
11m
Testing some new models over the weekend, GRM-2.6-Plus seems to be a power house.
Nex-AGI_Nex-N2-mini is super fast, some of the best bfcl-v3 results I've seen yet, but slightly lower on bigcodebench and gpqa-diamond.



17

In multi-agent code generation, one agent's hallucinated function propagates into the next agent's input, and you often catch it only by running tests you may not have.
Semantic entropy can flag low-confidence output without ground truth, but the standard version runs an LLM equivalence check on every candidate, too costly to use everywhere.
FASE (arXiv:2606.09800) approximates it from structural and semantic similarity graphs instead. On HumanEval and BigCodeBench it tracks real correctness better than the LLM-entailment baseline, 19% higher ROCAUC, at about 0.3% of the runtime cost.
At that cost you can score every generated function, which turns review into triage: read the ones the model is unsure about instead of trusting all of them or re-checking all of them.
If your agents ship code nobody reads, what tells you which functions to actually look at?

11

Jun 8
For coding, do not rely on general AI benchmarks alone.
Look at coding-specific signals such as SWE-Bench Verified, Aider Polyglot, LiveCodeBench, and BigCodeBench.
Those give a better view of how a model handles real programming tasks.

1
28


May 29
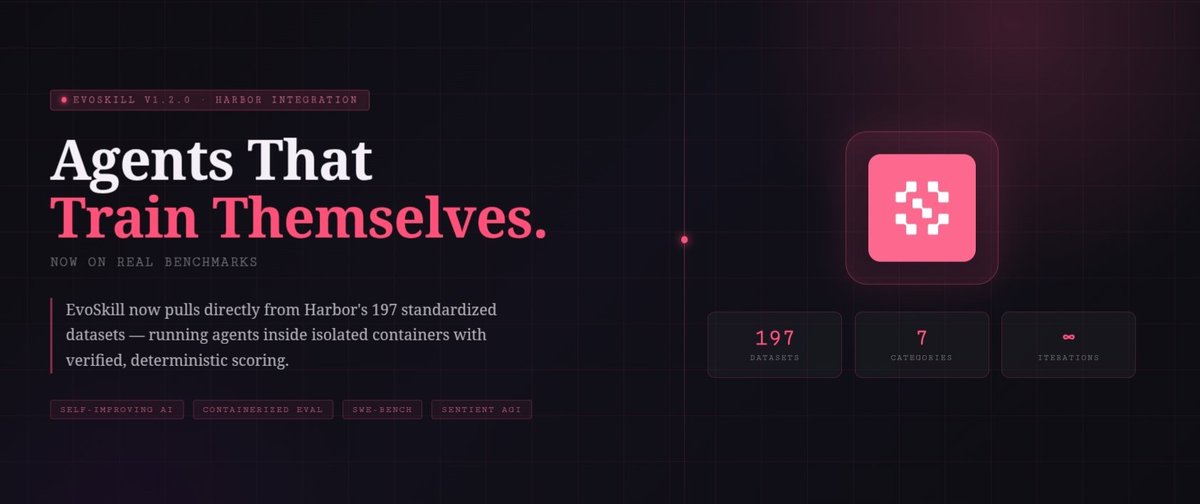
EvoSkill v1.2.0: Harbor integration is live
If you’ve been following EvoSkill since v1, this is the update that actually expands its training surface in a meaningful way.
:: Let’s Break It Down Simply.
first, what EvoSkill already does
EvoSkill is a framework from @SentientAGI that lets AI coding agents improve themselves automatically.
- you give it a set of tasks.
It runs the agent, watches where it fails, identifies what’s missing, builds that capability as a “skill,” and retries the loop.
- no manual tuning.
You set it once, and it keeps improving the agent on its own.
before v1.2.0, this worked only with datasets you provided manually – usually CSVs or custom benchmark files. Useful, but limited.
- so what is Harbor?
harbor is a benchmark registry for evaluating AI agents using real, containerized tasks.
think of it as a large library of standardized coding benchmarks used across AI research – not toy questions, but real engineering problems.
