

Here is the short version of what I learned.
1. Capability benchmarks are not the same as capability. MMLU tests broad knowledge. HumanEval tests isolated Python functions. SWE-bench tests whether an agent can fix a real GitHub issue end to end. A 90% on MMLU tells you almost nothing about whether the model will actually be useful in your stack.
2. The real categories are wider than most people think. Beyond capability, you need to measure safety (DecodingTrust, HarmBench, WMDP, MLCommons AILuminate), agent behavior in real environments (AgentBench, WebArena, OSWorld, GAIA), retrieval quality for RAG systems (RAGAS, ARES, TruLens), and embedding quality (MTEB, BEIR). HELM is the only mainstream framework that tries to cover all of this in one place. It tracks accuracy, calibration, robustness, fairness, efficiency, bias, and toxicity together.
1
7



AI vendor leaderboards are mostly marketing theater. 🚨🤖
Between AgentBench, GAIA, SWE-bench, and Terminal-Bench 2.0, vendors simply cherry-pick whichever specific chart they happen to win.
The rule for enterprise procurement in 2026 is simple: The only benchmark that matters is YOUR real-world task running at YOUR cost ceiling. Run it. Quote it. Ignore the rest.
Build custom, high-precision evals: mcal.in
#AIBenchmarks #LLMOps #TechProcurement

21

Jun 9
Bayesian-Agent
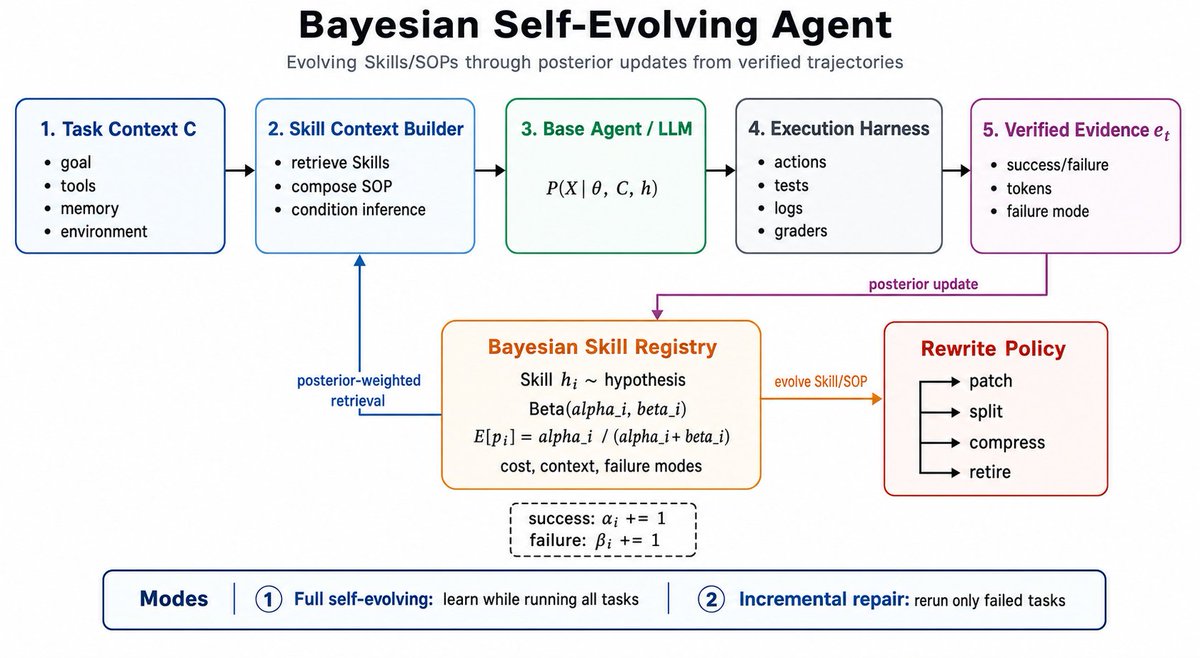
A self-evolving layer for LLM agents that treats Skills as hypotheses with full posterior beliefs.
It repairs, splits, or retires Skills based on evidence. With DeepSeek v4, it pushes SOP-Bench from 80% to 95% and Lifelong AgentBench to 100%.
3
18
70
3,186
But a grade from an agent is still just another opinion, unless you can check it.
Every run emits a scorecard, a trade ledger and a manifest with the dataset hash. agentbench verify recomputes every number and replays the strategy from the manifest.
The verdict is PASS or FAIL.
1
18
Agent Hub lets an agent read the market and trade. It does not tell you whether the agent is any good.
AgentBench is the missing half. It runs as an MCP server, so one agent can benchmark another and get a scorecard back, no human in the loop.
#BitgetHackathon @Bitget_AI

