
Research Economist @ecb. Personal opinions only. RT≠endorsement.
Joined February 2009
- Tweets 508
- Following 709
- Followers 344
- Likes 3,113
8 Photos and videos






Glenn Schepens retweeted

Jun 13
This is a great graph. The point is not time. The x axis is gdp per capita. The point is that growth does benefit all. The idea growth only benefits the rich is dramatically false. timely given Stieglitz, Pketty et al recent degrowth noise.
Jun 11

A way to see the amazing history of economic growth and declining poverty over the last two centuries.

11
140
560
72,673
Glenn Schepens retweeted

Jun 11
"What will happen to Europe if it keeps ignoring AI?"
Three American labs each (!!) operate more AI compute than all of Europe combined. Today we're launching Europe 2031: a story of what might happen if that doesn't change.

29
101
416
200,740
Glenn Schepens retweeted

Jun 9
Leave aside the existential philosophical stuff, and here's the hard-edged reality of where the business of AI is heading: towards closed platforms intervening on what users can do to maintain their moat.
We previously documented how the frontier labs self preference their own AI models, writing code that calls their own APIs to keep your token spend. This is the next logical step: quietly prevent you from being able to use their model to improve your own.
It's a completely understandable move, and can have real safety and geopolitical benefits, but it will raise a lot of uncomfortable policy questions that we saw play out in Web 2.0 too.
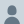
When Fable 5 is used for frontier LLM development, it does not notify the user and instead limits the model’s capabilities through methods such as prompt modification, steering vectors, and PEFT.
Anthropic estimated that this would affect approximately 0.03% of traffic.

4
16
89
27,418
Glenn Schepens retweeted
Important from a great team of labor economists. I am open to the benefits of remote for certain workers, but as with masks in public, my starting point is "societal interaction among strangers is a key part of humanity and it is bad that we lost so much of it from 2020."

Remote work hurts mental health. New research out in Science with @emma_k_h and Amanda Pallais. science.org/doi/10.1126/scie…
3
20
95
15,609
Glenn Schepens retweeted

Jun 2
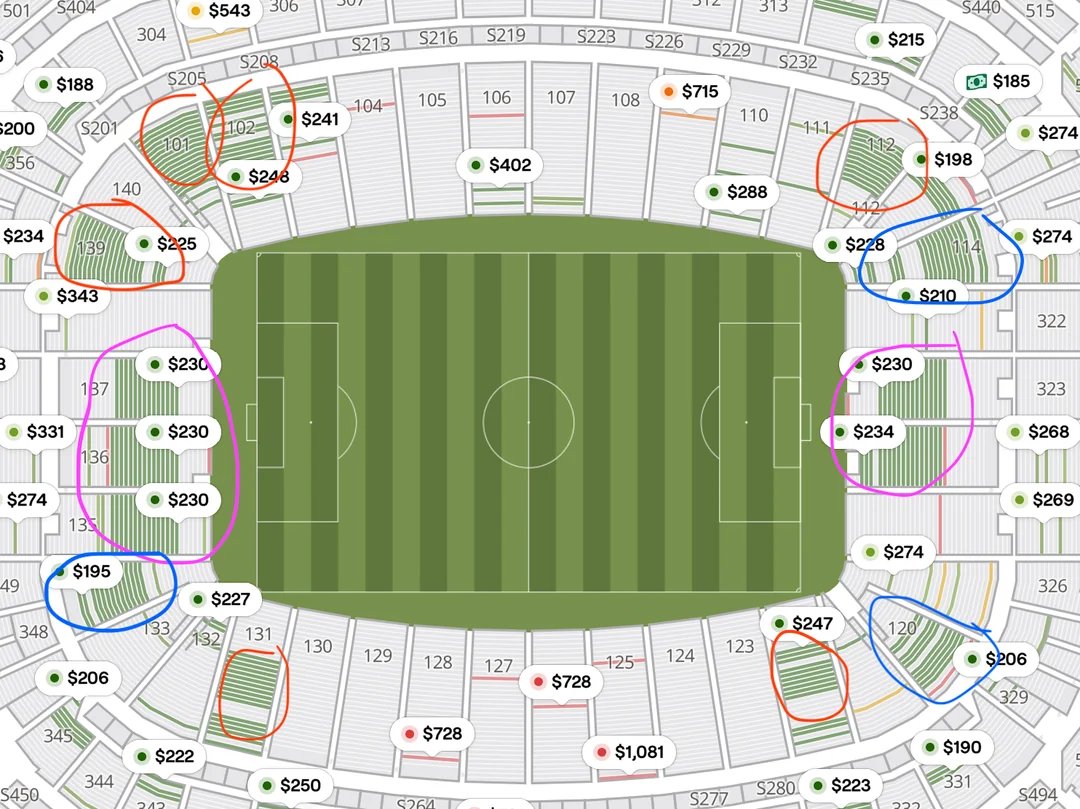
I believe we now have evidence of FIFA's World Cup ticketing shell game: FIFA is colluding with third-party resale platforms for its own supply management.
Look at this SeatGeek map (secondary market!) for Saudi Arabia vs Cape Verde. The circled areas are not random single resale tickets, but large, contiguous blocks of seats: entire rows and swaths in sections 101/102, 112/113, 119/120, 134–137, 139, ...
The blue circles appeared weeks ago, then the purple blocks suddenly showed up a day or two ago, and the red blocks seem to have appeared recently too.
That's not what ordinary fan or even commercial scalper resale looks like who resell pairs, fours, and scattered seats. Instead, this looks like inventory being dumped in bulk onto secondary markets, at prices below FIFA's official site.
Why doesn't FIFA just lower prices on its own site Probably because official price cuts could trigger refund demands, chargebacks, or consumer-protection headaches from fans who already bought at much higher prices.
Instead FIFA keeps official prices high, avoids openly admitting the market-clearing price is lower, and moves unsold inventory through third-party resale platforms instead.
390
2,241
14,104
5,003,395
Glenn Schepens retweeted

