
Most AI agents don’t fail because they’re dumb.
They fail because there’s no truth layer.
That’s what we built with Themis — now live on the Tessl Skill Registry 👇
tessl.io/registry/vitron-ai/…
⚖️ Turn outputs into verdicts
🧠 Replace prompts with testable logic
🔁 Make agents repeatable deterministic
This isn’t just “better prompting.”
It’s a shift from generation → validation.
Your agents shouldn’t just write code…
they should prove it works.
If you’re building with AI, this is the missing layer.
Install. Evaluate. Ship truth.
#AI #Agents #Testing #E2E #unittesting #DevTools #OpenSource #Tessl #agenttesting #aiagentskills
2
20

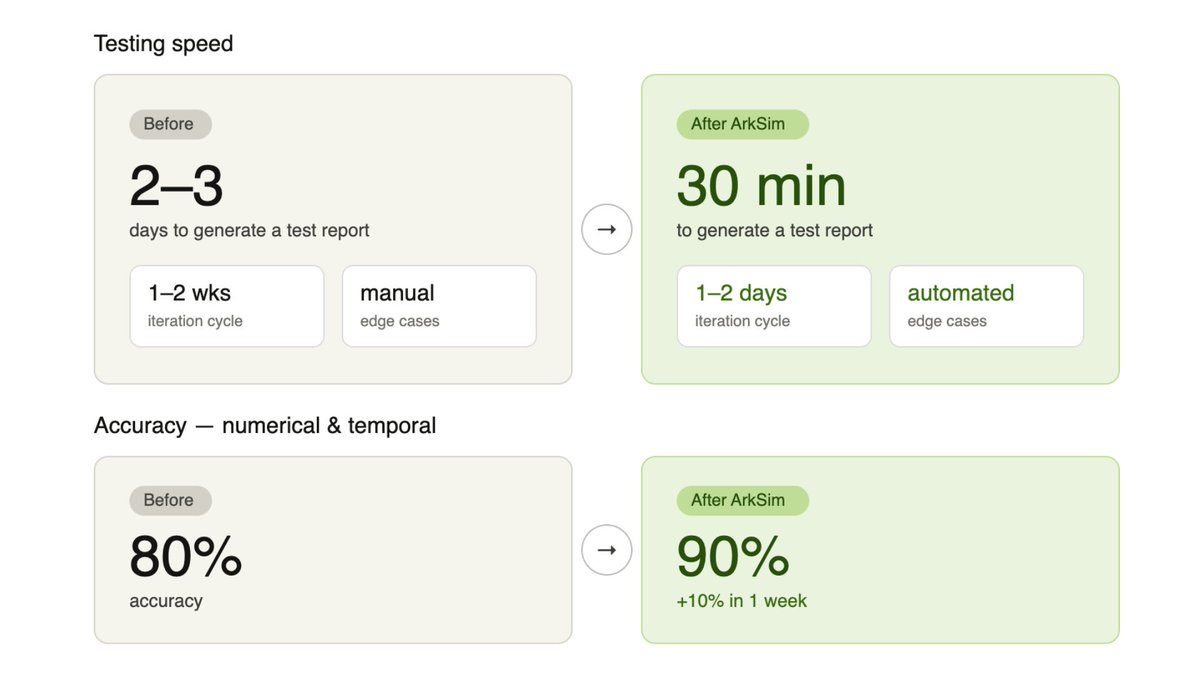
6 months of manual testing. Replaced in 30 minutes.
Jun-shuo (Lance) Liu , a research engineer at Columbia University, was stuck in a cycle most AI agent developers know well - designing test cases by hand, reading through every conversation, writing bug reports, and starting over with every update.
He tried ArkSim. Here's what happened:
→ Test report time: 2–3 days → 30 minutes
→ Iteration cycle: 1–2 weeks → 1–2 days
→ Accuracy: 80% → 90% in one week
But the biggest unlock wasn't speed. It was visibility. ArkSim surfaced a tool selection bug he'd been living with for months. This type of bugs was invisible to manual review, caught in a single run.
He wrote up the full story:
arklex.ai/home/blogs/from-6-…
#AIAgent #AIEval #AgentTesting
2
3
713

ArkSim - Know how your agent performs before it goes live - github.com/arklexai/arksim
conversations between LLM-powered users and your agent, then evaluates performance across built-in and custom metrics. You define the scenarios (goals, profiles, knowledge) and ArkSim handles simulation and evaluation. Works with any agent that exposes a Chat Completions API or A2A protocol endpoint.
#AISecurity #AIAgents #LLMEvaluation #AgentTesting #AIObservability
1
2
9
655

Speed. Stability. Insights. The December product updates for TestMu AI are live 🔗 bit.ly/4a6iUhW
We’ve rolled out significant enhancements designed to help you ship faster in Q1.
Now, teams can orchestrate JMeter executions, run stable Chrome tests, generate Lighthouse performance reports, and manage KaneAI projects more efficiently.
Read the full update now!
#TestMuAI #SoftwareTesting #AIAgent #AgentTesting #TestAutomation

