


26 Aug 2025
The paper replaces fixed tests with live chats to measure how humans and models perform together.
The core idea is simple, turn benchmark questions into back and forth chats that capture how people actually ask, skip details, and follow up.
The setup measures 3 modes, person alone, model alone, and person with AI, so the team can compare real outcomes.
The key claim, model-alone scores are a weak signal for person plus AI success on the same items.
Another consistent result, the big gap between a strong model and a weaker one on static tests shrinks once real chat starts.
Why this happens, people rarely paste the exact question, they paraphrase, add context, and sometimes correct the model mid way.
To scale beyond small studies, the authors add a simple 2-step user simulator that asks, then follows up like a person.
This simulator predicts person plus AI outcomes far better than raw model-alone accuracy.
So model choice and tuning should use this chat-based evaluation, not letter-only answers from static benchmarks.
----
Paper – arxiv. org/abs/2504.07114
Paper Title: "ChatBench: From Static Benchmarks to Human-AI Evaluation"

2
4
2,834

24 Aug 2025
Microsoft just released ChatBench-Mistral-7B on Hugging Face
This user simulator enables automated, realistic evaluation of LLMs through simulated conversations,
moving beyond static benchmarks.
2
3
17
1,201
23 Aug 2025
Microsoft just released chatbench-llama3-8b on Hugging Face
This fine-tuned user simulator enables automated, realistic evaluation of LLMs through simulated user–AI conversations, moving beyond static benchmarks.
2
4
17
969
23 Aug 2025
Microsoft just released ChatBench-DistilGPT2 on Hugging Face.
It's a user simulator for automated, realistic evaluation of LLMs through dynamic user-AI conversations.
Move beyond static benchmarks!

2
4
21
1,249

24 May 2025
Hey friends, it’s time to connect! 🌻
Join us THIS SUNDAY, May 25th for another enlivening conversation at the #ChatBench — a space to share stories, spark ideas, and learn something new together 🌱✨
🛋️ Zoom in ➡️ hubs.la/Q03p0Vnr0
#community #timebanking #timebanks

1
3
4
63

19 May 2025
Excited to have two papers accepted to ACL 2025 main! 🎉
1. ChatBench with @jakehofman @ashton1anderson - we conduct a large-scale user study converting static benchmark questions into human-AI conversations, showing how benchmarks fail to predict human-AI outcomes.

2
13
91
11,334
24 Apr 2025
Blog post on exciting research happening at MSR, including our recent work ChatBench on human-AI vs AI-alone evaluation!
23 Apr 2025

In this issue: our CHI 2025 & ICLR 2025 contributions, plus research on causal reasoning & LLMs; countering LLM jailbreak attacks; and how people use AI vs. AI-alone. Also, SVP of Microsoft Health Jim Weinstein talks rural healthcare innovation: msft.it/6013SHuu1
ALT The image features a circular, abstract design with three sections containing illustrations. The top section shows two people discussing equations on a whiteboard. The left section depicts a person working on a laptop with charts and graphs on the screen. The right section displays a hand holding a vial and pipette over test tubes. Text in purple boxes reads "RESEARCH FOCUS" and "APRIL 23, 2025."
1
19
2,025
9 Apr 2025
Check out ChatBench online and see our paper for many more details, including analyses of the user-AI conversations! Thanks to my fantastic collaborators at @MSFTResearch, @ashton1anderson and @jakehofman. 9/
ChatBench: huggingface.co/datasets/micr…
Paper: serinachang5.github.io/asset…