May 30
Asking for robustness in ref reports wastes everyone's time and DOES NOT WORK.
Authors selectively respond to requests, interpret things differently, and still have many degrees of freedom. This is a stupid dance.
Robustness checks are only useful if done by 3rd parties. 2/
1
10
95
10,181

May 12
RT @Benchimolium: 🚨 Public Good Alert 🚨
Two years of development. Zero funding. 𝟲,𝟲𝟵𝟯 𝗼𝗳𝗳𝗶𝗰𝗶𝗮𝗹 𝘀𝘁𝗮𝘁𝗲𝗺𝗲𝗻𝘁𝘀 𝗳𝗿𝗼𝗺 𝟱𝟭 𝗰𝗲𝗻𝘁𝗿𝗮𝗹 𝗯𝗮𝗻𝗸𝘀. #TextData…
102
Glenn Schepens retweeted

Apr 24
I put together a short practical guide for economists who want to use Claude Code, but who haven't gotten around to trying yet.
The goal is to reduce the start-up costs by using Claude Code within VS Code.

9
178
1,017
99,826
Glenn Schepens retweeted

Apr 21
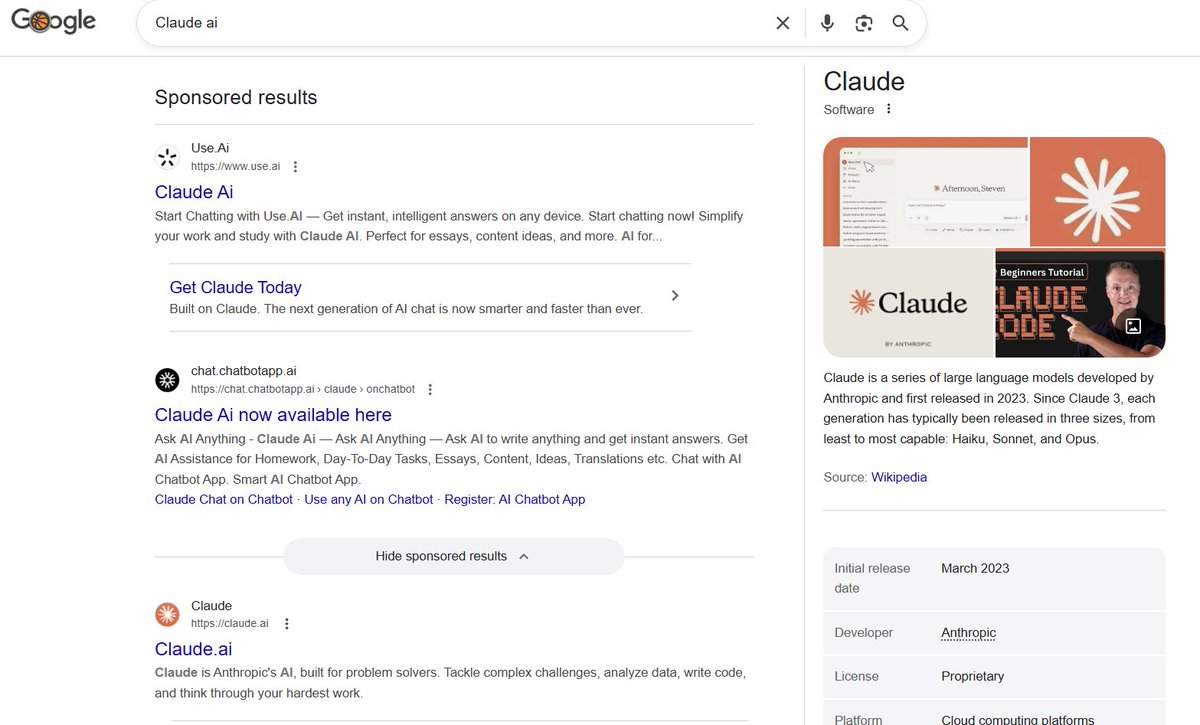
Here's a story on how easy fraud is today, from an example a friend got caught by. Search for "claude ai" on Google and Bing. The first sponsored results are fraudulent aggregators (more in a sec). On @bing, the "sponsored" tag is tiny and easy to miss (come on, guys!) 1/5

2
11
70
23,327
Glenn Schepens retweeted

Apr 17
De olieprijs daalt al 14 dagen lang en staat ondertussen 27% onder zijn piek. De gasprijs daalt al 30 dagen lang en staat ondertussen 36% onder zijn piek.
Maar Bouchez' populisme piekt steeds hoger.
Apr 17

🤯 Dit uitstel door de regering van beslissingen over ingrepen bij de energieprijzen had ik helaas voelen aankomen. Daarom heb ik dit dinsdag via een ultimatum aangeklaagd. De media hebben me opnieuw aangevallen, maar de feiten geven me gelijk.
⏳ Het enige doel van sommigen is tijd winnen…
💸 Ze zeggen dat het om budgettaire redenen is, maar laten we serieus zijn. Een volle tank benzine bestaat voor 60% uit belastingen. De brandstofsteun zou tussen 50 en 100 miljoen bedragen op een overheidsbudget van 170 miljard. De MR-ministers hebben de gevraagde besparingen binnen het regeerakkoord gerealiseerd. Vicepremier @DavidClarinval heeft zelfs 300 miljoen extra bespaard, terwijl hij alle aanvallen moest incasseren om dat resultaat te bereiken.
❓ Waarom gaan de andere ministers met 3,4 miljard in het rood? Tien dagen geleden werd er in enkele minuten wel 50 miljoen euro gevonden voor Fedasil.
👊 Het is goed om zich als verdediger van de begroting te profileren, maar het is beter om het ook effectief uit te voeren, zoals de MR doet.
❌ Zoals aangekondigd zal @MR_officiel dus een beslissing over energiesteun afwachten voordat andere dossiers binnen de regering vooruitgaan. De grootste Franstalige partij die opkomt voor werkende mensen heeft ook het recht om gehoord te worden. #MRvoorzitter #trotseliberaal
12
16
135
7,693
Glenn Schepens retweeted

Mar 30
Exactly. Most people still view AI as a better calculator. But we are already transitioning to AI orchestrating the entire scientific method autonomously. The gap between public perception and lab reality has never been wider.
The 'today epsilon' fallacy is dangerous. While labs push toward recursive self-improvement, the real friction won't be just compute, it will be institutional and regulatory bottlenecks that are difficult to change.
Mar 30