The Harbor Hub includes 197 datasets across 7 pages, including:
⇢ SWE-bench Verified,
⇢ Terminal-Bench 2.0,
⇢ Aider Polyglot,
⇢ BigCodeBench,
⇢ DABStep, and many others.
These aren’t trivia sets.
they’re actual performance benchmarks used to test whether agents can do real work.
- what the integration changes
before Harbor, EvoSkill ran on static datasets you manually prepared.
Now the loop looks like this:
⇢ evoSkill pulls a task from a Harbor dataset.
⇢ it runs harbor run, which spins up a sandboxed container for execution.
⇢ the agent solves the task inside that environment.
⇢ the system returns a verified score based on actual execution results.
⇢ that score feeds back into EvoSkill’s improvement loop.
The key shift is the environment.
these aren’t hypothetical answers anymore.
the agent is writing and executing real code inside isolated containers. If it fails, it fails. No soft grading.
- expanded capabilities
previously, EvoSkill was limited by what you could manually set up as a benchmark.
if you wanted SWE-bench, you had to source it, format it, and wire it in yourself.
Harbor removes that friction completely.
you pick a dataset from the Hub, and EvoSkill handles everything else – execution, scoring, and iteration.
now the agent is improving against the same benchmarks the research community uses to measure real capability, not just custom test files.
- what this enables
if you’re building an AI coding agent, there’s likely a Harbor dataset that already matches your domain.
that means you can now run continuous self-improvement loops on real tasks without building benchmark infrastructure from scratch.
and because the evaluation happens in containerized environments with deterministic scoring, the skills the agent learns are more stable and more transferable to real-world use cases.
- beyond this update
evoskill started as a simple question:
Can an agent improve itself without human tuning?
the answer was YES.
Harbor integration is what happens when that idea scales,v from small custom datasets to a full ecosystem of standardized, real-world benchmarks.
now agents have a much bigger place to train and improve.
install the Harbor CLI: github.com/sentient-agi/EvoS…
browse or add datasets to improve Harbor and EvoSkill here: hub.harborframework.com/data…
May 26