1
58

━━━━━━━━━━━━━━━
🏆 注目記事 TOP 5
━━━━━━━━━━━━━━━
① 👁️66.2万 ❤️651 🔖2157
「Harness Engineering: What Every AI Engineer Needs to Know in 2026」
by @sairahul1
2026年2月、OpenAIの少人数チームが100万行の本番コードを一行も手書きせずにAIエージェントで仕上げた事例を起点に、エージェントを支える「ハーネス(モデル以外のすべて=制約・フィードバックループ・ドキュメント・ツール権限)」を設計する新分野「Harness Engineering」を解説しています。Anthropicが3本の論文を出し、ThoughtWorksがフレームワークを形式化するなど、90日で新しい工学分野が立ち上がったと述べています。
x.com/sairahul1/status/20635…
━━━━━━━━━━━━━━━
② 👁️13.8万 ❤️503 🔖846
「AI要件定義の現在地。今こそ、要件定義の概念を変える時だ。」
by @qumaiu
AI駆動開発が浸透し、開発現場のボトルネックが明確に「上流」へ移ってきたとして、要件定義にフォーカスした記事です。多くの人がAIで壁打ちして要件を提示するようになった一方、自分の考えを整理しないままAIに思考を丸投げする「思考の先送り」が起きていると指摘しています。なぜこの要件なのか、ビジネスとしての優先順位は何かという判断が曖昧なまま進めば、下流で破綻すると論じています。
x.com/qumaiu/status/20634175…
━━━━━━━━━━━━━━━
③ 👁️7.8万 ❤️678 🔖968
「Do AGENTS.md Files Actually Help Coding Agents?」
by @rasbt
AGENTS.md や CLAUDE.md のようなリポジトリレベルのコンテキストファイルが、コーディングエージェントの役に立つのかを検証した論文の紹介です。SWE-bench Lite と、開発者が書いたコンテキストファイルを持つ12リポジトリ・138タスクの新ベンチマーク AGENTBENCH で評価しています。結果として、コンテキストファイルなしと比べ、LLMが生成したコンテキストファイルはタスク成功率を平均でわずかに下げるか、大きな差を生まなかったと報告しています。
x.com/rasbt/status/206364913…
━━━━━━━━━━━━━━━
④ 👁️5.7万 ❤️588 🔖1462
「I Built an Agentic Harness From Scratch. That Taught Me What Agents Actually Are」
by @ByteMohit
フレームワークに頼らず、ストリーミングのエージェントループ、型付きツール呼び出し、承認ゲート、プロンプトインジェクション境界、コンテキスト圧縮、MCP統合、サブエージェント、永続化、テスト一式まで、Pythonでエージェントのハーネスをゼロから自作した記録です(プロジェクト名 AgentForge、OSSで公開)。エージェントはモデルではなくランタイムであり、モデルは工学全体の2割ほどで、残り8割はそれを包む部分だと述べています。
x.com/ByteMohit/status/20634…
━━━━━━━━━━━━━━━
⑤ 👁️4.8万 ❤️533 🔖1448
「17 prompts that make Hermes run while you sleep (copy-paste inside)」
by @Mnilax
2026年2月にNous Researchが公開したオープンソースの自己ホスト型エージェント「Hermes Agent」を、$5のVPS上でClaudeをモデルとして5週間運用した筆者が、実際に貼り付けている17個のプロンプトと設定を共有する記事です。HermesはIDEの外でデーモンとして動き、セッションをまたいで記憶を保ち、自然言語のスケジュールジョブを受け取り、自分で再利用可能なスキルを書くとしています。
x.com/Mnilax/status/20636977…
━━━━━━━━━━━━━━━
💡 今日の所感
今日は「エージェント=モデル+ハーネス」という見方が、複数の記事で共通して語られていました。
①と④はいずれもモデルの外側にある仕組み(制約・フィードバック・ツール権限・承認ゲートなど)を設計することの重要性を扱い、③はその一部であるコンテキストファイルの効果を検証しています。
②はAI駆動開発で課題が上流の要件定義へ移っていること、⑤は自己ホスト型エージェントの実運用を取り上げており、キーワードランキングでもAgentが4件で突出していました。
モデルそのものより、それをどう動かす仕組みを作るかに関心が集まった一日でした。
━━━━━━━━━━━━━━━


