
All other LLMs: Let us Benchmax our models
Le Chaton- let us get a fat Cat and measure its fat percentage and report it as our models capability
7
77

OpenRouterのFusion APIはBenchMax的なイメージが強いが、ベンチマークで強ければ強いので、ベンチマークが出そろうのを待ちたい。出そろうの?
1
512

MiniMax = benchmax
Rio = benchmax
Nex = benchmax
DeepSeek = real
Kimi = real
GLM = real
17




Benchmax or no? I assume you are not running it locally
1
1
59

Jun 12
DeepSWE shows you the true reality amidst all this benchmax bullshit.
I'm glad I stuck to my OG gpt 5.5 without spending money on minimax, fable and now the new kimi.
Instead of diverse subs and endless routing complications, went all in on Pro 20x plan and its worth every penny.
manual resets is just the cherry on top!
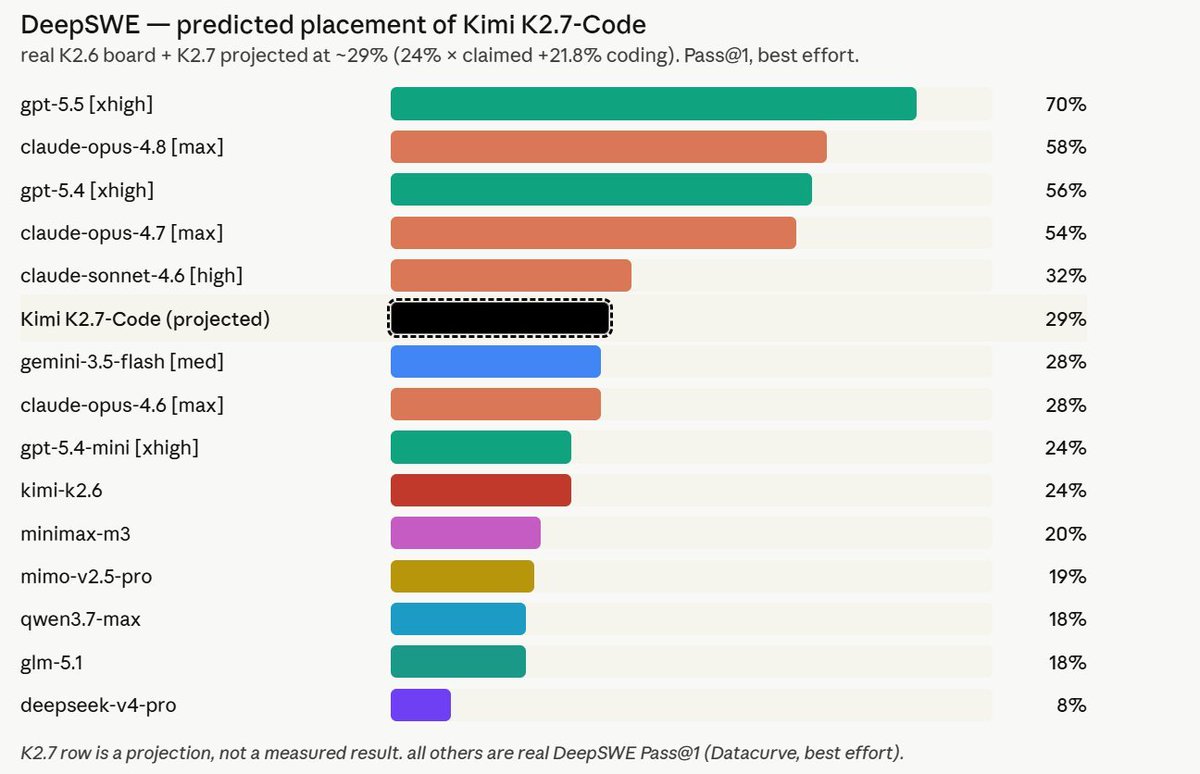

1
316

Jun 12
The frontier labs were already bored of math contests by the 2025 Putnam, and they will certainly not bother with IMO 2026. I could imagine that some formalization startup might still try pursue a Lean-verified IMO perfect score, which has not been accomplished yet ... but I hope they don't -- we all know that Codex/Claude could do this easily, so please just leave the spotlight to the students.
As for research math: it appears the only frontier labs pushing this have been OpenAI and Google DeepMind. My guess from observing OpenAI is that they use Erdos problems (only) as some kind of internal benchmark, but they do not try to benchmax and they only release solutions that are sufficiently interesting. DeepMind is a different beast, which pursues math and science applications for their own sake and will likely continue doing so.
I think there will also continue to be a space for startups to do research math things. They're not expected to make revenue for a while, and they can find some story to spin to VCs about why it will eventually be profitable.
9
981


Jun 10
yes for now we have cursor bench which gives good data, its just v coding specific. I like the AAII cost token score data because there's nowhere to hide -- those tests are too long to benchmax collectively and we can see performance:cost:latency tradeoff clearly
3
4
225

Jun 10
Is the result based on the public question set that model developers could hack or benchmax, or the private held-out questions?
1
95
Andreas Oschinski retweeted

Lol they retain every single prompt permanently forever
How do you think they benchmax and improve?

new policy from anthropic: if you use fable/mythos, they collect your data.
no exceptions. not even for enterprise partners.

2
3
3
1,764

Jun 10
If you were a company and you were going to benchmax once, when would you do it?
4
7
4,788



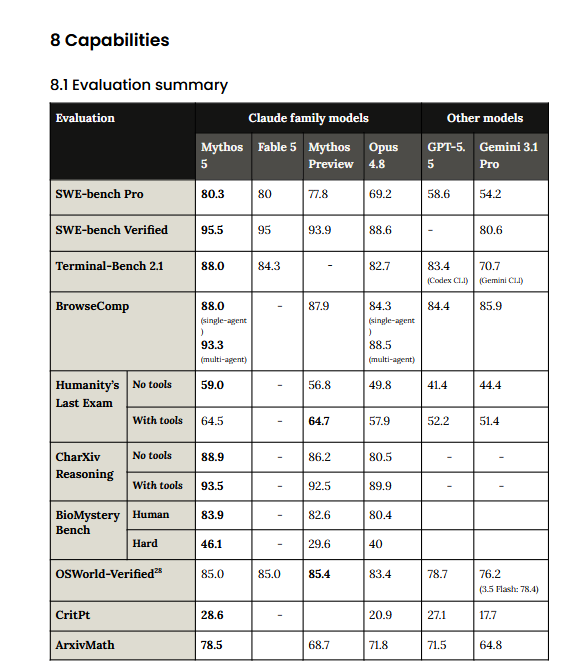

They've been nerfing models for a while after release, so the new releases feel "amazing"
I noticed this trend last year, they benchmax release, then dumb down over the months.
That's my reason for not using anthropic (and google models).
It's just marketing and milking cows
1
1
603