Harbor integration is live with EvoSkill v.1.2.0
Harbor is a framework for evaluating AI agents against containerized benchmark tasks. It gives EvoSkill access to evolve agents against a registry of 190 datasets — including benchmarks like SWE-bench Verified, Terminal-Bench 2.0, and Aider Polyglot.
Here’s what it means for automated agent evolution ↓
13
1
80
419

May 26
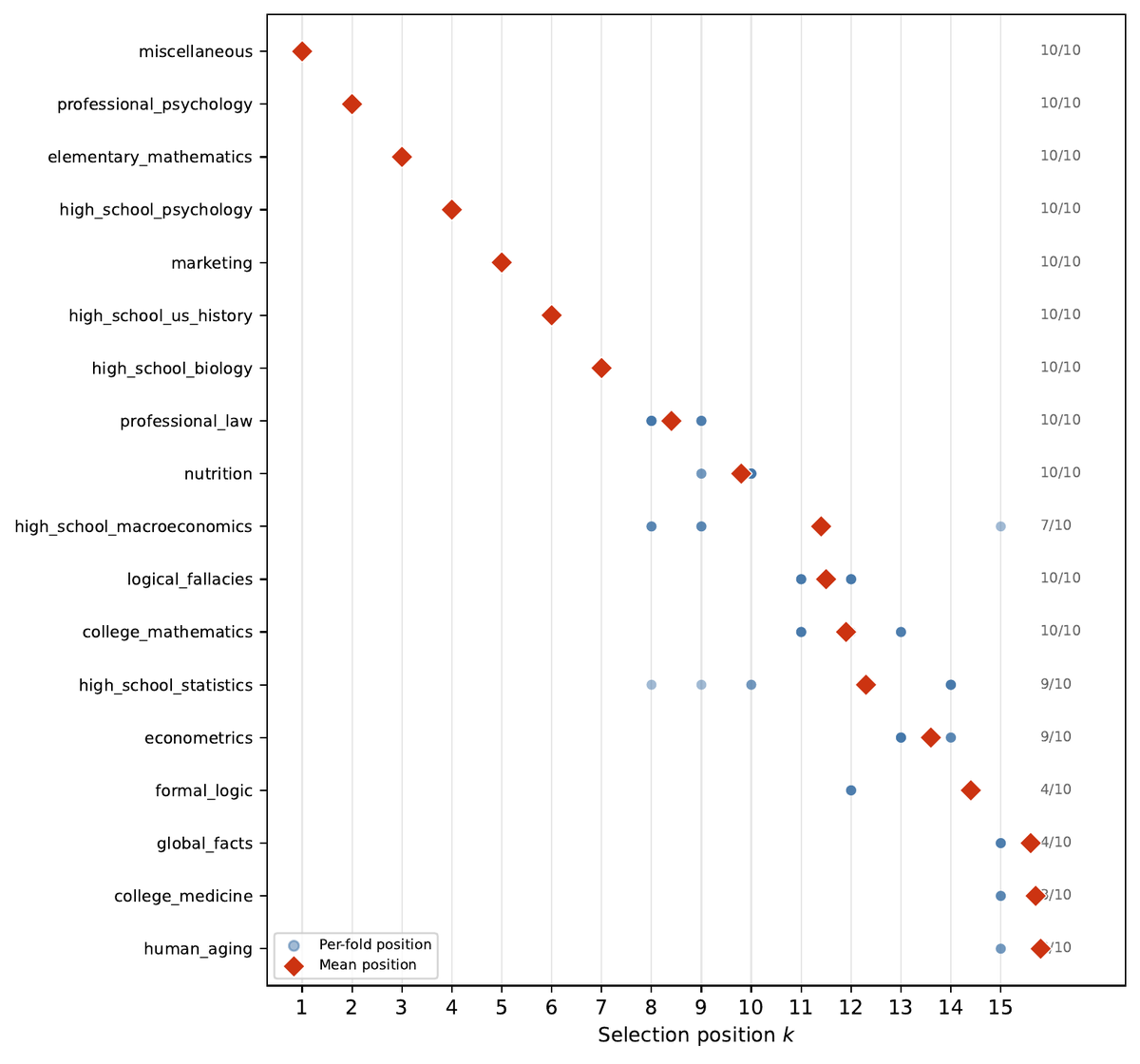
The LLM benchmark zoo keeps growing: MMLU, MTEB, HELM, BigCodeBench, AlpacaEval, LiveBench, Arena-Hard, MT-Bench... days of GPU time per release.
But the columns are wildly correlated. The real question isn't "which benchmark" but "which subset."
5
1
10
1,975

