
Jun 10
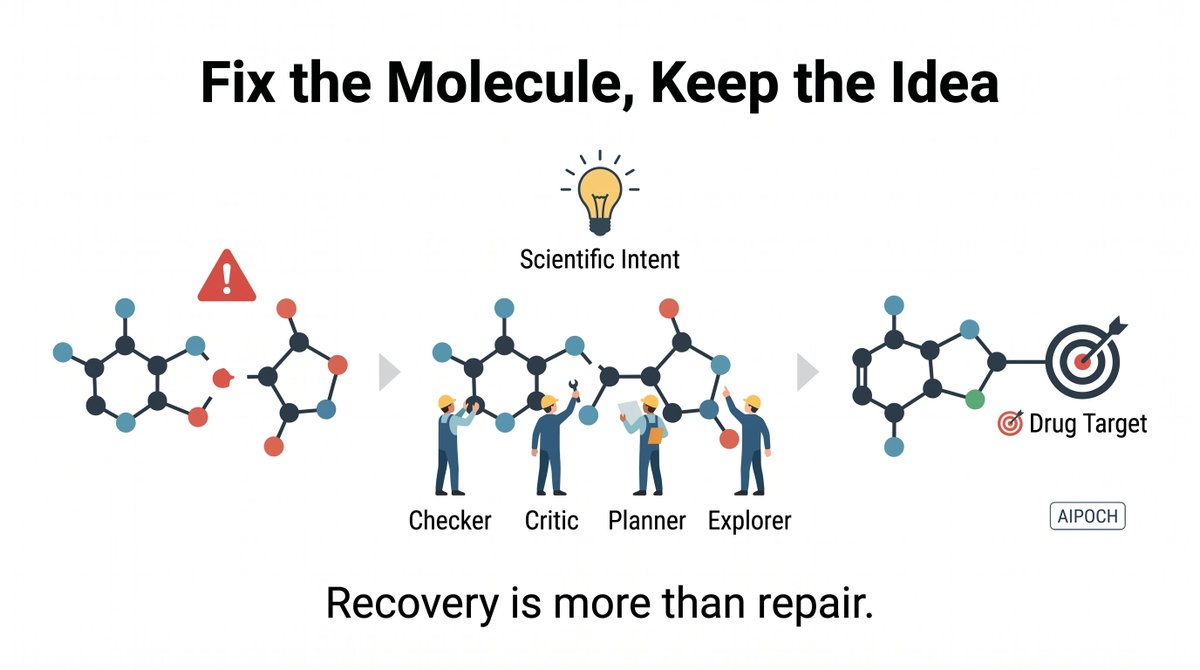
AIPOCH’s AMREC framework highlights a meaningful shift in AI drug discovery from simply repairing invalid molecules to recovering them in a way that preserves the underlying scientific intent through multi-agent checking, critique, planning, and chemistry-aware validation.
Jun 10

One of the most interesting trends in AI for drug discovery isn't molecule generation.
It's molecule recovery. 🧬
The AMREC framework highlights a subtle but important shift.
github.com/aipoch/medical-re…
When an LLM generates an invalid molecule, the goal is no longer simply to "fix the syntax."
The goal is to preserve scientific intent.
AMREC approaches this through a multi-agent workflow involving:
• Checking
• Critique
• Planning
• Candidate exploration
Combined with chemistry-aware validation tools.
In other words, the system doesn't just ask:
"Can this molecule be repaired?"
It asks:
"Can this molecule be repaired while preserving the biological idea behind it?"
That's a much harder problem.
And it reflects a broader trend we're seeing across AI-driven science:
Generation → Reflection → Recovery → Validation
As scientific agents become more capable, success will increasingly depend on how well they handle mistakes, not just how often they avoid them.
At AIPOCH, we think the same principle applies across biomedical research workflows.
Whether it's literature synthesis, biomarker discovery, protocol design, or translational research, the challenge isn't generating more outputs.
It's ensuring those outputs can survive evidence review, scientific scrutiny, and iterative refinement.
Because in science, the most valuable workflow isn't the one that never makes mistakes.
It's the one that can reliably detect and recover from them. 🔬
2
2,348
Tess retweeted

