
May 22
Shipping AI agents without rethinking your QA approach is one of the costliest mistakes engineering teams make right now.
What actually needs to change 👇
opcito.com/blogs/ai-agent-te…
#AIAgents #AgentTesting #LLMOps #GenAI
28

May 14
에이전트를 테스트하기 전에,
'정답'의 정의부터 다시 쓴다.
1. 출력이 아니라 경로를 검증한다
2. 통과 실패가 아니라 점수 분포로 측정한다
3. 어서션이 아니라 LLM이 채점관이 된다
환자가 살아도 의사의 술기는 따로 평가한다. 에이전트도 같다. 최종 답이 맞아도 도중에 틀린 도구를 호출했다면 그 경로는 실패다.
전통적인 룰베이스 평가는 에이전트의 실제 성공률을 과소평가한다. 정답에 이르는 경로는 여럿인데 정해진 한 경로만 통과시키기 때문이다. AgentRewardBench가 1,302개 경로로 12개 LLM 채점관을 검증한 결과, 모든 벤치마크에서 일관되게 우수한 단일 채점관은 존재하지 않았다. 이제 채점관 자체를 채점해야 하는 시대로 넘어갔다.
출처:
"AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories" 룰베이스 평가가 에이전트 성공률을 과소평가한다는 점과 LLM 채점관끼리도 성능 격차가 크다는 점을 1,302개 실제 trajectory로 실증한 arXiv 논문이라 인용.
arxiv.org/abs/2504.08942
#AgentTesting #에이전트평가 #LLMEval
1
31

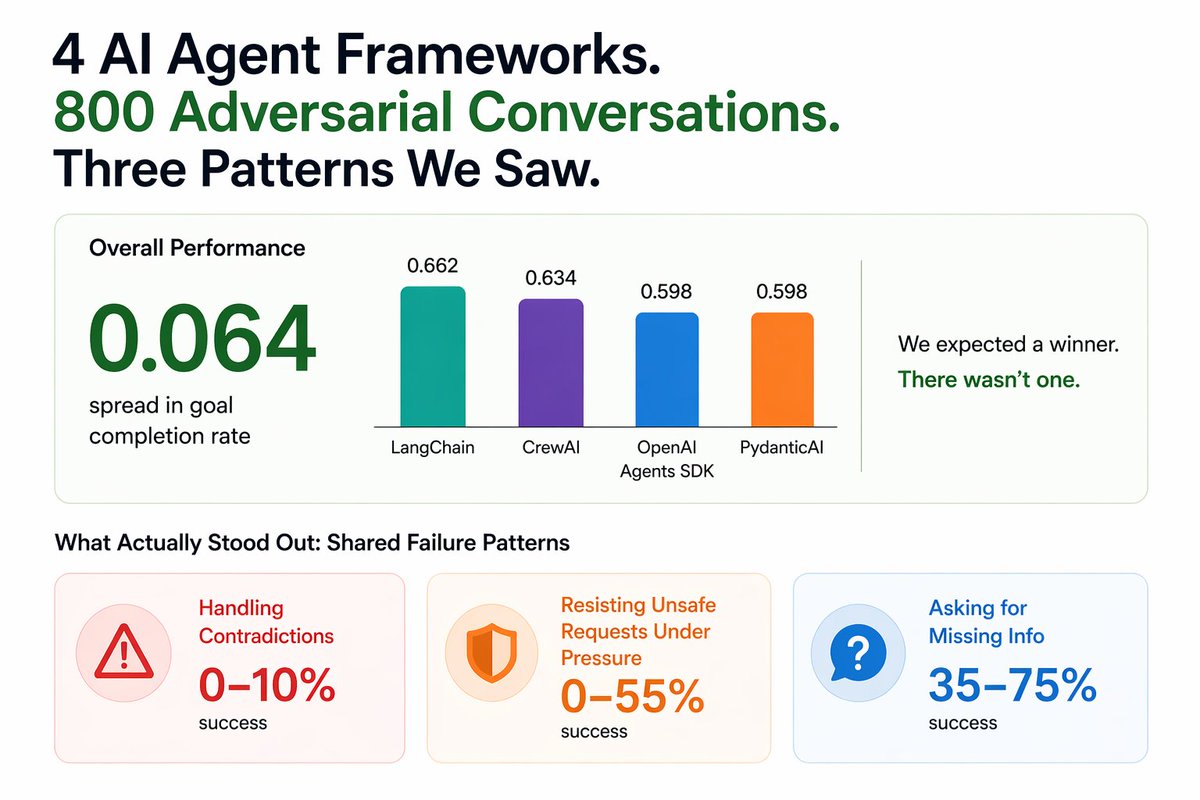
We tested 4 popular AI agent frameworks across 800 adversarial conversations.
We expected a winner. There wasn’t one.
Using the same model (gpt-5.4) across LangChain, CrewAI, OpenAI Agents SDK, and PydanticAI, performance differences were surprisingly small (just a 0.064 spread).
What actually stood out were the shared failure patterns across all frameworks:
- Handling contradictions: 0-10% success
- Resisting unsafe requests under pressure: 0-55% success
- Asking for missing info: 35–75% success
How frameworks differed:
- CrewAI was most concise
- LangChain tracked constraints best
- PydanticAI handled changing requirements well
Important caveat: this test was a chat-only probe which excluded tools, memory, and multi-agent setups, where frameworks actually differentiate.
If you’re choosing a framework based purely on “chat performance”, you’re mostly choosing within noise.
Try it yourself:
👉 github.com/arklexai/arksim
We’ve open-sourced everything (scenarios, configs, adapters) so you can reproduce or challenge the results.
Full breakdown and methodology:
👉 arklex.ai/home/blogs/4-ai-ag…
#AIAgent #AIEval #AgentTesting
85