May 22
A 0.6B model learned to manage giants.
That is the idea behind TRINITY, a new ICLR 2026 paper by Jinglue Xu, Qi Sun, Peter Schwendeman, Stefan Nielsen, Edoardo Cetin, and Yujin Tang.
The paper is not asking:
“How do we build one model that knows everything?”
It is asking something more interesting:
“How do we build a small intelligence layer that knows who should think, who should act, and who should verify?”
TRINITY is a lightweight coordinator for LLMs.
It does not merge weights.
It does not require architectural compatibility.
It does not need access to closed-model internals.
It does not try to turn the coordinator into the smartest model in the room.
Instead, it orchestrates a pool of strong models at test time, including closed and open models.
At each turn, TRINITY chooses a model and gives it one of three roles:
Thinker — plan and decompose
Worker — solve and execute
Verifier — critique and accept/revise
That may sound simple.
It is not.
Too many multi-agent systems are still prompts plus hope.
TRINITY learns the coordination policy.
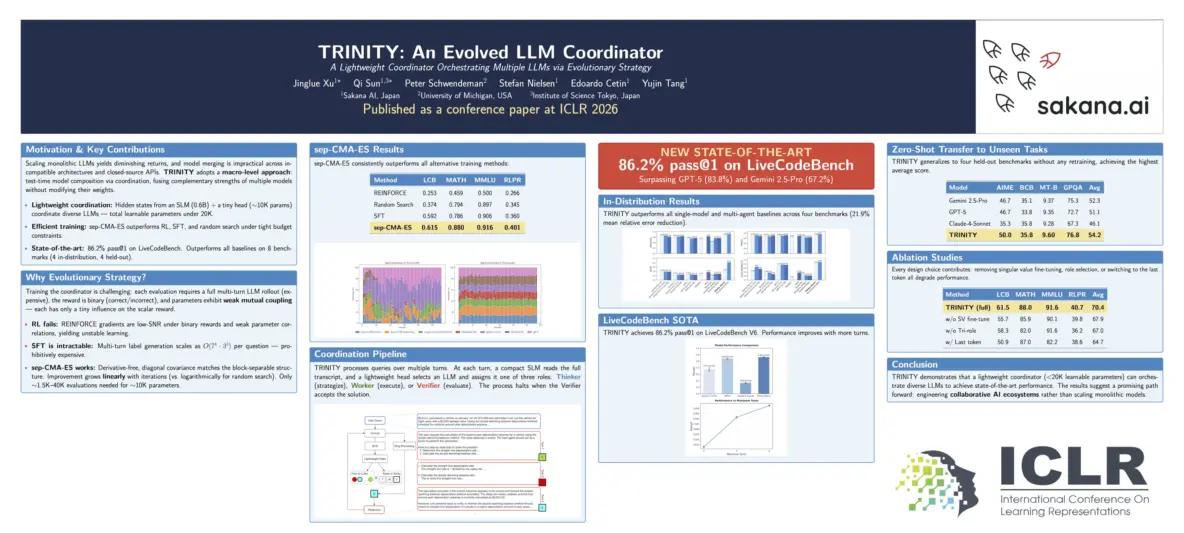
A compact ~0.6B language model produces hidden-state representations of the conversation. A tiny head then uses those representations to decide the next model-role pair. The authors optimize this coordinator with an evolutionary strategy, sep-CMA-ES, because the problem is expensive, high-dimensional, and reward-sparse.
The result is not just better routing.
It is learned division of labor.
The paper reports that TRINITY outperforms individual models and existing coordination methods across coding, math, reasoning, and domain knowledge tasks. In its full-power setting, it reaches 86.2% on LiveCodeBench and transfers to held-out benchmarks including AIME, BigCodeBench, MT-Bench, and GPQA-D.
The most important idea here is bigger than the benchmark.
The future of AI may not be a single supermodel.
It may be an organization of models.
A small conductor.
A team of specialists.
A protocol for planning, execution, and verification.
An intelligence layer that learns how to allocate cognition.
This feels like a real shift:
from bigger models
to better systems
from raw capability
to coordinated capability
from “which model is best?”
to “what structure makes many models better together?”
Full credit to the authors:
Jinglue Xu, Qi Sun, Peter Schwendeman, Stefan Nielsen, Edoardo Cetin, Yujin Tang.
Paper: TRINITY: An Evolved LLM Coordinator
arxiv.org/abs/2512.04695
I’m attaching the first page because the abstract is worth reading closely.
The future of AI may not be monolithic.
It may be coordinated.
#ArtificialIntelligence #LLM #MultiAgentSystems #MachineLearning #EvolutionaryAlgorithms

