鈴田泰久 | Yasuhisa Suzuta retweeted

Jun 10
【第4回 勉強会のお知らせ】
AI Ops Lab #4
AIと共に行う「しごとのリデザイン」
スモールバックオフィス編
ゲスト:
田中 裕一 ( @yuichitanaca )
株式会社MUSUBI 代表取締役
▼ 詳細はこちら(スレッド)

May 19

【第3回 勉強会のお知らせ】
AI Ops Lab #3
営業オペレーションのAI組織実装の最前線
ゲスト:
栗城 良規
株式会社Timers 取締役COO
▼ 詳細はこちら(スレッド)

1
9
15
2,166



May 10
_φ(・_・ Design.mdの作り方については、Stichを参考にすると良い。
stitch.withgoogle.com/docs/d…
Pintarestなどで「このサイトをベースに作って!」でもある程度は作れるが、調整は必須。
#AIOpsLab
1
1
4
307


May 10
_φ(・_・ AIにUIをレビューさせる方法。
Lazyweb は25,000社以上の実アプリ画面でAIを補強するMCPツール。参照させることでレビュー精度を上げる。
lazyweb.com/
とは言え、外国語サイトの学習が多いため、日本語テキスト崩れなどをレビューするスキルを作成中。
#AIOpsLab
1
2
5
225
May 10
_φ(・_・ デザインハーネスのお話。
x.com/kgsi/status/2052667728…
Claude Designはデザインシステム・ベースで動くため、制約によってアウトプットを制御するという意味でデザインハーネスの典型例と言える。
#AIOpsLab