1
2
4
293
AI agents are dynamic, so why is your testing static? To truly test an AI, you need an AI.
Here's an Agent-to-Agent Testing Platform by LambdaTest 🔗 bit.ly/4q3Bopm, where you automate the generation of diverse scenarios to test your Voice, Chat, and Calling agents against the metrics that matter most:
🚫 Bias
☣️ Toxicity
😵💫 Hallucinations
⚠️ Latency
👥 User Satisfaction, etc
By leveraging a variety of user personas, we help you ensure your AI performs effectively for everyone, every time.
Accelerate your release cycle today. 🚀
#LambdaTestYourApps #AIAgents #AgentTesting #AgentToAgent #QualityEngineering
3
4
120
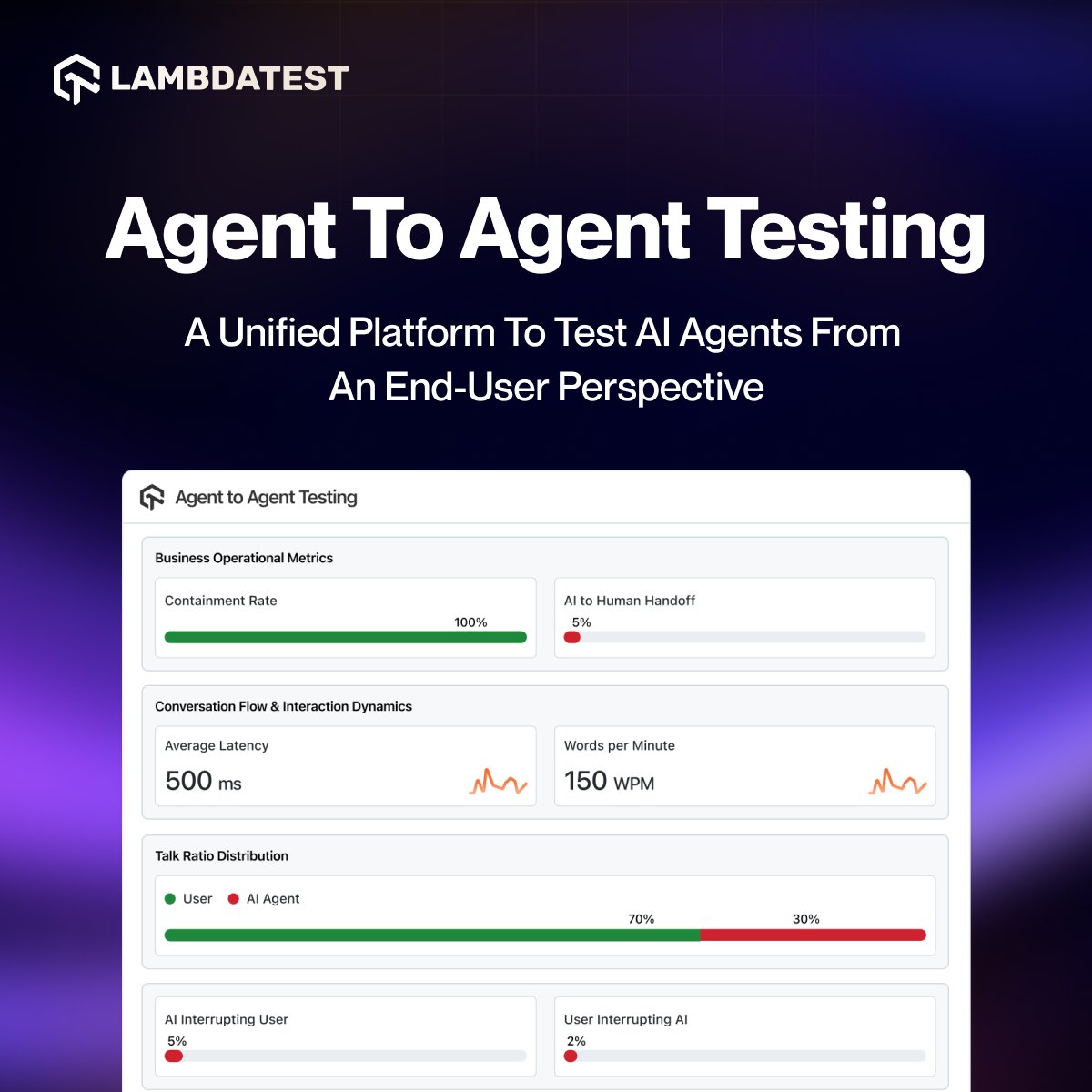
Your AI agents are getting smarter! But are you testing them smart enough?🤔
Meet the new way to validate AI chat, voice, hybrid, and phone caller agents with agents that test other agents. Our Agent-to-Agent Testing platform 🔗 bit.ly/4hUqZtm automatically generates diverse, real-world scenarios your AI systems will actually face:
➡️ Dynamic chat conversations
➡️ Voice-driven flows
➡️ Hybrid multimodal interactions
➡️ Full caller simulations
No manual scripting. No assumed edge cases. Just intelligent, automated scenario generation that stress-tests your AI like a real user would at scale.
#LambdaTestYourApps #AIAgent #AgentTesting #AI #QualityAssurance
1
4
145