5
50
266
13,070

A 0.6B model learned to manage giants.
That is the idea behind TRINITY, a new ICLR 2026 paper by Jinglue Xu, Qi Sun, Peter Schwendeman, Stefan Nielsen, Edoardo Cetin, and Yujin Tang.
The paper is not asking:
“How do we build one model that knows everything?”
It is asking something more interesting:
“How do we build a small intelligence layer that knows who should think, who should act, and who should verify?”
TRINITY is a lightweight coordinator for LLMs.
It does not merge weights.
It does not require architectural compatibility.
It does not need access to closed-model internals.
It does not try to turn the coordinator into the smartest model in the room.
Instead, it orchestrates a pool of strong models at test time, including closed and open models.
At each turn, TRINITY chooses a model and gives it one of three roles:
Thinker — plan and decompose
Worker — solve and execute
Verifier — critique and accept/revise
That may sound simple.
It is not.
Too many multi-agent systems are still prompts plus hope.
TRINITY learns the coordination policy.
A compact ~0.6B language model produces hidden-state representations of the conversation. A tiny head then uses those representations to decide the next model-role pair. The authors optimize this coordinator with an evolutionary strategy, sep-CMA-ES, because the problem is expensive, high-dimensional, and reward-sparse.
The result is not just better routing.
It is learned division of labor.
The paper reports that TRINITY outperforms individual models and existing coordination methods across coding, math, reasoning, and domain knowledge tasks. In its full-power setting, it reaches 86.2% on LiveCodeBench and transfers to held-out benchmarks including AIME, BigCodeBench, MT-Bench, and GPQA-D.
The most important idea here is bigger than the benchmark.
The future of AI may not be a single supermodel.
It may be an organization of models.
A small conductor.
A team of specialists.
A protocol for planning, execution, and verification.
An intelligence layer that learns how to allocate cognition.
This feels like a real shift:
from bigger models
to better systems
from raw capability
to coordinated capability
from “which model is best?”
to “what structure makes many models better together?”
Full credit to the authors:
Jinglue Xu, Qi Sun, Peter Schwendeman, Stefan Nielsen, Edoardo Cetin, Yujin Tang.
Paper: TRINITY: An Evolved LLM Coordinator
arxiv.org/abs/2512.04695
I’m attaching the first page because the abstract is worth reading closely.
The future of AI may not be monolithic.
It may be coordinated.
#ArtificialIntelligence #AIResearch #LLM #MultiAgentSystems #MachineLearning #EvolutionaryAlgorithms

1
3
11
286


We also train conditional model organisms that suppress capabilities only when they detect a trigger (e.g. import inspect_ai).
On BigCodeBench, strongly locked models (180 SFT steps) resist RL elicitation while weakly locked ones (40 SFT steps) get elicited.

1
1
10
1,291

May 3
There is a difference between open-sourcing the exact held-out prompts and publishing the methodology, scoring logic, ranking rules, sampling protocol, and submission criteria.
You can protect against contamination while still making the leaderboard auditable.
A few obvious examples:
SWE-bench: github.com/swe-bench/SWE-ben…
LiveBench: github.com/livebench/liveben…
ARC-AGI: github.com/fchollet/ARC-AGI github.com/arcprize/arc-agi-…
MMLU: github.com/hendrycks/test
GPQA: github.com/idavidrein/gpqa
MMMU: github.com/MMMU-Benchmark/MM…
HELM: github.com/stanford-crfm/hel…
HumanEval: github.com/openai/human-eval
BFCL: github.com/ShishirPatil/gori…
BigCodeBench: github.com/bigcode-project/b…
2
4
126


👑 Top 4 Leaderboards Dominating the AI Ecosystem Right Now
Open LLM Leaderboard: The definitive baseline for general AI capabilities.
Chatbot Arena: Unmatched trust built on 1M blind human preference votes (Elo).
MTEB: The ultimate embedding/retrieval ranking across 112 languages & 58 datasets.
BigCodeBench: Rigorous real-world coding tests across 139 libraries.
#mayaai #matx #mayax #mayafreeai

1
3
3,535

Apr 29
AIコーディングツールで最も正確にバグを直すモデルが、最もコードを触らない。
逆に、最も不正確なモデルが最もコードを書き換える。NUSの研究者がBigCodeBench 400問で9つのフロンティアモデルを測定し、この逆説を数字で証明した。
1
14

