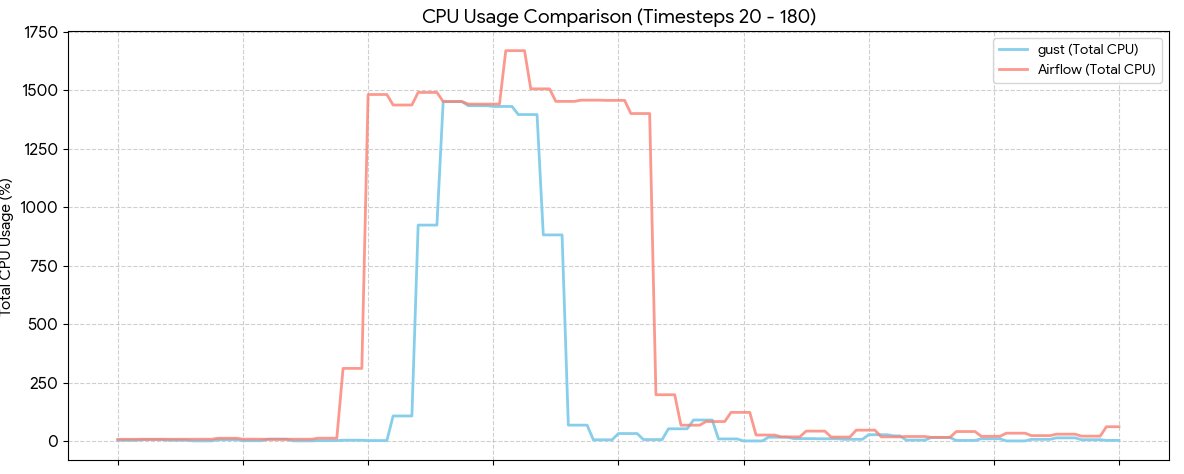
CPU benchmark: @ApacheAirflow vs Gust
- Idle: Gust ~30% more efficient
- High load: both hit ~1500% (~15 cores)
- Airflow: worker-heavy
- Gust: distributed load
Much smaller memory footprint with Gust.
Full results soon: github.com/marciok/gust
1
75
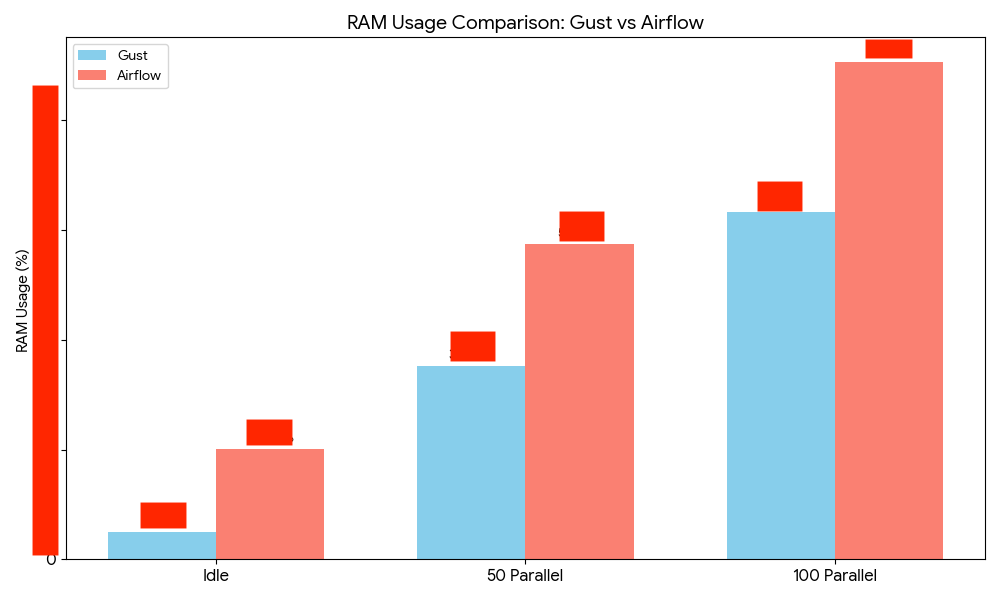
Just finished a RAM benchmark: @ApacheAirflow 3.2 vs Gust 0.1.29.
The results are very interesting:
- Up to 10x infra savings (idle RAM matters)
- ~1.6x more efficient at 50 parallel tasks
- ~1.4x at 100 parallel
Saving the raw numbers for @ElixirConfEU
Full code results coming to GitHub.
#MyElixirStatus
51
direnv is a blessing when working across multiple projects, especially with k8s.
github.com/direnv/direnv
43
As agents get better, we forget when to use deterministic algorithms.
Fixed rules, predictable failures -> workflows
Open-ended, dynamic problems -> agents
The sweet spot: agents coordinating
reddit.com/r/AI_Agents/comme…
43
A human in the loop is still needed—if you want high quality software architecture.
My agents most common slops:
- Variable and function naming
- Repeat code
- Don’t write tests before code ;)
1
91