1
6
635
9 Apr 2025
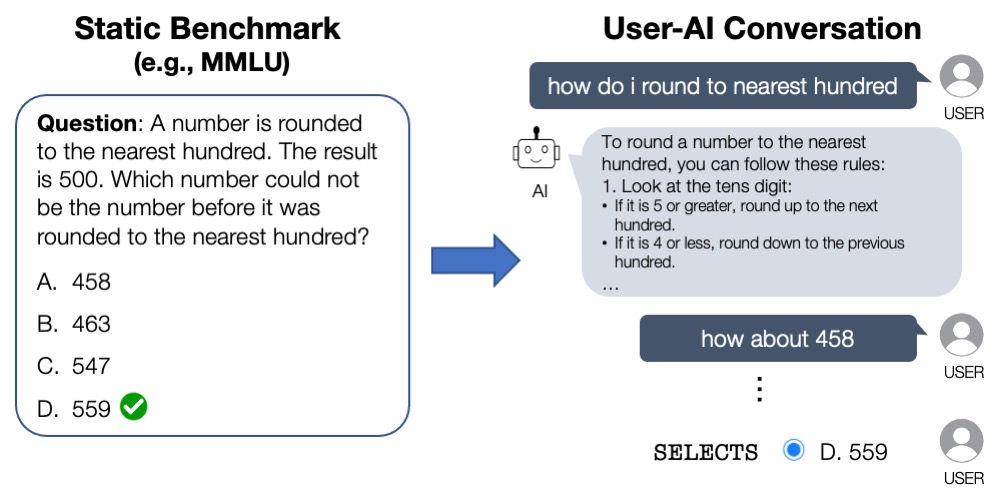
What happens when a static benchmark comes to life? ✨Introducing ChatBench, a large-scale user study where we *converted* MMLU questions into thousands of user-AI conversations. Then, we trained a user simulator on ChatBench to generate user-AI outcomes on unseen questions. 1/
2
14
82
17,493

12 Jun 2024
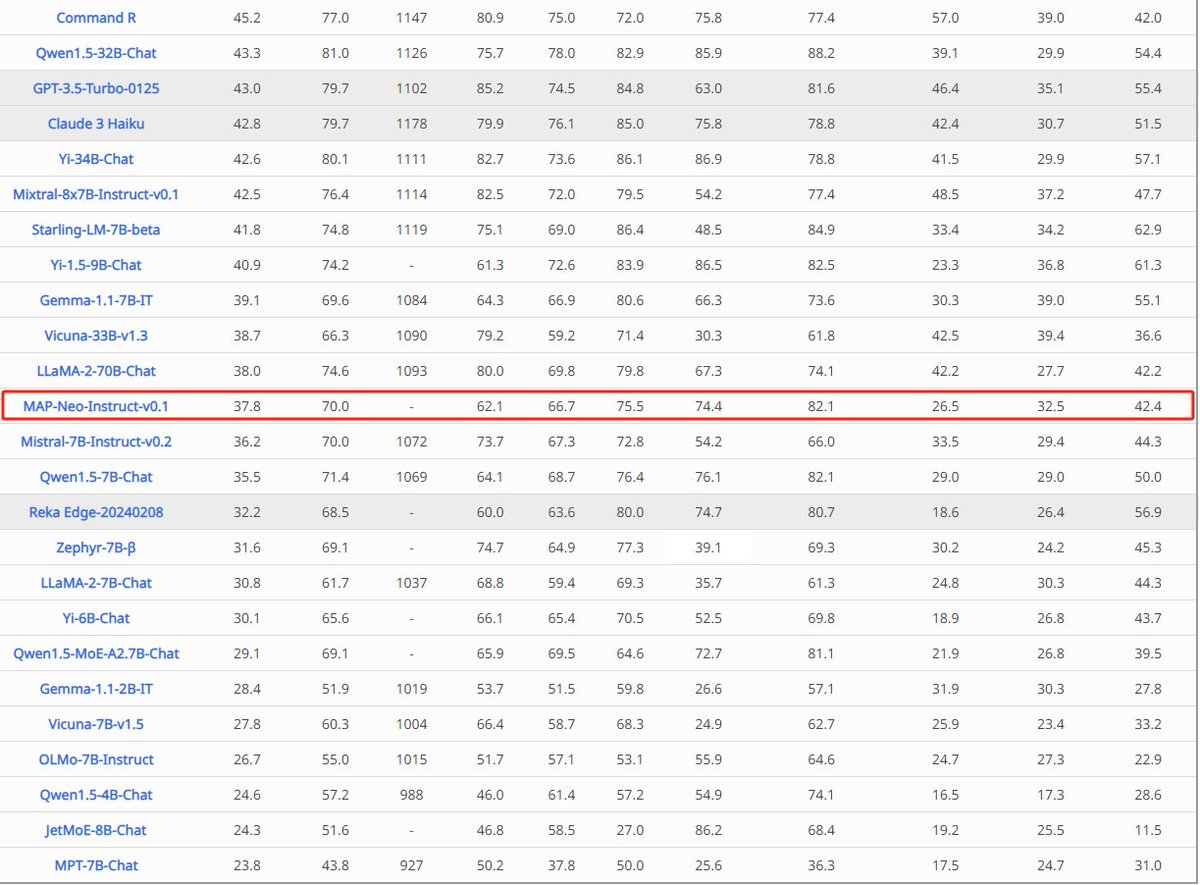
MAP-Neo is another good example!(github.com/multimodal-art-pr…)
We release all resources needed to be on par with Mistral v0.2 and surpass LLaMA-2(code/pretrain corpus/data cleaning pipeline/etc) with the similar size.
We are also glad to announce that we open-source the phase-2 SFT data of MAP-Neo today: huggingface.co/datasets/m-a-…
The neo-7b-instruct-v0.1(huggingface.co/m-a-p/neo_7b_…) shows really impressive performance on MixEval and all the automatic chatbench closely related to Chatbot Arena!
Look forward to see how it can perform on the Chatbot Arena: @lmsysorg
11 Jun 2024