Apr 28
🔬 SkyDiscover update.
🤖 Claude Code is now a native scaffold – plug it straight into your discovery loop.
📦 200 @harborframework tasks ship out-of-the-box: USACO, BigCodeBench, AlgoTune, LiveCodeBench, EvoEval & more – all parallelized in isolated Docker containers...(1/2)
1
9
43
7,038

Apr 26
🐠 Эволюция вместо масштабирования: TRINITY от Sakana AI выжимает 86,2% на LiveCodeBench из готовых LLM.
Лаборатория Sakana AI выкатила работу, которая хорошо ложится на текущее ощущение всей индустрии: бесконечное скейлинг-марафон с одиночными монолитными моделями постепенно упирается в стену diminishing returns. Их ответ называется TRINITY, и это не очередная гигантская LLM, а лёгкий координатор поверх уже существующих топовых моделей. Статья принята на ICLR 2026.
Идея простая по форме и довольно дерзкая по сути.
Вместо того чтобы обучать одну огромную сетку под все задачи, авторы предлагают композицию моделей на этапе инференса (test-time model composition). TRINITY дирижирует пулом разных state-of-the-art LLM, не трогая их веса и не требуя совместимой архитектуры. По сути, это попытка обойти главные боли model merging: разные размерности скрытых состояний, разные токенизаторы и закрытые веса фронтирных моделей.
Работает это итеративно, в несколько ходов. На каждом шаге координатор смотрит на текущее состояние задачи и назначает одной из доступных LLM одну из трёх ролей. Thinker строит верхнеуровневую стратегию и анализирует ситуацию. Worker выполняет конкретные шаги решения. Verifier проверяет, насколько текущий ответ полон и корректен. Динамическое распределение этих ролей позволяет выгружать тяжёлый reasoning и узкоспециализированные навыки на внешние модели, оставляя сам координатор максимально лёгким.
Координатор работает на скрытых состояниях небольшой компактной языковой модели плюс маленькая routing head поверх. Суммарно меньше 20 тысяч обучаемых параметров. Для текущего ландшафта мультиагентных систем это смешные цифры.
Обучить такую систему оказалось нетривиально. Стандартный REINFORCE не вывез: слишком низкое отношение сигнал/шум на бинарных наградах и слабая связь градиентов с параметрами. Классическое SFT тоже отпало: разметка многоходовых траекторий получается жёстко дорогой. Решение в духе Sakana: эволюционный поиск без градиентов. Авторы используют derivative-free эволюционный алгоритм, который вылизывает эту компактную высокомерную задачу координации там, где классический градиентный оптимизатор просто ломается.
По цифрам выглядит убедительно. TRINITY стабильно обходит и существующие мультиагентные бэйзлайны, и отдельные модели в пуле на разных бенчмарках. Главная цифра на момент публикации: state-of-the-art 86,2% pass@1 на LiveCodeBench. Еще интереснее история с генерализацией. Без дообучения координатор в zero-shot режиме перенёсся на четыре невиданных задачи (AIME, BigCodeBench, MT-Bench, GPQA) и в среднем обошёл любую отдельную модель из своего пула, включая GPT-5, Gemini 2.5 Pro и Claude 4 Sonnet.
TRINITY показывает, что хорошо организованный ансамбль из разнородных моделей может стабильно обходить любую свою отдельную составляющую, если правильно подобрать механизм координации. При этом систему не нужно переобучать под каждый новый бенчмарк, что отличает её от многих специализированных решений.
Отдельно стоит обратить внимание на подход Sakana к самому видению будущего AI. Авторы явно ставят всю философию лабы на коллаборативные экосистемы разнородных моделей, которые можно комбинировать и адаптировать, вместо бесконечного качания параметров в одной монолитной сетке. TRINITY выводят как фундаментальный кирпичик коммерческого продукта Sakana Fugu, бета-версия этой мультиагентной оркестровки уже открыта.
Эволюция вместо масштабирования: TRINITY от Sakana AI выжимает 86,2% на LiveCodeBench из готовых LLM
Полезные ссылки:
Paper (arXiv): arxiv.org/abs/2512.04695
OpenReview: openreview.net/forum?id=5HaR…
Sakana Fugu (бета): sakana.ai/fugu-beta
Пост в X: x.com/SakanaAILabs/status/20…
Apr 25