Jun 10
One of the most interesting trends in AI for drug discovery isn't molecule generation.
It's molecule recovery. 🧬
The AMREC framework highlights a subtle but important shift.
github.com/aipoch/medical-re…
When an LLM generates an invalid molecule, the goal is no longer simply to "fix the syntax."
The goal is to preserve scientific intent.
AMREC approaches this through a multi-agent workflow involving:
• Checking
• Critique
• Planning
• Candidate exploration
Combined with chemistry-aware validation tools.
In other words, the system doesn't just ask:
"Can this molecule be repaired?"
It asks:
"Can this molecule be repaired while preserving the biological idea behind it?"
That's a much harder problem.
And it reflects a broader trend we're seeing across AI-driven science:
Generation → Reflection → Recovery → Validation
As scientific agents become more capable, success will increasingly depend on how well they handle mistakes, not just how often they avoid them.
At AIPOCH, we think the same principle applies across biomedical research workflows.
Whether it's literature synthesis, biomarker discovery, protocol design, or translational research, the challenge isn't generating more outputs.
It's ensuring those outputs can survive evidence review, scientific scrutiny, and iterative refinement.
Because in science, the most valuable workflow isn't the one that never makes mistakes.
It's the one that can reliably detect and recover from them. 🔬
1
1
6
3,337

Agentic Molecular Recovery via Molecule-Aware Exploration
1. The paper reframes invalid SMILES from text-guided LLM generation as “corrupted molecular states” that often still contain useful structural cues, arguing the goal should shift from validity-only repair to identity-preserving molecular recovery.
2. It distinguishes two objectives: Repair = make the string chemically valid; Recovery = make it valid while preserving target-relevant scaffolds/functional groups and reconstructing the molecular identity implied by the natural-language description.
3. A key diagnosis: post-hoc repair methods (e.g., SELFIES/SMILES repair) can restore validity but frequently distort core substructures, while LLM-only iterative rewriting tends to cause unintended global drift because it regenerates whole SMILES sequences rather than controlled local edits.
4. The work also critiques “agentic greedy search” in tool-augmented molecular agents: even with RDKit-executable edit tools (better action fidelity), single-trajectory greedy refinement is vulnerable to early mistakes and lacks explicit tracking of molecule–text mismatches.
5. AMREC is introduced as an agentic recovery framework that combines molecule-aware mismatch tracking with expanded candidate exploration and trajectory-level selection, rather than committing to one step-by-step path.
6. AMREC’s core loop uses four roles: Checker extracts description-derived, verifiable structural requirements and evaluates them via RDKit observations; Critic summarizes remaining mismatches and flags structures to preserve; Planner proposes minimal-risk recovery intents; Candidate Explorer generates multiple candidate realizations per intent.
7. Two design choices are central: (a) requirement checklists serve as explicit objectives and stopping criteria to avoid unnecessary edits that might damage correct parts, and (b) a persistent candidate pool enables revisiting alternatives instead of discarding them after each step.
8. After the iterative loop, AMREC performs trajectory-level candidate selection: it selects the best molecule from all candidates seen across the trajectory, addressing the common failure mode where late edits degrade earlier, better-aligned molecules.
9. On invalid ChEBI-20 drafts from three backbone models (GPT-5.4-mini, Gemini-3.1-flash-lite, Claude-haiku-4.5), AMREC reports the strongest overall recovery profile across fingerprint similarities (MACCS/RDK/Morgan), exact match, string metrics (BLEU/ROUGE/Levenshtein), and distributional distance (FCD), outperforming validity repair, LLM-only correction, and generic tool-grounded agents (ReAct/ReWOO/PlanAndAct).
10. Ablations attribute gains to exploration and selection: larger trajectory-level pools improve identity/structure metrics; adding Critic improves structural recovery; final selection helps even tool agents, but AMREC benefits most because it generates higher-quality candidates to choose from.
📜Paper: arxiv.org/abs/2606.05847
#ComputationalBiology #Cheminformatics #MolecularGeneration #LLM #Agents #RDKit #SMILES #DrugDiscovery #MachineLearning

2
7
26
2,166

The workshop on the constitution of the Pan African Resource Reporting Code (PARC) Assessment Committee has officially commenced in Nairobi, Kenya.
AMREC-PARC provides Africa with a common, credible framework for classifying, managing and publicly reporting mineral and energy resources. It strengthens transparency, improves professional competency, and helps align resource reporting with the Africa Mining Vision, Agenda 2063 and sustainable development priorities.
#AMDC #AMREC #PARC #AfricaMiningVision #MineralGovernance #Agenda2063