We should call models like Llama 3, Mixtral, etc. “open-weight models”, not “open-source models”. For a model to be open-source, the code and training data need to be public (good examples: GPT-J, OLMo, RedPajama, StarCoder, K2, etc.). Weights are like an exe file, which would be ridiculous to call open-source.
1
2
25
5,415

14 Jan 2023
Huge thanks to Bridgwater Mens Shed for crafting & Bridgwater Rotary Club for donating this fantastic ‘Chat Bench’ just delivered to #BridgwaterLibrary @SomersetLib. We can see this getting well used!#BridgwaterMensShed #BridgwaterRotaryClub #ChatBench #ItsGoodToTalk




1
1
5
270



19 May 2022
With #summer #sunshine I find #Poppy's #Friendship #chatbench an Ideal opportunity to invite #neighbours @ProgressHG for a cuppa #safely in our cul de sac to #chat become #friends check they're ok and just #enjoy #community spirit in this uncertain world 😉 🐾 @BBCLancashire good




1
4
19 May 2022
#thursdayvibes my Daddy has attached the brass plaque to my #Poppy 🐾❤️ #Friendship #chatbench @SharonHartley_ @BBCLancashire @ProgressHG to be #officially opened by my #GodMother @russinblack with a collection for @BleakholtUK one sunny Friday afternoon 🐾❤️ #community #Boom! 🐾




2
5
18 May 2022
But @russinblack my Daddy treated me to a new tag #ImChipped along with my tag with Daddy's phone number ...and my new brass plaque for my #friendship #chatbench @ProgressHG looking forward to you cutting the ribbon 🎀 #community #friendship #neighbours my Daddy good man 👊🐾🐾🐾

1
1
4
14 May 2022
Oh my goodness #AuntyJoJo @russinblack look my Daddy bought that cushion after his #Spinning classes 🐾 #Pawsome #Pipan at #Home #independant #retail #ShopLocal #StAnnesOnSea @StAnnesTweetUp looking good on my #ChatBench @ProgressHG #community 🐾❤️ #friendship #neighbours 🐾😉




1
1
2
5 May 2022
#Poppy officially invites her #GodMother @russinblack to open her #Friendship #chatbench @ProgressHG in a couple of weeks when brass plaque attached 🐾 cause #AuntyJoJo is #Pawsome #friendship #neighbours we loves our #neighbours so much 🐾❤️ #friendship 🐾 matters good 👊🐾



1
1
2

As always, #MentalHealthAwarenessWeek starts in @VisitJerseyCI for me a week today. Over the few days I am there I shall be waking the course and attending @jerseyraceclub Guineas. Grateful to their support for #GoRacingGreen 💚 #loneliness #chatbench




13

6 Mar 2022
A nice bench has appeared in West Walks, donated by the Senior Citizen Liason Team but has already been visited by ‘ The Other’ 🖊
#Dorchester #Dorset #graffiti #chatbench


2
2