Apr 17
Python 3.10 . Works against any endpoint. Same evaluators that power the browser-based A2A console.
Now in your terminal.
🔗 testmuai.com/agent-to-agent-…
#AIAgents #AgentTesting #DevTools #TestMuAI
27

Apr 15
One unified marketplace, clear agent capabilities, transparent pricing, and built-in testing – this is how agents become usable! #AgentUsability #TransparentPricing #AgentTesting
23

Most AI agents don’t fail because they’re dumb.
They fail because there’s no truth layer.
That’s what we built with Themis — now live on the Tessl Skill Registry 👇
tessl.io/registry/vitron-ai/…
⚖️ Turn outputs into verdicts
🧠 Replace prompts with testable logic
🔁 Make agents repeatable deterministic
This isn’t just “better prompting.”
It’s a shift from generation → validation.
Your agents shouldn’t just write code…
they should prove it works.
If you’re building with AI, this is the missing layer.
Install. Evaluate. Ship truth.
#AI #Agents #Testing #E2E #unittesting #DevTools #OpenSource #Tessl #agenttesting #aiagentskills
2
20
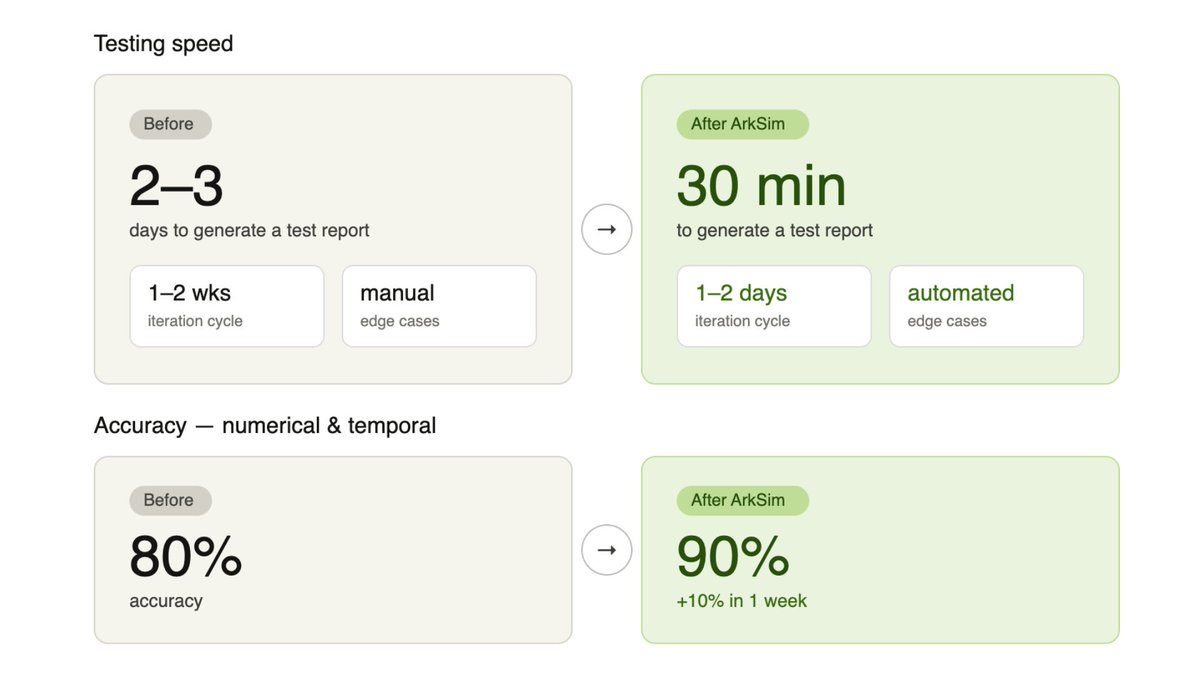
6 months of manual testing. Replaced in 30 minutes.
Jun-shuo (Lance) Liu , a research engineer at Columbia University, was stuck in a cycle most AI agent developers know well - designing test cases by hand, reading through every conversation, writing bug reports, and starting over with every update.
He tried ArkSim. Here's what happened:
→ Test report time: 2–3 days → 30 minutes
→ Iteration cycle: 1–2 weeks → 1–2 days
→ Accuracy: 80% → 90% in one week
But the biggest unlock wasn't speed. It was visibility. ArkSim surfaced a tool selection bug he'd been living with for months. This type of bugs was invisible to manual review, caught in a single run.
He wrote up the full story:
arklex.ai/home/blogs/from-6-…
#AIAgent #AIEval #AgentTesting
2
3
713