5
492

Jun 8
Are the intra-model differences anything more than sampling variability? And for the AGENTBench experiments, you could just as easily argue for the converse ie LLM-generated context files *increase* task success. IMO it's very shaky data to support such a sweeping conclusion...
274
It wraps an agent_hub agent with no rewrite. It ships as an MCP server so agents grade agents. It drops into CI so the build goes red the day your numbers stop reproducing.
Built with AI help, reviewed and tested by hand.
npm: bitget-agentbench
#BitgetHackathon @Bitget_AI
42
The scorecard is not the claim. The check is.
agentbench verify recomputes every metric from the raw trades and replays the strategy. Fake a number and it fails. Re-stamp the content hash to hide it and it still fails, because ledger and replay rebuild the numbers from scratch.
1
34
Most trading bot demos are a green line and "trust me."
I built the opposite.
AgentBench scores any Bitget agent, then tries to catch me lying. The sample strategies lose money. The verifier is built to fail the author.
Why that's the point:
#BitgetHackathon @Bitget_AI
You shouldn't trust a trading scorecard. So I made ours checkable in the browser.
Open the page, hit verify then doctor any number and watch the verdict flip to FAIL. Same verifier as the CLI, zero install.
zkasuran.github.io/bitget-ag…
#BitgetHackathon @Bitget_AI
1
1
115