You don't truly understand the magnitude of the potential impact of powerful AI on the world unless you are aware, and have fully internalized, that senior leadership and most researchers at the frontier labs *actually believe* the following:
1. Existing AI is already significantly speeding up AI research. Very soon (this year), AI will very likely take over *ALL* aspects of AI research other than generation of novel research ideas. Soon (within the next 2 years), AI will very likely take over *ALL* aspects of AI research, period. This means hundreds of thousands of GPUs working 24/7 to discover novel ideas at the level of, or better than, the likes of Alec Radford, Ilya Sutskever, etc. The thread below presents a conservative timeline: AI researchers will "meaningfully contribute" to AI development in 1-3 years.
2. Many (but, as far as I can tell, not all) executives and researchers at the frontier labs believe that fully automated AI research will kick off recursive self-improvement (RSI), wherein the AI models will autonomously build better and better AI models, with human oversight (for safety reasons), but increasingly with no human input into the research or implementation of that research. From the thread below: "'[h]umans vs AI on intellectual work is likely to be like human runner vs a Porsche in a race', likely very soon" - but replace "intellectual work" generally with "AI research" specifically.
RSI is a complicated and messy thing to consider, both because there will be compute and energy constrains and because there are unknowns (will there be diminishing returns from greater intelligence of the models? if so, when will these diminishing returns become meaningful? is there a ceiling to intelligence that we don't know about?). But suffice to say that, if RSI *is* achieved in a way that many leaders/researchers at the frontier labs believe is possible, *THE WORLD MAY BECOME COMPLETELY UNRECOGNIZABLE WITHIN JUST A FEW YEARS*. This is subject to various bottlenecks; as the thread below correctly notes, "[i]nstitutional, personal & regulatory bottlenecks will bind very hard", and much also depends on continuing progress in areas like robotics.
3. On ~the same timeline as full, end-to-end automation of *ALL* aspects of AI research (within the next 2 years), AI will also become capable of making significant novel scientific discoveries *IN OTHER FIELDS*. This is why Dario Amodei, Demis Hassabis et al. believe that it is possible that all diseases will be curable within 10 years. (One account of how this might be possible is set forth in "Machines of Loving Grace".) The point is that an LLM that is capable of significant novel insights in the field of AI research should likewise be capable of significant novel insights in at least some (and perhaps all) other fields. The thread below notes: "AI for automating science [is] very early" - obviously true, but I think some changes may be right on the horizon.
Overall, and again from the thread below: "'a million scientists in a data center' will think much more quickly than humans, on almost any intellectual task; this will happen in the next 2-10 years." This is ~the same timeline as that presented in "Machines of Loving Grace".
Many will be tempted to dismiss all this as "just hype", "they are just trying to raise money again", etc. But no! - the above, in fact, presents the *actual beliefs* of senior leadership and many researchers at the frontier labs. Again, they genuinely think that AI research will be automated soon. Many of them genuinely believe that RSI is achievable in the not-too-distant future. And they genuinely see a real path towards AI significantly accelerating science, curing diseases, inventing new materials, helping to solve key global issues from poverty to climate change, etc., etc.
Whether the frontier labs' beliefs are correct is, of course, a separate question. I personally have historically tended to take public statements by OpenAI, Anthropic and Google at face value and quite seriously. As a result, I was not surprised when LLMs won gold in the IMO, IOI and the ICPC competitions last year, or when Claude Code/Codex started taking off, or when Anthropic and OpenAI started releasing significantly better models every 1-2 months, or when some of the best coders became reliant on Claude Code/Codex in their daily work, or when LLMs became significantly helpful to scientists in fields like math and physics in the last few months. The trajectory has been ~the same as that publicly predicted by the frontier labs. We have been accelerating. And, as of right now, all signs are indicating that the acceleration shall continue and that full automation of AI research and, potentially, RSI are firmly on the horizon.
2
8
989
Glenn Schepens retweeted

Mar 30
NEW ODD LOTS:
Goldman's CIO on the warp-speed advances happening in AI
@tracyalloway and I talk to Marco Argenti about the massive changes in AI at the bank in just the last 6 months, and what's actually being done to integrate it into the firm's work podcasts.apple.com/us/podcas…
8
16
131
63,736
Glenn Schepens retweeted

Mar 27
Okay, I have read this paper and it is horrible. The obvious reply, that many economists have made, is that there is no causality in there.
The problem is that I have not seen many replies that cite actual empirical research, so let me plug this in. On five grounds.
Mar 26