1
3
4
1,902

Apr 1
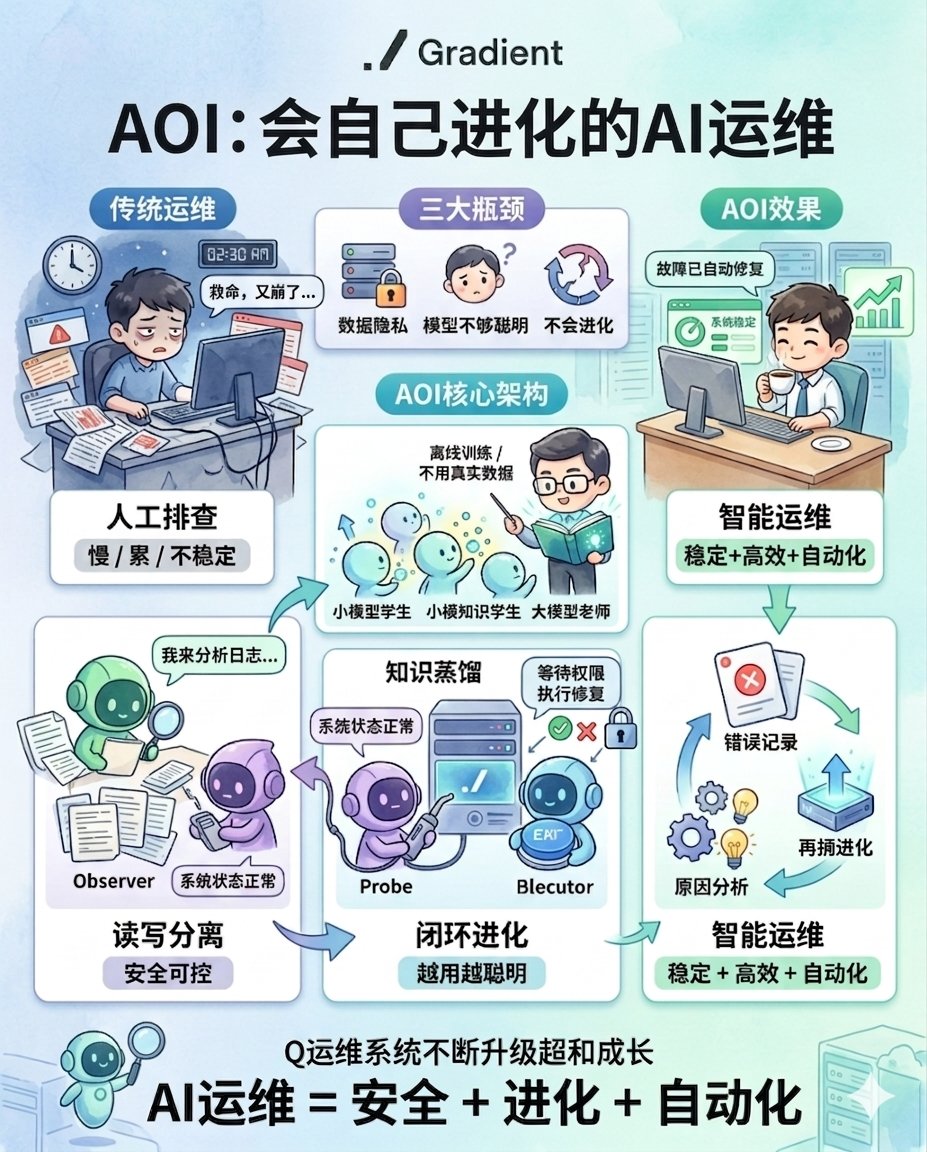
最近 @Gradient_HQ 团队动作频频,技术输出很密集。先是 Messari 出了份详细报告,深入拆解他们的 Open Intelligence Stack 如何通过分布式架构大幅降低 AI 训练门槛;接着 Echo-2 相关分析也指出,它用双群分布式架构,让 RL 后训练成本最高降低了 80% 以上(部分基准达 10.6 倍)。前不久,他们又发布了一篇新论文 【AOI】(Autonomous Operations Intelligence),聚焦用 AI 实现自动化运维。今天单聊 AOI,这个方向确实值得关注。
为什么 AI 运维喊了多年,却一直难落地?
云服务故障几乎是每个技术团队的痛点:半夜被叫醒、翻日志、查监控、试命令,一搞就是几个小时。这种“模式识别加逻辑推理”的工作,本该最适合 AI。
但现实中落地案例不多,核心卡在三个问题。
1.数据隐私:把企业日志喂给 GPT-4 这类大模型,数据就得传到云端,金融、医疗、政府等行业根本不敢冒这个风险。
2.能力不足: 本地部署开源小模型虽然安全,但诊断准确率低,容易误判、漏判,关键时刻靠不住。
3.不进化: 今天犯的错,明天照样重蹈覆辙,用一年还是原地踏步,不会从失败中吸取教训。
说白了,要么贵到用不起,要么便宜但不好用,而且都不长记性。
AOI 的解法:专注 三个关键设计
Gradient 这篇论文没有追求“什么都懂”的通用 AI,而是专注做好一件事,云故障诊断与修复,并通过一套机制让它持续进化。
第一个设计:小模型“偷师”大模型(知识蒸馏)
怎么让一个小模型变得聪明?他们用了一个很实际的方法。
先用 Claude 这类前沿大模型,在安全实验室环境中生成大量“专家示范”——面对某类故障,专家会看哪些指标、查哪些日志、如何一步步定位根因。然后用这些示范数据,训练一个 14B 的开源模型。
关键点在于:整个过程不接触任何真实企业敏感数据。示范在实验室生成,训练好的模型部署到企业内网后,数据全程不出内网。
实测结果挺有意思。这个 14B 的“徒弟”,在特定垂直诊断任务上做到了 42.9% 的准确率,而它的老师 Claude 是 39.1%。一个 140 亿参数的小模型,在特定领域反超了千亿级的通用大模型。
这说明一个问题:通用大模型的优势是知识面广,但垂直领域的深度可以通过针对性训练补上来。对数据敏感的企业来说,这意味着无需上传数据,就能获得接近顶尖的能力。
第二个设计:读写分离 精细权限控制
这是我觉得最务实的安全设计。
AOI 把智能体拆成三个清晰角色,各司其职。
-Observer(观察员) 只读不写,负责看日志、查指标、提出诊断假设,没有任何操作权限。
-Probe(探测员) 可以执行只读探测命令,比如查配置、测网络,用来验证猜测,但仅限于探测。
-Executor(执行员) 才有修改权限,而且每次操作都要经过安全规则审核,高风险动作需要人工审批。
每一步都有完整审计日志,可追溯。这套架构不是简单地把 AI“关在笼子里”,而是渐进式授权,先让它看,看准了再让它问,问对了再让它做。随着信任建立,权限可以逐步放开。
第三个设计:把失败变成进化燃料(闭环学习)
这是最打动我的设计。大多数 AI 系统是静态的,训练完就定型了。但 AOI 不一样,它会从自己的错误中学习。
每次任务失败,系统会完整记录轨迹,从观察到判断再到失败,然后分析根因,是看漏了指标?还是判断逻辑有问题?接着把这个失败的案例转化为结构化训练信号,重新喂给模型训练。
结果就是:上周犯过的错,这周就不会再犯。失败不再是终点,而是进化的起点。
实验数据也印证了这一点。加入这个 Evolver 闭环机制后,系统成功率提升了 4.8 个百分点,而且运行间方差降低了 35%,表现更稳定。
实测表现
他们在 AIOpsLab 基准上跑了 86 个真实 SRE 任务,结果挺能说明问题。
端到端成功率方面,AOI 完整系统做到了 66.3%,比之前最好的方案高出 24.4 个百分点。
更关键的是泛化能力。对训练时没见过的故障类型,成功率仍然保持在 63.8% 以上,说明它学到的不是死记硬背具体的故障模式,而是诊断的通用逻辑。
这些数据让我觉得,AOI 不只是一个实验室项目,它已经具备了在真实场景中落地的潜力。
值得关注的点
技术指标是一方面,但我更在意这套方案背后的思路。
第一,小模型在垂直领域可以做到“专精胜过通用”。 以前大家总觉得 AI 就是要堆参数、堆算力,越大越好。但 AOI 证明,把一个中等模型在特定场景练到极致,可能对中小企业更实用,几张消费级显卡就能跑,不用去抢那些买不到的 H100。
第二,失败闭环可能是通往真智能的关键路径。 人类的学习很大程度上就是从错误中来的,AI 也应该如此。不是追求一开始就完美,而是让它能持续变好。这个机制可以迁移到很多其他 AI 系统。
第三,安全架构不是简单限制,而是精细的分层与可控。 Observer、Probe、Executor 三个角色的设计,本质上是一种渐进式授权。这种思路对任何想把 AI 放到生产环境的人都有参考价值。
一点感想
以前总觉得 AI 进化就是堆算力、堆参数,但 Gradient 的 AOI 提供了另一条路径:用分布式 RL(Echo-2)降低训练成本,用针对性训练让小模型做到垂直极致,用失败闭环实现持续进化,用读写分离保障安全落地。
AOI 正是他们 Open Intelligence Stack 在真实场景的一次完整应用:Echo 做 RL 训练,Parallax 做分布式推理,Lattica 做通信协同,最终落地成一个能安全、可持续进化的运维系统。
@HexxRL
2
19
1,122