18 Oct 2025
"With the persistence of a river carving a new path through stone."
Manual testing of AI agents is a time taking.
Rogue changes the game. An open source framework where one agent tests another automatically.
#ThoughtForTheDay #agent #agenttesting
1
1
3
57
Why AI agents forget - and how Context Engineering solves it
AI agents fail when context isn’t structured or retrieved properly, leading to errors, outdated information, or reasoning drift.
In this blog, @saikrisv & @srinivasanskr, Directors of Engineering at LambdaTest, break down the 4 context failure modes - poisoning, distraction, confusion, clash and show how the WRITE and SELECT pillars manage memory and retrieval for reliable, task-relevant outputs along with real-world examples.
Read now🔗 bit.ly/4hgis3L
#AI #AIAgent #ContextEngineering #AgentTesting #LambdaTestYourApps

3
3
134
AI is evolving fast. Testing needs to evolve faster.⚡
With LambdaTest’s Agent-to-Agent Testing, we’re setting a new benchmark:
😎Agents testing agents through a multi-agent system
🌎Intelligent real-world scenario generation that covers the known, unknowns, and edge cases
⚡Continuous, scalable validation with parallel execution for instant feedback
🔒Broader coverage, including the hardest edge cases
This isn’t just another tool. It’s the future of how AI agents get tested.
Learn More👉 bit.ly/3V8p0Hi
#AI #AgentTesting #MultiAgentSystems #LambdaTest

2
4
142
PentestJudge: Judging Agent Behavior Against Operational Requirements -arxiv.org/abs/2508.02921 by @dreadnode
Introducing PentestJudge, an LLM-as-judge system for evaluating the operations of pentesting agents. The scores are compared to human domain experts as a ground-truth reference, allowing us to compare their relative performance with standard binary classification metrics, such as F1 scores.
Inspired by OpenAI's work with PaperBench, "PentestJudge: Judging Agent Behavior Against Operational Requirements" explores:
➡️ Model performance vs. human experts (seeing strong performance from Claude and Kimi)
➡️ Cost analysis of the different models evaluated vs. human experts
➡️ The different failure modes observed in the judge, with an emphasis on shallow model tool calling capabilities
➡️ Future work leveraging the output of these judge systems as a reward signal for difficult-to-verify domains within security using techniques like GRPO for model training
Authors: @shncldwll, @0xdab0, @VincentAbruzzo, @moo_hax, and Michael Kouremetis.
#PentestJudge #PenTestAI #AISecurity #AIJudging #SecurityAI #AIModels #ModelTesting #CyberAI #AIResearch #AIExperts #ClaudeAI #KimiAI #AITraining #ToolCalling #ModelScores #AIAgents #CostAnalysis #FailureModes #RewardSignals #AgentTesting #AICompare #Benchmarks #AIJudge #PentestJudge #LLMSecurity

5
11
1,138

3 Aug 2025
I’ve been in Software test engineering for over a decade.
🧪 I’ve seen test automation evolve from:
➡️ Basic shell/Python scripts
➡️ Record-and-play tools like selenium IDE, QTP, TestComplete
➡️ Selenium test suites that broke when any UI element changed
Then came the shift to code:
✅ pytest for fast backend/API tests
✅ JUnit/TestNG for scalable test suites
✅ We automated assertions, mocked services, tested logic early
🔁 CI/CD became the norm — tests ran on every commit Tests were no longer “extra.” They were essential.
Then came the browser revolution: 🚀 Tools like Cypress and Playwright gave us:
Parallel runs
Automatic waits
Reduced flakiness
Dev-friendly test flows
I still remember the first time I saw 50 UI tests run in under 2 minutes. Magic. ✨
🌐 Then in terms of performance testing:
JMeter ruled for a while
Then came k6: modern, scriptable, DevOps-ready We started testing scale, not just correctness.
But today?
I’m witnessing something wild.
🤖 Agent-vs-Agent Testing is here.
One AI agent simulates a user
The other is the system under test (AI chatbot, AI voice agent,)
LLMs like GPT act as judges, evaluating responses for: Correctness Tone Helpfulness Real intent match
We’re no longer asserting status codes or UI clicks.
We’re testing language, intent, and experience.
🧠 The test automation stack is no longer just a pyramid. It’s a feedback loop — powered by AI.
🎥 Want to see Agent-vs-Agent testing in action? Check the attached video
#QA #TestAutomation #LLM #AgentTesting #Cypress #Playwright #pytest #JMeter #k6 #DevOps #AI #SoftwareTesting #BuildInPublic #TestingCommunity
3
198

30 Jun 2025
Not all agents are created equal @recallnet puts them to the ultimate test.
🔥 Open-ended competitions
🧠 Framework-agnostic evaluation
⚔️ Real-time performance battles
If your AI can thrive here, it’s ready for anything.
#RecallNet #AgentTesting #AICompetition

3
2
5
41