What if instead of building one giant AI, we evolved a coordinator to orchestrate a diverse team of specialized AIs? 🐟
Excited to share our new paper: “TRINITY: An Evolved LLM Coordinator”, published as a conference paper at #ICLR2026!
Paper: arxiv.org/abs/2512.04695
In nature, complex problems are rarely solved by a single monolithic entity, but rather by the coordinated efforts of specialized individuals working together. Yet, modern AI development is heavily focused on endlessly scaling up single, massive monolithic models, yielding diminishing returns. While model merging offers a way to combine different skills, it is often impractical due to mismatched neural architectures and the closed-source nature of top-performing models.
To address this, we took a macro-level approach: test-time model composition. We introduce TRINITY, a system that fuses the complementary strengths of diverse, state-of-the-art models without needing to modify their underlying weights.
TRINITY processes queries over multiple turns. At each step, a lightweight coordinator assigns one of three distinct roles to an LLM from its available pool:
1/ Thinker: Devises high-level strategies and analyzes the current state.
2/ Worker: Executes concrete problem-solving steps.
3/ Verifier: Evaluates if the current solution is complete and correct.
By dynamically assigning these roles, the coordinator effectively offloads complex reasoning and skill execution onto the external models.
What makes TRINITY unique is its extreme efficiency. The coordinator relies on the hidden states of a compact language model and a small routing head. In total, it has fewer than 20K learnable parameters.
Training this system presented a massive challenge. Traditional Reinforcement Learning (REINFORCE) failed because the gradients had a low signal-to-noise ratio due to binary rewards and weak parameter coupling. Imitation learning (Supervised Fine-Tuning) was ruled out because generating multi-turn labels is prohibitively expensive.
Our solution? We turned to nature-inspired algorithms. We optimized the coordinator using a derivative-free evolutionary algorithm. We found that evolution is uniquely suited to optimize this tight, high-dimensional coordination problem where traditional gradient-based methods fail.
The results are very promising. In our experiments, TRINITY consistently outperforms existing multi-agent methods and individual models across various benchmarks. At the time of publication, it set a new state-of-the-art record on LiveCodeBench, achieving an 86.2% pass@1 score.
More importantly, it demonstrated incredible generalization. Without any retraining, TRINITY transferred zero-shot to four unseen tasks (AIME, BigCodeBench, MT-Bench, and GPQA). On average, the evolved coordinator surpassed every individual constituent model in its pool, including GPT-5, Gemini 2.5-Pro, and Claude-4-Sonnet (the top frontier models available at the time of our #ICLR2026 submission last year).
This work is central to Sakana AI's vision. We believe the future of AI isn't just about scaling monolithic models, but engineering collaborative, diverse AI ecosystems that can adapt and combine their strengths.
We invite the community to read the paper and explore these ideas!
Paper: arxiv.org/abs/2512.04695
OpenReview: openreview.net/forum?id=5HaR…
This foundational research is part of the core engine powering our multi-agent product: Sakana Fugu 🐡👇