Mar 31
The numbers on AIOpsLab benchmark:
66.3% success rate. Prior best was 41.9%. 24 percentage points. No task specific training.
14B open source model surpassing Claude Sonnet 4.5 on held-out fault types.
37 failed trajectories converted into training signal. Run-to-run variance reduced by 35%.
1
3
22

Mar 31
AI is transforming , but DevOps and SRE are tough nuts to crack. security, privacy, and the fear of an AI accidentally taking down production hv been huge roadblocks until now
AOI (Autonomous Operations Intelligence) is a trainable multi-agent framework designed to make automated cloud operations secure, private, and capable of self-improvement
why this a big deal for the future of AIOps??
• Strict Read/Write Separation: Current LLM agents dangerously mix "read" and "write" permissions. AOI fixes this by splitting the workload among an Observer (read-only diagnosis), a Probe, and an Executor (which only handles gated write actions). This architectural separation ensures safe learning and prevents unauthorized system mutations.
• Local & Private: SRE environments are full of sensitive data that cannot be sent to closed-source frontier APIs. AOI solves this by using GRPO (Group Relative Policy Optimization) to distill expert-level operational knowledge into a highly capable 14B open-source model. You get expert reasoning without exposing proprietary data.
• Learning From Failure: Usually, when a closed AI system fails a task, that data is useless. AOI introduces a "Failure Trajectory Closed-Loop Evolver" that mines unsuccessful diagnostic runs and converts them into corrective supervision signals. The system literally learns from its own mistakes to continually refine its performance.
>>> and on the AIOpsLab benchmark, the base AOI runtime achieved a 66.3% success rate, outperforming the prior state-of-the-art by 24.4 percentage points. Furthermore, the locally deployed 14B model surpassed Claude Sonnet 4.5 on unseen faults, and the Evolver successfully reduced run-to-run variance by 35%.
this a massive step forward in building truly autonomous SRE agents that actually respect enterprise permissions and boundaries ./