3
4
152

May 24
في ظل تصاعد خطاب مأزوم يربط الأمازيغية والوعي الهوياتي الأصيل بإسرائيل وتنامي حملات التخوين والاستهداف الممنهج يصبح من الضروري تفكيك هذه الافتراءات ليس فقط بمنطق السياسة والتاريخ، بل وبعلم النفس الأكاديمي والعيادي لتشريح عقليات مروجيها.
ولتبسيط الرد لابد من التذكير أولا بأن إسرائيل دولة نووية منذ سنة 1972 وتتحكم فموازين قوى دولية وصراعها منذ نصف قرن قائم مع العرب والعروبة والأنظمة القومية والإسلامية. لذلك، يهمها استراتيجيا أن تبقى ملفات التفاوض والتطبيع تحت يافطة القومية العربية ليكون انتصارها السياسي مسجلا على هذا المحيط القومي برمته وهي لا تبحث عن أي بديل هوياتي أو لغوي.
ثانيا إن تهمة العمالة للأجنبي ضد الأمازيغ ليست وليدة اليوم بل كانت من رصيد ونفس النخبة الحضرية الفاسية التي شكلت نواة حزب الاستقلال لاحقا المتأثرة بالفكر القومي المشرقي منذ الثلاثينات. ففي 16ماي 1930 أصدرت سلطات الحماية الفرنسية مرسوما ينظم القضاء العرفي في المناطق الأمازيغية. فقامت النخبة الفاسية بتسميته بالظهير البربري واخترعت بروباغندا مفادها أن هناك مؤامرة لتمسيح الأمازيغ وفصلهم عن محيطهم لضرب المكون الأصلي وتمرير وصايتهم الأيديولوجية وهي نفس السنة التي كتب فيها مجموعة من الطلبة الفاسيين الذين كانوا يدرسون فباريس كتابا شهيرا بعنوان Tempête sur le Maroc (عاصفة على المغرب) يتوجهون فيه للحكومة الفرنسية لمنع تطبيق العرف الأمازيغي وتضمن نظرة استعلائية واحتقارا عرقيا واضحا وصَف القوانين والأعراف الأمازيغية بالبدائية والموحشة (loi extrêmement primitive)، وهو إرث تميزي مستمر إلى اليوم في عقول أحفادهم الأيديولوجيين.(ياتيتون الساحة السياسية المغربية اليوم).
ثالثا تاريخيا حين كانت النخب الأيديولوجية هذه والقومية في الحواضر تصيغ أدبيات الشكوى والشعارات اللفظية كان الأمازيغ فالجبال والفيافي يروون الأرض بدماء طاهرة صانت السيادة الوطنية فمعارك تاريخية يطمسها المزورون اليوم ولابذ من ذكر بعضها:
معركة الهري (13 نوفمبر 1914): بقيادة البطل الأمازيغي موحا أوحمو الزياني الذي سحق القوات الاستعمارية الفرنسية فالأطلس المتوسط وعرقل زحفهم لسنوات.
معركة أنوال (21 يوليو 1921): المعجزة العسكرية التي قادها أمير الريف محمد بن عبد الكريم الخطابي والتي دمر فيها الجيش الإسباني وصارت مرجعا لحركات التحرر العالمية.
معركة بوغافر (فبراير/مارس 1933): الملحمة التي سطرها البطل عسو أوبسلام وقبائل آيت عطا بالجنوب الشرقي صامدين فوق القمم ضد أعتى الطائرات والمدافع الفرنسية...
رابعا إن محاولة إلصاق تهمة العلاقات الخارجية بالأمازيغ تصطدم بصلابة الترتيب الزمني للأحداث السياسية في المغرب الحديث ففي نونبر1961 بدأت المفاوضات والاتفاقات الرسمية بين الدولة المغربية والحكومة الإسرائيلية لتسهيل هجرة اليهود المغاربة عملية "ياخين".فهذا التاريخ لم تكن هناك أي حركة أو جمعية أمازيغية قد رأت النور بعد
فقد تأسست أول جمعية أمازيغية فتاريخ المغرب الحديث (الجمعية المغربية للبحث والتبادل الثقافي - AMREC) سنة 1967 على يد أكاديميين كـأحمد بوكوس وعبد الله بونفور وكان نشاطها ثقافيا لغويا، وحقوقياً بحتا متأصلاً فالأرض دون أي نفوذ للمحاور الدولية وفمنتصف السبعينات برزت الحركة الثقافية الأمازيغية (MCA) فالجامعات فأوج مد التحرر العالمي. وقادة التنظيمات السبعينية الماركسية مثل "إلى الأمام" و"23 مارس" من أبناء العمق الأمازيغي دافعوا عن الأمازيغية كحق إنساني لرفع الاستلاب الثقافي معتبرين قضية فلسطين قضية تحرر وطني عادلة ضد الاستعمار الاستيطاني.
المفارقة التاريخية الكبرى التي تفضح انتهازية الخطاب الإخواني هي أن من وقع على الإعلان المشترك لاستئناف العلاقات بين المغرب وإسرائيل بصفته الرسمية هو سعد الدين العثماني رئيس الحكومة والأمين العام لحزب العدالة والتنمية الإسلامي آنذاك يوم 22 دجنبر2020 بقرار سيادي من الدولة بينما لم يكن للحركة الأمازيغية الحرة أي يد أو سلطة حكومية في هذا القرار.
خامسا وبعيدا عن السياسة يفسر علم النفس السلوكي والتحليلي هاته الهستيريا ضد الأمازيغية من خلال عدة ميكانزمات دفاعية (Defense Mechanisms) تلجأ إليها الشخصيات المأزومة أيديولوجيا:
أولا التنافر المعرفي والإسقاط (Projection) فهذه التيارات كبرت وتغذت منذ السبعينيات على عائدات الولاء والدعم المالي والسياسي من منظمات ودول أجنبية مشرقية. وعندما يصطدمون بواقع أن المغاربة تصالحوا مع هويتهم الأمازيغية بشكل عفوية وتلقائي يصابون بتنافر معرفي وبدل النقد الذاتي يُسقطون عيوبهم وتبعيتهم للخارج على الأمازيغ مدعين وجود مؤامرة كونية.
تابع 👇👇
@𝑺𝒉𝒐𝒎𝒚𝒂 𝒉𝒂𝒊𝒊𝒎