I'm happy to announce this new paper — we compile evidence on the extraordinary harms caused by IMF and World Bank structural adjustment programmes in the global South since the 1980s.
The empirical record is devastating: documented negative impacts on wages, poverty, inequality, maternal mortality, infant mortality, healthcare access, etc.
SAPs inflicted misery on the periphery in order to curtail their consumption, scupper independent development, and make labour and resources more cheaply available for the core.
gh.bmj.com/content/11/Suppl_…

17
122
565
114,365
Glenn Schepens retweeted

Ruime ervaring in de privésector: bij Dexia co-architect van grootste bankenongeval in Belgische geschiedenis, aandeelhouderswaarde vernietigd bij D’Ieteren met overname Moleskine. En die man krijgt de sleutels van investeringsfonds van België? Komaan.
Mar 25
De @MR_officiel benoemt Axel Miller tot voorzitter van de FPIM. Zijn ruime ervaring in de privésector en op de financiële markten, in combinatie met zijn recente verleden als politiek kabinetschef, maken hem de ideale kandidaat om de strategische keuzes van de regering om te zetten in een beheer dat economisch doeltreffend is en dat de economische ontwikkeling van strategische sectoren in ons land mogelijk maakt. #MRvoorzitter #trotseliberaal
25
93
472
36,160
Mar 23
🚨One week left to submit your papers for IBEFA 2027! 🚨
Submit at conftool.pro/ibefa-assa2027
Feb 2

The CfP for the IBEFA Annual Meeting 2027 is out! 📢
We're looking for high-quality research on financial intermediation and related topics. Join us in DC!
🗓️ Jan 3–5, 2027 📍 Washington, DC ⏰Submission deadline: March 31, 2026
Paper submissions: conftool.pro/ibefa-assa2027
1
65
Glenn Schepens retweeted