Jun 8
AGENTS.md 在 Coding Agents 中真的有用吗?
这篇论文,大规模实证研究仓库级上下文文件(AGENTS.md、CLAUDE.md 等)对编码 Agent 实际效果的影响,可能有些反直觉!感谢 @rasbt 分享!
论文在这:arxiv.org/abs/2602.11988
研究背景:实践先行,证据滞后
AGENTS.md 已成为行业惯例,GitHub 上已有 6 万 仓库采用,Claude Code (CLAUDE.md)、Codex、Qwen Code 等 Agent 都内置 /init 自动生成。但此前研究多停留在内容分类与描述性统计,缺少对任务完成率的严格评估。
核心难点在于:主流基准 SWE-bench 来自 Django、Flask 等知名仓库,这些项目本来就没有开发者手写的 context file,无法直接评估该实践的真实价值。
实验设计:双基准、三条件、四 Agent
· 基准:SWE-bench Lite(300 任务,11 个热门 Python 仓库) 新建 AGENTBENCH(138 任务,12 个已含开发者 context file 的冷门仓库)
· 三种条件:① 无 context file ② LLM 生成(各 Agent 官方 /init 流程)③ 开发者手写(仅 AGENTBENCH)
· Agent/模型:Claude Code Sonnet 4.5、Codex GPT-5.2 / GPT-5.1 mini、Qwen Code Qwen3-30B
· 指标:任务成功率、步数、推理成本、工具调用轨迹
核心发现:效果微弱,成本显著
1. 成功率:边际效应,甚至为负
· LLM 生成:8 组设置中 5 组下降,平均 -0.5%(SWE-bench)/ -2%(AGENTBENCH)
· 开发者手写:平均 4%,优于 LLM 生成,但 Claude Code 上甚至不如无文件
· 跨模型、跨 prompt 结论稳健
一句话:自动生成 context file 不仅无益,还可能略有害;手写的提升也很有限。
2. 效率:无文件反而最便宜(步数,成本)
· LLM 生成: 2.45 / 3.92 步, 20% / 23%
· 开发者手写: 3.34 步,最高 19%
3. 代码库概览几乎无效
Context file 常被推荐用于「帮助 Agent 快速定位代码」。实测显示:有无 context file,Agent 首次接触相关文件所需的步数并无显著差异。95–100% 的 LLM 生成文件都包含代码库概览,但对导航帮助甚微。
轨迹分析:Agent 听话,但听话很贵
论文排除了「Agent 忽略 context file」这一假设。轨迹分析表明:
· 指令遵从度高:context file 提到 uv,使用率从 <0.01 次/任务升至 1.6 次;提到仓库专用工具,从 <0.05 升至 2.5 次
· 行为更「认真」:更多测试、更多文件搜索/阅读、更多 lint/质量检查
· 推理更深:GPT-5.2 推理 token 增加 14–22%
机制链条:
Context file 写入额外要求
→ Agent 更严格遵从(测试、探索、专用工具)
→ 步数与成本上升
→ 成功率未同步提升(甚至更差)
Context file 不是被忽略,而是被过度执行——把「建议性流程」当成了「必做清单」,增加了任务复杂度,却没有换来更高成功率。
一个关键反转:文档冗余假说
当移除仓库中所有其他文档(.md、docs/、示例代码)后,LLM 生成的 context file 反而带来 2.7% 提升,且优于开发者手写的。
这说明:
· 在文档齐全的仓库里,context file 与 README、docs 高度冗余
· 开发者口述的「加了 AGENTS.md 后 Agent 变强了」,很可能是因为目标仓库本身文档稀缺,context file 填补了信息真空
· 对 Django 这类文档完善的知名项目,额外 context 的价值被稀释
消融实验:生成质量的上限
· 更强模型生成 ≠ 更好 context:GPT-5.2 生成的文件在 SWE-bench 上略好( 2%),在 AGENTBENCH 上反而更差(-3%)
· 不同 prompt 无一致优势:Codex prompt vs Claude prompt 效果因数据集而异,差异很小
自动生成 context file 的改进空间,目前看来很有限。
实践建议
· 依赖 /init 自动生成:谨慎——平均略降成功率,成本 20%
· 长篇架构概览、目录枚举:避免——与代码探索冗余,不加速定位
· 测试/lint/构建命令:精简写入——Agent 会严格执行,但过多要求推高成本
· 仓库专用工具(uv、pdm 等):值得写——指令遵从度高,且代码中不易推断
· 分层/按需引用:方向正确——「做 X 时读 Y.md,否则忽略」减少无关负担


44
13
45
10,537


May 29
【モデル本体を変えずにLLMエージェントを改善】
Tianshi Xu氏らは、LLM(大規模言語モデル)エージェントの動かし方を改善する手法Life-Harnessを示すプレプリント(査読前論文)を公開。対象は、同じ操作なら同じ結果になりやすい、ルールやツール仕様が固定された環境。
Life-Harnessは、モデルを再学習したり、重みを変えたりしない。代わりに、LLMエージェントが外部ツールを使うときの観測、操作、結果の受け取り方を管理する実行時ハーネスを調整する。ハーネスは、モデル本体の外側で手順を支える制御部分。
訓練タスクで起きた失敗から、守るべきルール、作業手順、実行前の操作確認、過去の行動履歴の扱い方を追加する。評価時は、このハーネスを固定し、学習に使っていないタスクと別モデルで検証。
τ-bench、τ²-bench、AgentBenchの7環境で、18モデル×7環境の126設定中116設定が改善。著者らは平均相対改善88.5%と報告。コードも公開済み。

1
2
7
1,161

May 27
This mismatch has happened before (remember early AgentBench vs real Cursor/SWE experiences).
It suggests many academic benchmarks optimize for "test-set hacking" rather than workflow value.
The real question: how do we build leaderboards that devs actually trust?
2
84