1
5
34
831

May 13
Um dia de boas agendas aqui no sul do estado.
Visitei prefeitos, vereadores, secretários, lideranças e empresários das regiões da AMUREL (Associação dos municípios da região de Laguna) e AMREC - região carbonífera.
Conversando com pessoas na ponta da linha, verdadeiros entendedores das demandas locais.
Agradeço a consideração do @guicolombosc pelo excelente dia.
61
630
2,399
14,230
This week in Pretoria, South Africa, experts from across Africa and Europe are gathering for the PanAfGeo National AMREC/PARC – UNFC Workshop to strengthen collaboration on harmonised mineral resource governance, reporting standards, and implementation pathways aligned with the Africa Mining Vision and Agenda 2063.
Representing the African Minerals Development Centre is the officer in charge; Tunde Arisekola FNMGS, who is contributing to discussions on AMV implementations tools.
#AMDC #PanAfGeo #AfricaMiningVision #UNFC #AMREC #MineralResources #Geoscience #AfricaEU #Agenda2063 #SustainableMining




5
9
296

May 9
FUNAABITES I don't even know AMREC. 😂

Funaabite but i dont even know Old trafford, extension gate, Okay geolex i dey see dat one for road side...
4
35

Encerramos ontem o roteiro pela AMESC e AMREC em grande estilo.
Na Associação Imbralit, em Criciúma, mais de 1.300 pessoas reunidas ao lado de importantes lideranças políticas de SC, debatendo o presente e o futuro do nosso estado.
Santa Catarina quer seguir avançando.
4
421

jab amrec aja kar bhi to nswari ghyatya raha to tery gandy khon ko koi badal nahi skta hy ...

1
3
17

Apr 2
Incrível o criciuma esporte clube um ano é vamos evitar fogos pelos autistas e no ano seguinte é compre todos os fogos da amrec e faça um reveillon 2 em abril
2
177

Apr 1
It’s crazy how I’ve been avoiding MP and AMREC since the bee incident
5
55


Fabulous Funaabites,
This is to inform all students to kindly avoid the MP and Amrec area until further notice.
Following the recent bee attack recorded in that vicinity, arrangements have been made for immediate treatment and the removal of all bee hives within the area. This process may trigger bee activity and poses a potential risk to anyone nearby.
For your safety, we strongly advise that you stay clear of the area while this exercise is ongoing.
Further updates will be communicated as necessary.
Thank you for your cooperation and understanding.
3
9
42
2,627

Mar 25
FUNAAB Issues Safety Advisory on Bee Encounters Following Incidents at AMREC, MPB
In light of yesterday's (March 24, 2026) bee-related incidents reported around the Agricultural Media Resources and Extension Centre (AMREC) and Oba Lipede Multipurpose Building (MPB), members...

1
2
7
114

Fabulous Funaabites,
Please avoid MP and AMREC vicinity as there is a swarm of bees in the area. if you are there, kindly vacate the premises immediately.

Fabulous Funaabites,
Do well to avoid MP and AMREC vicinity as there is a rapid spread of bees within that area.
Please if you are there, kindly vacate that premises.
4
170

Mar 24
🚨 URGENT CAMPUS UPDATE: Widespread Bee Infestation at FUNAAB
Status: CRITICAL | Time: Tuesday, March 24, 2026
New Affected Locations
The infestation is no longer localized. Heavy bee activity and attacks have now been reported at:
- MP - AMREC - CLSU Building- COLFHEC- COLBIOS
1
1
7
323

RE: URGENT UPDATE
Bee infestation reported near MP, AMREC, and COLBIOS areas! 🚨
Students, please avoid the area and take alternative routes for now. Your safety is our priority! We'll keep you updated as more info comes in.
- @JustFunaab

6
182