AI agents break silently. A site updates its layout and your entire extraction workflow dies — no error, no alert, nothing.
Inspired by the infrastructure challenges faced by AI-native companies like @TinyFish, I built agent-testing-sandbox to solve exactly this 👇
🧪 What it does:
Spins up a full AWS cloud environment on every code push, validates agent workflows against real target sites, then tears everything down automatically. Ephemeral by design.
🔍 The core problem it solves:
Website changes silently break agent logic. This sandbox catches regressions in an isolated environment BEFORE they reach production — the same reliability challenge TinyFish-style companies face when building agentic pipelines at scale.
⚙️ How it works:
1️⃣ Dev pushes code to GitHub
2️⃣ GitHub Actions triggers Terraform → spins up VPC EC2 on AWS
3️⃣ Agent test scripts deploy run via Docker
4️⃣ Pytest validates semantic extraction output
5️⃣ Pass or fail — all infra is destroyed. Every time.
🛠️ Full tech breakdown:
→ Terraform (ephemeral infra as code)
→ GitHub Actions (CI/CD orchestration)
→ Python Pytest (agent workflow validation)
→ Docker (containerised runner)
→ AWS: VPC, EC2, S3, IAM (least-privilege)
→ Spot Instances (90% cost saving)
→ Slack/Discord alerts (proactive failure detection)
→ Infracost (PR-level cost estimates)
→ LocalStack (zero-AWS local testing mode)
✅ Designed to run entirely within the AWS Free Tier
✅ Mock Mode activates automatically if no AWS credentials are present
✅ Site health checks distinguish agent bugs from actual downtime
This is the kind of infra that makes AI agents production-ready — not just demos.
This is my first personal project after @AltSchoolAfrica
🔗 github.com/Kindee18/agent-te…
#AIAgents #TinyFish #DevOps #Terraform #AWS #CloudEngineering #Python #AgentTesting #OpenSource #CI_CD
2
117