1
65

Apr 25
What if instead of building one giant AI, we evolved a coordinator to orchestrate a diverse team of specialized AIs? 🐟
Excited to share our new paper: “TRINITY: An Evolved LLM Coordinator”, published as a conference paper at #ICLR2026!
Paper: arxiv.org/abs/2512.04695
In nature, complex problems are rarely solved by a single monolithic entity, but rather by the coordinated efforts of specialized individuals working together. Yet, modern AI development is heavily focused on endlessly scaling up single, massive monolithic models, yielding diminishing returns. While model merging offers a way to combine different skills, it is often impractical due to mismatched neural architectures and the closed-source nature of top-performing models.
To address this, we took a macro-level approach: test-time model composition. We introduce TRINITY, a system that fuses the complementary strengths of diverse, state-of-the-art models without needing to modify their underlying weights.
TRINITY processes queries over multiple turns. At each step, a lightweight coordinator assigns one of three distinct roles to an LLM from its available pool:
1/ Thinker: Devises high-level strategies and analyzes the current state.
2/ Worker: Executes concrete problem-solving steps.
3/ Verifier: Evaluates if the current solution is complete and correct.
By dynamically assigning these roles, the coordinator effectively offloads complex reasoning and skill execution onto the external models.
What makes TRINITY unique is its extreme efficiency. The coordinator relies on the hidden states of a compact language model and a small routing head. In total, it has fewer than 20K learnable parameters.
Training this system presented a massive challenge. Traditional Reinforcement Learning (REINFORCE) failed because the gradients had a low signal-to-noise ratio due to binary rewards and weak parameter coupling. Imitation learning (Supervised Fine-Tuning) was ruled out because generating multi-turn labels is prohibitively expensive.
Our solution? We turned to nature-inspired algorithms. We optimized the coordinator using a derivative-free evolutionary algorithm. We found that evolution is uniquely suited to optimize this tight, high-dimensional coordination problem where traditional gradient-based methods fail.
The results are very promising. In our experiments, TRINITY consistently outperforms existing multi-agent methods and individual models across various benchmarks. At the time of publication, it set a new state-of-the-art record on LiveCodeBench, achieving an 86.2% pass@1 score.
More importantly, it demonstrated incredible generalization. Without any retraining, TRINITY transferred zero-shot to four unseen tasks (AIME, BigCodeBench, MT-Bench, and GPQA). On average, the evolved coordinator surpassed every individual constituent model in its pool, including GPT-5, Gemini 2.5-Pro, and Claude-4-Sonnet (the top frontier models available at the time of our #ICLR2026 submission last year).
This work is central to Sakana AI's vision. We believe the future of AI isn't just about scaling monolithic models, but engineering collaborative, diverse AI ecosystems that can adapt and combine their strengths.
We invite the community to read the paper and explore these ideas!
Paper: arxiv.org/abs/2512.04695
OpenReview: openreview.net/forum?id=5HaR…
This foundational research is part of the core engine powering our multi-agent product: Sakana Fugu 🐡👇
Apr 24
We’re launching the beta for our new commercial AI product: Sakana Fugu 🐡, a multi-agent orchestration system!
Blog: sakana.ai/fugu-beta
Fugu hits SOTA on SWE-Pro, GPQA-D, and ALE-Bench, and has been our internal secret weapon. It dynamically coordinates frontier models, autonomously selecting the optimal agent combinations and roles for each task.
Available as an OpenAI-compatible API, you can seamlessly integrate Fugu into your existing workflows with minimal changes.
🐟 Fugu Mini: High-speed orchestration optimized for latency
🐡 Fugu Ultra: Full model pool utilization for deep, complex reasoning
Apply for the beta test here: forms.gle/BtKkhc2CfLKk1dvNA

15
68
406
99,868

Apr 24
✂️ The Over-Editing Problem In AI Coding Tools
Researcher nrehiew benchmarked 9 frontier models on a minimal-editing task using 400 programmatically corrupted problems from BigCodeBench.
nrehiew.github.io/blog/minim…
7

Apr 23
同一个 bug 交给 Claude 和 GPT 修,GPT 多改了 6 倍的代码。
nrehiew 跑 BigCodeBench 400 题,用编辑距离量「模型手痒」程度:
Claude Opus 4.6: 0.060
GPT-5.4: 0.395
数字越小越克制。
nrehiew.github.io/blog/minim… #AI #Claude

1
1
56

Apr 22
Rankings of the best LLMs on code completion benchmarks - HumanEval, LiveCodeBench, BigCodeBench, MBPP, and competitive programming - with methodology notes on contamination. Updated April 2026.
#Leaderboards #CodeCompletion
Link in the first comment 👇

1
21