Mar 31

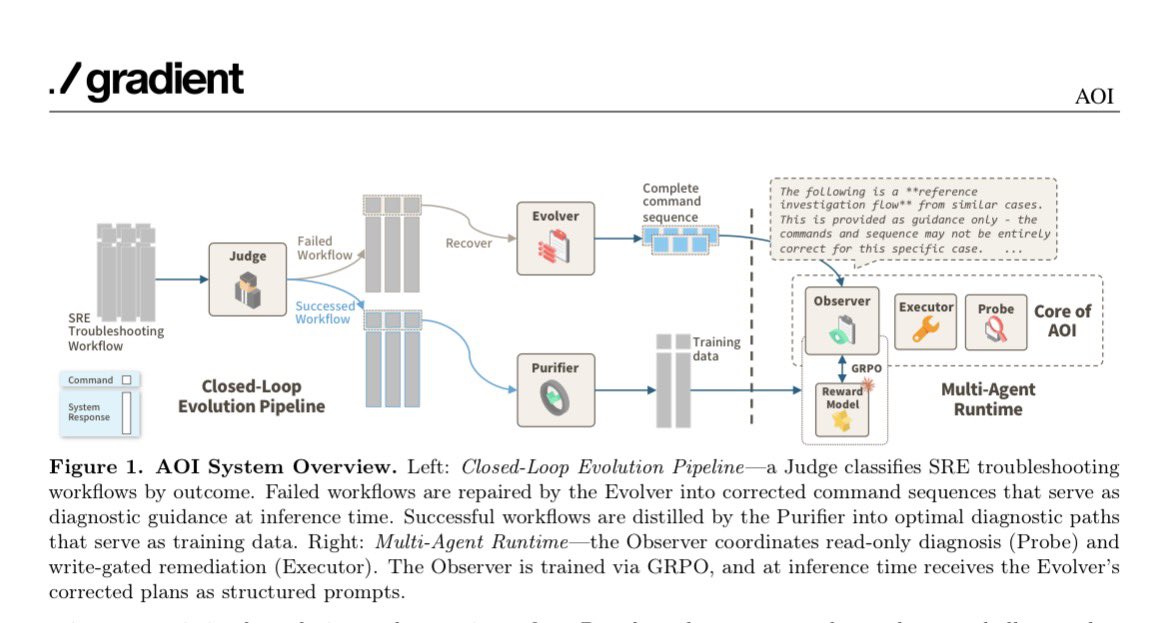
AOI: Turning Failed Trajectories into Training Signals for Autonomous Cloud Diagnosis
Proposed in solving the main barriers to using LLM agents for Site Reliability Engineering (SRE) in real enterprises. These include no access to sensitive operational data, strict permission and safety rules that block risky actions, and closed systems that cannot learn from their own failures.
The core solution is AOI (Autonomous Operations Intelligence), a secure, trainable multi-agent framework that turns automated cloud operations into a trajectory learning problem. Its three key innovations are:
- a trainable diagnostic system using GRPO to distill expert knowledge into a small open-source 14B model without exposing proprietary data
- a read-write separated architecture that splits agents into Observer (read-only diagnosis), Probe, and Executor (gated write actions) for safety and auditability
- a Failure Trajectory Closed-Loop Evolver that mines failed runs and converts them into corrective training signals for continuous self-improvement in a closed environment.
On the AIOpsLab benchmark with 86 real-world SRE tasks, base AOI hits 66.3% best@5 success (beating prior state-of-the-art by 24.4 points). The GRPO-trained Observer achieves 42.9% avg@1 on unseen faults, outperforming Claude Sonnet 4.5, while the Evolver adds 4.8 points end-to-end and cuts variance by 35%. AOI shows the abilities of how to build truly autonomous, self-improving SRE agents that stay secure and respect permissions.
Full research paper: arxiv.org/abs/2603.03378
3
1
16
266

Mar 31
AOI: Turning Failed Trajectories into Training Signals for Autonomous Cloud Diagnosis
Proposed in solving the main barriers to using LLM agents for Site Reliability Engineering (SRE) in real enterprises. These include no access to sensitive operational data, strict permission and safety rules that block risky actions, and closed systems that cannot learn from their own failures.
The core solution is AOI (Autonomous Operations Intelligence), a secure, trainable multi-agent framework that turns automated cloud operations into a trajectory learning problem. Its three key innovations are:
- a trainable diagnostic system using GRPO to distill expert knowledge into a small open-source 14B model without exposing proprietary data
- a read-write separated architecture that splits agents into Observer (read-only diagnosis), Probe, and Executor (gated write actions) for safety and auditability
- a Failure Trajectory Closed-Loop Evolver that mines failed runs and converts them into corrective training signals for continuous self-improvement in a closed environment.
On the AIOpsLab benchmark with 86 real-world SRE tasks, base AOI hits 66.3% best@5 success (beating prior state-of-the-art by 24.4 points). The GRPO-trained Observer achieves 42.9% avg@1 on unseen faults, outperforming Claude Sonnet 4.5, while the Evolver adds 4.8 points end-to-end and cuts variance by 35%. AOI shows the abilities of how to build truly autonomous, self-improving SRE agents that stay secure and respect permissions.
Full research paper: arxiv.org/abs/2603.03378
4
15
648