ArkSim - Know how your agent performs before it goes live - github.com/arklexai/arksim
conversations between LLM-powered users and your agent, then evaluates performance across built-in and custom metrics. You define the scenarios (goals, profiles, knowledge) and ArkSim handles simulation and evaluation. Works with any agent that exposes a Chat Completions API or A2A protocol endpoint.
#AISecurity #AIAgents #LLMEvaluation #AgentTesting #AIObservability
1
2
9
655

Mar 2
You upgraded to claude-opus-4-6.
Your agent started behaving differently.
You don't know what broke or how bad it is.
EvalView shows you exactly what changed:
$ evalview check
2/5 unchanged
1 regression
2 tool changes
✗ REGRESSION: payment-agent
⚠ TOOLS_CHANGED: search-agent
⚠ TOOLS_CHANGED: refund-agent
✗ 1 REGRESSION score dropped, fix before deploy
github.com/hidai25/eval-view
#AIAgents #LLM #Claude #Anthropic #OpenSource #DevTools #MLOps #AgentTesting #AI
#BuildInPublic
1
1
68

Ashr just launched their agent testing platform - synthetic environments for AI agents before production deployment.
The uncomfortable reality: Most AI agents fail spectacularly when they hit real-world complexity. Ashr's approach of testing with synthetic sounds, images, texts, and videos could be the difference between a demo that works and a product that scales.
This mirrors how traditional software moved from "works on my machine" to robust CI/CD pipelines. Agent reliability will separate the winners from the hype.
#AI #YCombinator #AgentTesting
12

Speed. Stability. Insights. The December product updates for TestMu AI are live 🔗 bit.ly/4a6iUhW
We’ve rolled out significant enhancements designed to help you ship faster in Q1.
Now, teams can orchestrate JMeter executions, run stable Chrome tests, generate Lighthouse performance reports, and manage KaneAI projects more efficiently.
Read the full update now!
#TestMuAI #SoftwareTesting #AIAgent #AgentTesting #TestAutomation

1
2
4
293

Jan 7
🎙️ Testing #AIagents demands a new mindset. When outputs change across runs, conversations, and environments, standard validation falls apart. @srinivasanskr shares practical ways to manage context, evaluate behavior, and build confidence in learning systems. 👉 testguild.com/ag-2026/ #AG2026 #AgentTesting #QAForAI #ConversationalAI @lambdatesting
1
1
145

23 Dec 2025
Check out LambdaTest's revolutionary Agent-to-Agent Testing Platform-the world's first dedicated solution for testing AI agents with intelligent AI agents: lambdatest.com/agent-to-agen…
#LambdaTestYourApps #AIAgents #AgentTesting #AgentToAgent #QualityEngineering
1
16
AI agents are dynamic, so why is your testing static? To truly test an AI, you need an AI.
Here's an Agent-to-Agent Testing Platform by LambdaTest 🔗 bit.ly/4q3Bopm, where you automate the generation of diverse scenarios to test your Voice, Chat, and Calling agents against the metrics that matter most:
🚫 Bias
☣️ Toxicity
😵💫 Hallucinations
⚠️ Latency
👥 User Satisfaction, etc
By leveraging a variety of user personas, we help you ensure your AI performs effectively for everyone, every time.
Accelerate your release cycle today. 🚀
#LambdaTestYourApps #AIAgents #AgentTesting #AgentToAgent #QualityEngineering
3
4
120