Mar 17
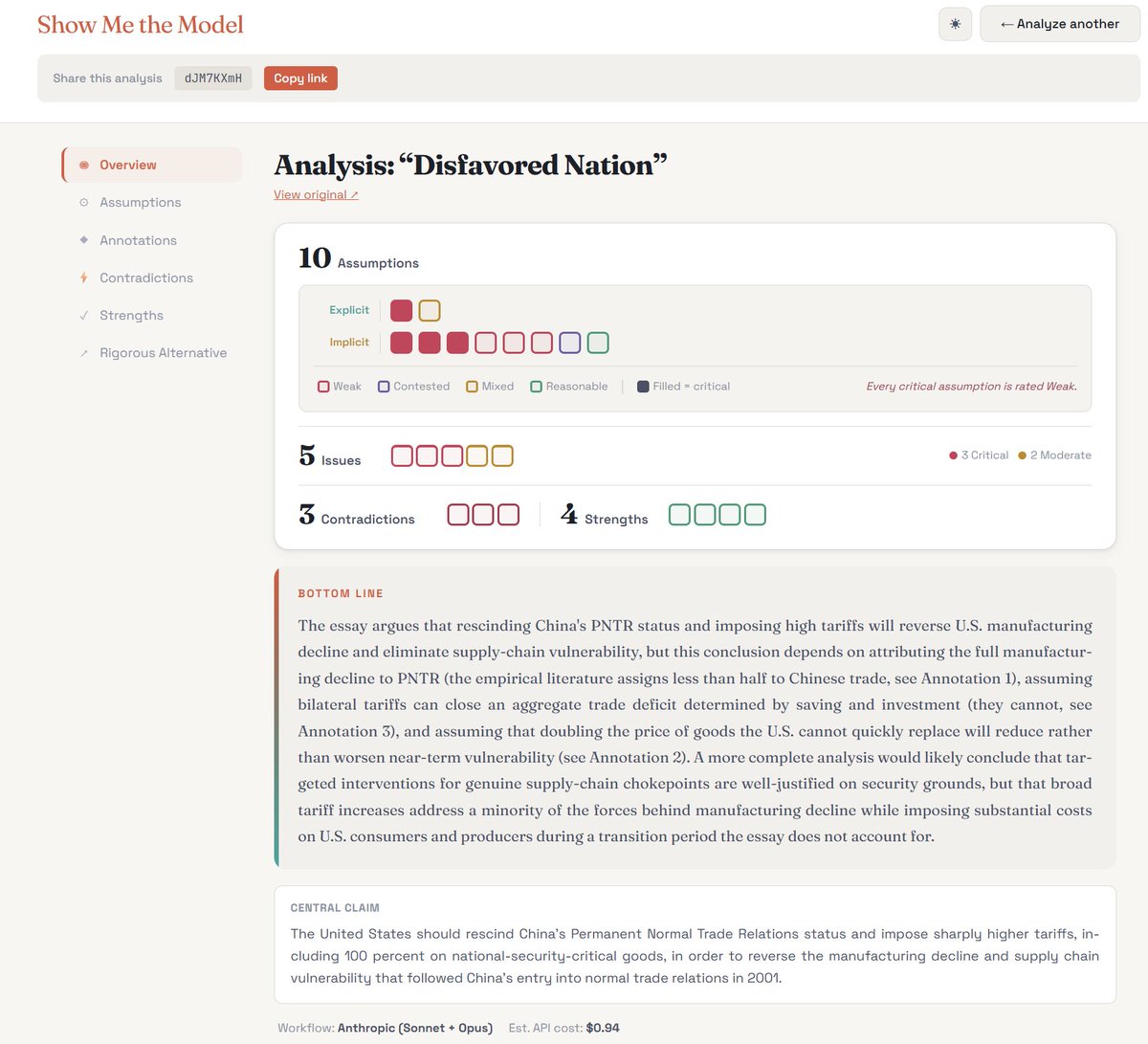
I spend way too much time on social media debunking "economic slop" promulgated by lawyers pretending to be economists, so I built Show Me the Model: a tool that uses AI to check whether the economic reasoning in an essay actually holds up.
showmethemodel.io
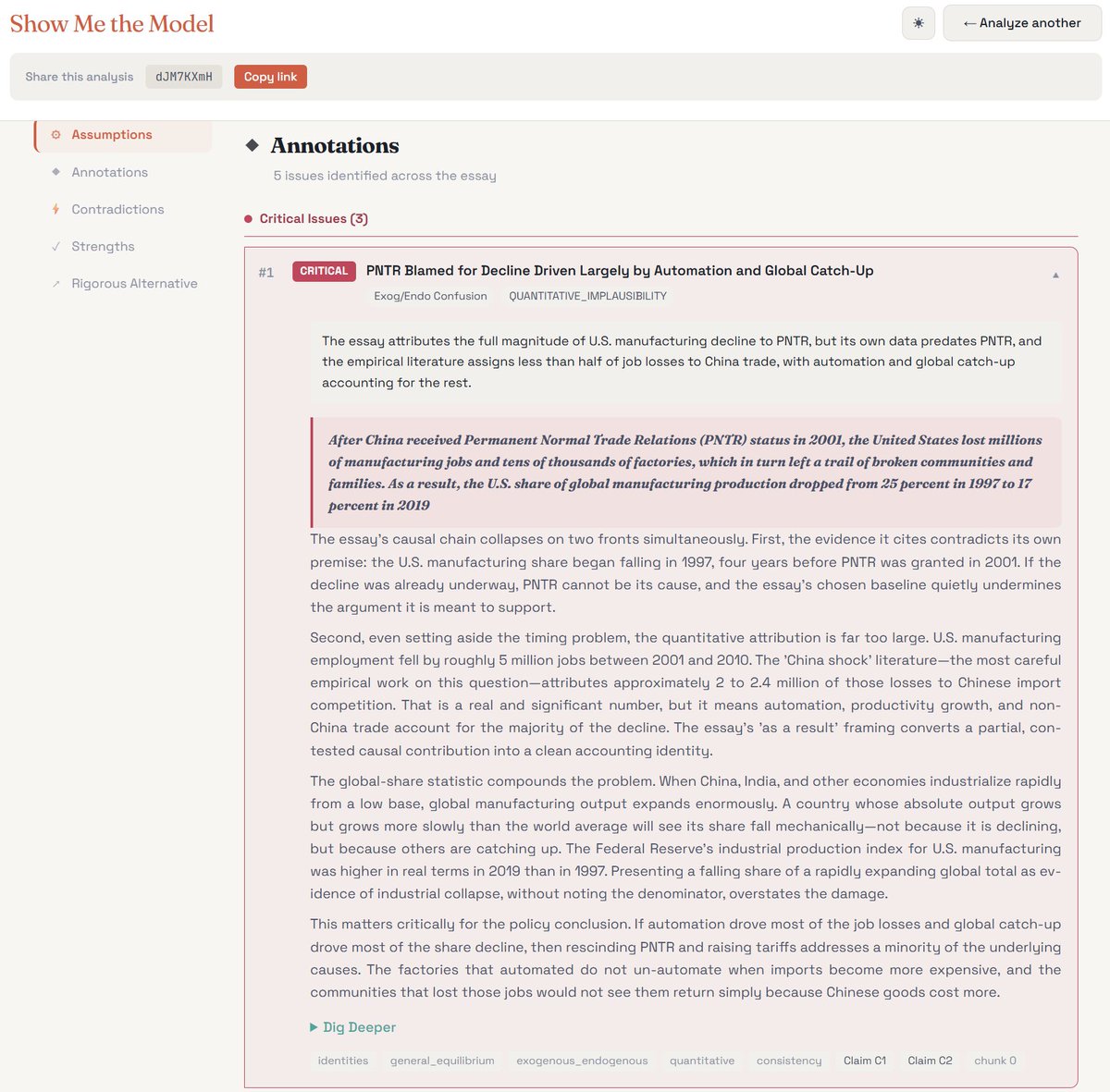
Give it a URL or paste some plain text, and the tool flags hidden assumptions, internal inconsistencies, and other problem areas, and tells you how a real economist would think through the issue.
Right now, it has 4 "personas:" macro, trade, IO/price theory, and labor. The tool first figures out which persona is right for the job, and then uses a parallelized prompt scaffold specific to that persona to process the source text.
Here are some example outputs based on some essays that triggered me hard:
Citrini Research's viral essay on how AI could trigger a self-reinforcing financial crisis rivaling the GFC:
showmethemodel.io/#/results/…
American Compass on the harms of trade deficits:
showmethemodel.io/#/results/…
@oren_cass on why Built-to-Rent should be banned:
showmethemodel.io/#/results/…
American Compass on the "China Shock:"
showmethemodel.io/#/results/…
@michaelxpettis on why China's trade surplus reduces global output:
showmethemodel.io/#/results/…
Try it yourself at showmethemodel.io. You'll need to bring your own API key (OpenAI or Anthropic), and a typical analysis costs $0.50–$1.50.
It's super preliminary and will probably break on you. I'd love feedback about both the functionality as well as the quality of the output.