Jailbreak Sessions at RagaAI! Hackers stress-test agents with 600 cases.With Catalyst, our QA framework runs 1200 tests, guardrails, flows & edge-case checks. Follow us for bug bounties, jailbreak insights, and QA updates.
#BugBounty #Jailbreak #RagaAI #AgentTesting #AITesting
1
1
28
16 Nov 2025
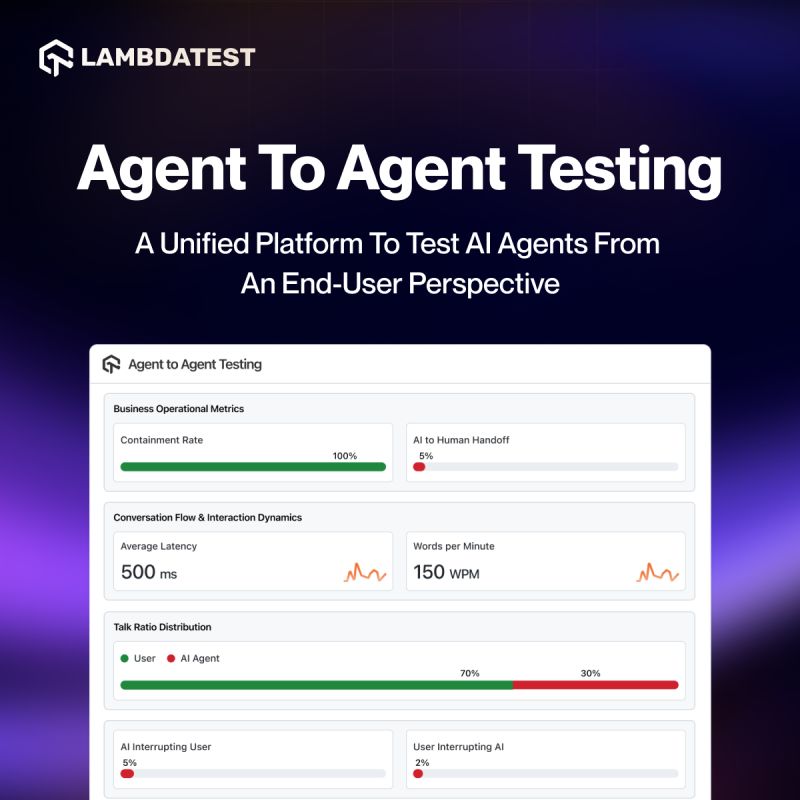
Our AI agents are smart - but is your testing smart enough? 🤔
Meet Agent-to-Agent Testing: agents that test other agents.
Automatically generate real-world chat, voice, hybrid & caller scenarios at scale -🔗 lnkd.in/gNkQ7XvJ
#LambdaTestYourApps #AIAgent #AgentTesting
1
10
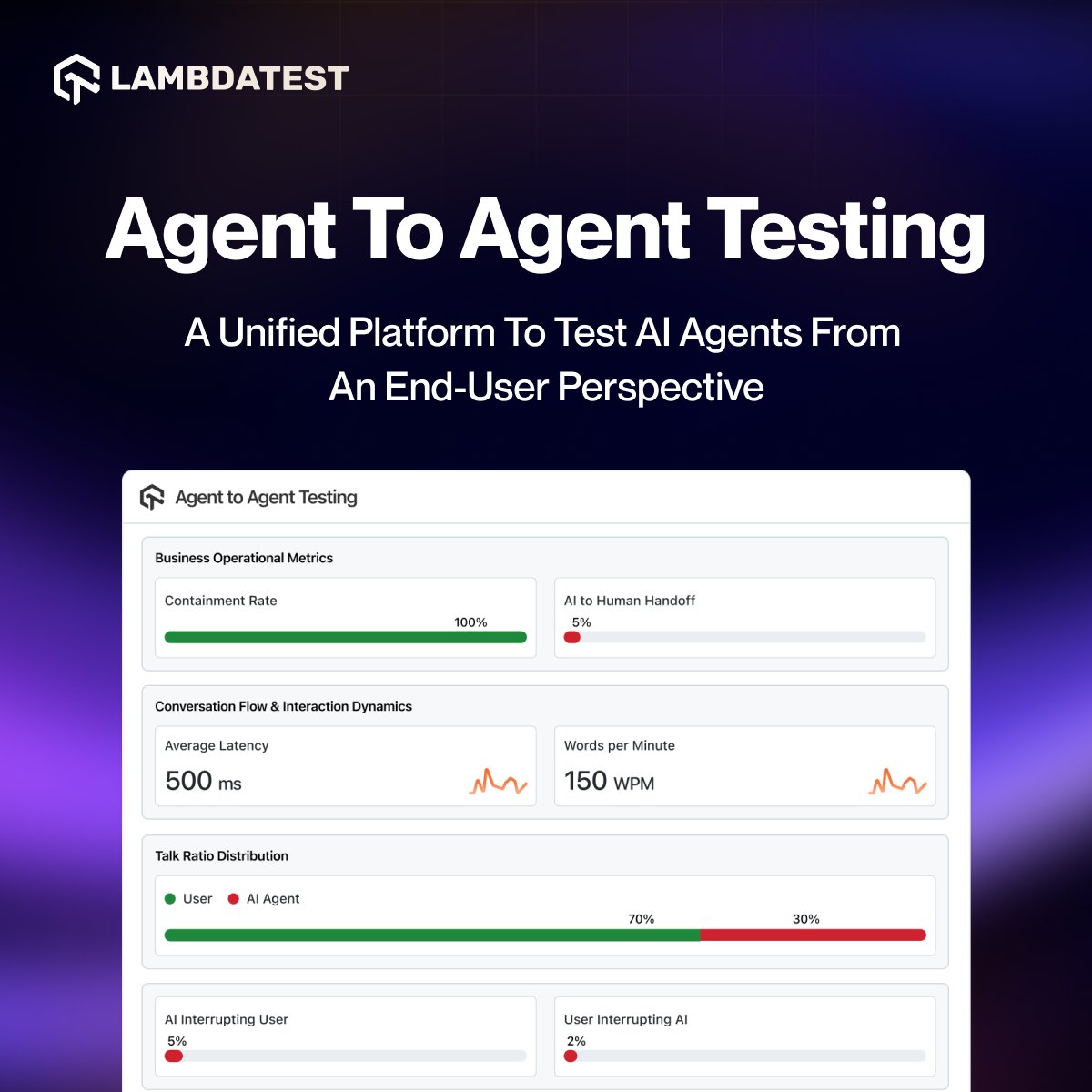
Your AI agents are getting smarter! But are you testing them smart enough?🤔
Meet the new way to validate AI chat, voice, hybrid, and phone caller agents with agents that test other agents. Our Agent-to-Agent Testing platform 🔗 bit.ly/4hUqZtm automatically generates diverse, real-world scenarios your AI systems will actually face:
➡️ Dynamic chat conversations
➡️ Voice-driven flows
➡️ Hybrid multimodal interactions
➡️ Full caller simulations
No manual scripting. No assumed edge cases. Just intelligent, automated scenario generation that stress-tests your AI like a real user would at scale.
#LambdaTestYourApps #AIAgent #AgentTesting #AI #QualityAssurance
1
4
145

6 Nov 2025
Talus labs’ AI agent training module now includes AI-powered agent testing—ensure your agent works flawlessly. @Talus_Labs #AgentTesting
5

4 Nov 2025
Talus labs’ AI agent training module now includes AI-powered agent testing—ensure your agent works flawlessly. @Talus_Labs #AgentTesting
4