26
135
751
108,503
Glenn Schepens retweeted

Submit your papers on housing and come see us in Frankfurt in summer 👇🏾
Mar 12

📢 CfP: Housing Market Frictions and Access to Homeownership
1st Annual Workshop in Real Estate Finance · 24–25 Aug 2026 · Frankfurt
Keynote speakers:
• Timothy McQuade (UC Berkeley, NBER)
• Andreas Fuster (Swiss Finance Institute at EPFL, CEPR)
3
10
1,500
Glenn Schepens retweeted

Aan de @ugent is er dan blijkbaar een “Departement” dat enkel niet-mannelijke onderzoekers uit het “Globale Zuiden” (Australië?) aanwerft???
Een zaak voor UNIA en het IGVM, toch?

Mar 3

Ook de UGent weigerde zijn aanstelling: waarom omstreden onderzoeker Pettit na drie bewogen dagen op straat staat 👇 in @demorgen
demorgen.be/politiek/ook-de-…
6
8
56
4,990
Glenn Schepens retweeted
I just published a free Claude Skill that generates feedback on your own academic papers. Link in the comments below.
12
64
579
104,220
Glenn Schepens retweeted
Feb 22
A few people have raised this question. The point isn't about whether we "need" 1,000 papers or not. The point is that that's what is possible now, and we need to adjust to that reality and start redesigning systems to make sure we promote knowledge production.
If we do nothing and leave the journal system as is, then the incentive will be for people to produce thousands of not very good papers, probably. We should aim to do better.

Ok so like….i say this as someone who used to be an academic and believes, still, in the value of academic research and writing: why do we need 1,000 academic papers produced at record speed?
16
8
55
14,281